NLP 论文领读 | Seq2Seq一统江湖?谷歌提出全新端到端检索范式DSI,它才是检索模型的未来?
欢迎关注 NLP 论文领读专栏!快乐研究,当然从研读paper开始——澜舟科技团队注重欢乐的前沿技术探索,希望通过全新专栏和大家共同探索人工智能奥秘、交流NLP「黑科技」,踩在「巨人」肩上触碰星辰!官网:https://langboat.com
本期分享者:澜舟科技研究实习生 沈田浩,天津大学自然语言处理实验室(TJUNLP)一年级博士生,目前正在研究对话系统,期待人和机器能够真正自由交流的那一天!Feel free to contact me via email: [email protected] 君子以文会友,以友辅仁~
写 在 前 面
信息检索可以说是互联网中应用最广泛和最成功的技术之一,没有信息检索,我们就会迷失在海量的互联网数据中。想找到自己需要的信息?很蓝的啦~
目前的各类信息检索模型大体都遵循召回+排序的两阶段流程,也就是根据用户的查询(query)首先从海量的文档(document)集合中用简单的特征和模型筛选出粗略匹配的文档(召回),然后对这些文档使用更多的特征和更强的模型做进一步打分(排序),就可以最终得到按分数排序的文档列表了。
那么如何组织海量的文档以便模型检索呢?这时候就需要一个索引了。稀疏检索方式(使用高维稀疏向量表示用户查询和文档,如BM25[1])一般是使用倒排索引,也就是以词为索引,构建词到文档的映射。而稠密检索方式(使用低维稠密向量表示查询和文档,如目前一票基于深度学习的双塔检索模型)则是构建一个表,其中每一行存储一个文档的向量表示。
然而我们可以看到,目前的这套检索框架存在一些天然的缺陷。首先,两阶段流程会导致错误的传播,并且排序模型和召回模型不能联合优化。如果一个用户想要的文档都没有进入召回模型的法眼,那么无论排序模型多么强大也无法挽救了。如果能使用一个端到端的模型统一建模检索过程,就可以极大缓解上述问题;其次,目前的检索方式都依赖于不可学习的外部索引,并采用不可学习的度量方式(如归一化内积),如果能够根据数据对索引和度量也做优化,是不是就非常的有趣了呢?
正所谓“好风凭借力,送我上青云”,最近大规模预训练模型的迅猛发展大家也是有目共睹,它能够通过自己“记住”的知识回答很多问题,并且具有极强的生成能力。如果能使用一个大模型直接完成整个检索流程,就朝着解决上述问题前进了一大步!
近日来自谷歌研究院的研究人员就发表了一篇名为《Transformer Memory as a Differentiable Search Index》的论文,提出了一种基于Seq2Seq的端到端检索架构DSI,并取得了不错的检索效果。接下来就让我们一起来看看这篇论文,它是否能够代表未来检索模型的发展方向呢?
论文标题
Transformer Memory as a Differentiable Search Index
论文作者
Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, Donald Metzler
论文单位
Google Research
论文链接
https://arxiv.org/abs/2202.06991
论文代码
https://github.com/ArvinZhuang/DSI-transformers
(目前还没有开源,非官方复现)
DSI有什么不一样?
首先,论文给出了一个与此前检索方式比较的表格,从中就能看出DSI的不同之处:

可以看到,DSI引入了新的文档索引方式docid,并通过训练模型实现docid到文档的映射,因此索引实际上是存储在模型参数中的。同时,DSI的检索方式也是可训练的,检索时不再计算内积,而是通过序列的方式输出docid。同时,文中也提到,DSI的排序是通过Beam Search的方式输出top-k的docid,因此不需要额外的排序模型,极大地简化了整体设计。
虽然DSI看上去极具颠覆性,和此前的检索模型比起来简直是哪哪都不一样,但实际上DSI的结构却是非常简单的。笔者在这里画了一个示意图,供大家参考:

从图中可以看到,DSI按先后顺序可分为四个模块:
1. 文档表示策略:这里是要解决索引什么(what to index)的问题。考虑到完整文档往往较长,作者认为采用文档词序列的子集来表示文档是更好的方案。作者提出了三种文档表示策略:
• Direct Index: 使用前L个tokens表示该文档;
• Set Index: 先去重,去停用词,然后按照类似Direct Index的方式操作;
• Inverted Index: 多次采样连续的k个tokens表示该文档。
2. Docid 构造:作者认为一个好的docid需要满足两条要求:首先,docid需要能够表示文档语义;其次,docid需要在每一步解码过程中帮助解码器缩小搜索空间,以保证检索速度。基于这个目标,作者提出了三种构造docid的方案:
• Unstructured Atomic Docid:直接为doc分配任意int值的docid,预测时视为分类任务,这个方案不满足上述的任何一条要求;
• Naively Structured String Docid:把docid视为文本序列进行解码,以降低每步解码时可选的token范围。这个方案能够实现上述第二条要求,但第一条仍无法满足;
• Semantically Structured Docid:作者认为较好的方案,通过层次化的语义编码在降低每步解码时可选token范围的同时赋予docid语义信息,如下图所示。可以看到这个方案能够同时满足上述两条要求。

具体来说,在构造Semantically Structured Docid时,模型首先使用8层BERT对文档编码得到文档的向量表示,然后做k-means聚类。聚类时先将文档集合分为10个cluster(每个cluster要少于c个文档),如果多于c个文档,则再分为10个cluster,直到每个cluster都少于c个文档为止。总体来看这是一种十进制的树状编码,其中作者实际使用的c=100。
3. 基于docid和文档表示训练索引(index)模型:这里是要解决如何索引(how to index)的问题。有了docid和文档表示以后,就要建立它们之间的对应关系了。DSI采用Seq2Seq的方式建模索引过程,同时作者也给出了四种索引建模策略:
• Inputs2Target:输入文档表示,输出docid;
• Target2Inputs:与上面的策略相反,输入docid,输出文档表示;
• Bi-directional:上述两种方式进行联合训练,通过tag让模型知道是哪个方向;
• Span corruption: 直接把docid和文档表示拼在一起做随机span corruption。
4. 基于索引和用户查询训练检索(retrieval)模型:这一步就是实际的检索步骤了,可以看到和索引任务一样,它们的输出都是docid,只不过输入从文档表示变成了用户的查询。那么一个很自然的想法就是将这两个任务也放在一起训练,而作者也是这么做的。
作者在这里尝试了两种方式:1)先训练一个索引模型,再在检索任务上微调,以及2)直接同时学习两个任务,并使用prompt加以区分。实验表明第二种方案显著优于第一种,因此后续的实验也是基于后者开展的。
介绍完模型后我们再来回顾一下,DSI是怎么解决前面提到的问题的呢?
1. 首先,它的编码和检索建模成了同一个任务,因此可以使用一个模型同时训练。同时不再针对排序设计专门的模型,而是直接使用解码过程中的beam search完成,因此是一个端到端的检索架构,这就解决了传统的召回+排序两阶段流程中错误传播和无法联合优化的问题;
2. 其次,它的索引方式和检索方式都是可训练的,且直接存储于模型参数中,这使得模型可以学习到更适合训练数据的索引方式和检索方式,而不会局限于固定的索引和向量相似度检索。
实 验 设 置 及 结 论
实验数据集方面,作者基于Natural Question(NQ)[2]构造出三种不同规模的数据集: NQ10K/NQ100K/NQ320K(分别包含10K/100K/320K个文档),指标则使用了衡量召回性能的Hits@k。模型方面,作者使用了Base(0.2B), Large(0.8B), XL(3B)和XXL(11B)四种不同参数规模的T5模型。为了训练这些模型,作者使用了128-256块(XL/XXL)和64-128块(Base/Large)TPU,只能说谷歌就是谷歌,延续了一贯的壕气作风……
不过这里笔者认为实验的数据集和评测指标还是太过单一了:只使用了NQ和衡量召回性能的Hits@k。首先,数据集层面还有很多其它的检索数据集,如目前学术界广泛使用的MSMarco[4];其次,鉴于DSI能够排序,评测指标层面应引入对位置敏感的评测指标(如MRR)以评估beam search的排序能力,这点还是有点遗憾的。
接下来我们来看实验:
1. 有监督的full-shot setting:

如上表所示,在这个设置下,作者比较了BM25、使用T5的双塔架构和使用T5的DSI架构的表现。可以看到DSI总体来说是比BM25和双塔架构强的,也可以看出模型越大DSI的表现越好。但最优的docid表示策略则有点出乎意料,作者认为最好的Semantic Docid相比其它两种相对朴素的策略并没有全方位的领先,三种策略各自占据了一些最优指标。笔者猜想这可能是由于构造docid的模型(即8层BERT+k-means)的建模能力偏弱,导致Semantic Docid的表示能力不足,进而无法完全达到作者的设计初衷。
2. zero-shot setting,即不使用用户查询,只有文档的情形:
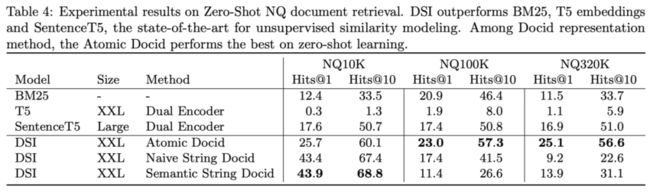
可以看到DSI再次优于BM25和双塔架构,且领先幅度较大。笔者认为这是由于索引和检索两个任务建模成了相同的形式,因此在没有用户查询时,索引可视为检索的预训练任务,因此为zero-shot 的检索提供了一个还不错的初始化权重。
然而,在最优的docid表示策略方面,当数据规模变大时,反倒是最朴素的Atomic Docid效果最好(并且好得多),但在full-shot设置下却没有这种现象。这点作者并没有解释原因,并且在实验分析部分更是直接把实验结果的表格用自然语言复述了一遍,没有提供任何新的有用信息,这点让笔者感到十分困惑。同时,作者在比较时使用的SentenceT5只是一个Large模型,而双塔和DSI的T5却使用了XXL模型(两者参数量大约相差十几倍),且提升相较参数量来说有限,针对参数带来的提升和算法带来的提升还需要进一步分析。
3. 不同的文档表示策略和索引建模策略:
• Index策略: 在NQ100K数据集和Atomic Docid策略下,Hits@1分别为:Inputs2Targets (13.5) > Bi-directional (13.2) >> Targets2Inputs (0) ≈ Span Corruption (0),可以看到Inputs2Targets仍然是最好的策略,这也比较符合我们的直觉;
• Document表示: 从下图可以看出,最简单的Direct Index(取前32个token)反而效果最好,并且不同的表示方法对检索表现有非常大的影响。

4. Scaling Laws:
可以看到随着模型参数量变大,DSI性能能够继续大幅提升,但双塔架构基本停滞。这意味着DSI架构对参数量更敏感,因此更能从目前大模型的研究中获益,但这同时也意味着它需要大模型才能充分发挥作用,如果不解决大模型推理阶段的检索速度和成本问题,DSI还是很难实用化的。
5. Interplay Between Indexing and Retrieval:
这里作者探究了index和retrieval两个任务之间的关系。既然两个任务是同时训练的,那么比例就要有讲究。可以看到索引和检索比例为32:1时达到最好性能,不过由于实验没有使用其它数据集,目前无法确定该比例与什么因素有关(比如用户查询长度、候选文档数量等)

未 来 方 向
• 在DSI中,索引和检索两个任务有显著的依赖关系(即检索依赖好的索引模型),在这种具有先后依赖关系的任务间进行多任务学习仍然是具有挑战性的,未来需要探索更好的训练策略,如某种形式的交替训练或基于课程学习的训练方法;
• 信息检索,特别是大规模数据的检索对速度是非常敏感的,考虑到DSI对参数量的要求,未来需要提升检索速度,使其能够顺利应用到大规模数据中;
• 数据更新对于信息检索来说是家常便饭,但对于DSI来说,数据更新时模型也需要更新。考虑到训练DSI需要花费大量时间,如何在推理阶段以较低成本更新模型也是一个值得研究的问题;
• 检索增强的语言模型是时下最火热的NLP研究方向之一(参见往期检索增强相关论文领读,DeepMind 发布检索型 LM,或将成为 LM 发展新趋势!?和别再第四范式:看看新热点检索增强怎么做文本生成!),作为一种与大规模预训练模型联系更加紧密的检索范式,DSI和检索增强的语言模型的结合也许很值得期待哦~
总 结
这篇论文提出了一种全新的端到端检索范式:Differentiable Search Index (DSI),通过Seq2Seq的方式实现检索,并统一建模了召回和排序过程。实验表明,DSI在full-shot和zero-shot上击败了双塔稠密检索模型和稀疏检索模型BM25,但最优的docid构造策略仍有待商榷。
DSI最大的亮点在于它能够更直接地借助大规模预训练模型的力量。在以往的检索模型中,预训练模型大多都应用在编码器上以获得更好的向量表示。而DSI则更进一步,将编码、检索和排序的全过程都纳入到预训练模型的版图,这样就可以利用海量的无监督语料来优化整个检索过程,在没有数据的情况下也能得到一个差强人意的检索模型。与此同时,DSI还可以加入其它建模成Seq2Seq的任务的数据进行联合训练,这也有望进一步提升检索模型的表现。这么来看,Seq2Seq+Prompt大潮在攻陷一众NLP任务后,又啃下来了一块硬骨头,朝着一统天下又迈进了一步。
然而目前,阻碍DSI实用化的最大因素还是速度问题。DSI将原本不可学习的、基于向量相似度的检索变成了模型的inference。然而成也可学习,败也可学习,如果不解决大模型对检索速度产生的巨大影响,DSI是无法取代现有的检索架构的。不过这种挖新坑的文章往往也是大家希望看到的,毕竟它是一块璞玉,能进一步雕琢的地方越多,越能吸引人去follow嘛~
参考资料
[1] Robertson, Stephen, and Hugo Zaragoza. "The Probabilistic Relevance Framework: BM25 and Beyond." Information Retrieval 3.4 (2009): 333-389.
[2] Kwiatkowski, Tom, et al. "Natural questions: a benchmark for question answering research." Transactions of the Association for Computational Linguistics 7 (2019): 453-466.
[3] Raffel, Colin, et al. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer." Journal of Machine Learning Research 21 (2020): 1-67.
[4] Nguyen, Tri, et al. "MS MARCO: A human generated machine reading comprehension dataset." CoCo@ NIPS. 2016.
[5] Ni, Jianmo, et al. "Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models." arXiv preprint arXiv:2108.08877 (2021).
本专栏欢迎投稿,关注公众号「澜舟科技」或者联系澜小舟(id: langboat2021)哦。