(CVPR 2017) Joint 3D Proposal Generation and Object Detection from View Aggregation
摘要
我们提出了AVOD,一种用于自动驾驶场景的聚合视图目标检测网络。所提出的神经网络架构使用LIDAR点云和RGB图像来生成由两个子网络共享的特征:区域proposal网络(RPN)和第二阶段检测器网络。所提出的RPN使用一种新颖的架构,能够在高分辨率特征图上执行多模态特征融合,从而为道路场景中的多个目标类别生成可靠的3D目标proposal。使用这些proposal,第二阶段检测网络执行准确的定向3D边界框回归和类别分类,以预测3D空间中目标的范围、方向和分类。我们提出的架构被证明可以在KITTI 3D目标检测基准[1]上产生最先进的结果,同时以低内存占用实时运行,使其成为部署在自动驾驶汽车上的合适候选者。代码地址:https://github.com/kujason/avod
I.介绍
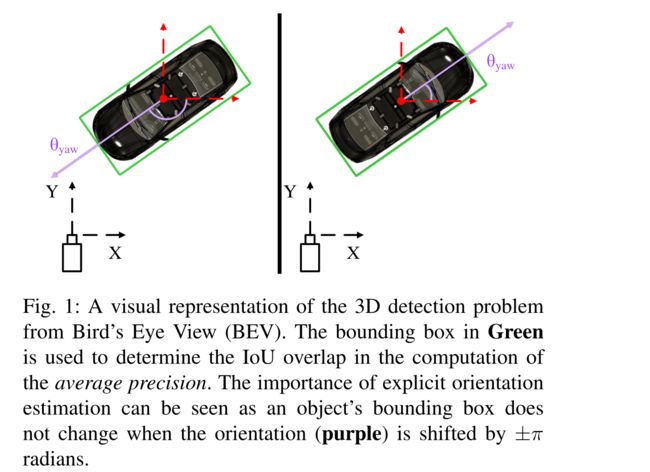
近年来,深度神经网络在2D物体检测任务上取得的显著进展并没有很好地转移到3D目标的检测上。在标准基准上,两者之间的差距仍然很大,例如KITTI目标检测基准[1],其中2D汽车检测器已经实现了超过90%的平均精度(ap),而相同场景下得分最高的3D汽车检测器仅实现了70%的平均精度。出现这种差距的原因在于,向估计问题添加第三维所带来的困难、3D输入数据的低分辨率以及其质量随距离而变差。此外,与2D目标检测不同,3D目标检测任务需要估计定向边界框(图1)。
与2D目标检测器类似,大多数用于3D目标检测的最先进的深度模型依赖于3D区域proposal生成步骤来减少3D搜索空间。使用区域proposal允许在后期检测阶段通过更复杂和计算成本更高的处理来生成高质量的检测。但是,在proposal生成阶段丢失的任何实例都无法在以下阶段恢复。因此,在区域proposal生成阶段实现高召回率对于良好的性能至关重要。
图1:鸟瞰图(BEV)中3D检测问题的可视化表示。绿色中的边界框用于确定平均精度计算中的IoU重叠。显式方向估计的重要性可以看作是,当方向(紫色)偏移±π弧度时,目标的边界框不会改变。
区域proposal网络(RPN)是在Faster-RCNN[2]中提出的,并已成为2D目标检测器中流行的proposal生成器。 RPNs可以被认为是一个弱amodal检测器,提供高召回率和低精度的proposals。这些深度架构很有吸引力,因为它们能够与其他检测阶段共享计算成本高的卷积特征提取器。然而,将这些RPN扩展到3D是一项艰巨的任务。Faster R-CNN RPN架构是为密集的高分辨率图像输入量身定制的,其中目标通常在特征图中占据超过几个像素。在考虑稀疏和低分辨率输入时,例如前视图[3]或鸟瞰图(BEV)[4]点云投影,这种方法不能保证有足够的信息来生成区域proposals,尤其是对于小目标类。
图2:所提出方法的架构图。特征提取器以蓝色显示,区域proposal网络以粉红色显示,第二阶段检测网络以绿色显示。

在本文中,我们旨在通过提出AVOD来解决这些困难,这是一种用于自动驾驶的聚合视图目标检测架构(图2)。提议的架构提供了以下贡献:
-
受用于2D目标检测的特征金字塔网络(FPNs)[5]的启发,我们提出了一种新颖的特征提取器,它从激光雷达点云和RGB图像中产生高分辨率的特征地图,允许在场景中定位小类(small classes)。
-
我们提出了一种特征融合区域Proposal网络(RPN ),它利用多种模态为小类(small classes)产生高召回区域proposals。
-
我们提出了一种新颖的3D边界框编码,它符合框几何约束,允许更高的3D定位精度。
-
所提出的神经网络架构在RPN阶段利用1×1卷积,以及3D anchor投影的固定查找表,在保持检测性能的同时允许高计算速度和低内存占用。
上述贡献产生了一种架构,该架构以低计算成本和低存储器占用量提供最先进的检测性能。最后,我们将该网络集成到我们的自动驾驶堆栈中,并在更极端的天气和照明条件下对新场景和检测进行推广,使其成为部署在自动驾驶汽车上的合适候选。
II.相关工作
用于Proposal生成的手工制作特征: 在3D区域Proposal网络(RPN)[2]出现之前,3D proposal生成算法通常使用手工制作的特征来生成一小组候选框,以检索3D空间中的大部分目标。3DOP[6]和Mono3D[7]使用来自立体点云和单目图像的各种手工制作的几何特征,在能量最小化框架中对3D滑动窗口进行评分。前 K K K个评分窗口被选为区域proposal,然后由修改后的Fast-RCNN[?]消耗以生成最终的3D检测。我们使用从BEV和图像空间中学习特征的区域proposal网络以有效的方式生成更高质量的proposals。
Proposal Free Single Shot Detectors: Single shot目标检测器也被提议作为用于3D目标检测任务的RPN自由架构。VeloFCN[3]将激光雷达点云投影到正面视图,作为全卷积神经网络的输入,直接生成密集的3D边界框。3D-FCN[8]通过对从激光雷达点云构建的3D体素网格应用3D卷积来生成更好的3D边界框,从而扩展了这一概念。我们的两阶段(two-stage)架构使用RPN检索道路场景中的大多数目标实例,与这两种单次方法相比,提供了更好的结果。 VoxelNet[9]通过使用逐点特征而不是占用值对体素进行编码,进一步扩展了3D-FCN。然而,即使使用稀疏的3D卷积操作,VoxelNet的计算速度仍然比我们提出的架构慢3倍,这在汽车和行人类别上提供了更好的结果。
基于单目的Proposal生成: 最先进的另一个方向是使用成熟的2D目标检测器在2D中生成proposal,然后通过amodal范围回归将其拉伸为3D。这种趋势始于[10]用于室内物体检测,这启发了基于Frustum的PointNets(F-PointNet)[11]使用PointNet[12]的逐点特征而不是点直方图进行范围回归。虽然这些方法适用于室内场景和明亮的户外场景,但预计它们在更极端的户外场景中表现不佳。任何错过的2D检测都会导致错过3D检测,因此,这些方法在这种极端条件下的泛化能力还有待证明。LIDAR数据的可变性远小于图像数据,我们在第四节中展示了AVOD对嘈杂的LIDAR数据和光照变化具有鲁棒性,因为它在雪景和低光照条件下进行了测试。
基于单目的3D目标检测器: 利用成熟的2D目标检测器的另一种方法是使用先验知识仅从单目图像执行3D目标检测。 Deep MANTA[13]提出了一种基于单目图像的多任务车辆分析方法,可同时优化区域proposal、检测、2D框回归、部分定位、部分可见性和3D模板预测。该架构需要一个对应于几种类型车辆的3D模型数据库,这使得所提出的方法难以推广到不存在此类模型的类。 Deep3DBox[14]提出通过利用3D边界框的透视投影应该紧密地适合其2D检测窗口这一事实,将2D目标检测器扩展到3D。然而,在第四节中,与使用点云数据的方法相比,这些方法在3D检测任务上表现不佳。
3D区域Proposal网络: 3D RPN先前已在[15]中提出,用于从RGBD图像中检测3D目标。然而,据我们所知,MV3D[4]是唯一提出针对自动驾驶场景的3D RPN的架构。 MV3D通过将BEV特征图中的每个像素对应到多个先前的3D anchors,将Faster R-CNN[2]的基于图像的RPN扩展到3D。然后,这些anchors被送入RPN,以生成3D方案,用于从BEV、[3]的前视图和图像视图特征图创建视图特定的feature crops。深度融合方案用于组合来自这些特征裁剪的信息,以产生最终的检测输出。但是,这种RPN架构不适用于BEV中的小目标实例。当通过卷积特征提取器进行下采样时,小实例将在最终特征图中占据一小部分像素,导致数据不足,无法提取信息特征。我们的RPN架构旨在融合来自图像的全分辨率特征裁剪和BEV特征图作为RPN的输入,从而为较小的类生成高召回率建议。此外,我们的特征提取器提供了全分辨率特征图,在检测框架的第二阶段,这对小目标的定位精度有很大帮助。
III.AVOD架构
所提出的方法,如图2所示,使用特征提取器从BEV图和RGB图像生成特征图。然后,RPN使用这两个特征图来生成无方向的区域proposals,然后将其传递给检测网络进行维度细化、方向估计和类别分类。
A. 从点云和图像生成特征图
我们按照[4]中描述的程序从点云的体素网格表示中生成六通道BEV图,分辨率为0.1米。点云被裁剪为[−40, 40] × [0, 70]米,以包含相机视野内的点。 BEV地图的前5个通道使用每个网格单元中点的最大高度进行编码,由沿Z轴[0, 2.5]米之间的5个相等切片生成。第六个BEV通道包含按 min ( 1.0 , log ( N + 1 ) log 16 ) \min \left(1.0, \frac{\log (N+1)}{\log 16}\right) min(1.0,log16log(N+1))计算的每个单元格的点密度信息,其中 N N N是单元格中的点数。
B. 特征提取器
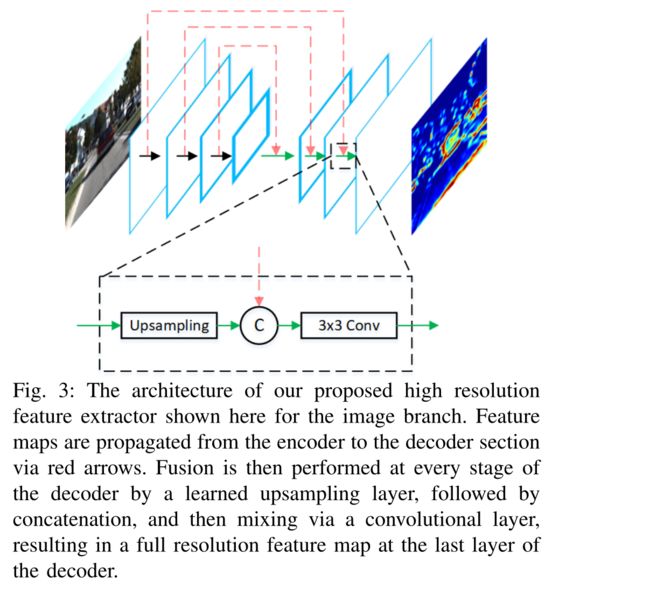
所提出的架构使用两个相同的特征提取器架构,一个用于每个输入视图。全分辨率特征提取器如图3所示,由两部分组成:编码器和解码器。编码器仿照VGG-16 [16]进行了一些修改,主要是将通道数量减少一半,并在conv-4层切割网络。因此,编码器将 M × N × D M × N × D M×N×D图像或BEV图作为输入,并生成 M 8 × N 8 × D ∗ \frac{M}{8} \times \frac{N}{8} \times D^{*} 8M×8N×D∗特征图 F F F。 F F F具有很高的表示能力,但与输入相比分辨率低8倍。 KITTI数据集中的平均行人在BEV中占据 0.8×0.6米。这转化为分辨率为0.1米的BEV图中的8×6像素区域。 8倍的下采样导致这些小类在输出特征图中占据不到一个像素,即没有考虑卷积引起的感受野增加。受特征金字塔网络(FPN)5]的启发,我们创建了一个自下而上的解码器,该解码器学习将特征图上采样回原始输入大小,同时保持运行时速度。解码器将编码器的输出 F F F作为输入,并生成一个新的 M × N × D M × N × D M×N×D特征图。图3显示了解码器执行的操作,包括通过卷积转置操作对输入进行上采样,连接来自编码器的相应特征图,最后通过3 × 3卷积操作将两者融合。最终的特征图具有高分辨率和代表性,由RPN和第二阶段检测网络共享。
图3:我们提出的图像分支的高分辨率特征提取器的结构。特征图通过红色箭头从编码器传播到解码器部分。然后,在解码器的每一级,通过学习的上采样层执行融合,随后是级联(concatenation),然后通过卷积层进行混合,从而在解码器的最后一层产生全分辨率特征图。
C. 多模态融合区域Proposal网络
与2D两阶段检测器类似,所提出的RPN回归了一组先前的3D框与ground truth之间的差异。这些先验框被称为anchors,并使用图4所示的轴对齐边界框编码进行编码。anchor框由质心 ( t x , t y , t z ) \left(t_{x}, t_{y}, t_{z}\right) (tx,ty,tz)和轴对齐维度 ( d x , d y , d z ) \left(d_{x}, d_{y}, d_{z}\right) (dx,dy,dz)参数化.为了生成3D anchor网格, ( t x , t y ) \left(t_{x}, t_{y}\right) (tx,ty)对在BEV中以0.5米的间隔进行采样,而 t z t_{z} tz是根据传感器在地平面上方的高度确定的。anchors的维度是通过对每个类的训练样本进行聚类来确定的。 BEV中没有3D点的anchors通过积分图像有效去除,每帧产生80-100K个非空anchors。
图4:[4]中提出的8角框编码、[15]中提出的轴对齐框编码和我们的4角框编码之间的视觉比较。
Extracting Feature Crops Via Multiview Crop And Resize Operations: 为了从视图特定的特征图中为每个anchor提取feature crops,我们使用裁剪和调整大小操作[17]。给定3D中的anchor,通过将anchor投影到BEV和图像特征图上来获得两个感兴趣的区域。然后使用相应的区域从每个视图中提取特征图crops,然后将其双线性调整为3×3以获得等长的特征向量。这种提取方法导致feature crops在两个视图中都遵守投影anchor的长宽比,提供了比Faster-RCNN最初使用的3×3卷积更可靠的feature crops。
通过1 × 1卷积层降维: 在某些场景中,需要区域proposal网络在GPU内存中保存100K anchors的feature crops。尝试直接从高维特征图中提取feature crops会给每个输入视图带来很大的内存开销。例如,假设32位浮点表示,从256维特征图中提取100K anchors的7 × 7 feature crops需要大约5gb(100000 × 7 × 7 × 256 × 4字节)的存储器。此外,用RPN处理这样的高维特征裁剪大大增加了它的计算需求。
受[18]中使用卷积核的启发,我们建议对每个视图的输出特征图应用1 × 1卷积核,作为一种有效的降维机制,学习选择对区域proposal生成的性能有很大贡献的特征。这将计算锚特定特征裁剪的内存开销减少了 D ~ × \tilde{D} \times D~×,允许RPN仅使用几兆字节的额外内存来处理数万个anchors的融合特征。
3D Proposal生成: 裁剪和调整大小操作的输出是来自两个视图的大小相等的feature crops,它们通过逐元素均值操作进行融合。大小为256的全连接层的两个任务特定分支[2]使用融合特征裁剪来回归轴对齐的目标proposal框并输出目标/背景“objectness”分数。3D框回归通过计算 ( Δ t x , Δ t y , Δ t z , Δ d x , Δ d y , Δ d z ) \left(\Delta t_{x}, \Delta t_{y}, \Delta t_{z}, \Delta d_{x}, \Delta d_{y}, \Delta d_{z}\right) (Δtx,Δty,Δtz,Δdx,Δdy,Δdz)、anchors和ground truth边界框之间的质心和尺寸差异来执行。Smooth L1损失用于3D框回归,交叉熵损失用于“objectness”。与[2]类似,在计算回归损失时会忽略背景anchors。背景anchors是通过计算anchors和ground truth边界框之间的BEV的2D IoU来确定的。对于汽车类,IoU小于0.3的anchors被认为是背景anchors,而IoU大于0.5的anchors被认为是目标anchors。对于行人和骑自行车的人,目标anchor IoU阈值降低到0.45。为了去除多余的proposals,在BEV中以0.8的IoU阈值的2D非极大值抑制(NMS)用于在训练期间保留前1024个proposals。在训练时,300个proposals用于汽车类,而1024个proposals用于行人和骑自行车的人。
D. 第二阶段检测网络(Second Stage Detection Network)
3D边界框编码: 在[4]中,Chen等人表明8角框编码比先前在[15]中提出的传统轴对齐编码提供了更好的结果。但是,8角编码不考虑3D边界框的物理约束,因为边界框的顶角被迫与底部的顶角对齐。为了减少冗余并保持这些物理约束,我们建议用四个角和两个高度值对边界框进行编码,这些值代表从传感器高度确定的与地平面的顶部和底部角偏移。因此,我们的回归目标是 ( Δ x 1 … Δ x 4 , Δ y 1 … Δ y 4 , Δ h 1 , Δ h 2 ) \left(\Delta x_{1} \ldots \Delta x_{4}, \Delta y_{1} \ldots \Delta y_{4}, \Delta h_{1}, \Delta h_{2}\right) (Δx1…Δx4,Δy1…Δy4,Δh1,Δh2),即从proposals和ground truth框之间的地平面的角和高度偏移。为了确定角点偏移量,我们将proposals的最近角点与BEV中ground truth框的最近角点对应起来。所提出的编码将框表示从超参的24维向量减少到10维向量。
显式方向向量回归: 为了确定3D边界框的方向,MV3D[4]依赖于估计的边界框的范围,其中方向向量被假定为在框的较长边的方向上。这种方法存在两个问题。首先,对于不总是遵守上述规则的检测目标(例如行人),此方法失败。其次,所得到的方向只有在 ± π ±π ±π弧度的附加常数范围内才能知道。方向信息丢失,因为在最近的角到角匹配中没有保留角顺序。图1展示了一个示例,说明相同的矩形边界框如何包含具有相反方向向量的目标的两个实例。我们的架构通过计算 ( x θ , y θ ) = ( cos ( θ ) , sin ( θ ) ) \left(x_{\theta}, y_{\theta}\right)=(\cos (\theta), \sin (\theta)) (xθ,yθ)=(cos(θ),sin(θ))来解决这个问题。这种方向向量表示隐含地处理角度环绕,因为每个 θ ∈ [ − π , π ] \theta \in[-\pi, \pi] θ∈[−π,π]都可以由BEV空间中的唯一单位向量表示。我们使用回归的方向向量从采用的四角表示中解决边界框方向估计中的歧义,因为实验发现这比直接使用回归方向更准确。具体来说,我们提取边界框的四种可能方向,然后选择最接近显式回归的方向向量的方向。
生成最终检测: 与RPN类似,多视图检测网络的输入是将proposals投影到两个输入视图中生成的feature crops。由于proposals的数量比anchors的数量低一个数量级,因此使用深度为 D ~ = 32 \tilde{D}=32 D~=32的原始特征图来生成这些feature crops。来自两个输入视图的裁剪被调整为7×7,然后与元素平均操作融合。一组大小为2048的三个全连接层处理融合的feature crops,以输出每个proposal的框回归、方向估计和类别分类。与RPN类似,我们采用了多任务损失,结合了边界框和方向向量回归任务的两个Smooth L1损失,以及分类任务的交叉熵损失。仅当proposals在BEV中具有至少0.65或0.55的2D IoU与汽车和行人/自行车类别的ground truth框时,才在评估回归损失时考虑proposals。为了消除重叠检测,使用NMS的阈值为0.01。
E.训练
我们训练了两个网络,一个用于汽车类,一个用于行人和自行车类。 RPN和检测网络以端到端的方式联合训练,使用包含一个图像的小批量分别具有512和1024个ROI。该网络使用ADAM优化器进行120K迭代训练,初始学习率为0.0001,每30K迭代以指数方式衰减,衰减因子为0.8。
V.结论
在这项工作中,我们提出了AVOD,一种用于自动驾驶场景的3D目标检测器。所提出的架构通过使用高分辨率特征提取器与多模态融合RPN架构相结合,与现有技术有所不同,因此能够为道路场景中的小类(small classes)生成准确的区域proposals。此外,所提出的架构采用显式方向向量回归来解决从边界框推断出的模糊方向估计。 在KITTI数据集上的实验表明,我们提出的架构在3D定位、方向估计和类别分类任务上优于现有技术。最后,所提出的架构被证明可以实时运行并且内存开销很低。
原文链接:https://arxiv.org/abs/1712.02294
参考文献
[1] A. Geiger, P . Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 3354–3361.
[2] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” in Advances in Neural Information Processing Systems 28, 2015, pp. 91–99.
[3] B. Li, T. Zhang, and T. Xia, “V ehicle detection from 3d lidar using fully convolutional network,” in Proceedings of Robotics: Science and Systems, AnnArbor, Michigan, June 2016.
[4] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Computer Vision and Pattern Recognition, 2017. CVPR 2017. IEEE Conference on,.
[5] T.-Y . Lin, P . Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Computer Vision and Pattern Recognition, vol. 1, no. 2, 2017, p. 4.
[6] X. Chen, K. Kundu, Y . Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun, “3d object proposals for accurate object class detection,” in NIPS, 2015.
[7] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, “Monocular 3d object detection for autonomous driving,” in Computer Vision and Pattern Recognition, 2016.
[8] B. Li, “3d fully convolutional network for vehicle detection in point cloud,” in IROS, 2017.
[9] Y . Zhou and O. Tuzel, “V oxelnet: End-to-end learning for point cloud based 3d object detection,” arXiv preprint arXiv:1711.06396, 2017.
[10] J. Lahoud and B. Ghanem, “2d-driven 3d object detection in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4622–4630.
[11] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” arXiv preprint arXiv:1711.08488, 2017.
[12] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” arXiv preprint arXiv:1612.00593, 2016.
[13] F. Chabot, M. Chaouch, J. Rabarisoa, C. Teulière, and T. Chateau, “Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[14] A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka, “3d bounding box estimation using deep learning and geometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[15] S. Song and J. Xiao, “Deep sliding shapes for amodal 3d object detection in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 808–816.
[16] K. Simonyan and A. Zisserman, “V ery deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[17] J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadarrama, and K. Murphy, “Speed/accuracy trade-offs for modern convolutional object detectors,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[18] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,” arXiv preprint arXiv:1602.07360, 2016.
[19] “Kitti 3d object detection benchmark,” http://www.cvlibs.net/datasets/ kitti/eval object.php?obj benchmark=3d, accessed: 2018-02-28.