基于OPENCV的手指个数识别
一个不知名大学生,江湖人称菜狗
original author: jacky Li
Email : [email protected]
Last edited: 2022.11.17

大佬绕路,这里菜狗
目录
环境:
效果展示:
逻辑原理:
介绍
原理
背景减法
移动侦测和阈值设定
轮廓提取
代码实现
执行代码
总结
环境:
- cv2
- imutils
- numpy
- sklearn
效果展示:

逻辑原理:
介绍
对于计算机视觉爱好者来说,手势识别是一个很酷的项目,因为它涉及一个直观的分步过程,可以很容易地理解,因此你可以在这些概念之上构建更复杂的东西。
长期以来,手势识别一直是计算机视觉社区中一个非常有趣的问题。这主要是因为从杂乱的背景中分割前景对象是一个具有挑战性的实时问题。最明显的原因是,当人类看图像和计算机看同一图像时,涉及语义差距。人类可以很容易地弄清楚图像中的内容,但对于计算机来说,图像只是三维矩阵。正因为如此,计算机视觉问题仍然是一个挑战。看看下面的图片。

此图像描述了语义分割问题,其目标是在图像中找到不同的区域并标记其相应的标签。
原理
背景减法
首先,我们需要一种有效的方法来区分前景和背景。为此,我们使用运行平均值的概念。我们让我们的系统查看特定场景 30 帧。在此期间,我们计算当前帧和前一帧的运行平均值。通过这样做,我们基本上告诉我们的系统—— 这是背景
在弄清楚背景之后,我们把手拿进来,让系统明白我们的手是进入背景的新入口,这意味着它变成了前景对象。但是,我们该如何单独去掉这个前景呢?答案是背景减法。
如果你想使用Python编码,请继续阅读。

在使用运行平均值计算出背景模型后,我们使用当前帧,除了背景之外,它还包含前景对象(在我们的例子中是手)。我们计算背景模型(随时间更新)和当前帧(有我们的手)之间的绝对差异,以获得包含新添加的前景对象(即我们的手)的差异图像。这就是背景减法的全部内容。
移动侦测和阈值设定
为了从这个差异图像中检测手部区域,我们需要对差异图像进行阈值设置阈值,以便只有我们的手部区域变得可见,而所有其他不需要的区域都被涂成黑色。这就是运动检测的全部意义所在。
轮廓提取
在对差异图像进行阈值处理后,我们在生成的图像中找到轮廓。假设面积最大的轮廓是我们的手。
代码实现
def run_avg(image, aWeight):
global bg
# initialize the background
if bg is None:
bg = image.copy().astype("float")
return
# compute weighted average, accumulate it and update the background
cv2.accumulateWeighted(image, bg, aWeight)接下来,我们有我们的函数,用于计算背景模型和当前帧之间的运行平均值。此函数接受两个参数 - 当前帧和aWeight,这就像对图像执行运行平均值的阈值。如果背景模型为None(即如果是第一帧),则使用当前帧对其进行初始化。然后,使用cv2.accumulateWeighted() 函数计算背景模型和当前帧的运行平均值。
def segment(image, threshold=25):
global bg
# find the absolute difference between background and current frame
diff = cv2.absdiff(bg.astype("uint8"), image)
# threshold the diff image so that we get the foreground
thresholded = cv2.threshold(diff, threshold, 255, cv2.THRESH_BINARY)[1]
# get the contours in the thresholded image
(_, cnts, _) = cv2.findContours(thresholded.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# return None, if no contours detected
if len(cnts) == 0:
return
else:
# based on contour area, get the maximum contour which is the hand
segmented = max(cnts, key=cv2.contourArea)
return (thresholded, segmented)我们的下一个函数用于从视频序列中分割手部区域。该函数接受两个参数 - 当前帧和用于阈值差异图像的阈值。
首先,我们使用cv2.absdiff() 函数找到背景模型和当前帧之间的绝对差异。
接下来,我们对差异图像进行阈值设置阈值,以仅显示手部区域。最后,我们对阈值图像进行轮廓提取,并获取面积最大的轮廓(即我们的手)。
我们将阈值图像以及分割图像作为元组返回。阈值设置背后的数学原理非常简单。如果x(n)x(n)表示输入图像在特定像素坐标处的像素强度,然后THRES HOLdTHRES HOLD决定我们将如何很好地将图像分割/阈值转换为二进制图像。
if __name__ == "__main__":
# initialize weight for running average
aWeight = 0.5
# get the reference to the webcam
camera = cv2.VideoCapture(0)
# region of interest (ROI) coordinates
top, right, bottom, left = 10, 350, 225, 590
# initialize num of frames
num_frames = 0
# keep looping, until interrupted
while(True):
# get the current frame
(grabbed, frame) = camera.read()
# resize the frame
frame = imutils.resize(frame, width=700)
# flip the frame so that it is not the mirror view
frame = cv2.flip(frame, 1)
# clone the frame
clone = frame.copy()
# get the height and width of the frame
(height, width) = frame.shape[:2]
# get the ROI
roi = frame[top:bottom, right:left]
# convert the roi to grayscale and blur it
gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# to get the background, keep looking till a threshold is reached
# so that our running average model gets calibrated
if num_frames < 30:
run_avg(gray, aWeight)
else:
# segment the hand region
hand = segment(gray)
# check whether hand region is segmented
if hand is not None:
# if yes, unpack the thresholded image and
# segmented region
(thresholded, segmented) = hand
# draw the segmented region and display the frame
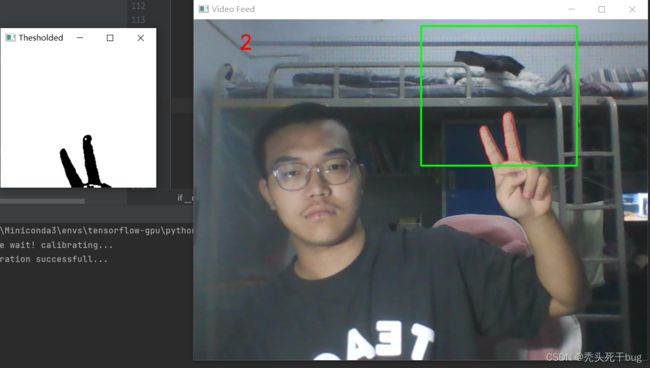
cv2.drawContours(clone, [segmented + (right, top)], -1, (0, 0, 255))
cv2.imshow("Thesholded", thresholded)
# draw the segmented hand
cv2.rectangle(clone, (left, top), (right, bottom), (0,255,0), 2)
# increment the number of frames
num_frames += 1
# display the frame with segmented hand
cv2.imshow("Video Feed", clone)
# observe the keypress by the user
keypress = cv2.waitKey(1) & 0xFF
# if the user pressed "q", then stop looping
if keypress == ord("q"):
break
# free up memory
camera.release()
cv2.destroyAllWindows()上面的代码示例是我们程序的主要功能。我们将权重初始化为 0.5。如运行平均值方程中的 eariler 所示,此阈值意味着如果为此变量设置较低的值,则将在较多的前几帧上执行运行平均值,反之亦然。我们使用 cv2 引用我们的网络摄像头。视频捕获(0),这意味着我们在计算机中获取默认的网络摄像头实例。
我们将尝试最小化识别区域(或区域),而不是从整个视频序列中识别手势,系统必须在其中寻找手部区域。为了突出这个区域,我们使用cv2.rectangle()函数,它需要顶部,右侧,底部和左侧像素坐标。
为了跟踪帧数,我们初始化一个变量num_frames。然后,我们开始一个无限循环,并使用camera.read()函数从我们的网络摄像头读取帧。然后,我们将输入帧的大小调整为 700 像素的固定宽度,以保持imutils库的纵横比,并翻转帧以避免镜像视图。
接下来,我们只取出感兴趣的区域(即识别区域),使用简单的NumPy切片。然后,我们将该ROI转换为灰度图像,并使用高斯模糊来最小化图像中的高频分量。直到我们超过30 帧,我们继续将输入帧添加到我们的run_avg函数并更新我们的背景模型。请注意,在此步骤中,必须保持相机不动。否则,整个算法都会失败。
更新背景模型后,将当前输入帧传递到分割函数中,返回阈值图像和分割图像。分割的轮廓使用cv2.drawContours() 在帧上绘制,阈值输出使用cv2.imshow() 显示。
最后,我们在当前帧中显示分割的手部区域,并等待按键退出程序。请注意,我们在此处将bg变量维护为全局变量。这很重要,必须加以处理。
执行代码
注意:请记住通过保持相机静止而不移动来更新背景模型。5-6秒后,在识别区露出你的手,只露出你的手部区域。下面您可以看到我们的系统如何有效地从实时视频序列中分割手部区域。

总结
在本实验中,运用了背景减法、运动检测、阈值化和轮廓提取,以使用 OpenCV 和 Python 从实时视频序列中很好地分割手部区域。
如果需要代码,请私聊博主,博主看见回。
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……