第三章 k近邻法
文章目录
- 基本概况
- KNN算法
- k近邻模型
-
- 模型
- 距离度量
- k值的选择
- 分类决策规则
- k近邻法的实现:kd树
-
- 构造kd树
- 搜索kd树
基本概况
KNN是一种基本的分类和回归方法。该文只讨论分类问题中的KNN。
KNN的输入为实例的特征向量,输出为实例的类别,可以取多类。
k值的选择、距离的度量以及分类决策规则是k近邻法的三个基本要素。
KNN算法
算法3.1:
输入:训练数据集T,其中 x i ∈ X x_i\in\mathbb{X} xi∈X为实例向量, y i ∈ Y = { c 1 , c 2 , . . . c K } y_i\in\mathbb{Y}=\{c_1,c_2,...c_K\} yi∈Y={c1,c2,...cK}为实例的类别;实例特征向量 x x x;
输出:实例 x x x所属的类 y y y;
步骤:
- 根据给定的距离度量,在训练集T中找出与 x x x最邻近的 k k k个点,涵盖这个 k k k个点的 x x x的邻域记作 N k ( x ) N_k(x) Nk(x);
- 在 N k ( x ) N_k(x) Nk(x)中根据分类决策规则(如多数表决)决定 x x x的类别 y y y: y = arg max c j ∑ x i ∈ N k ( x ) I ( y i = c j ) , i = 1 , 2 , . . , N ; j = 1 , 2 , . . . , K y=\argmax_{c_j}\sum_{x_i\in N_k(x)}I(y_i=c_j),i=1,2,..,N;j=1,2,...,K y=cjargmaxxi∈Nk(x)∑I(yi=cj),i=1,2,..,N;j=1,2,...,K
其中, I I I为指示函数。
当 k = 1 k=1 k=1时,称为最近邻算法。 k k k近邻算法没有显式的学习过程。
k近邻模型
模型
k近邻法使用的模型实际上对应于对特征空间的划分。
k近邻法中,当训练集、距离度量、k值及决策规则确定后,对于任何一个新的输入实例,它所属的类是唯一地确定的。
这相当于将特征空间划分为一些子空间,确定子空间里每个点所属的类。特征空间中,对每个训练实例点 x i x_i xi,距离该点比其他点更近的所有一个区域,称为单元。每个训练实例点拥有一个单元,所有的训练实例点构成了对特征空间的一个划分。
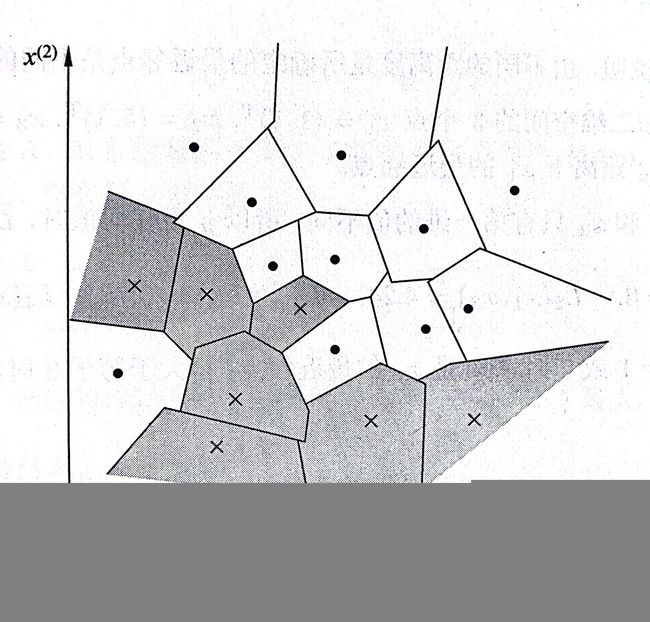
距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反应。一般采用欧式距离,但也可以采用其他的距离。
L p L_p Lp距离:假设特征空间为 n n n维实属向量空间,结果定义为: L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i,x_j)=(\sum_{l=1}^n|x_i^{(l)}-x_j^{(l)}|^p)^{\frac{1}{p}} Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1
当 p = 2 p=2 p=2时,称为欧式距离。
当 p = 1 p=1 p=1时,称为曼哈顿距离。
当 p = ∞ p=∞ p=∞时, L ∞ ( x i , x j ) = max l ∣ x i ( l ) − x j ( l ) ∣ L_{∞}(x_i,x_j)=\max_{l}|x_i^{(l)}-x_j^{(l)}| L∞(xi,xj)=maxl∣xi(l)−xj(l)∣,即各个坐标距离的最大值。

k值的选择
k值的选择对k近邻的结果产生重大影响。
如果选择较小的k值相当于用较小的邻域中的训练实例进行预测,优点是:“学习”的近似误差会减小,只有与输入实例较近的训练实例才会对预测结果起作用。缺点是:“学习”的估计误差会增大,预测结果会对近邻的实例点非常敏感,如果近邻点恰巧是噪声,预测结果就会是错误。
k值的减小意味着整体模型变得复杂,容易发生过拟合(近似误差减小,估计误差增大)。
如果选择较大的k值相当于用较大领域中的训练实例进行预测,优点是:“学习”的估计误差减小,“缺点”是近似误差增大。此时,与测试实例不相似的训练实例也会对预测起作用,使预测发生错误。
k值的增大意味着整体模型变得简单。
极端情况下,用 k = N k=N k=N,相当于简单地预测训练实例中较多的类。这完全忽略了实例中大量的有用信息。
一般通过交叉验证法来确定k值。
这有点感觉是听从少数几个关键人的意见,经过深思熟虑后得到答案;或者听从很多很多人的意见,不过脑子,按照提的最多的建议来。
分类决策规则
分类决策规则往往是多数表决。
其解释为:如果分类损失函数为0-1损失函数,其分类函数为: f : R n → { c 1 , c 2 , . . . , c K } f:R^n\to \{c_1,c_2,...,c_K\} f:Rn→{c1,c2,...,cK}
那么误分类的概率是:
P ( Y ≠ f ( X ) ) = 1 − P ( Y = f ( X ) ) P(Y\not=f(X))=1-P(Y=f(X)) P(Y=f(X))=1−P(Y=f(X))
模型的误分类率为 1 k ∑ x i ∈ N k ( x ) I ( y i ≠ c j ) = 1 − 1 k ∑ x i ∈ N k ( x ) I ( y i = c j ) \frac{1}{k}\sum_{x_i\in N_k(x)}I(y_i\not=c_j)=1-\frac{1}{k}\sum_{x_i\in N_k(x)}I(y_i=c_j) k1xi∈Nk(x)∑I(yi=cj)=1−k1xi∈Nk(x)∑I(yi=cj)
要使误分类率最小即经验风险最小,就要使 ∑ x i ∈ N k ( x ) I ( y i = c j ) \sum_{x_i\in N_k(x)}I(y_i=c_j) ∑xi∈Nk(x)I(yi=cj)最大,所以多数表决规则等价于经验风险最小化(这是在损失函数设为01损失函数的基础上)。
意思是说,我没有训练阶段,但是在测试阶段我遵循着策略(经验风险最小化,虽然不是训练数据集)。
k近邻法的实现:kd树
主要考虑的问题是如何对训练数据进行快速k近邻搜索。这点在特征空间的维数大及训练数据容量大时尤其必要。
最简单的实现方式是线性扫描,将输入实例与每一个训练实例做一个计算。当数据集很大时十分耗时。
采用kd树可以减少距离的计算次数。
构造kd树
kd树是二叉树,表示对k维空间的一个划分。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列k维超矩形区域。kd树的每一个节点对应于一个k维超矩形区域。
算法3.2:
输入: k k k维空间数据集 T = { x 1 , x 2 , . . . , x N } T=\{x_1,x_2,...,x_N\} T={x1,x2,...,xN},其中 x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( k ) ) T , i = 1 , 2 , . . . , N x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(k)})^T,i=1,2,...,N xi=(xi(1),xi(2),...,xi(k))T,i=1,2,...,N
输出kd树。
(1)开始:构造根节点,根节点对应于包含T的k维空间的超矩形区域。
1.1 选择 x ( 1 ) x^{(1)} x(1)为坐标轴,以T中所有实例的 x ( 1 ) x^{(1)} x(1)坐标的中位数为切分点,将根节点对应的超矩形区域切分为两个子区域。切分通过切分点并与坐标轴 x ( 1 ) x^{(1)} x(1)垂直的超平面实现。
1.2 由根节点生成深度为1的左右子节点:左子节点对应坐标 x ( 1 ) x^{(1)} x(1)小于切分点的子区域,右子节点对应坐标 x ( 1 ) x^{(1)} x(1)大于切分点的子区域。将落在切分超平面上的实例点保存为根节点。
(2)重复:
2.1 对深度为j的节点,选择 x ( l ) x^{(l)} x(l)为切分的坐标轴, l = j ( m o d k ) + 1 l=j(mod~k)+1 l=j(mod k)+1,以该节点的区域中的所有实例的 x ( l ) x^{(l)} x(l)坐标的中位数为切分点,将该节点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 x x x{(l)}$垂直的超平面实现。
2.2 由该节点生成两个深度为 j + 1 j+1 j+1的节点。其落在切分超平面的实例点保存在该节点。
(3)直到两个子区域没有实例存在为止。
import numpy as np
class binaryTreeNode:
def __init__(self,element=None):
self.element = element
self.leftChild = None
self.rightChild = None
T = [(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)]
d = 2
length = len(T)
kdTree = np.full((length,2),-1)
root = binaryTreeNode()
def create_kdtree(level,l,seq,position,parent):
if(l==0):
return
idx = level % d
seq = sorted(seq,key=lambda x:x[idx])
instance_idx = int(l/2)
instance_point = seq[instance_idx]
left_seq = seq[:instance_idx]
right_seq = seq[instance_idx+1:]
del T[instance_idx]
node = binaryTreeNode(instance_point)
if position==0:
parent.element = instance_point
node = parent
elif position == -1:
parent.leftChild = node
elif position == 1:
parent.rightChild = node
create_kdtree(level+1,len(left_seq),left_seq,-1,node)
create_kdtree(level+1,len(right_seq),right_seq,1,node)
def pre_order(node,level):
print(node.element,level)
if(node.leftChild!=None): pre_order(node.leftChild,level+1)
if(node.rightChild!=None): pre_order(node.rightChild,level+1)
return
create_kdtree(0,length,T,0,root)
pre_order(root,0)
'''
(7, 2) 0
(5, 4) 1
(2, 3) 2
(4, 7) 2
(9, 6) 1
(8, 1) 2
'''

搜索kd树
以最近邻为例加以叙述。
算法3.3(用kd树的最近邻搜索):
输入:已构造的kd树,目标点 x x x;
输出: x x x的最近邻。
- 在kd树中找出包含目标点 x x x的叶节点:从根节点出发,递归向下访问kd树。若目标点 x x x当前维的坐标小于切分点的坐标,则移动到左子节点,否则移动到右子节点,知道子节点为叶节点为止;
- 以此叶节点为“当前最近点”;
- 递归地向上回退,在每个结点进行以下操作:
(a)如果该节点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”;
(b)当前最近点一定存在于该结点一个子节点对应的区域。检查该子节点的父节点的另一子节点对应的区域是否有更近的点。具体来说,检查另一子节点是对应的区域是否与以目标点为球心,以目标点与“当前最近点”间的距离为半径的超球体相交。如果相交,移动到另一子节点进行递归搜索。反之向上回退。 - 当回退到根节点时,搜索结束。最后的“当前最近点”即为x的最近邻点。
也就是说,每到一个节点,先看这个节点本身和目标点近不近,再看节点的子节点所在的区域和目标点构成的圆相不相交。这是一个向上和向下都有可能的算法。
这样的话搜索的平均复杂度就下降到了 O ( log N ) O(\log N) O(logN)。
切记把每个点看成一个区域的代表,代表的是其左右两个区域的合并。