一文尽览 | 基于点云、多模态的3D目标检测算法综述!(Point/Voxel/Point-Voxel)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
目前3D目标检测领域方案主要包括基于单目、双目、激光雷达点云、多模态数据融合等方式,本文主要介绍基于激光雷达雷达点云、多模态数据的相关算法,下面展开讨论下~
3D检测任务介绍
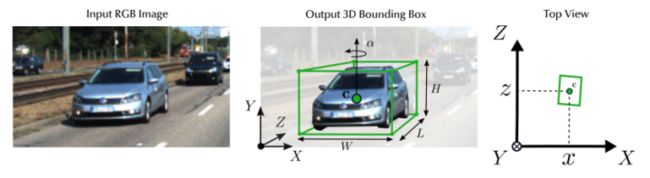
3D检测任务一般通过图像、点云等输入数据,预测目标相比于相机或lidar坐标系的[x,y,z]、[h,w,l],[θ,φ,ψ](中心坐标,box长宽高信息,相对于xyz轴的旋转角度)。
3D检测相关数据集
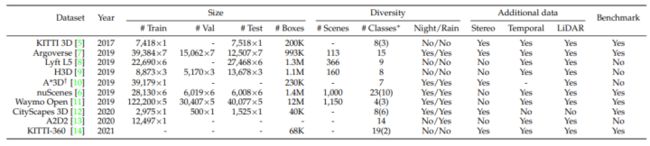
下面汇总了领域常用的3D检测数据集,共计11种:
KITTI-3D: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
Argoverse:https://www.argoverse.org/data.html#download-link
Lyft L5:https://level-5.global/download/
H3D:https://usa.honda-ri.com//H3D
A*3D:https://github.com/I2RDL2/ASTAR-3D
nuScenes:https://www.nuscenes.org/nuscenes#download
Waymo Open:https://waymo.com/open/download/
CityScapes-3D:https://www.cityscapes-dataset.com/downloads/
A2D2:https://www.a2d2.audi/a2d2/en/download.html
KITTI-360:http://www.cvlibs.net/datasets/kitti-360/download.php
Rope3D:https://thudair.baai.ac.cn/rope
3D检测在数据格式上的分类
基于激光雷达点云
基于point
PointRCNN
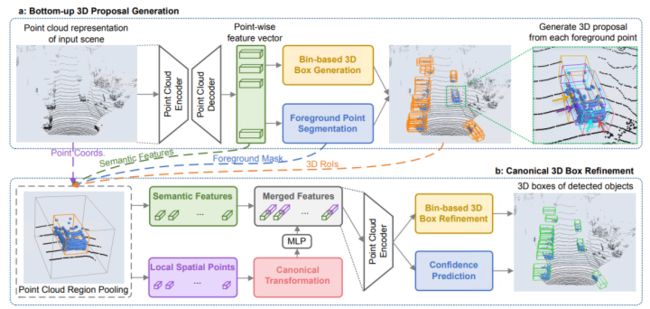
基于Point系列的3D点云检测器一般逐点检测采样,PointRCNN是领域中比较经典的一篇文章,基于原始密集点云数据直接进行特征提取和RPN操作。论文使用PointNet++网络实现前景与背景分割,主要分为两个阶段。第一阶段生成一大堆很冗余的bounding box。首先,对点云语义分割,对每个点的到一个预测label,比如现在:对所有判断是“车”的点(也叫做前景点),赋予label=1,其他点(也叫做背景点),赋予label=0。然后,用所有前景点生成bounding box,一个前景点对应一个bounding box,但是必须要保证语义分割结果的准确。作者使用了一些去除冗余的方法,继续减少bounding box的数目,这一阶段结束的时候只留下300个bounding box。第二阶段继续优化上一阶段生成的bounding box。首先,对前一阶段生成的bounding box做旋转平移,把这些bounding box转换到自己的正规划坐标系下(canonical coordinates)。然后通过点云池化等操作的到每个bounding box的特征,再结合第一阶段的到的特征,进行bounding box的修正和置信度的打分,从而的到最终的bounding box。网络结构如下所示(结果也是当年的SOTA!):
3DSSD
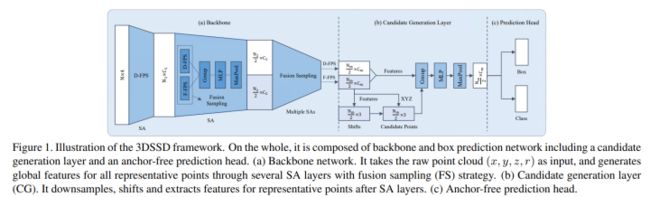
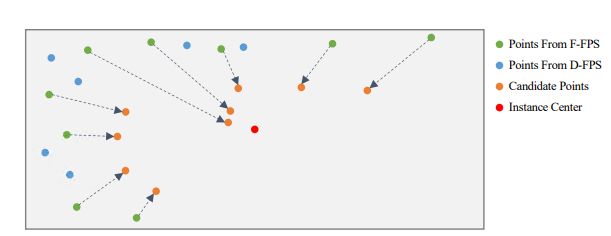
3DSSD作者提出像PointRCNN这种基于原始点云的二阶段3D检测方法,在第一阶段往往利用Set Abstraction层(SA)进行不断的下采样、分组与特征提取,然后利用Feature Propagation层(FP)对SA的输出进行不断上采样与特征传播。利用语义分割获得了前景点后,这些方法以每个前景点为中心进行3D检测框的提议(第一阶段的粗提议)。粗提议结束后,对这些粗提议检测框内部点进行特征提取与处理,微调检测框,获得更精确的检测框(第二阶段的精炼过程)。然而上述的二阶段方法中的FP层和精炼过程在模型前向推理过程中往往会消耗一半以上的时间。那简单地将这些模块删除后(只剩下SA层),然后基于SA提取的特征直接进行单阶段提议是否可行?事实证明有人确实这么做了,但是该简单直接的方法造成了检测精度降低了不少。可能的原因有:现有一些方法在SA层的下采样步骤中用到了D-FPS方法(基于距离的最远点采样法)。该采样方法的特点是:以空间距离最大为原则,不断迭代采样场景的点云,采样后的点云基本覆盖了整个场景(避免了随机采样对密度较高点云簇的青睐)。因为场景中背景点数量偏多,且有些较远目标中的前景点较少,这样的采样方式几乎会过滤掉距离较远的物体的所有前景点。前景点都过滤完了,检测精度自然不会高到哪儿去。因此,作者希望有一个采样方式使得采样的点(记做representative points)既能铺满整个采样空间,又能尽可能地包含更多的前景点,也就是论文中的F-FPS。3DSSD,在精度和效率之间实现了良好的平衡,比前期基于点的检测算法速度提升近1倍,也超越了当时的单阶段所有基于voxel的方法!
Fast PointRCNN
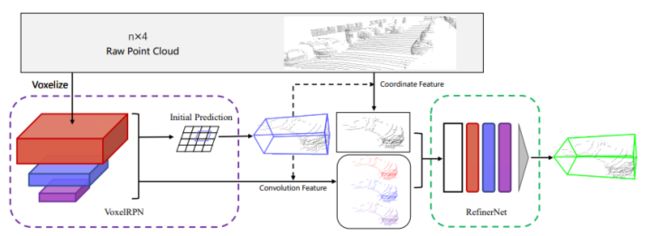
Fast PointRCNN是PointRCNN的改进版,但是一种point-voxel方式检测器(为了方便先放置在这里一起讲了),PointRCNN在第一阶段太慢了,又是前景分割,又是前景点的RPN回归。Fast PointRCNN作者直接利用基于Voxel的数据处理方式进行点云结构化,然后利用三维卷积和二维卷积的堆叠实现Voxel特征的提取。(全三维卷积可以保留Z轴的信息,但是效率会比较低,因为运算量大。全二维卷积直接就忽略了Z轴的信息了,虽然速度快,但是精度也受到了影响。所以作者采用这种“三维卷积-二维卷积”的网络结构,先利用“三维卷积”保留Z轴的信息,然后为了提高效率,采用了"二维卷积”进行特征提取。实验表明,这种方式确实可以提高效率,而且精度也不会降低。)在基于图片的2D物体检测任务中,通常利用特征金字塔(FPN)的网络结构实现大小不同物体的proposal。YOLO V3的一个特点就是在三个不同尺度的特征图中,分别放置负责检测不同大小物体的预设框Anchor。底层的特征因为感受野小,负责小物体检测,因此放置较小的Anchor。反之,顶层的特征因感受野较大,负责大的物体的检测任务,因此放置较大的Anchor。受启于此,FastPointRCNN的作者也选择了这样的方式实现了对不同大小物体的同时检测,提出了一种叫做VoxelRPN的网络,实现第一阶段的候选框粗略提议。第一阶段完成proposal后,然后引入RefinerNet完成第二阶段的优化!网络流程如下图所示:
Lidar RCNN
Lidar RCNN是一个两阶段检测器,通常可以改进任何现有的3D检测器(无需re-training)。为了在实践中满足实时性和高精度要求,论文采用了基于点(point)的方法,而不是流行的基于voxel的方法。但是论文在以前的工作中发现了一个被忽视的问题:天真地应用基于PointNet的基于点的方法可能会使学习到的特征忽略proposals的尺度。为此,论文详细分析此问题,并提出几种补救方法,以带来显著的性能改进,论文给出了性能和耗时分析,综合性能突出!
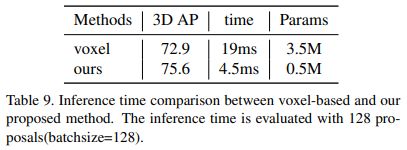
IA-SSD
IA-SSD是CVPR2022最新提出的网络,论文针对三维激光雷达点云的有效目标检测问题开展了研究,为了减少内存和计算成本,现有的基于point的pipeline通常采用任务无关随机采样或最远点采样来逐步向下采样输入pointset,然而并非所有点对目标检测任务都同等重要。对于detector来说,前景点本质上比背景点更重要。基于此,论文提出了一种高效的单级基于point的3D目标检测器,称为IA-SSD。IA-SSD利用两种可学习的,面向任务、实例感知的下采样策略来分层选择属于感兴趣对象的前景点。此外,还引入了上下文质心感知模块,以进一步估计精确的实例中心。最后,为了提高效率,论文按照纯编码器架构构建了IA-SSD。在多个大规模检测benckmark上进行的实验证明了IA-SSD的优势。由于低内存占用和高度并行性,在KITTI数据集上单个RTX2080Ti GPU实现了每秒80多帧的速度。
基于Voxel
VoxelNet
基于Voxel的方法是领域研究热点,近年来也有非常多的paper,VoxelNet是开山之作,苹果公司提出!论文将三维点云划分为一定数量的Voxel,经过点的随机采样以及归一化后,对每一个非空Voxel使用若干个VFE(Voxel Feature Encoding)层进行局部特征提取,得到Voxel-wise Feature,然后经过3D Convolutional Middle Layers进一步抽象特征(增大感受野并学习几何空间表示),最后使用RPN(Region Proposal Network)对物体进行分类检测与位置回归。VoxelNet整个pipeline如下图所示:

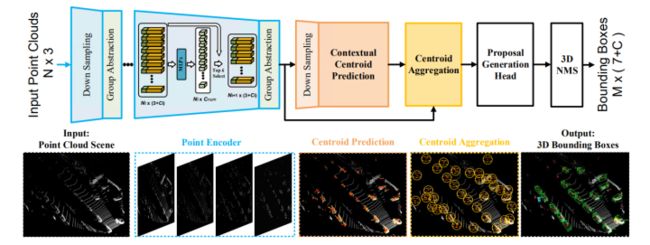
SECOND
VoxelNet思路比较好,但速度上优势不大!SECOND全称为Sparsely Embedded Convolutional Detection,也就是稀疏卷积,SECOND的出现,让实时检测更近一步!考虑到VoxelNet通过Feature Learning Network后获得了稀疏的四维张量,而采用3D卷积直接对这四维的张量做卷积运算的话,确实耗费运算资源,SECOND作为VoxelNet的升级版,用稀疏3D卷积替换了普通3D卷积,如下图所示。
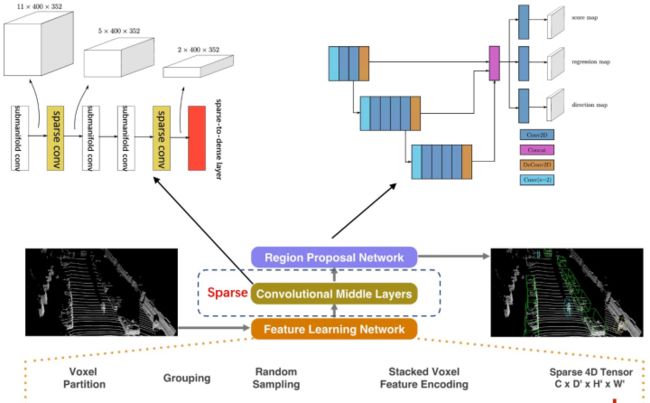
PointPillars
PointPillars是2019年出自工业界的一篇Paper,意义很大,该模型最主要的特点是检测速度和精度的平衡,平均检测速度达到了62Hz,最快速度达到了105Hz,遥遥领先了其它的模型(也是目前落地较多的方案)。论文提出了一种新的点云编码方法用于给PointNet提取点云特征,再将提取的特征映射为2D伪图像以便用2D目标检测的方式进行3D目标检测。尽管只使用激光雷达,但PointPillars在3D和鸟瞰KITTI基准方面,甚至在融合方法中,都显著优于最新技术,模型结构如下图所示:
Part-A2
Part-A2将PointRCNN扩展到一个新的、强大的基于点云的三维对象检测框架,即部件感知和聚合神经网络(part-A2网络),整个框架由部件感知阶段和部件聚合阶段组成。部件感知阶段利用3D GT bbox提供的信息,生成3D 分割的标注信息,分割前景点和背景点;对于所有的前景点,估计每一个前景点的相对位置(intra-object part location,认为该信息隐式编码3D目标的形状);从原始点云生成3D proposals(包括anchor-free和anchor-based两种方法)。部件聚合阶段对于不同的proposals可能具有相同的点云信息,产生相同的特征带来的模糊性的问题,论文提出ROI-aware点云池化方案,它保留非空和空体素的所有信息,以消除点云池化方案的模糊性。利用空体素对bbox的几何图形信息进行编码,提升bbox的re-score和位置refine的性能。除此之外,进一步利用稀疏卷积和稀疏池化操作,逐步聚合每个3D proposals的池化后的part feature,实现准确预测;Part-A2网络优于当年所有的3D检测方法(仅利用激光雷达点云数据),在KITTI 3D目标检测数据集上实现了SOTA。
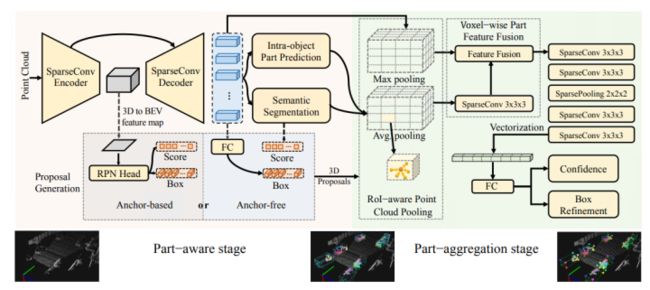
CIA-SSD
CIA-SSD这篇文章以SECOND为Backbone提出了一种基于体素的一阶段目标检测模型,其基本思想是校准单步目标检测中分类和定位两个任务,提出Confident IoU-Aware Single-Stage object Detector (CIA-SSD)。第一个是Spatial-Semantic Feature Aggregation(SSFA)模块,为了准确预测目标框和分类置信度,自适应地融合低端spatial feature和高端抽象semantic feature。而第二个是IoU-aware confidence rectification模块,对置信度进一步校准(rectified),使其和定位精度更加一致。最后采用Distance-variant IoU-weighted NMS获得更平滑的回归并避免冗余预测。
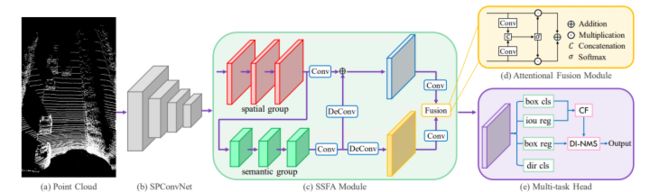
SE-SSD
SE-SSD提出了Self-Ensembling single-stage目标检测器(SE-SSD),在户外点云中进行精确检测,其关注点是利用soft(teacher模型预测的)和hard(标注信息)的目标以及制定的约束来共同优化模型,且不在推理中引入额外计算。具体地说,SE-SSD包含一对teacher和student的SSD,并设计了一个有效的IOU-based的匹配策略来过滤teacher的soft目标,并制定一致性损失来使student的预测与它们保持一致。此外,为了最大限度地运用teacher的蒸馏知识,设计了一种新的数据增强方案来产生形状感知的增强样本来训练student SSD,以推断完整的目标形状。最后,为了更好地利用hard目标,还设计了一个ODIoU损失来监督约束预测的box中心和方向的student,速度可达30.56ms。
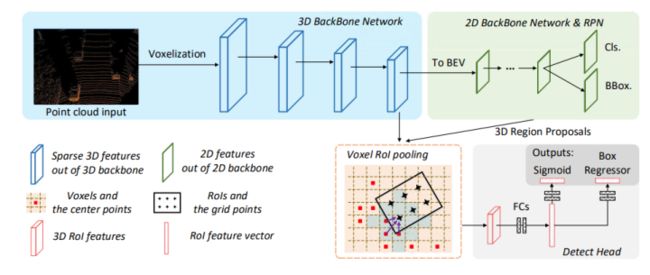
Voxel-RCNN
Voxel-RCNN指出一般point-based精度高但特征计算量大,voxel-based结构更适合特征提取,但精度下降;作者认为,点云数据的精确定位并不需要,而粗voxel粒度也能产生充分检测精度。论文提出的Voxel R-CNN是一个两步法,仍然达到和当前point-based方法可比的检测性能,但计算量降低较多。Voxel R-CNN主要包括3D主干网络,2D BEV RPN和检测头,其中提出的voxel ROI pooling负责从voxel特征中提取ROI特征。如下图所示,通过3D backbone提取3D特征,然后映射到BEV空间,生成proposal,通过Voxel ROI Pooling方式提取特征做优化。与现有的基于体素的方法相比,Voxel R-CNN提供了更高的检测精度,同时保持了实时帧处理速率,在NVIDIA RTX 2080 Ti GPU帧率为25!
CenterPoint
CenterPoint是Center-based系列工作(CenterNet、CenterTrack、CenterPoint)的扩展,于2020年作者在arxiv公开了第一版CenterPoint,后续进一步将CenterPoint扩充成了一个两阶段的3D检测追踪模型,相比单阶段的CenterPoint,性能更佳,额外耗时很少。本文的主要贡献是提出了一个两阶段的Center-based的目标检测追踪模型,在第一阶段(如下图中的a,b,c),使用CenterPoint检测三维目标的检测框中心点,并回归其检测框大小,方向和速度。在第二阶段(如下图中的d)设计了一个refinement模块,对于第一阶段中的检测框,使用检测框中心的点特征回归检测框的score并进行refinement。在nuScenes的3D检测和跟踪任务中,单阶段的CenterPoint效果很好,单个模型的NDS为65.5,AMOTA为63.8。模型性能很好,但是论文中说该模型的速度是在Waymo上11FPS,在nuScenes上为16FPS;同时模型的速度实验是在TiTan RTX上做的,也就是在所有边缘计算设备上均达不到实时计算。
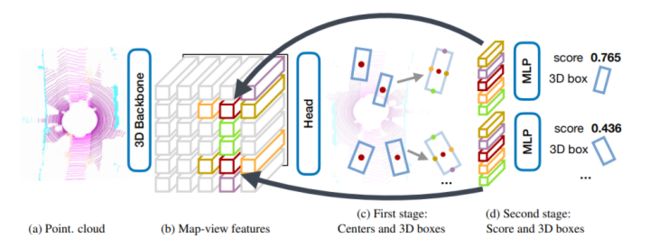
基于Point-Voxel
PV-RCNN
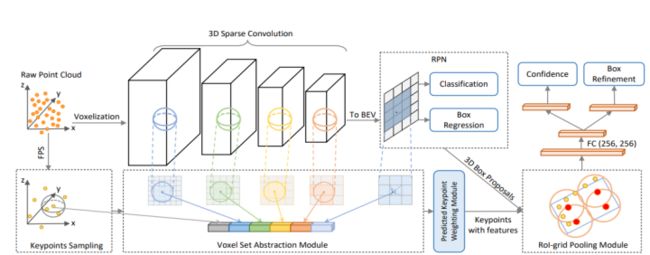
基于Point-Voxel方法是介于point-based和voxel-based之间的一种方式。PV-RCNN是首个经典point-based和voxel-based结合的网络,论文提出了Voxel Set Abstraction操作,将Sparse Convolution主干网络中多个scale的sparse voxel及其特征投影回原始3D空间,然后将少量的keypoint (从点云中sample而来) 作为球中心,在每个scale上去聚合周围的voxel-wise的特征。这个过程实际上结合了point-based和voxel-based两种点云特征提取的结构,同时将整个场景的multi-scale的信息聚合到了少量的关键点特征中,以便下一步的RoI-pooling。论文还提出了Predicted Keypoint Weighting模块,通过从3D标注框中获取的免费点云分割标注,来更加凸显前景关键点的特征,削弱背景关键点的特征。除此之外,论文还设计了更强的点云3D RoI Pooling操作,也就是论文提出的RoI-grid Pooling: 与前面不同,每个RoI里面均匀的sample一些grid point,然后将grid point当做球中心,去聚合周围的keypoint的特征。通过Voxel-to-keypoint与keypoint-to-grid这两个point-voxel特征交互的过程,显著增强了PV-RCNN的结构多样性,使其可以从点云数据中学习更多样性的特征,来提升最终的3D检测性能。算法在仅使用LiDAR传感器的setting下,在自动驾驶领域Waymo Open Challenge点云挑战赛中取得了(所有不限传感器算法榜单)三项亚军、Lidar单模态算法三项第一的成绩,以及在KITTI Benchmark上保持总榜第一的成绩超过半年。
SA-SSD
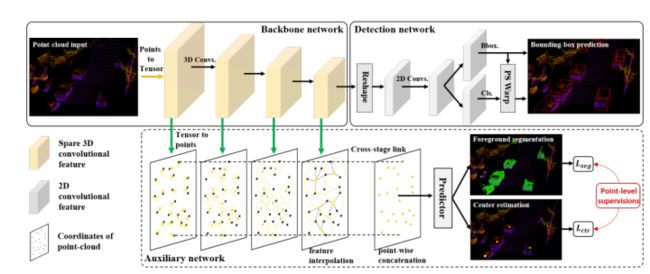
SA-SSD将二阶段方法独有精细回归运用在一阶段的的检测方法上,为此作者采用了SECOND作为backbone,添加了两项附加任务,使得backbone具有structure aware的能力,定位更加准确,如下图所示,辅助头参与训练,推理阶段可以消除!
PV-RCNN++
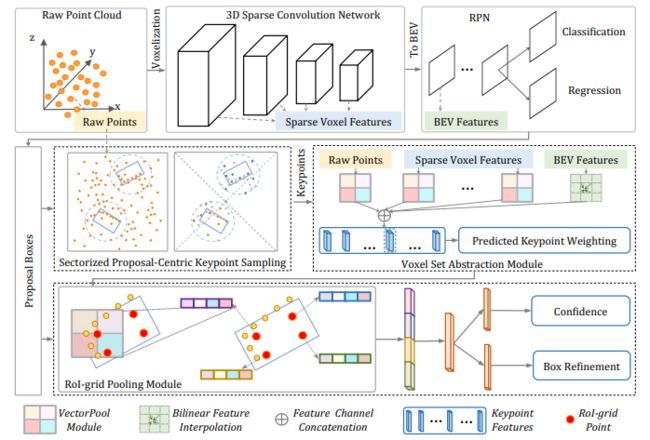
PV-RCNN++提出了基于点体素区域的卷积神经网络,用于从点云中检测三维目标。首先,论文提出了一种新的三维检测器,它包括两个步骤:体素到关键点场景编码和关键点到网格RoI特征提取。这两个步骤将3D体素CNN与基于PointNet的集合抽象深度集成,以提取判别特征。除此之外,还提出了一个先进的框架PV-RCNN++,用于更有效和准确的3D对象检测。它包括两个主要的改进:一个是分区化的以提案为中心的策略,用于高效地生成更多代表性的关键点;另一个是矢量池聚合,用于以更少的资源消耗更好地聚合局部点特征。通过这两种策略,PV-RCNN++比PV-RCNN快两倍以上,同时在检测范围为150m×150m的大规模Waymo开放数据集上也实现了更好的性能。此外,提出的PV-RCNN在Waymo开放数据集和高度竞争的KITTI基准上都实现了最先进的3D检测性能。
基于多模态数据
基于多模态方法主要是结合点云、图像、深度图、range图等其中的两种或者多种来完成3D检测,性能一般要比单模态数据好。
MV3D
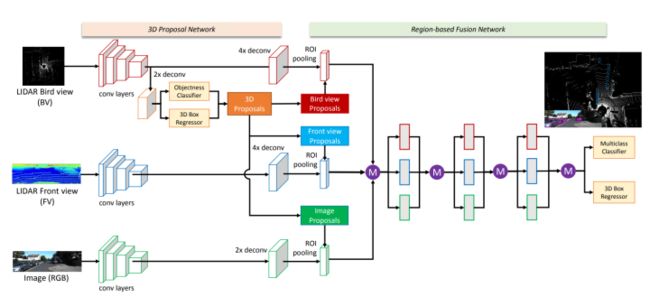
3D点云数据的一些主要问题可以体现在其稀疏性、无序性、冗余性三个方面。对于稀疏性,现有的一些方法喜欢引入体素(Voxel)进行三维空间的划分,然后将稀疏、无序,分布不均匀的点云数据分配于不同的体素,接着利用MLP、卷积、池化等操作实现对体素(点云)进行特征提取,很明显这种方法会引入大量的计算量。考虑到这一点,MV3D并没有使用类似的方法,而是将点云数据和图片数据映射到三个不同的维度进行特征融合,然后进行物体的定位和识别。这三个维度分别为:点云的BEV图、点云的前视图以及RGB图。MV3D结构如下图所示,输入为BEV和FV以及RGB图,在BEV分支申城3D proposal,然后送入到三个分支上,最后通过ROI pooling提取特征,然后汇总三个分支特征,进行分类和回归!相比于同时代的方法,KITTI上SOTA!
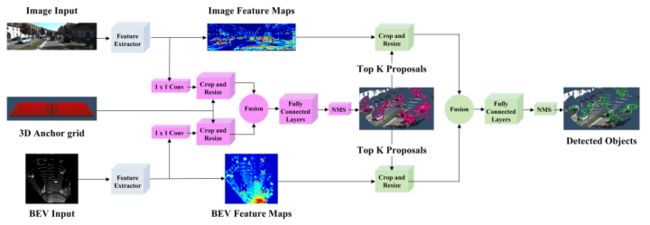
AVOD
AVOD输入RGB图像以及BEV(Bird's Eye View) Map,利用FPN网络得到二者全分辨率的feature map,然后通过crop&resize提取两个feature map对应的feature crop并融合,最后挑选出3D proposal以实现3D物体检测,整个过程是two-stage detection,可以理解为MV3D的加强版。相比于MV3D最大改进是3D RPN,MV3D使用的是微调的VGG16,同时做了一些操作(upsampling+remove some pooling layer),使得最终的feature map相对于input是 8x downsampling ;而AVOD使用的是FPN,包含了encoder和decoder,在保证最终的feature map相对于input是full-resolution的同时,并且还结合了底层细节信息和高层语义信息,因此能显著提高物体特别是小物体的检测效果。同时期来说,速度快,但性能未有非常大优势!
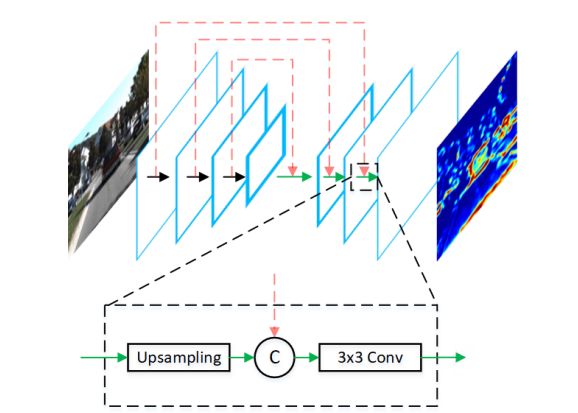
MVXNet
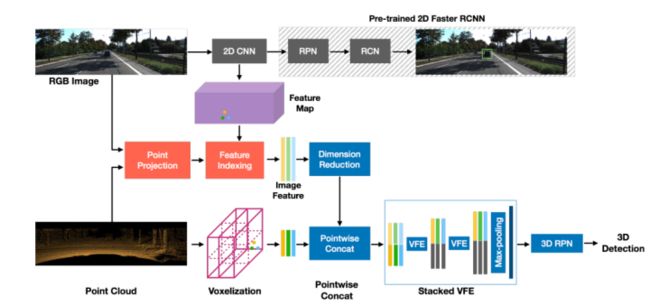
MVXNet提出目前3D检测网络大多基于点云数据,通常基于单一模式,无法利用来自其它模式(如camera)的信息。虽然有几种方法融合不同模态的数据,但这些方法要么使用复杂的pipeline顺序处理模态,要么执行后期融合,无法在早期阶段了解不同模态之间的相互作用。MVXNet提出了点融合和体素融合:两种简单而有效的早期融合方法,通过利用最近引入的VoxelNet框架,将RGB和点云模式结合起来。在KITTI数据集的评估表明,与仅使用点云数据的方法相比,性能有显著提高。此外,通过使用简单的单级网络,所提出的方法提供了与最先进的multimodal算法对比的结果,在KITTI基准上的六个鸟瞰图和3D检测类别中的五个类别中排名前二。
PointPainting
3D物体目标检测任务最好采用哪种传感器?Camera还是Lidar?不同团队给出了不同的答案。Camera和Lidar作为目标检测领域的两大巨头传感器,各有优缺点:图像的分辨率比较高,纹理信息比较丰富,但深度信息相对模糊;点云的空间信息、深度信息比较准确丰富,但数据往往比较稀疏、不够完整。由于两种传感器在一些方面存在互补关系,所以很多人相信我们可以利用多模态的方案来实现强强联合,开创1+1>2的局面,但实际却是...各种1+1<1。这是因为图像和点云两种数据之间存在着完全不同的特性,这种差异性致使我们无法通过一些“理所当然”的方案来实现性能的叠加。虽然已经有很长一段时间各大榜单被Lidar-only的方案所霸占(最近好像有逆转的趋势),但在之间也不乏一些多模态方法的优秀工作,比如PointPainting。PointPainting是工业界发表的一篇多模态3D物体目标检测Paper,在文中作者提出了一种图像与点云的新型融合方案。PointPainting提出一种顺序融合的方法来解决该问题,其工作原理是将LIDAR点投影到图像语义分割网络的输出中,并将分类分数附加到每个点云上,Painted的点云可以输入任何LIDAR点云的网络,在Point-RCNN、voxelnet、pointpillar上均实现涨点。PointPainting是按顺序设计的,因此不能端到端优化!
如下图所示,PointPainting架构包括三个主要阶段:(1)基于图像的语义网络(2)融合(绘制)和(3)基于激光雷达的检测器。在第一步中,图像通过语义分割网络获得逐像素分割分数。在第二阶段,将激光雷达点投影到分割掩模中,并用在前一步骤中获得的分数进行装饰。最后,基于激光雷达的目标检测器可用于装饰(绘制)的点云,以获得3D检测结果!

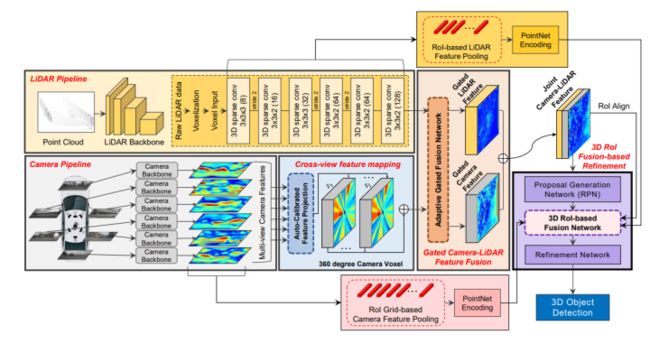
3D-CVF
3D-CVF提出由于视角不同,相机特征投影到3D世界坐标中时,会丢失空间信息,因为这个转换是一对多(one-to-many)的映射。此外,投影坐标与LIDAR 3D坐标之间可能存在不一致性,因此如何在不损失信息的情况下融合2种特征至关重要。论文提出了一种融合camera和LIDAR进行3D目标检测的网络,camera和LIDAR存在的一个难点是:二者获取信息的视角不同,因此,在不丢失信息的情况下组合两个异构特征图毕竟困难。3D-CVF采用自动校准投影 (auto-calibrated projection),将2D camera特征转换为与BEV中的 LiDAR 特征对应性最高的平滑空间特征图。然后,应用gated feature fusion network,利用空间注意力机制,根据region适当地混合camera和LIDAR的特征。紧接着,在proposal refinement stage,进一步实现了camera-LIDAR的特征融合。使用ROI-based feature pooling分别池化low-level的camera和LIDAR特征,然后与联合camera-LIDAR特征融合以进一步refine结果。在KITTI和 nuScenes取得了SOTA结果。
CLOCs
CLOCs融合提供了一个低复杂度的多模态融合框架,显著提高了单模态检测器的性能。在任何2D和3D检测器的非最大抑制(NMS)之前,CLOCs对组合输出候选对象进行操作,并经过训练,利用它们的几何和语义一致性,生成更准确的最终3D和2D检测结果。我们对具有挑战性的KITTI目标检测基准的实验评估,包括3D和鸟瞰指标,显示了显著的改进,特别是在长距离,比最先进的基于融合的方法。在提交时,CLOCs在所有基于融合的方法中排名最高的官方KITTI排行榜。
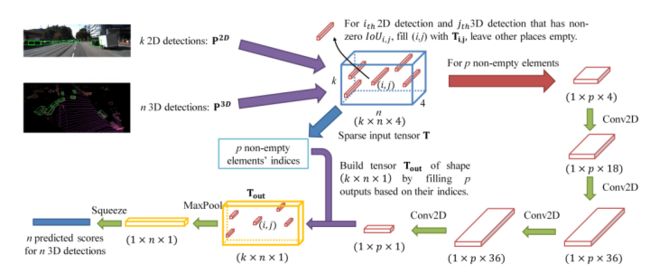
工程落地支持
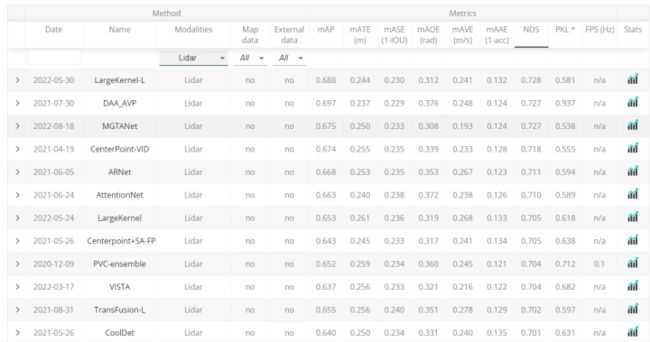
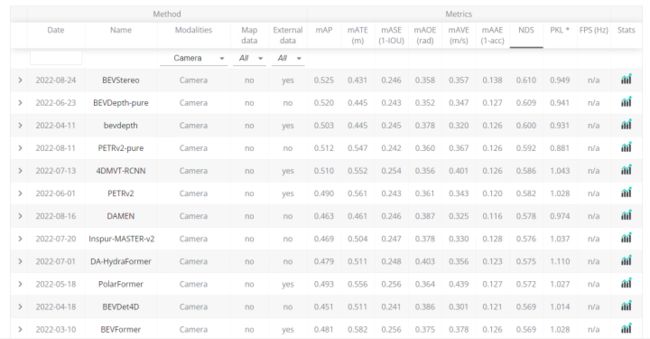
一般来说多模态性能>基于点云>基于双目>基于双目,单目本身无法获取深度学习,天生的缺陷导致其性能并不高,双目虽然可以借助几何关系获取更高的表征,但还是逊色于点云Lidar方案!下面是nuscene上3D检测榜单结果,可以看到基于camera的网络最高mAP在0.525,激光雷达方式在0.688,多模态方式(以最常见的Lidar+Camera为例)在0.756!
基于激光雷达:
基于Camera的:
基于多模态:

总结
聊一下目前工程上使用比较多的模型,基于单目的主要是FCOS3D、SMOKE、FCOS3D++等结构,结构相对简单,纯卷积方案(BEV感知也是一部分,但不在今天的讨论范围内!)
双目方案整体来说,相关研究较少(不那么热门),主要表现在开源数据base少,而且业内的一些自动驾驶方案不采用双目视觉方案,目前的一些思路主要是双目视觉图像生成深度图/伪激光雷达数据,然后送入基于点云的3D检测网络中,解决了激光雷达昂贵的问题。也有一些网络联合深度估计和3D检测任务,端到端。每个公司的落地方案暂时不明确,仁者见仁智者见智!
基于Lidar方案比较受欢迎的是PointPillars、SECOND,在一些自动驾驶公司和造车新势力产品上被广泛采用,速度快,性能佳!另外,一些框架如商汤的mmdeploy以及支持PointPillars到ONNX、TensorRT、OpenVINO了,部署起来很方便!不得不说,mmlab很给力~
多模态领域上使用CLOCs、Fast-CLOCs、PointPainting(pointaugmenting效果更好)使用较多,简单高效、容易部署!
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)
单目3D检测新SOTA!PersDet:透视BEV中进行3D目标检测
超全汇总 | 基于Camera的3D目标检测算法综述!(单目/双目/伪激光雷达)
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
