3D Object DetectionFrom Point Cloud With Part-Awareand Part-Aggregation Network【翻译】
摘要
基于激光雷达点云的3D目标检测是三维场景理解中的一个具有挑战性的问题,具有许多实际应用。
在本文中,在原始工作PointRCNN基础上扩展到一种新颖且强大的基于点云的3D检测框架,即部分感知和聚合神经网络(Part-A^2 net)。
整个框架由部分感知阶段和部分聚合阶段组成。
部分感知阶段:
部分感知阶段首次充分利用源于3D ground-truth box的免费部分监督,以同时预测高质量的3D proposals和准确的intra object part locations。
在同一提议中预测的intra object part location由新设计的RoI感知点云池化模块分组,从而有效的表示来编码每个3D提议的几何特定特征。
部分聚合阶段:
部分聚合阶段通过探索合并的intra object part location的空间关系,学习重新评分和细化框的位置。
大量实验证明提出的框架的每个组件的性能改进。
Part-A2 net优于所有现有的3D检测方法,并且通过仅利用激光雷达点云数据实现了在KITTI 3D目标检测数据集
1 INTRODUCTION 引言
随着自动驾驶和机器人技术需求的增加,3D目标检测越来越受到重视。尽管图像中2D目标的检测已经取得了重大成就,但是直接将2D检测方法扩展到3D可能会导致较差的性能,由于3D场景中的点云数据具有不规则的数据格式,点云3D检测由于不规则的数据格式和六自由度(DoF)大搜索空间而面临巨大的挑战。
现有的3D目标检测方法已经探索了几种方法来应对这些挑战。一些工作利用2D检测器从图像中去检测2D框,然后对裁剪后的点云采用PointNet直接从原始点云回归3D框的参数。然而这些方法严重依赖于2D检测器的性能,无法利用3D信息生成鲁棒的边界框提议。一些其他的工作从鸟瞰图投影点云来创建2D鸟瞰点密度图,并应用2D卷积神经网络(CNN)对这些特征图进行3D目标检测,但是,手工裁剪的特征不能充分利用原始点云的3D信息,可能不是最佳的。还有一些单阶段3D目标检测器将3D空间划分为规则的3D体素,并应用3D CNN 或3D稀疏卷积来提取3D特征,最后压缩成鸟瞰图特征来进行3D 目标检测。这些工作并没有充分利用3D框注释中的所有可用信息来提高3D检测的性能。例如,3D框注释还隐含每个3D目标内部的点分布,这有利于学习更多差别特征来提高3D目标检测的性能。此外,这些工作都是单阶段检测框架,不能利用Rol池化方案来池化每个提议的特定特征,以便在第二阶段进行框优化。
相比之下,我们提出了一种新颖的两阶段 3D 对象检测框架,即部分感知和聚合神经网络(即 Part-A2 网络),它直接在 3D 点云上操作,并通过从训练数据中充分探索信息丰富的 3D 框注释,实现最先进的 3D 检测性能 。主要观察结果是,与2D图像中的目标检测不同,自动驾驶场景中的 3D 物体由带注释的 3D 边界框自然且良好地分离,这意味着带有 3D 框标注的训练数据会自动提供免费的语义掩码(masks),甚至每个前景点在3D 地面真实边界框内的相对位置(参见图 1 的说明)。在本文的其余部分中,每个前景点的相对位置 w.r.t. 它所属的目标框表示为the intra-object part locations。这与2D图像中的框注释完全不同,因为2D图像中的对象的某些部分可能被遮挡。使用地面真实2D边界框会为对象中的每个像素生成不准确且有噪声的the intra object part locations。这些 3D the intra object part locations隐含了 3D 物体的 3D 点分布。 这种 3D the intra object part locations信息丰富,可以免费获得,但从未在 3D 对象检测中探索过。
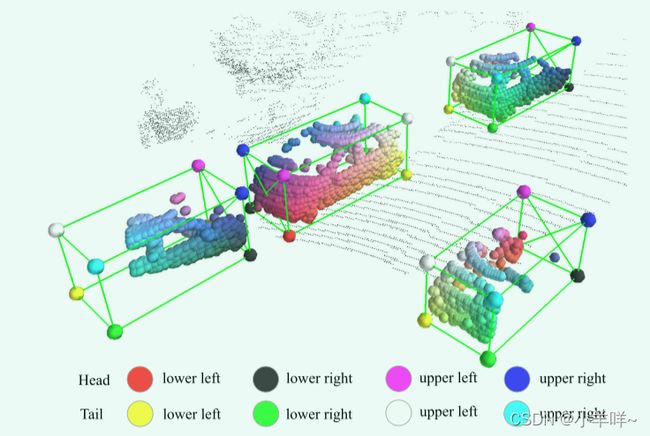
图 1. 提出的部分感知和聚合网络即使物体被部分遮挡的情况下也可以准确地预测intra-object part locations。这样的部分位置可以帮助准确的 3D 目标检测。该方法通过八个角点的插值颜色来可视化预测的intra-object part locations。最好用彩色来观看。
受此观察的启发,我们提出的 Part-A2 网络被设计为一种新颖的两阶段 3D 检测框架,该框架由部分感知阶段 (Stage-I)用于预测准确的intra-object part locations和学习逐点特征的 ,以及部分聚合阶段(Stage-II)用于聚合部分信息以提高预测框的质量组成。我们的方法生成了参数化为(x,y,z,h,w,l,θ)的3D边界框,其中(x,,y,z)为框的中心坐标,(h,w,l)分别为每个框的高度、宽度和长度,θ为从鸟瞰图上看每个框的方位角。
具体来说,在部分感知阶段 I,网络学习对前景点进行分割,并估计所有前景点的intra-object part locations(见图1),其中分割掩码(segmentation masks)和地面真实部分位置(ground-truth part location)标注直接从地面真实3D框(ground-truth 3D box)标注中生成。此外,该网络还对点云进行前景分割和部分估计,同时生成 3D 提议。我们研究了两种策略,即无锚与基于锚的策略,用于 3D 提案生成以处理不同的场景。无锚策略相对轻量级,内存效率更高,而基于锚的策略以更多的内存和计算成本实现更高的召回率。对于无锚策略,我们方法是分割前景点并同时从预测的前景点生成三维提议,以自底向上方法直接生成3D边界框提议。由于它避免像之前的方法那样在整个 3D 空间中使用大量 3D 锚框,因此可以节省大量内存。对于基于锚的策略,它从下采样的鸟瞰图(bird-view) 特征图中生成3D提议,在每个空间位置处具有预定义的3D锚框。由于它需要在每个位置放置多个具有不同方向和类别的3D锚,因此它需要更多内存,但可以实现更高的目标召回率。
在现有两阶段检测方法的第二阶段中,3D提议中的信息需要通过某些池化操作进行聚合,以便进行后续的框重新评分和位置优化。然而,之前的点云池化策略(在我们的初步 PointRCNN[32] 中使用)会导致表示模糊,因为不同的提议最终可能会池化同一组点,从而失去了对提议的几何信息进行编码的能力。为了解决这个问题,我们提出了一种新颖的可微分 RoI 感知点云池化操作,该操作将来自非空体素和空体素的所有信息保留在提议中,以消除先前点云池化策略的模糊性。这对于获得框评分和位置细化的有效表示至关重要,因为空体素也对框的几何信息进行编码。
第二阶段旨在通过提议的 RoI 感知池化来聚合第一阶段的池化部分特征,以提高提议的质量。我们的第二阶段网络采用稀疏卷积和稀疏池化操作,逐步聚合每个3D提议的池化部分特征,以进行准确的置信度预测和框细化。实验表明,聚合的部分特征可以显著提高提议的质量,整体框架在KITTI 3D检测基准上达到了最先进的性能。
本文主要贡献可以概括为四方面。
(1)提出了用于从点云进行 3D 目标检测的 Part-A2 网络框架,该框架通过使用免费的对象内部分信息(intra-object part information)来学习有鉴别性的 3D 特征,并利用RoI 感知池和稀疏卷积有效聚合部分特征,提高了3D 检测性能。
(2)我们提出了两种3D提案生成策略,以处理不同的场景。无锚策略对内存需求较小,而基于锚的策略具有更高的对象召回率。
(3)提出了一种可微分的RoI感知点云区域池化操作,以消除现有点云区域池化操作的模糊性。实验表明,池化特征(pooled feature)表示对框细化阶段有显著的好处。
(4)截止2019年8月15日,在极具挑战性的KITTI3D检测基准上,我们提出的Part-A^2网络以14帧每秒的推理速度排名第一,优于所有已发表的方法,这证明了我们的方法的有效性。
2 RELATED WORK 相关工作
(1)3D Object Detection From 2D Images
从 2D 图像进行 3D 目标检测
目前已有一些关于从图像中估计3D边界框的工作。利用 3D 和 2D 边界框之间的几何约束来恢复 3D 对象姿态。利用 3D 对象和 CAD 模型之间的相似性。Chen等人将物体的三维几何信息表示为能量函数,以对预定义的三维框进行评分。Ku等人提出了聚集损失法,以提高单目图像的3D定位精度。最近,探索了立体图像对,以提高3D检测性能。由于缺乏准确的深度信息,这些工作只能生成粗略的3D检测结果,并且会受到外观变化的显著影响。
(2)3D Object Detection From Multiple Sensors
多传感器3D目标检测
现有的几种方法都致力于融合来自多个传感器(如激光雷达和相机)的信息,以帮助三维目标检测。[1]、[4] 将点云投影到鸟瞰图,并分别从鸟瞰图和图像中提取特征,然后通过将 3D 提议投影到相应的 2D 特征图进行裁剪和融合,以进行 3D 目标检测。[5]进一步探索了特征融合策略,提出了连续融合层,将图像特征与鸟瞰特征融合。与将点云投影到鸟瞰图不同,[6],[25]首先使用现成的2D对象检测器检测2D框以裁剪点云,然后应用PointNet[27],[28]从裁剪的点云中提取特征以进行3D框估计。这些方法在实际应用中可能存在多个传感器的时间同步问题。与这些传感器融合方法不同的是,我们提出的 3D 检测框架 Part-A^2 网络可以通过仅使用点云作为输入来实现相当甚至更好的 3D 检测结果。
(3)3D Object Detection From Point Clouds Only
仅从点云进行3D目标检测
Zhou等人 [29] 首次提出了体素网VoxelNet,从点云中学习鉴别性的特征,并仅使用点云检测3D对物体。[7] 通过引入稀疏卷积 [30],[31] 来改进体素网络,以进行有效的体素特征提取。[7] 通过引入稀疏卷积[30],[31]对体素网VoxelNet进行改进,以实现有效的体素特征提取。[9]、[10]、[11] 将点云投影到鸟瞰图上,并在这些图上应用 2D CNN。这些方法没有充分利用来自信息丰富的 3D 框标注的所有可用信息,并且都是单阶段 3D 检测方法。相比之下,我们提出的两阶段 3D 检测框架 Part-A^2 网络,探索了由3D 框注释提供的丰富信息,并学习预测准确的 intra-object part locations以学习 3D 对象的点分布,并将预测的部分位置聚合在第二阶段用于细化 3D 提议,这显着提高了 3D 目标检测的性能。
(4)Point Cloud Feature Learning for 3D Object Detection
点云特征学习在三维物体检测中的应用
通常有三种从点云学习特征的方法来进行三维检测。
(1) [1], [4], [5], [10], [11] 将点云投影到鸟瞰图,并利用 2D CNN 进行特征提取。
(2) [6],[25]执行PointNet[27],[28]直接从原始点云学习点云特征。
(3) [29] 提出了 VoxelNet,[7] 应用稀疏卷积 [30]、[31] 来加速 VoxelNet 进行特征学习。在我们的框架中,只有第二种和第三种方法有可能提取逐点特征来分割前景点并预测我们框架中的intra-object part locations。在这里,我们设计了一个类似于UNet[45]的编码器-解码器点云骨干网来提取具有鉴别性的点对点特征(point-wise features),该骨干网基于3D稀疏卷积和3D稀疏反卷积操作,因为它们比PointNet++等基于点的骨干网更高效、更有效[28]。4.1.1 节对基于点的主干和基于体素的主干进行了实验和讨论。
(5)3D/2D Instance Segmentation
3D/2D实例分割
3D实例分割的方法通常基于基于点云的三维检测方法。有几种方法基于3D检测边界框,带有一个额外的mask支路(mask branch),用于预测对象mask。Yi等人 [46] 提出了一种综合分析策略来生成用于 3D 实例分割的 3D proposals。Hou等人将多视图RGB图像和3D点云结合起来,以端到端(end-to-end)方式更好地生成proosals和预测对象实例masks。
其他一些方法首先估计语义分割标签,然后根据学习到的point-wise嵌入将点分组到实例中。Wang等人[48]计算了点之间的相似度,用于对每个实例的前景点进行分组。Wang等人[49]提出了一种语义感知(semantic-aware)的点级(point-level)实例嵌入策略,以更好地学习语义和实例点云分割的特征。Lahoud等人[50]提出了一个mask-task学习框架,用于学习特征嵌入和实例中心的方向信息,以便更好地将点聚类到实例中。然而,他们没有像我们提出的方法那样利用免费的intra-object part locations作为额外的监督。
二维实例分割也有一些无锚(anchor-free)方法,即将像素聚类成实例。Brabandere等人[51]采用判别损失函数在特征空间中对同一实例的像素进行聚类,而Bai等人[52]则提出估算改进后的water-shed energy landscape,以分离不同实例的像素。然而,这些方法仅将前景像素/点分组到不同的实例中,并没有估计 3D 边界框。与上述方法不同,我们提出的anchor-free方法估计intra-object part locations,并直接从各个 3D 点生成 3D 边界框proposals,以实现 3D 目标检测。
(6) Part Models for Object Detection
用于目标检测的部分模型
在使用深度学习模型之前,基于变形部分的模型(DPM)[53]在二维目标检测方面取得了巨大成功。[54]、[55]、[56] 将 DPM 扩展到 3D 世界,以推理 3D 中的部分并估计对象姿态,其中 [54] 将对象建模为具有可变形面和可变形部分的 3D 长方体,[55 ] 提出了一种 3D DPM,它生成具有连续外观表示的完整 3D 对象模型,[56] 提出了与 3D CAD 模型共享 3D 部分的概念以估计精细姿态。这些基于DPM的方法通常采用几个由手工制作的特征训练的部分模板来定位对象和估计对象的姿态。相比之下,我们将对象部分表示为点云上下文中的point-wise 的intra-object part locations,其中部分位置的训练标签可以直接从 3D 框注释生成,并且它们隐式编码 (implicitly encode)3D 对象的部分分布。此外,通过更强大的深度学习网络来学习intra-object part locations的估计和聚合,而不是以前手工制作的方案。
3 PART-A2 NET:3D PART-AWARE AND AGGREGATION FOR 3D DETECTION FROM POINT CLOUD
这项工作的初步版本在 [32] 中提出,我们提出 PointRCNN 用于从原始点云进行 3D 目标检测。为了使该框架更具通用性和有效性,本文将PointRCNN扩展到一种新的端到端3D检测框架,即part-A^2网络,以进一步提高点云3D目标检测的性能。
关键的观察是,3D 目标检测的 ground-truth box不仅因为 3D 场景中的3D物体的自然分离而自动提供准确的分割mask,而且还隐含了ground-truth box内每个前景 3D 点的相对位置。这与 2D 目标检测非常不同,其中 2D 目标框可能由于遮挡而仅包含对象的一部分,因此无法为每个 2D 像素提供准确的相对位置。 这些前景点的相对位置编码了前景 3D 点的有价值信息,有利于 3D 对象检测。这是因为同一类别(如汽车类别)的前景对象通常具有相似的3D形状和点分布。前景点的相对位置为box 评分(scoring)和定位提供了强有力的线索。我们将3D前景点到它们对应的boxes的相对位置w.r.t命名为intra-object part locations。
这些intra-object part locations为从点云中学习有鉴别性的3D特征提供了丰富的信息,但在以前的3D目标检测方法中从未探索过。有了如此丰富的监督,我们提出了一种新颖的部分感知和聚合的3D 对象检测器 即Part-A2 网络,用于从点云进行 3D 对象检测。具体来说,我们建议在第一阶段使用免费的3Dintra-object part location标签和分割标签作为额外的监督,以更好地学习3D特征。然后在第二阶段聚合每个3Dproposal中预测的3Dintra-object part locations和point-wise 3D特征,以对boxes进行score并refine其位置。总体框架如图2所示。

图2.我们用于 3D 对象检测的部分感知和聚合神经网络的整体框架由两个阶段组成:(a) part aware stage-I首次预测intra-object part locations,并通过将点云提供给我们的编码器-解码器网络来生成3D proposals。(b) part-aggregation stage-II 进行提出的 RoI 感知点云池化操作以聚合来自每个 3D proposal 的部分信息,然后使用 part-aggregation 网络,根据来自第一阶段的部分特征和信息对boxes进行score和细化位置。
3.1 Stage-I: Part-Aware 3D Proposal Generation
部分感知网络旨在通过学习估计前景点的intra-object part locations来从点云中提取鉴别性的特征,因为这些部分位置通过指示3D对象的表面点的相对位置来隐式地编码3D对象的形状。此外,部分感知阶段学习估计前景点的intra-object part locations并同时生成 3D proposals。针对不同的场景,提出了两种基于点云的三维proposals生成方法,即anchor-free和anchor-based 方法。
3.1.1 Point-Wise Feature Learning via Sparse Convolution
为了分割前景点和估计intra-object part locations,我们首先需要学习具有鉴别性的point-wise特征来描述原始点云。不是使用 [27]、[28]、[57]、[58]、[59]、[60]、[61] 等基于点的方法从点云中提取point-wise特征,如图所示 图 2 的左侧部分,而是,我们提出利用具有稀疏卷积和反卷积的编码器-解码器网络 [30]、[31] 来学习用于前景点分割和intra-object part location估计的具有鉴别性的point-wise特征,这更比我们的初步工作[32]中使用的PointNet++主干网络高效且有效。
具体来说,我们将三维空间体素化为规则体素,通过稀疏卷积和稀疏反卷积的叠加,提取每个非空体素的体素方向特征,其中,其中每个体素的初始特征简单地计算为LiDAR坐标系中每个体素内点坐标的平均值。每个非空体素的中心被认为是一个点,形成一个新的点云,具有点状特征(即体素特征),大致相当于原始点云,如图3所示, 因为与整个 3D 空间(70 m 80 m 4 m)相比,体素尺寸要小得多(例如,在我们的方法中为 5 cm 5cm 10 cm)。每个非空体素的中心被认为是一个点,用point-wise特征(即voxel-wise特征)形成一个新的点云,大致相当于如图3所示的原始点云, 因为与整个 3D 空间(~70m*80m*4 m)相比,体素尺寸要小得多(例如,在我们的方法中为 5cm*5cm*10 cm)。对于在KITTI数据集[33]中每个3D场景,3D空间中一般有16000个非空体素。体素化后的点云不仅可以通过基于主干网的稀疏卷积被处理,而且在三维目标检测中也可以保持与原始点云的近似等价性。
我们的基于稀疏卷积的骨干网是在编码器-解码器体系结构的基础上设计的。输入特征量的空间分辨率通过一系列步长为 2 的稀疏卷积层下采样 8 倍,然后通过稀疏反卷积逐渐上采样到原始分辨率,以进行voxel-wise特征学习。详细的网络结构在第 3.5 节和图 7 中进行了说明。我们新设计的基于 3D 稀疏卷积的主干在我们的初步 PointRCNN 框架 [32] 中比基于 PointNet++ 的主干具有更好的 3D 框召回率(如表 1 中的实验结果所示) ,这证明了这种新主干对point-wise学习的有效性。
表1.不同骨干网络和不同proposals生成策略,proposa生成阶段的召回率

3.1.2 Estimation of Foreground Points and Intra-Object Part Locations
segmentation masks有助于网络区分前景点和背景,而intra-object part locations为神经网络识别和检测三维对象提供了丰富的信息。例如,车辆的侧面通常是与其相应边界框的侧面平行的平面。通过学习不仅可以估计前景segmentation mask,还可以估计每个点的intra-object part location,神经网络发展了推断对象形状和姿态的能力,这对于 3D 对象检测至关重要。
Formulation of Intra-Object Part Location.
如图 4 所示,我们将每个前景点的intra-object part location表示为其在其所属的 3D ground-truth中的相对位置。我们表示三个连续的数值(x(^part), y(^part),z(^part))作为前景点(x(^p), y(^p),z(^p))的intra-object part location,计算如下
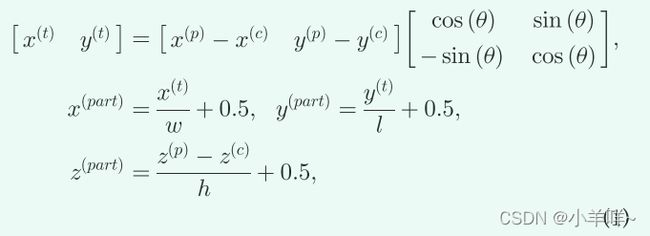
(x(^c), y(^c),z(^c))是box的中心,(h, w, l)是box的尺寸(),θ是鸟瞰图中的框方向,前景点的相对部分位置∈[0, 1],因此物体中心的部分位置为(0.5,0.5,0.5),请注意,物体内位置坐标系遵循 KITTI 全局坐标系的类似定义,其中 z 的方向垂直于地面,x 和 y 平行于水平面。

图4. 前景点的对象内零件位置图示。在这里,我们使用插值颜色来指示每个点的对象内部分位置。最好用彩色来观看。
Learning Foreground Segmentation and Intra-Object Part Location Estimation.
如图 2 所示,给定上述基于稀疏卷积的主干,在编码器-解码器主干的输出特征上附加了两个分支,用于分割前景点并预测它们的intra-object part locations。两个分支都使用sigmoid函数作为最后一个非线性函数来生成输出。由于intra-object part locations仅在训练阶段在前景点上进行定义和学习,前景点的分割scores表示预测的intra-object part locations的可信度。由于在大型户外场景中,前景点的数量通常远小于背景点的数量,因此我们采用focal loss [21]来计算点分割损失Lseg来处理类不平衡问题。
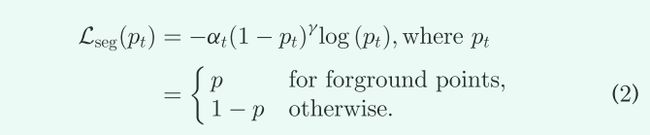
其中p是单个3D点的预测前景概率,我们保持在at=0:25 , γ=2,与原始论文相同。 ground-truth boxes内的所有点作为正点,其他点作为负点进行训练。
为了估计每个前景点的intra-object part location(表示为(x(^part), y(^part),z(^part))),因为它们在[0,1]之间,我们将二进制交叉熵(binary cross entropy)损失应用于每个前景点,如下所示

其中![]() 是来自网络输出的预测intra-object part location,而
是来自网络输出的预测intra-object part location,而![]() 是对应的ground-truth的intra-object part location。请注意,部分位置估计仅针对前景点进行。
是对应的ground-truth的intra-object part location。请注意,部分位置估计仅针对前景点进行。
3.1.3 3D Proposal Generation From Point Cloud
为了在第二阶段聚合预测的intra-object part locations和学习的point-wise 3D 特征以提高 3D 对象检测的性能,我们需要生成 3D proposals来对属于同一对象的前景点进行分组。本文研究了两种基于点云的三维proposals生成策略,即无锚anchor-free方案和基于锚anchor-based方案,以处理不同的场景。无锚策略的内存效率更高,而基于锚的策略以更多的内存成本实现更高的召回率。
Anchor-Free 3D Proposal Generation.
我们采用这种策略的模型被表示为Part-A^2-free。我们提出了一个类似于初步PointRCNN[32]的新方案,以自下而上的方式生成3D proposals。如图2的左半部分所示,我们向稀疏卷积主干的解码器附加一个额外分支,从预测为前景的每个点生成3Dproosals。
但是,如果算法直接从每个前景点估计目标的中心位置,回归目标的变化范围会很大。例如,对于位于对象角落的前景点,其相对于对象中心的偏移量要比位于对象侧面的前景点的偏移量大得多。如果用常规回归损失(如L1或L2损失)直接预测每个前景点的相对偏移量,则这种损失将主要受角前景点误差的影响。
为了解决回归目标变化范围大的问题,我们提出了bin-based 的中心回归损失。如图 5 所示,通过将每个轴的搜索范围S划分为等长δ的bins,我们沿 X 和 Y 轴将每个前景点的周围鸟瞰区域分割成一系列离散的 bins,表示不同的对象中心(x, y)在X-Y平面上。我们观察到,在x轴和Y轴上使用交叉熵损失进行bin-based的分类,而不是使用smooth-L1损失[14]进行直接回归,可以获得更准确、更鲁棒的中心定位。为了在分配到每个X-Y bin后细化小的定位,还需要估计小的误差(residual)。因此,X轴或Y轴的总体回归损失包括bin classification loss和residual regression loss within the classified bin。对于垂直z轴的中心位置z,我们直接使用smooth-L1 loss进行回归,因为大多数对象的z值一般都在一个较小的范围内。因此,对象中心回归目标可以表述为

δ是bin的长度
(x^(p), y^(p),z^(p))是感兴趣的前景点坐标
(x^(c), y^(c),z^(c))是其对应对象的坐标中心
![]() 为ground-truth bin分配
为ground-truth bin分配
![]() 为ground-truth residual,用于在分配的bin内进行进一步的位置refinement。
为ground-truth residual,用于在分配的bin内进行进一步的位置refinement。
由于我们提出的自底向上的propasal生成策略是anchor-free的,所以它没有box定向的初始值。因此,我们直接将方向2π划分为离散的 bin,bin 大小为 w,计算 bin classification目标![]() 和 residual regression目标
和 residual regression目标![]() 为
为

因此,整体三维边界框回归损失Lbox可被表示为

![]() 是预测bin分配和和前景点p的residuals
是预测bin分配和和前景点p的residuals
![]() 是上面计算的ground-truth目标
是上面计算的ground-truth目标
是在垂直轴上的预测中心残差或相对于整个训练集中的每个类的平均对象尺寸的尺寸残差![]()
是![]() 的相应ground-truth目标
的相应ground-truth目标 ![]()
Lce表示交叉熵分类损失,Lsmooth-L1表示平滑-L1损失。
注意,box回归损失Lbox仅应用于前景点。
在推理阶段,首先选择预测置信度最高的bin中心,然后将预测residuals相加,得到回归x、y和θ。
基于这种无锚(anchor-free)策略,我们的方法不仅充分挖掘点云中的3D信息用于3D proposal生成,而且通过将3Dproposal约束为仅由前景点生成,避免了在3D空间中使用大量预定义的3D锚框(anchor boxes)。
我们采用这种策略的模型表示为Part-A^2-anchor。第一阶段如图2所示,基于稀疏卷积的编码器采用形状为M*N*H的体素化点云,并生成8倍X和y轴下采样M/8*N/8 的H/16 *D特征通道的2D鸟瞰特征图,其中 H/16 表示沿 Z 轴下采样 16 次的特征体积(feature volume),D是每个编码后的特征体素的特征维数,“D”表示将每个x-y不同高度的鸟瞰位置的特征串联起来,得到一维的特征向量。然后,我们将与 [7] 类似的Region Proposal Net-work (RPN) 头附加到上述鸟瞰特征图,用于使用预定义的 3D 锚点生成 3D proposal。每个类具有针对每个类的指定anchor大小尺寸的2*M/8*N/8个预定义的anchors,其中鸟瞰特征图上的每个像素都有一个平行于X轴的anchor和一个平行于Y轴的anchor。每个类都有自己的预定义anchors,因为不同类的对象大小差异很大。例如,我们将(l=3.9, w=1.6, h=1.56) 米用于汽车,(l=0.8, w=0.6, h=1.7) 米用于行人,(l=1.7, w=0.6, h=1.7) 米适用于 KITTI 数据集上的骑自行车者。
通过计算 2D 鸟瞰图Intersection-over-Union(IoU)与ground-truth相关联,其中正 IoU 阈值根据经验设置为 0.6、0.5、0.5,负 IoU 阈值为 0.45、0.35 ,汽车、行人和骑自行车的人分别为 0.35。我们在鸟瞰特征图中添加了两个核大小为1*1*1的卷积层,用于proposal分类和box回归。对于anchor scoring,我们使用类似于式(2)的focal loss,对于正anchor直接使用residual-based的回归损失。在这里,由于IoU阈值,锚与其对应的地面真值框之间的中心距离通常在比无锚策略的中心距离更小的范围内,我们直接采用常用的smoothL1 loss进行回归。候选 anchor为![]() ,目标 ground-truth为
,目标 ground-truth为![]() ,中心、角度和大小的residual-based的box回归目标定义为
,中心、角度和大小的residual-based的box回归目标定义为

其中定向目标编码为sin(θ^(gt)-θ^(a)),以消除定向循环值的模糊性。然而,这种方法将两个相反的方向编码为相同的值,因此我们在鸟瞰特征图的 [7] 中采用具有核大小1*1*1的额外卷积层来对两个相反方向进行分类,其中方向目标通过以下方法计算:如果θ^(gt)为正,方向目标为1,否则方向目标为0(注意θ^(gt)∈[-π, π]。我们类使用似于式(3)交叉熵损失来对方向方向进行二元分类,记作term Ldir。然后整个3D bounding box回归损失Lbox可表示为
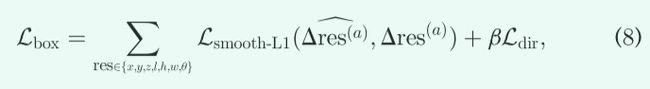
其中,![]() 是候选anchor的预测residual,
是候选anchor的预测residual,![]() 是为相应的ground-truth目标,按式(7)计算。损失权重β=0.1。注意,box回归损失 Lbox仅应用于正anchors。
是为相应的ground-truth目标,按式(7)计算。损失权重β=0.1。注意,box回归损失 Lbox仅应用于正anchors。
Discussion ofthe Two 3D Proposal Generation Strategies.
这两种3Dproposal生成策略都有各自的优点和局限性。所提出的anchor-free策略通常是轻量级并且存储高效,因为它不需要在3D空间中的每个空间位置处评估大量的anchor。由于三维物体检测中的不同类通常需要不同的anchor boxes,因此多类物体检测的效率更明显,而anchor-free方案可以共享point-wise特征以生成多类的proposals。第二种anchor-based的proposal生成策略通过对每个类使用预定义anchors覆盖整个鸟瞰特征图,获得略高的召回率,但需要更多的参数和更多的GPU内存。详细的实验和比较在 4.1.4 节中讨论。
3.2 RoI-Aware Point Cloud Feature Pooling
鉴于预测的intra-object part locations和3Dproposals,我们的目标是通过聚合part information和同一proposal内所有点的学习point-wise特征来进行box scoring和proposal
refinement。在本小节中,我们首先介绍正则变换(canonical transformation),以减少不同3D proposals的旋转和位置变化的影响,然后,我们提出了RoI感知点云特征池模块,以消除之前点云池化操作的模糊性,并对3Dproposal的特定位置(position-specific)特征进行编码,以进行框优化(box refinement)。
Canonical Transformation.
我们观察到,如果在正则坐标系中对box refinement目标进行归一化(normalized),则可以通过下面的box refinement阶段进行更好地估计。我们将属于每个方案的pooled点转换为相应3Dproposals的各个标准坐标系。一个 3D proposal 的正则坐标系表示:(1)原点位于 box proposal 的中心; (2) 局部 X' 和 Y' 轴与地平面近似平行,X' 指向proposal的头部方向,另一个 Y'轴垂直于 X'; (3) Z' 轴与全局坐标系保持一致。盒子方案中所有pooled点的坐标p都应通过适当的旋转和平移转换为正则坐标系~p。正3D proposals及其对应的 ground-truth 3D box转换为正则坐标系,以计算用于box refinement的residual回归目标。
所提出的正则坐标系基本上消除了不同3Dproposals的大量旋转和位置变化,并提高了特征学习的效率,以用于以后的box location refinement。虽然这种转换可能会导致遮挡信息的丢失,但我们观察到,深度神经网络的优点大于缺点,具有较大的模型能力来处理不同的遮挡情况。
RoI-Aware Point Cloud Feature Pooling.
我们的初步工作 PointRCNN [32] 中的点云池化操作只是将 3D proposals中的point-wise特征池化,其对应的点位置在 3D proposal内。所有内部点的功能都由PointNet++编码器聚合,以便在第二阶段refining proposal。然而,我们观察到,这种操作会丢失很多三维几何信息,并在不同的三维proposal之间引入模糊性(ambiguity)。这种现象如图 6 所示,其中不同的proposal会产生相同的pooled点。 相同的pooled特征对接下来的refinement阶段产生了不利影响。

图6.提出的RoI感知点云特征池化的说明。以前的点云池化方法对proposal的几何信息(蓝色虚线框)进行有效编码。我们提出的RoI感知点云池化方法,通过保留空体素来对box的几何信息(绿框)进行编码,通过稀疏卷积可以有效地处理空体素。
因此,我们提出了RoI感知点云池化模块,以将每个3Dproposal均匀地划分为具有固定空间形状(Lx*Ly*Lz)的规则体素 ,其中Lx,Ly,Lz是3Dproposal的每个维度中的池化分辨率(pooling resolution)的整数超参数 integer hyperparameters(例如,14*14*14在我们的框架中采用),并且与不同的3Dproposal大小无关。
具体来说,让![]() 表示 3D proposal b 中所有内部点的point-wise特征,并根据其local正则坐标 X =
表示 3D proposal b 中所有内部点的point-wise特征,并根据其local正则坐标 X =![]() 分散在 3D proposal的划分体素中, 其中 n 是内部点的数量。 然后 RoI 感知体素最大池化和平均池化操作可以表示为
分散在 3D proposal的划分体素中, 其中 n 是内部点的数量。 然后 RoI 感知体素最大池化和平均池化操作可以表示为

其中 Q 是proposal b 的池化 3D 特征体积。 具体来说,体素的max pooling和average pooling在第k个体素Qk处的特征向量可以计算为

其中Nk是属于第k个体素的点的集合,其中k∈{1,...,Lx*Ly*Lz}。注意,此处空体素 (|Nk| = 0) 的特征将设置为零并标记为空,以用于以下基于稀疏卷积的特征聚合。
所提出的 RoI 感知点云池化模块使用相同的局部空间坐标对不同的 3D proposal进行编码,其中每个体素对 3D proposal中相应固定网格的特征进行编码。这种特定于位置的特征池化更好地捕捉3Dproposal的几何形状,并产生用于后续box scoring和location refinement的有效表示。此外,提出的RoI感知点云池模块是可微的,这使得整个框架能够进行端到端的训练。
3.3 Stage-II: Part Location Aggregation for Confidence Prediction and 3D Box Refinement
通过考虑预测的intra-object part locations的空间分布和从第一阶段的3D box proposal中学习到的point-wise 部分特征,可以合理地将box proposal scoring和 box proposal refinement 中的所有信息聚合在一起。基于池化的 3D 特征,我们训练一个子网络来稳健地聚合信息以对box proposal进行score并refine它们的位置。
Fusion of Predicted Part Locations and Semantic Part Features.
如图2右边所示,我们采用所提出的RoI感知点云池化模块来获取每个三维proposal的鉴别性的特征。令 b 表示单个 3D proposal,对于它的所有内部点(正则坐标![]() ),记
),记![]() 作为他们从阶段I预测的point-wise部分位置和语义score,记
作为他们从阶段I预测的point-wise部分位置和语义score,记![]() 作为它们的point-wise语义特征被骨干网络所学习。这里n是proposal b的内点总数。然后,proposal b的部分特征编码可表述如下
作为它们的point-wise语义特征被骨干网络所学习。这里n是proposal b的内点总数。然后,proposal b的部分特征编码可表述如下

其中 G 表示子流形(submanifold)稀疏卷积层,用于将池化部分位置转换为相同的特征维度 C 以匹配 Q^(sem),[,.,]表示特征连接(concatenation),![]() 有相同的空间形状(默认为14*14*14)。融合后的特征Q^(roi)由骨干网对box proposal的几何信息和语义信息进行编码。请注意,这里我们使用平均池来池化预测的intra-object part locations F1,以获得proposal中每个体素的代表性预测部分位置,而使用最大池来池化语义部分特征F2。
有相同的空间形状(默认为14*14*14)。融合后的特征Q^(roi)由骨干网对box proposal的几何信息和语义信息进行编码。请注意,这里我们使用平均池来池化预测的intra-object part locations F1,以获得proposal中每个体素的代表性预测部分位置,而使用最大池来池化语义部分特征F2。
Sparse Convolution for Part Information Aggregation.
对于每个 3D proposal,我们需要从该提案的所有内部空间位置聚合融合特征 Q^(roi),以实现稳健的box scoring 和refinement。如图2右边部分所示,我们堆叠了几个内核大小为3*3*3的3D稀疏卷积层,以便随着接受域(filed)的增加,聚合proposal的所有部分特征。在这里,我们还在稀疏卷积层之间插入了一个内核大小为 2 *2* 2 和步长为 2 的稀疏最大池化,以将特征体积下采样到 7*7*7 ,以节省计算成本和参数。最后,我们将其矢量化(vectorize)为特征向量(空体素保持为零),并将其输入到两个分支以进行box scoring 和 location refinement。
与直接将池化的3D 特征量矢量化为特征向量的简单方法相比,我们基于稀疏卷积的部分聚合策略可以通过从局部到全局尺度聚合特征,有效地学习预测部分位置的空间分布。稀疏卷积策略还通过节省大量计算、参数和 GPU 内存来实现更大的 14*14*14 池化大小。
3D IoU Guided Box Scoring.
对于第二阶段的box scoring分支,受 [35]、[62] 的启发,我们将 3D proposal与其对应的ground truth box之间的 3D Intersectoin-over-Union (IoU) 归一化,作为proposal质量评估的软标签(soft label)。提案质量 q^(a)定义为

它也由二元交叉熵损失Lscore监督,其定义类似于式(3)。 我们在4.1.7节的实验表明,与传统的基于分类的盒子评分相比,IoU引导的盒子评分性能略好一些。
3.4 Overall Loss
我们的整个网络是端到端可训练的,整体损失函数包括部分感知损失和部分聚合损失。
Losses of Part-Aware Stage-I.
对于部分感知stage-I,损失函数由三个具有相等损失权重的项(terms)组成,包括用于前景点分割的focal损失、用于部分位置回归的binary cross entropy损失和用于3D proposal生成的smooth-L1损失,

其中损失权重λ = 2.0,Npos 是前景点的总数,对于 Part-A2-free 模型,Mpos = Npos ,Mpos 是 Part-A2-anchor 模型的正anchor的总数。
对于 Lbox损失,如第3.1.3节所述,对于Part-A2-free模型,我们采用bin-based box产生损失,对于Part-A2-anchor 模型,我们采用residual-based box回归损失。
Losses of Part-Aggregation Stage-II.
对于部分聚合阶段II,损失函数包括用于box质量回归的二元交叉熵损失项和用于3Dbox proposal refinement的smooth-L1损失项,

其中 Tpos 是正proposal的数量,如式(7)所示,我们对 Lbox_refine进行了residual-based box回归损失。包括box center refinement损失、尺寸refinement损失和角度refinement损失。 除此之外,我们还添加了 [6] 中使用的角正则化损失 (corner regularization loss)Lcorner,最终box refinement 损失如下

其中  是 3D proposal的预测residual,
是 3D proposal的预测residual,![]() 是计算类似于等式(7)的相应ground-truth目标。并且这里的所有损失都具有相同的损失权重。注意,由于由于正proposal的IoU约束,proposal与其对应的ground-truth boxes之间的角度差在较小范围内,因此这里angle refinement target直接编码为
是计算类似于等式(7)的相应ground-truth目标。并且这里的所有损失都具有相同的损失权重。注意,由于由于正proposal的IoU约束,proposal与其对应的ground-truth boxes之间的角度差在较小范围内,因此这里angle refinement target直接编码为![]() 。
。
Overall Loss.
因此,我们的Part-A2网端到端训练的总损失函数计算为
![]()
其中这两个阶段的损失具有相等的损失权重。
3.5 Implementation Details
我们设计了一个类似 UNet 的架构 [45],用于在获得的稀疏体素上使用 3D 稀疏卷积和 3D 稀疏反卷积来学习point-wise特征表示。通过三个步长为 2 的稀疏卷积对空间分辨率进行 8 次下采样,每一次稀疏卷积之后都i进行了几次子流形稀疏卷积。如图7所示,我们还基于稀疏操作设计了与[63]相似的上采样块,对融合后的特征进行细化。

图7.Part-A2-anchor模型部分感知阶段i的基于稀疏卷积的编码器-解码器骨干网络
Network Details.
如图7所示,对于Part-A2-anchor模型的part-aware stage-I,空间特征体具有四个尺度,特征维数为16-32-64-64,我们使用三个核大小为3*3*3的3 D稀疏卷积层,步长为2,将空间分辨率下采样八倍。我们在每个level堆叠两个submanifold convolution layers,核大小为 3*3*3,stride为 1。解码器中有四个稀疏上采样块(网络细节如图7所示),特征维数逐渐增加为64-64-32-16。注意,最后一个上采样块的stride为1,其他三个上采样块的stride为2。对于Part-A2-free网络,我们在每个尺度上将解码器的特征维数增加到128,并使用简单的级联(concatenation)来融合来自同一层编码器和前一层解码器的特征,因为学习到的解码器的point-wise特征应该编码更具辨别力的特征,用于自下而上的3Dproposal生成。
对于部分聚合阶段,如图2所示,感知RoI的点云池化模块的池化大小为14*14*14,经过稀疏卷积和特征维度为128的最大池化处理后,将其下采样到7*7*7。我们将下采样的特征量矢量化为单个特征向量,用于最终的box scoring 和 location refinement。
Training and Inference Details.
我们使用ADAM优化器和批量大小为6的50个epochs对整个网络进行端到端训练。采用余弦退火(cosine annealing)学习速率策略,初始学习速率为0.001。我们从每个场景中随机选择128个proposal进行训练II,其中正proposal和负proposal的比例为1:1,其中positive proposals for box refinement有3D IoU,其对应的ground truth box在所有类中至少为0.55,否则为负proposal, scoring 目标定义为Eq.(13)进行置信度预测。
在训练过程中,我们进行常见的数据增强,包括随机翻转、从[0.95,1.05]均匀采样比例因子的全局缩放、从[-π/4,π/4]中以均匀采样的角度绕垂直轴进行全局旋转。为了模拟各种环境的对象为[7],我们也从其他场景中随机“复制”几个ground-truth box及其内点,并将其“粘贴”到当前的训练场景中。我们提出的部分感知和部分聚合网络的整个训练过程在单个NVIDIA Tesla V100 GPU上大约需要17个小时。
为了进行推断,只有100个proposal被保留在part-aware stage-I,其中Part-A2-free的NMS阈值为0.85,Part-A2-anchor阈值为0.7,然后在接下来的part-aggregation stage-II进行评分和细化。最后,我们使用旋转后阈值为0.01的NMS去除冗余的box,生成最终的三维检测结果。在单个Tesla V100 GPU处理器卡上,整体推断时间约为70ms。
3.6 Pros and Cons
我们提出的三维目标检测框架在不同情况下有一些优点和缺点。与以往的三维物体检测方法 [1] 、 [4] 、 [5] 、 [6] 、 [7] 、 [26] 、 [29] 、 [64] (1) 相比,我们首次提出的方法引入了intra-object part
locations的学习,以提高点云的三维物体检测性能,其中预测的物体intra-object part locations有效地编码三维物体的点分布,有利于三维物体的检测。(2) 提出的 RoI-aware 特征池化模块消除了先前点云池化操作的模糊性,将稀疏的point-wise特征转换为规则体素特征,对 3D proposal的特定位置几何和语义特征进行编码,有效地连接了proposal生成网络和proposal细化网络,具有较高检测精度。(4) 此外,部分位置的学习过程也可以用于其他任务,以学习更具鉴别性的point-wise特征,例如点云的实例分割。提出的RoI-aware池模块还可以灵活地用于将基于点的网络(如PointNet++)中的point-wise特征转换为稀疏体素特征,从而可以通过更高效的稀疏卷积网络进行处理。
另一方面,我们的方法也有一些局限性。由于我们的方法旨在实现自动驾驶场景中的高性能三维目标检测,因此我们的方法的某些部分无法很好地应用于室内场景中的三维目标检测。这是因为室内场景中的 3D 边界框可能会相互重叠(例如桌下的椅子),因此室内场景的 3D 边界框标注无法提供准确的point-wise分割标签。此外,有些类别的方向没有明确定义(例如圆桌),因此我们无法生成proposal的intra-object part locations的准确标签。
然而,我们提出的anchor-free proposal生成策略在室内场景的 3D proposal生成方面仍然显示出巨大的潜力,因为室内对象并不总是停留在地面上,而且我们的anchor-free策略避免在整个 3D 空间中设置 3D anchors。
4 EXPERIMENTS
在本节中,我们在KITTI [33] 数据集的具有挑战性的3D检测基准上进行了大量的实验,对我们提出的方法进行了评价。在第4.1节中,我们提供了广泛的消融研究(ablation studies)和分析,以研究我们模型的各个组成部分。在第4.2节中,我们通过与目前最先进的三维检测方法的比较来说明我们的方法的主要结果。最后,我们在第4.3节中对我们提出的三维检测模型的一些定性(qualitative)结果进行了可视化。
Dataset.
在KITTI三维检测基准数据集中有7481个训练样本和7518个测试样本。将训练样本分为train split(3712个样本)和val split(3769个样本)作为KITTI数据集的常用分区。所有模型只在train split上进行训练,并在val和test split上进行评估。
Models.
我们的实验主要有三种模型,即Part-A2-free模型、Part-A2-anchor模型和我们的初步PointRCNN 模型[32]。第3节展示了Part-A2-free和Part-A2-anchor模型的网络细节,整个框架如图2所示。正如3.1.3节所讨论的,这两个版本的Part-A2模型的关键区别在于,Part-A2-free模型以自底向上(无锚)的方式生成3D提案,而Part-A2-anchor net模型则以基于锚的方式生成3D提案。PointRCNN是这个工作[32]的初步版本。它使用PointNet++提取point-wise特征,根据第3.1.3节所示,通过对前景点进行分割,以自下而上的方式生成3D proposal。此外,在 PointRCNN 的第二阶段,我们汇集了每个 3D proposal的内部点及其point-wise特征,然后将其输入到第二个 PointNet++ 编码器以提取每个 3D proposal的特征,以进行proposal置信度预测和 3D 框proposal细化。
4.1 From Points to Parts: Ablation Studies for Part-A2 Net
在本节中,我们提供了大量的消融实验和分析,以调查我们提出的Part-A2网络模型的各个组件。
4.1.1 SparseConvUNet versus PointNet++ Backbones for3DPoint-Wise Feature Learning
如3.1节所述,我们没有使用PointNet++作为骨干网络,而是设计了一个基于稀疏卷积的UNet(记作SparseConvUNet)来进行逐点特征学习,网络细节在图7所示。我们首先比较了PointRCNN和PointNet++主干网以及Part-A2-free和SparseConvUNet主干网,用相同的损失函数来测试这两种不同的主干网。
表1显示了我们基于SparseConvUNet的Part-A2-free(第二行)的3D IoU阈值为0.7,召回率为81.54%,比基于PointNet++的PointRCNN(第一行)的召回率高6.73%,它证明了我们新设计的SparseConvUNet可以从点云中学习更多有鉴别性的point-wise特征,用于生成3Dproposal。如表 5 所示,我们还为这两个主干提供了不同数量的提案的召回值。我们可以发现基于稀疏卷积的主干的召回率始终优于基于PointNet++的主干的召回率,这进一步验证了基于稀疏卷积的主干在point-wise特征学习和3Dproposal生成方面优于基于PointNet++的主干。
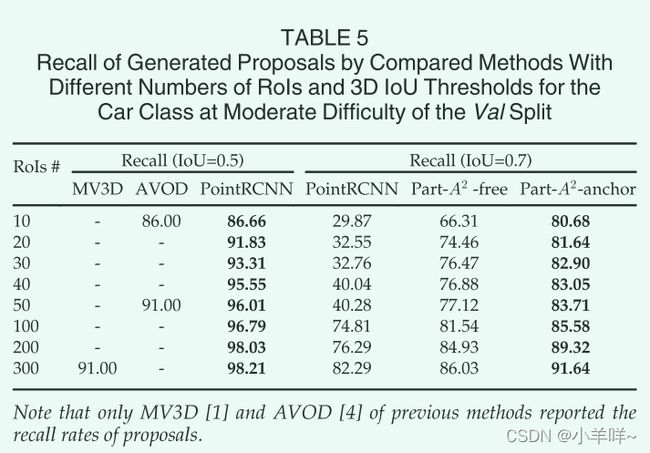
表1和表5也显示我们的Part-A2-anchor模型比Part-A2-free模型有更高的召回率。因此,在我们剩余的实验部分中,除非另有说明,我们主要采用Part-A2-anchor模型进行消融研究和实验比较。
4.1.2 Ablation Studies for RoI-Aware Point Cloud Pooling
在本节中,我们设计了消融实验,以验证我们提出的RoI感知点云池化模块与Part-A2-anchor模型的有效性,我们还探索了更多的池化大小,以调查增加RoI池化大小时的性能趋势。
Effects of RoI-Aware Point Cloud Region Pooling.
如第 3.2 节所述,所提出的 RoI 感知点云池化模块将不同的 3D 提议归一化到相同的坐标系,以对提议的几何信息进行编码。如图6所示,它解决了之前的3D点云池方案的模糊编码问题3D proposal被划分为常规体素,以编码每个3D proposal的位置特定特征。
为了验证RoI感知池化模块的效果,我们进行了以下对比实验。(a) 我们用固定大小的RoI池化取代了感知RoI的池化,也就是说,将所有3Dproposal以相同的固定大小(l=3.9;w=1.6;h=1.56米,适用于car)3D 框是根据具有 14 14 14 个网格的训练集的平均对象大小计算得出的 。三维网格的中心和方向分别设置为其相应三维proposal的中心和方向。这与PointRCNN中使用的池方案非常相似,池化过程中并不是所有的几何信息都能很好的保留。(b) 我们用几个 FC 层替换了第二阶段的稀疏卷积。 如表 2 所示,去除 RoI-aware pooling 会显着降低检测精度,而用 FC 层替换 stage-II 的稀疏卷积实现了类似的性能,这证明了我们提出的 RoI-aware pooling 的有效性,但稀疏卷积并不是主要改进。

Effects of RoI Pooling Size.
2D 对象检测通常选择 14 14 池大小,我们按照相同的设置使用 14 14 14 作为 3D RoI-aware 池化大小。我们还测试了不同的 RoI 池大小,如表 3 所示。池化大小显示了不同 3D 对象的稳健性能。如果池大小大于 12 12 12,则可以观察到类似的性能。

4.1.3 Sparse Convolution versus Fully-Connected Layers forPart Aggregation
在我们的Part-A2网络中,在应用了RoI-aware point cloud pooling模块之后,有几种方法可以实现part-aggregation阶段。
最简单的策略是将pooled feature volumes直接向量化为feature vector,然后是几个fully-connected layers,用于box scoring 和 refinement。从表4的第一行可以看出,这种简单的方法已经取得了很好的效果,这得益于我们的RoI-aware point cloud pooling的有效表示,因为feature vector的每个位置都对感兴趣对象的特定intra-object position进行编码,以帮助更好地了解box的形状。在表4的第二行中,我们进一步研究了使用核大小为3 3 3的稀疏卷积来逐渐聚合从局部到全局的特征,在相同的池大小为7 7 的情况下取得了略好的结果。第 3 行显示具有较大池化大小 14 14 14 的全连接层可以提高性能,但这种设计会消耗大量计算和 GPU 内存。正如我们在第3.3节中提到的,我们提出的part-aggregation网络采用了一个大的池大小14 14 14来捕获细节,然后使用sparse max-pooling来对feature volumes进行降采样以进行特征编码,它在表4所示的简单和中等难度级别上实现了最佳性能,与完全连接的层相比,它的计算和GPU内存成本更低。

4.1.4 Ablation Studies for 3D Proposal Generation
在 Part-A2-anchor 和 Part-A2-free 模型中,我们研究了从点云生成 3D proposal的两种策略,一种是anchor-based的策略,另一种是我们提出的anchor-free策略。在本节中,我们首先对两种proposal生成策略进行了详细的实验和讨论,为在不同场景下选择更好的3Dproposal生成策略提供参考。然后我们比较了两种策略的不同中心回归损失center regression looses的性能。
Anchor-Free versus Anchor-Based 3D Proposal Generation.
我们使用最先进的两阶段 3D 检测方法验证了我们的提案生成策略的有效性。如表 5 所示,我们的具有anchor-free proposal生成和 PointNet++ 主干的初步 PointRCNN 已经比以前的方法实现了显着更高的召回率。PointRCNN只有50个proposal,在IoU阈值为0.5的情况下,获得96.01%的召回率,在相同proposal数量下,这比91%的AVOD[4]的召回率高出5.01%。请注意,后一种方法使用2D图像和点云生成proposal,而我们仅使用点云作为输入。
我们还通过表5中的anchor-free 和 anchor-based的策略报告了在IoU阈值0.7的3D边界框召回率。Part-A2-free模型(采用anchor-free proposal生成策略)在IoU阈值0.7下仅50个proposal的召回率达到77.12%,远高于我们初步工作点RCNN的召回率,因为Part-A2-free模型采用了更好的基于稀疏卷积的主干。我们的 Part-A2-anchor 模型(使用anchor-based的proposal生成策略)在 IoU 阈值为 0.7 时,使用 50 个proposal将召回率进一步提高到 83.71%。这是因为anchor-based策略有大量的anchors可以更全面地覆盖整个3D空间,从而实现更高的召回率。然而,这种改进伴随着牺牲,因为它需要在每个空间位置为不同的类设置不同的anchor。例如行人anchor尺寸(l=0.8m, w=0.6m, h=1.7m),车辆anchor尺寸(l=3.9m, w=1.6m, h=1.56m)。他们不太可能共享同一个anchor。相比之下,我们的anchor-free策略仍然可以从每个分割的前景点生成单个3Dproposal,即使对于许多类别,因为我们只需要根据其语义标签计算相对于相应平均对象大小的3D尺寸residual。

表 6 报告了 Part-A2-free 和 PartA2-anchor 模型对汽车、骑自行车者和行人的 3D 检测结果。我们可以看到,在自行车和行人的三维检测中,Part-A2-free模型与Part-A2-anchor模型的结果相当,而在中等难度和容易难度上,Part-A2-free模型对汽车的检测结果低于Part-A2-anchor模型。因此,自底向上的Part- A2-free模型在小尺寸物体(如自行车和行人)的多类三维检测方面具有较好的潜力,且内存成本较低,而anchor-based Part-A2-anchor模型在汽车等大尺寸物体的三维检测方面可能会取得稍好的性能。这是因为预定义的anchors更接近大尺寸对象的中心位置,而自底向上的proposal生成策略难以将大residuals从对象表面点回归到对象中心。
Center Regression Losses of 3D Bounding Box Generation.
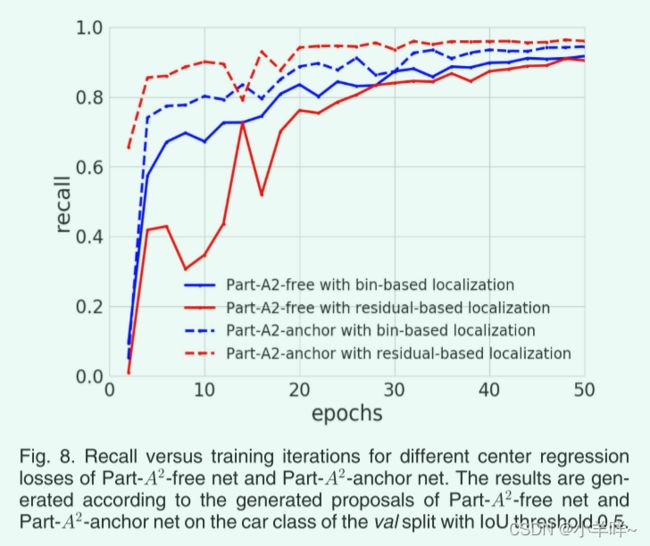
我们比较了我们的Part-A2-free 网络和我们的 Part-A2-anchor 网络上的不同中心回归损失center regression losses,包括建议的bin-based的回归损失(方程(4))和residual-based的回归损失(方程 (7)的第一行))。 如图 8 所示,对于具有anchor-free proposal生成策略的Part-A2-free 网络,bin-based 的回归损失(蓝色实线)比residual-based的回归损失(红色实线)收敛得更快。相反,对于anchor-based proposal生成方案的Part-A2-anchor网络,residual-based regression loss(红色虚线)比bin-based regression loss(蓝色虚线)收敛更快、更好。它表明,所提出的基于 bin 的中心回归损失更适合于anchor-free proposal生成策略,以实现更好的性能,因为anchor-free proposal的中心回归目标(通常从表面点到对象中心)变化较大,基于 bin 的定位可以更好地约束回归目标,使收敛更快、更稳定。图 8 显示,通过residual-based的中心回归损失,Part-A2-anchor 网络召回率更高,我们还对 Part-A2-anchor 网络采用了residual-based的中心定位损失,如第 3.1.3 节所述。
4.1.5 Benefits ofIntra-Object Part Location Prediction for 3D Object Detection
为了验证利用free-of-charge intra-object part locations进行3D检测的有效性,我们测试了从part-A2-anchor模型中移除part location监控。在主干网中,我们只删除用于预测intra-object part locations的分支,而保持其他模块不变。RoI-aware池的point-wise part locations将替换为每个点的正则坐标。
如表 7 所示,与没有intra-object part location监督训练的模型(第 3 行与第 4 行)相比,具有part location监督的模型在汽车类的 val split 的所有难度级别上实现了更好的召回率和平均精度。召回率和精度的显着提高表明,网络通过对intra-object part location的详细和准确的监督,学习了更好的 3D 特征来scoring box 和refining locations以进行检测。
4.1.6 One-Stage versusTwo-Stage 3D Object Detection
表 7 显示,如果没有用于scoring box 和refining locations的阶段 II,我们的第一个提案阶段的proposal召回是可比的(80.90 与 80.99)。然而,在part-aggregation stage对 100 个proposal进行细化后,性能显着提高(82.92 对 84.33)。结果表明,预测的intra-object part locations有利于stage-II,我们的part-aggregation stage-II可以有效地聚合预测的intra-object part locations,以提高预测的 3D boxes的质量。stage-I 和 stage-II之间的性能差距(第一行与第三行,第二行与第四行)也表明,我们的stage-II通过重新对框proposal进行re-scoring并refining其框位置,显着提高了 3D 检测性能。
4.1.7 Effects of IoU Guided Box Scoring
如 3.3 节所述,我们应用归一化的 3D IoU 来估计预测的 3D 框的质量,将其用作最终 NMS(非最大抑制)操作中的ranking score以去除冗余框。表 8 显示,与 NMS 的传统分类得分相比,我们的 3D IoU guided scoring方法在所有难度级别上都略微提高了性能,这验证了使用归一化 3D IoU 来指示预测 3D 框质量的有效性。

4.1.8 Memory Cost of Anchor-Free and Anchor-Based Proposal Generation
如表9所示,我们通过计算不同对象类数量的参数数量和生成框的数量,比较了anchor-free 和anchor-based的proposal生成策略的模型复杂性。Part-A2-free 模型(使用 anchor-free proposal 生成策略)一致地生成 16k 个建议(即点云的点数),与类数无关,而生成的框数(即预定义的anchors )) 的 Part-A2-anchor 模型(具有anchor-based proposal生成),随着类的数量线性增加,因为每个类都有自己的anchor,anchor为每个类指定了对象大小。Part-A2-anchor模型的anchor数量达到211.2k,检测3类对象,这表明我们的anchor-free proposal生成策略是一种相对轻量级和内存高效的策略,尤其是对于多类。
我们还报告了KITTI[33]数据集上三类检测(汽车、行人和自行车)的推断GPU内存成本。推理由 PyTorch 框架在单个NVIDIA TITAN Xp GPU 卡上进行。 对于单个场景的推理,Part-A2-free 模型消耗大约 1.16 GB GPU 内存,而 Part-A2-anchor 模型消耗 1.63 GB GPU 内存。对于同时具有六个场景的推理,Part-A2-free 模型消耗约 3.42 GB GPU 内存,而 Part-A2-anchor 模型消耗 5.46 GB GPU 内存。它表明,Part-A2-free模型(采用anchor-free方案生成proposal)比Part-A2-anchor模型(采用anchor-based的方案生成proposal)具有更高的内存效率。
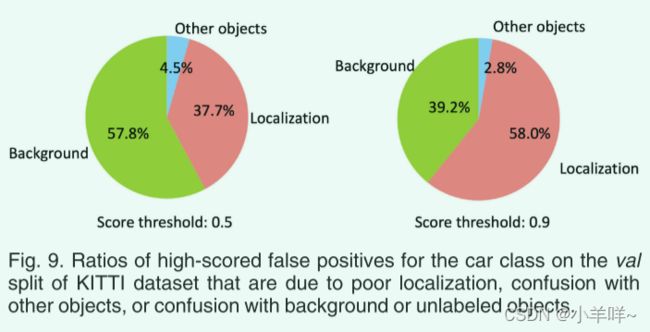
4.1.9 Analysis of False Positive Samples
图 9 显示了最佳性能 Part-A2-anchor 模型在具有不同分数阈值的 KITTI 验证数据集上的误报率,这是由于与背景混淆、定位不佳以及与其他类别的对象混淆造成的。可以看出,大多数误报来自背景和定位不佳。背景的混乱主要是由于稀疏的点云不能为一些背景提供足够的语义信息,如花台。仅使用激光雷达的3D检测方法可能会错误地将它们识别为前景物体,比如汽车,因为它们在点云中具有相似的几何形状。随着score阈值的增加,来自定位不佳的误报率显着增加。这是因为 3D 旋转 IoU 约束对 3D 检测的评估要求比 2D 检测的评估指标更严格。
4.2 Main Results and Comparison With State-of-the-Arts on KITTI Benchmark
在本节中,我们报告了在 KITTI 基准上与最先进的 3D 检测方法的比较结果。我们主要报告Part-A2-anchor模型的性能,因为它能够在我们的消融实验中达到更高的精度。
Comparison With State-of-the-art 3D Detection Methods.
我们在KITTI test split的3D检测基准和鸟瞰检测基准上评估我们的方法,其结果在KITTI的官方测试服务器上进行评估。结果如表10所示。

对于3D对象检测基准,通过仅使用激光雷达点云,我们提出的Part-A2网络在所有三个级别的所有难度级别上都优于所有之前的同行评审的仅使用激光雷达的方法,并且在最重要的“中等”难度级别上优于所有之前的多传感器方法,无论是汽车类还是自行车类。对于汽车、行人和骑自行车的人的鸟瞰检测,我们的方法在几乎所有难度级别上都大大优于以前的最先进方法。截至 2019 年 8 月 15 日,我们提出的 Part-A2-anchor 网络在 KITTI 3D Object Detection Benchmark [65] 的最重要汽车类 3D 对象检测排行榜的所有方法中排名第一,而我们的方法在自行车类的所有 LiDAR-only 方法中也排名第一。
Results on Validation Set.
对于最重要的汽车类别,我们的方法与 KITTI val split 的最新方法进行了比较,包括 3D 对象检测(如表 11 所示)和 3D 对象定位(如表 12 所示)。我们可以看到,在最重要的“中等”难度级别上,我们的 Part-A2 网络通过仅使用点云作为输入,在两个任务上都优于最先进的方法,并且有很大的差距。此外,我们的 Part-A2 网络在 KITTI 3D 对象检测 val split 的所有难度级别上都实现了新的最先进的性能,这证明了我们提出的 3D 对象检测方法的有效性。


如表13所示,我们还报告了我们的方法在验证集上对自行车人和行人的性能,以供参考。请注意,与 PointRCNN 相比,我们最新的方法 Part-A2-anchor 网络显着提高了骑车人的性能,同时在行人上取得了可比的结果。 行人性能稍差的原因可能是行人的方向很难从稀疏点云中识别出来,这对我们的 Part-A2-anchor 网络中的部分位置的预测是有害的。集成RGB图像的多传感器方法在检测行人等小物体方面具有优势。
Evaluation of Part-A2-Anchor Net for Predicting Intra-Object Part Locations.
我们的part-aware stage-I预测的intra-object part locations对于part-aggregation stage-II准确score the box 和refine the box location至关重要。在这里,我们通过以下指标评估预测的intra-object
part locations的准确性:

![]() 是predicted part location,
是predicted part location,![]() ground truth part location,
ground truth part location,![]() 是每个样本的前景点集合。最终的
是每个样本的前景点集合。最终的 ![]() 是所有样品的
是所有样品的![]() 的平均值。
的平均值。
如表 14 所示,对于最重要的汽车类别,我们预测的intra-object part location的平均误差为 6.28%,这表明part-aware网络准确地预测了intra-object part location,因为平均误差每米仅为![]() 。基于这种准确的intra-object part location,我们的部分聚合阶段 II 可以更好地对框进行评分,并通过利用预测的几何信息来细化框的位置。在这里,我们还报告了图 10 中 KITTI val split 的不同难度级别上预测的对象内部分位置的详细错误统计信息,以供参考。
。基于这种准确的intra-object part location,我们的部分聚合阶段 II 可以更好地对框进行评分,并通过利用预测的几何信息来细化框的位置。在这里,我们还报告了图 10 中 KITTI val split 的不同难度级别上预测的对象内部分位置的详细错误统计信息,以供参考。


通过计算Pearson相关系数,我们进一步分析了预测的intra-object part location误差与预测的3D边界框误差之间的相关性,Pearson相关系数为[-1,1],其中1表示完全正线性相关,-1表示完全负线性相关。在这里,我们使用 1-IoU 来表示预测的 3D 边界框的误差,其中 IoU 是预测的 3D 边界框与其最佳匹配的ground-truth 框之间的 3D Intersection-over-Union (IoU)。如表 15 所示,我们可以看到对象内部分位置的误差与预测的 3D 边界框的误差具有明显的正相关关系。整体相关系数为 0.531,相关系数最高的轴是高度方向的 z 轴,相关系数达到 0.552,这表明准确的对象内部分位置有利于预测更准确的 3D 边界框。
我们还报告了由于定位不准确导致的假阳性样本上的对象内部分位置误差(见表 14 的第 2 行),我们可以看到预测的部分位置误差在所有三个轴上都显着增加,这表明 不准确预测的对象内部分位置可能导致不令人满意的 3D 对象定位并降低 3D 对象检测的性能。

4.3 Qualitative Results
我们在图 11 中展示了我们提出的 Part-A2-anchor 网络在 KITTI 数据集的测试分割上产生的一些代表性结果。从图中我们可以看到,我们提出的部分感知网络可以通过仅使用点来估计准确的对象内部分位置 云作为输入,由我们设计的部分聚合网络聚合以生成准确的 3D 边界框。
5 CONCLUSION
在本文中,我们将我们的初步工作 PointRCNN 扩展到一个新颖的 3D 检测框架,即部分感知和聚合神经网络(Part-A2 网络),用于从原始点云中检测 3D 对象。 我们的part-aware stage-I学习通过使用来自ground-truth 3D box注释的免费对象内位置标签和前景标签来估计准确的对象内部分位置。 同时,3D proposal是通过两种替代策略生成的,即anchor-free 和基于anchor-based 的方案。 每个对象的预测intra-object part location通过新颖的 RoI 感知点云池化方案进行池化。 下面的part-aggregation stage-II可以更好地捕捉对象部分的几何信息,从而准确地对框进行评分并细化它们的位置。
我们的方法显着优于现有的 3D 检测方法,并在具有挑战性的 KITTI 3D 检测基准上实现了新的最先进的性能。 广泛的实验经过精心设计和进行,以研究我们提出的框架的各个组成部分。