GNN Tensorflow packages
tf framework定义
tf.name_scope()函数
tf.name_scope(name),用于定义python op的上下文管理器。
此上下文管理器将推送名称范围,这将使其中添加的所有操作的名称带有前缀。
例如,定义一个新的Python op my_op:
def my_op(a, b, c, name=None):
with tf.name_scope("MyOp") as scope:
a = tf.convert_to_tensor(a, name="a")
b = tf.convert_to_tensor(b, name="b")
c = tf.convert_to_tensor(c, name="c")
# Define some computation that uses `a`, `b`, and `c`.
return foo_op(..., name=scope)在执行时,张量a,b,c,将有名字MyOp/a,MyOp/b和MyOp/c。
变量:创建、初始化、保存和加载
变量:创建、初始化、保存和加载
当训练模型时,用变量来存储和更新参数。变量包含张量(Tensor)存放于内存的缓存区。建模时他们需要被明确地初始化,模型训练后它们必须被存储到磁盘。这些变量的值可以在之后模型训练和分析时被加载。
文本档描述两个TensorFlow类:
- tf.Variable类
- tf.train.Saver类
创建
当创建一个变量时,你将一个张量作为初始值传入构造函数Variable()。TensorFlow提供了一系列操作符来初始化张量,初始值是常量或随机值。
Notice:所有这些操作符都需要你指定张量的shape。
# Create two variables.
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),
name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")- 一个Variable操作存放变量的值。
- 一个初始化op将变量设置为初始值。这事实上是一个tf.assign操作
- 初始值的操作,例子中对biases变量的zeros操作也被加入了graph。
初始化
变量的初始化必须在模型的其他操作运行之前先明确地完成。最简单的方法就是添加一个给所有变量初始化的操作,并在使用模型之前首先运行那个操作。
使用tf.initialize_all_variables()添加一个操作对变量做初始化。该函数便捷地添加一个op来初始化模型的所有变量。
# Create two variables.
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),
name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
...
# Add an op to initialize the variables.
init_op = tf.initialize_all_variables()
# Later, when launching the model
with tf.Session() as sess:
# Run the init operation.
sess.run(init_op)
...
# Use the model
...tf.trainable_variables()函数
这个函数可以也仅可以查看可训练的向量。在生成变量variables时,无论是使用tf.Variable()还是tf.get_variable()生成变量,都会涉及到一个参数trainable,其默认为True。
__init__(
initial_value=None,
trainable=True,
collections=None,
validate_shape=True,
...
)
w1 = tf.Variable(tf.random_normal([256, 2000]), 'w1')
b1 = tf.get_variable('b1', [2000])
learning_rate = tf.Variable(0.5, trainable=False)
global_step = tf.Variable(0, trainable=False)
trainable_params = tf.trainable_variables()
trainable_params
-------------------------------------------
'''
Variable:0
b1:0
'''保存和加载
最简单的保存和恢复模型的方法是使用tf.train.Saver对象。构造器给graph的所有变量,添加save和restore opration。
- 用tf.train.Saver()创建一个Saver类管理模型中的所有变量。
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add an op to initialize the variables.
init_op = tf.initialize_all_variables()
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, initialize the variables, do some work, save the
# variables to disk.
with tf.Session() as sess:
sess.run(init_op)
# Do some work with the model.
..
# Save the variables to disk.
save_path = saver.save(sess, "/tmp/model.ckpt")
print "Model saved in file: ", save_path- 用一个Saver对象来恢复变量。
Notice,当你从文件中恢复变量时,不需要事先对它们做初始化。
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
with tf.Session() as sess:
# Restore variables from disk.
saver.restore(sess, "/tmp/model.ckpt")
print "Model restored."
# Do some work with the model
...tf tensor packages
tf.one_hot()函数
tf.one_hot()函数返回一个one-hot tensor。
one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None)
'''
参数功能如下:
1)indices中的元素指示on_value的位置,on_value默认值为1,不指示的地方都为off_value,off_value默认值为0。indices可以是向量、矩阵。
2)depth表示输出张量的尺寸,indices中元素默认不超过(depth-1),如果超过,输出为[0,0,···,0]
3)on_value默认为1
4)off_value默认为0
5)dtype默认为tf.float32
'''tf.one_hot()函数规定输入的元素indices从0开始,最大的元素值不能超过(depth - 1)
import tensorflow as tf
indices = [0,2,3,5]
depth1 = 6 # indices没有元素超过(depth-1)
a = tf.one_hot(indices,depth1)
-----------------------------------------
'''
a =
[[1. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1.]] # shape=(4,6)
'''tf.SparseTensor()函数
TensorFlow表示一个稀疏张量,作为三个独立的稠密张量:indices,values和dense_shape。
SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4])
------------------------------------------------------------------------
[[1, 0, 0, 0]
[0, 0, 2, 0]
[0, 0, 0, 0]]tf.random_normal()函数
tf.random_normal()函数用于从“服从指定正态分布的序列”中随机取出指定个数的值。
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
shape: 一维整数张量或 Python 数组.输出张量的形状.
mean: dtype 类型的0-D张量或 Python 值.正态分布的均值.
stddev:dtype 类型的0-D张量或 Python 值.正态分布的标准差.
dtype: 输出的类型.
seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
name:操作的名称(可选).输入
a = tf.Variable(tf.random_normal([2,2],seed=1))
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b)
输出:
[[-0.81131822 1.48459876]
[ 0.06532937 -2.44270396]]
[[-0.85811085 -0.19662298]
[ 0.13895047 -1.22127688]]
指定seed之后,a的值不变,b的值也不变tf.layers packages
tf.layers.conv1d()函数
一维卷积一般用于处理文本数据,like序列数据,如自然语言处理领域。
地址:CNN神经网络之一维卷积、二维卷积详解
一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。
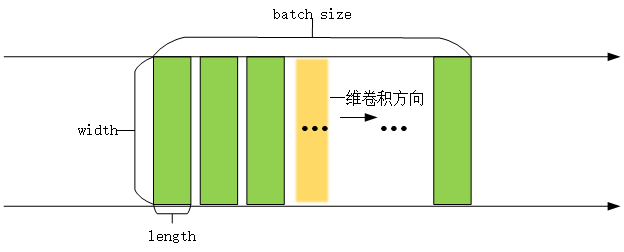
tf.layers.conv1d(
inputs, 张量数据输入,一般是[batch, width, length]
filters, 整数,输出空间的维度,可以理解为卷积核(滤波器)的个数
kernel_size, 单个整数或元组/列表,指定1D(一维,一行或者一列)卷积窗口的长度。
strides=1, 单个整数或元组/列表,指定卷积的步长,默认为1
padding='valid', "SAME" or "VALID" (不区分大小写)是否用0填充,SAME用0填充;VALID不使用0填充,舍去不匹配的多余项。
data_format='channels_last', 一个字符串,一个channels_last(默认)或channels_first。输入中维度的排序。channels_last:对应于形状的输入(batch, length, channels);channels_first:对应于形状输入(batch, channels, length)
dilation_rate=1,
activation=None, 激活函数
use_bias=True, 该层是否使用偏差
kernel_initializer=None, 卷积核的初始化
bias_initializer=tf.zeros_initializer(), 偏置向量的初始化器
kernel_regularizer=None, 卷积核的正则化项
bias_regularizer=None, 偏置的正则化项
activity_regularizer=None, 输出的正则化函数
kernel_constraint=None,
bias_constraint=None,
trainable=True, Boolean,如果True,将变量添加到图collection中
name=None,
reuse=None Boolean,是否使用相同名称重用前一层的权重
)import tensorflow as tf
x = tf.get_variable(name="x", shape=[32, 512, 1024], initializer=tf.zeros_initializer)
x = tf.layers.conv1d(
x,
filters=1, # 输出的第三个通道是1
kernel_size=512, # 不用管它是多大,都不影响输出的shape
strides=1,
padding='same',
data_format='channels_last',
dilation_rate=1,
use_bias=True,
bias_initializer=tf.zeros_initializer())
print(x) # Tensor("conv1d/BiasAdd:0", shape=(32, 512, 1), dtype=float32)1. 输入数据的维度为[batch, data_length, data_width]=[32, 512, 1024],一般输入数据input第一维为batch_size,此处为32,意味着有32个样本,第二维度和第三维度分别表示输入的长和宽(512,1024)
2. 一维卷积核是二维的,也有长和宽,长为卷积核的数量kernel_size=512,因为卷积核的数量只有一个,所以宽为输入数据的宽度data_width=1024,所以一维卷积核的shape为[512,1024]
3. filteres是卷积核的个数,即输出数据的第三维度。filteres=1,第三维度为1
4. 所以卷积后的输出数据大小为[32, 512, 1]
tf.nn packages
tf.nn active_functions
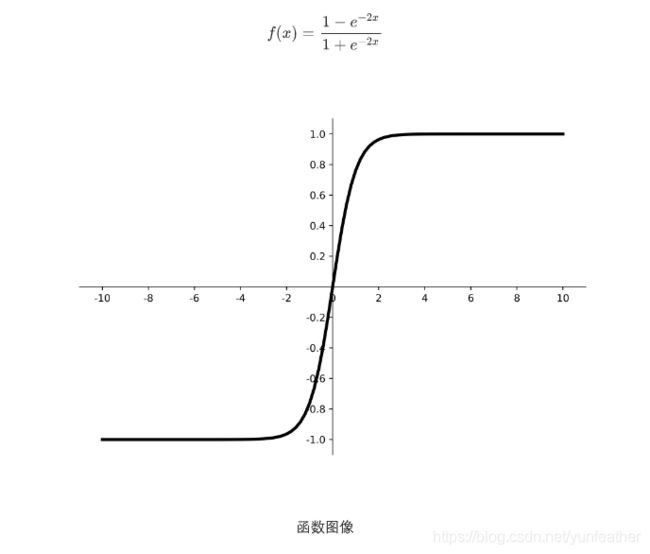
tf.tanh()函数
tf.nn.softmax()函数
tf.nn.softmax()函数用于归一化。
tf.nn.softmax(logits,axis=None,name=None,dim=None)
logits:一个非空的Tensor。必须是下列类型之一:half, float32,float64
axis:将在其上执行维度softmax。默认值为-1,表示最后一个维度
name:操作的名称(可选)
dim:axis的已弃用的别名
输入: 全连接层(往往是模型的最后一层)的值
输出: 归一化的值,含义是属于该位置的概率;
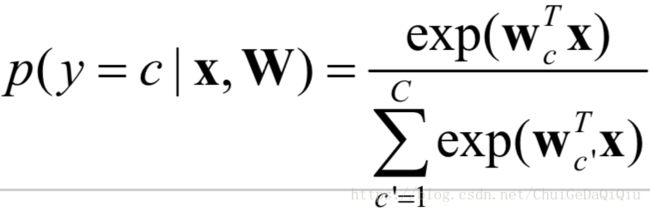
tf.sparse_softmax()函数
将softmax应用于批量的N维SparseTensor。
tf.nn.leaky_relu()函数
tf.nn.leaky_relu(
features, features:一个Tensor,表示预激活
alpha=0.2, alpha:x<0时激活函数的斜率
name=None) 操作的名称(可选)
参数:
返回值:激活值

优点:
1.能解决深度神经网络(层数非常多)的“梯度消失”问题,浅层神经网络(三五层那种)才用sigmoid 作为激活函数。
2.它能加快收敛速度。
tf.nn optimization优化
tf.nn.dropout()函数
tf.nn.dropout()是tensorflow 将元素随机置零以防止过拟合的函数,它一般用于全连接层。
tf.nn.dropout(
x, rate, noise_shape=None, seed=None, name=None
)
dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。
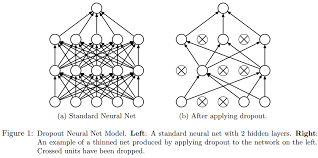
但在测试及验证中:每个神经元都要参加运算,但其输出要乘以概率p。
Dropout对于正则化DNN模型很有用。输入元素被随机设置为零(其他元素被重新缩放)。这鼓励每个节点独立使用,因为它不能依赖其他节点的输出。
更精确地:x的元素有rate概率设置为0。
x = tf.ones([3, 5])
y = tf.nn.dropout(x, rate=0.5, seed=1)
print(x)
print(y)
------------------------------------
'''
tf.Tensor(
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]], shape=(3, 5), dtype=float32)
tf.Tensor(
[[0. 2. 0. 0. 2.]
[0. 0. 0. 2. 2.]
[2. 0. 0. 0. 0.]], shape=(3, 5), dtype=float32)
'''tf.nn loss_function损失函数
tf.nn.sparse_softmax_cross_entropy_with_logits()函数
多分类交叉熵计算函数--进行softmax和loss计算,它适用于每个类别相互独立且排斥的情况,例如一幅图只能属于一类。
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=None, logits=None, name=None)
'''
labels: shape为[batch_size],labels[i]是[0, num_classes]的一个索引,type为int32或int64.
logits: shape为[batch_size, num_classes],type为float32或float64
name:
'''import tensorflow as tf
labels_sparse = [0, 2, 1]
# 索引,即真实的类别
# 0表示第一个样本的类别属于第1类;
# 2表示第二个样本的类别属于第3类;
# 1表示第三个样本的类别属于第2类;
logits = tf.constant(value=[[3, 1, -3], [1, 4, 3], [2, 7, 5]],
dtype=tf.float32, shape=[3, 3])
loss_sparse = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels_sparse,
logits=logits)
with tf.compat.v1.Session() as sess:
print("loss_sparse: \n", sess.run(loss_sparse))
--------------------------------------------------------
'''
loss_sparse:
[0.12910892, 1.3490121, 0.13284527]
'''tf operations
tf calculations计算
加:tf.add( x,y, name=None):
最常见的情况,将x矩阵加到y矩阵上。
加:tf.nn.bias_add()函数
tf.nn.bias_add(value, bias, name=None)
将bias向量加到value矩阵上,是向量与矩阵的每一行进行相加,得到的结果和value矩阵大小相同。
加:tf.sparse_add()函数
两个稀疏张量相加,其中至少有一个是 SparseTensor.
sparse_add(
a,
b,
thresh=0 )乘:tf.multiply()函数
两个矩阵中对应元素各自相乘。
格式: tf.multiply(x, y, name=None)
参数:
x: 一个类型为:half, float32, float64, uint8, int8, uint16, int16, int32, int64, complex64, complex128的张量。
y: 一个类型跟张量x相同的张量。
返回值: x * y element-wise.
import tensorflow as tf
a = tf.constant([[3, 2], [5, 1]])
b = tf.constant([[1, 6], [2, 9]])
c = tf.multiply(a, b)
sess = tf.Session()
print sess.run(c)
输出:
[[ 3 12] 【3*1,2*6】
[10 9]] 【5*2,1*9】乘:tf.matmul()函数
矩阵a乘以矩阵b,生成a*b
# 2-D tensor `a`
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3]) => [[1. 2. 3.]
[4. 5. 6.]]
# 2-D tensor `b`
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2]) => [[7. 8.]
[9. 10.]
[11. 12.]]
c = tf.matmul(a, b) => [[58 64]
[139 154]]乘:tf.sparse_tensor_dense_matmul()函数
用稠密矩阵B乘以SparseTensor矩阵A
import tensorflow as tf
'''
[[1,0],
[0,1]]
'''
st = tf.SparseTensor(values=[1, 2], indices=[[0, 0], [1, 1]], dense_shape=[2, 2])
dt = tf.ones(shape=[2,2],dtype=tf.int32)
result = tf.sparse_tensor_dense_matmul(st,dt)
sess = tf.Session()
with sess.as_default():
print(result.eval())print结果:
[[1 1]
[2 2]]
乘:tf.tensordot()函数
tf.tensordot()函数是tensorflow中tensor矩阵相乘的api,可以进行任意维度的矩阵相乘。
tf shape形状
tf.transpose()转置函数
Defined in tensorflow/python/ops/array_ops.py.
# 'x' is [[1 2 3]
# [4 5 6]]
tf.transpose(x) ==> [[1 4]
[2 5]
[3 6]] tf.set_shape()函数和reshape()函数
tensorflow中,张量具有静态形状和动态形状。
静态形状:创建一个张量或者由操作推导出一个张量时,初始状态的形状。
- tf.Tensor.get_shape()函数,获取静态形状
- tf.Tensor.set_shape()函数,用于更新tensor对象的静态形状shape,通常用于在不能直接推断的情况下。
动态形状:一种描述原始张量在执行过程中的形状(动态变化)
- reshape,用于动态地创建一个具有不同shape的新的tensor
tf.sparse_reshape()函数
重塑一个SparseTensor以表示新密集形状中的值。
tf 降维 dimensionality reduction
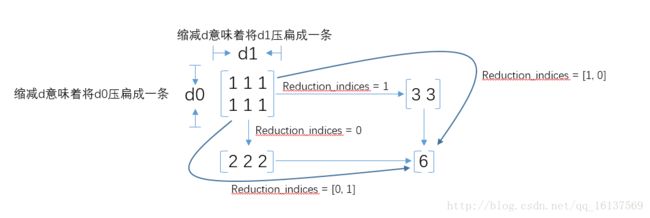
加:tf.reduce_sum()函数
reduce_sum 应该理解为压缩求和,用于降维(是从维度上考虑的)
tf.reduce_sum(input_tensor,axis=None,keepdims=None,name=None,reduction_indices=None,keep_dims=None)
平均:tf.reduce_mean()函数
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
reduce_mean(input_tensor, # 输入的待降维的tensor;
axis=None, # 指定的轴,如果不指定,则计算所有元素的均值;
keep_dims=False, # 是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
name=None, # 操作的名称;
reduction_indices=None) # 在以前版本中用来指定轴,已弃用;import tensorflow as tf
x = [[1,2,3],
[1,2,3]]
xx = tf.cast(x,tf.float32)
mean_all = tf.reduce_mean(xx, keep_dims=False)
mean_0 = tf.reduce_mean(xx, axis=0, keep_dims=False)
mean_1 = tf.reduce_mean(xx, axis=1, keep_dims=False)
with tf.Session() as sess:
m_a,m_0,m_1 = sess.run([mean_all, mean_0, mean_1])
------------------------------------------------
print m_a # output: 2.0
print m_0 # output: [ 1. 2. 3.]
print m_1 #output: [ 2. 2.]
------------------------------------------------
# if keep_dims=True
print m_a # output: [[ 2.]]
print m_0 # output: [[ 1. 2. 3.]]
print m_1 #output: [[ 2.], [ 2.]]tf.squeeze()函数
def squeeze(input, axis=None, name=None, squeeze_dims=None)tf.squeeze()函数返回一个张量,这个张量是将原始input中所有维度为1的那些维都删掉
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1]
tf.shape(tf.squeeze(t)) # [2, 3]tf.expand_dims()函数
tf.expand_dims(
input, axis=None, name=None, dim=None)
- input:输入,tensor类型
- axis:增加维度的位置,比如:0表示在input的第一维增加一维,shape(a)=[2,3],操作之后数据维度为[1,2,3]。如果是1,shape=[2,1,3]
- name:操作的名称(可选)。
tf.concat()函数
tf.concat([tensor1, tensor2, tensor3,...], axis)
axis=0 代表在shape第0个维度上拼接
axis=1 代表在shape第1个维度上拼接
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 1) # [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
# tensor t3 with shape [2, 3]
# tensor t4 with shape [2, 3]
tf.shape(tf.concat([t3, t4], 0)) # [4, 3]
tf.shape(tf.concat([t3, t4], 1)) # [2, 6]