pyG利用MessagePassing实现GCN(了解pyG的底层逻辑)
目录
必备了解
利用MessagePassing实现GCN
利用MessagePassing实现GCN是pyG官网的例子,后面graphSAGE和GAT是根据公式和pyG例子写的! 这个东西是CS224W: machine learing with graph的作业的一部分!
感觉这部分还是需要了解透,因为自己写论文搭建模型,就得自己利用MessagePassing类实现自己的模型。
注:下面的内容中我准备把代码给非常好几块!因为我想在代码下面注释它对应的公式,但是注释不了(公式不好打),所有把代码分开,代码下面增加图片和文字!!所有的代码都是顺序排列!直接复制使用,得注意缩进!
必备了解
因为pyG里面很多东西都封装好了,我们写自己模型时,也不是所有的部分都要自己写。就下面我自己实现的graphSAGE,GAT而言,主要需要实现的部分在forward函数,message函数和aggregate函数!其他部分我们都是自动调用封装好的部分。下边介绍一些,pyG里面默认的东西!
第一个,一般模型用到的输入是节点特征X和边edge_index。
在pyG里面,有两个表示x_i,x_j。x_i 表示聚合信息时的中心节点,x_j表示邻居节点。一般来讲,输入的edge_index为[[1,2],[4,6]],shape为2×E,两行,E表示边的数量,第一行表示边的起始点,第二行表示边的终点。那么对于这个输入,x_i =[1,2] , x_j = [4,6], 我们把起点视为中心,终点视为邻居!!
第二个,这个是理解后面代码非常非常重要的一个理解!!如果一个图有N个节点,那么应该有几个邻居节点?几个中心节点??中心节点应该有N个,每个节点都可以作为中心聚集邻居的信息;邻居节点也有N个,在其他节点是中心的时候,每个节点都会被当作邻居节点!所以可以说,中心节点和邻居节点时相同的,都是那N个节点!!
举个例子说明!在GCN中,

节点 i 的邻居需要做个线性变换,因为这个线性变换是通用的(其他节点邻居做变换时也是用这个变换参数), 那么是不是每个邻居节点都会执行相同线性变换!那么我们是不是可以直接用线性层去处理输入的X, x = self.linear(x)。至于怎么把I的邻居节点信息求和,在其他的地方处理!
第三个,一般来讲公式中的很大一部分会在forward函数完成,并不是像介绍GNN那样,message操作在message函数中完成,aggregate操作在aggregate函数中完成!
第四个,: 当计算 W* Concat(X1,X2)时, 基本上采取 W1*X1+W2*X2 来代替
利用MessagePassing实现GCN
这个是官方示例!
首先给大家展示一下,GCN实际实现时它计算迭代的公式
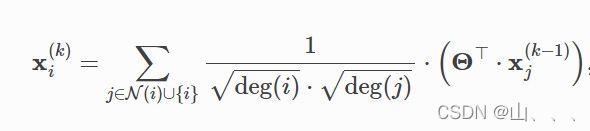
下面是代码:
第一个函数 init ,用来初始化和声明一些需要用到的部分!
这个self.lin就是GCN公式中的
# 这个是 pyG实现GCN,调用MessagePassing的示例
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" aggregation (Step 5).
self.lin = torch.nn.Linear(in_channels, out_channels)
接下来是forward函数,一般来讲公式中的很大一部分会在这完成,并不是像介绍GNN那样,message操作在message函数中完成,aggregate操作在aggregate函数中完成!
第一步,他在edge_index中增加了自环。因为每次聚集信息时,不仅仅会聚集邻居的信息还会聚集自己的信息,加入自环后,自己就相当于自己的邻居。因此在聚集邻居的操作时,就一同聚集了自己的信息!
第二步,它直接使用了这个线性层,那么这个时候,我们得到的x,就不再是x,而是表示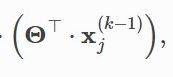
第三步,它计算了前面这个标准化
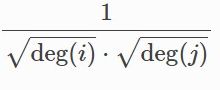
第四步,它调用了propagate函数,这个函数就会去调用 message函数和aggregate函数,按照我的理解,先调用message函数,message函数的输出会被当作aggregate函数的输入!
需要注意的是,propagate传递参数,x不是节点特征了,而是经过线性变换的!
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: Add self-loops to the adjacency matrix.
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: Linearly transform node feature matrix.
x = self.lin(x) # !!!!这一步就是massage中W H 那一步了!!!
## 直接对所有的节点做message中的这个操作,
#因为所有节点都会成为邻居节点,成为邻居节点后的操作是相同的
# Step 3: Compute normalization.
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: Start propagating messages.
return self.propagate(edge_index, x=x, norm=norm)
对应一下公式,你会发现理论中的message操作以及在forward函数中做过了!所以在message中其实不需要做些什么!
以及在message函数中,它的默认输入参数中有x_j,我个人认为这个地方应该是调用propagate函数后,它调用了一些封装好的函数,就得到了这个x_j。在这个x_j里面存的数据,应该是edge_index中的第二行,但是对应数据应该是用propagate传递的参数x给替换过了!所以对于现在这个模型,此处的x_j,应该就相当于是edge_index中第二行数据经过线性变换的结果。
我觉得,如果在forward函数中在调用propagate函数时,如果传递参数的X变化,这个X_j也会相应的变化!!
def message(self, x_j, norm):
# x_j has shape [E, out_channels]
# Step 4: Normalize node features.
# 因为已经做过W H 这一步 ,这里只需要标准化就行了Suppose we have 4 nodes, so $x_{central}$ and $x_{neighbor}$ are of shape 4 * d. We have two edges (1, 2) and (3, 0). Thus, $x\_i$ is obtained by $[x_{central}[1]^T; x_{central}[3]^T]^T$, and $x\_j$ is obtained by $[x_{neighbor}[2]^T; x_{neighbor}[0]^T]^T$
return norm.view(-1, 1) * x_j在这个aggregate函数中,我认为,这个inputs就是message函数的输出,index应该就是edge_index中的第一行! 这个scatter函数就完成了,对于节点i的邻居信息求和的操作——当index相同时,其实就是中心节点相同时,对于inputs做求和操作,也就是对邻居信息求和!
def aggregate(self, inputs, index, dim_size = None):
out = scatter(inputs, index, dim=self.node_dim, dim_size=dim_size, reduce='sum')
return out
可以稍微了解一下scatter函数!
torch_scatter.scatter详解_StarfishCu的博客-CSDN博客_scatter_meanscatter方法通过src和index两个张量来获得一个新的张量。torch_scatter.scatter(src: torch.Tensor, index: torch.Tensor, dim: int = - 1, out: Optional[torch.Tensor] = None, dim_size: Optional[int] = None, reduce: str = 'sum') → torch.Tensor原理如图,根据index,将index相同值对应的src元素进行对应定义的计https://blog.csdn.net/StarfishCu/article/details/108853080