使用pytorch搭建ResNet并基于迁移学习训练
1. 介绍
在博文经典网络ResNet讲解,详细介绍了ResNet网络。网络的机构参数如下:
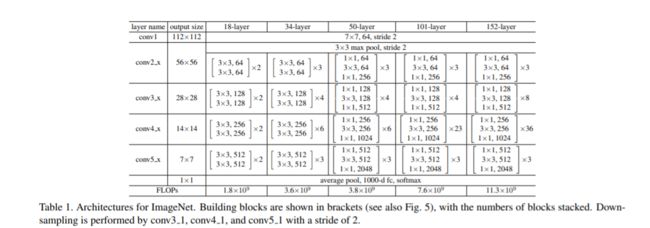
通过这张表格可以发现无论是18层,34层,50层,101层,还是152层网络。他们的网络框架基本上都是一样的。
- 首先通过一个
7x7的卷积层,然后通过3x3的最大池化下采样,紧接着再通过conv2_x所对应的一系列残差结构,紧接着conv3_x所对应的一系列残差结构,conv4_x所对应的一系列残差结构,conv5_x所对应的一系列残差结构。然后最后在跟上一个平均池化下采样以及我们的全连接输出层
2. ResNet 代码搭建
2.1 定义残差结构
在经典网络ResNet讲解,我们讲过对于18层,34层的ResNet,它的残差结构与50层,101层,152层它的结构是不一样的。
2.1.1 搭建 18层,34层的残差结构
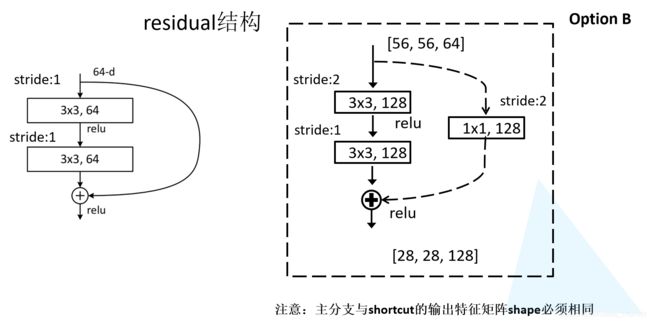
- 定义
BasicBlock类:18层,34层ResNet的残差结构 expansion参数,对应我们残差结构主分支所采用的卷积核个数有没有发生变化,比如18层和34层的残差结构中第一层和第二层的卷积核个数是一模一样的,所以就设置expansion=1. 在搭建50,101,152层的残差结构主分支的所采用的卷积核个数是不一样的。比如第一层与第二层是一样的,第三层是第一层的4倍。
class BasicBlock(nn.Module):
expansion=1
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=out_channel
,kernel_size=3,stride=stride,padding=1,bias=False)
self.bn1=nn.BatchNorm2d(out_channel)
self.relu=nn.Relu()
self.conv2=nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3, stride=1,padding=1,bias=False)
self.bn2=nn.BatchNorm2d(out_channel)
self.downsample=downsample
def forward(self,x):
identity=x
if self.downsample is not None:
identity=self.downsample(x)
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
out +=identity
out=self.relu(out)
return out
- 通过
BasicBlock构建满足虚线和实线的残差结构,downsample为None对应是实线残差结构,downsample不为None则为虚线的残差结构。在conv3_x,conv4_x,conv5_x对应的一系列残差结构中,它们的第一层都是虚线的残差结构,因为每一层第一个残差结构有降维的作用。比如conv3_x所对应的一系列残差结构,它的输入特征矩阵为conv2_x的输出特征矩阵shape为(56x56x64),而conv3_x的期望的输出特征矩阵shape为28x28x128,所以需要将输入特征矩阵缩放到我们需要的维度,因此有downsample参数。所以conv3_x,conv4_x,conv5_x对应的一系列残差结构中,它们的第一层都是上图中的虚线的残差结构。 - 接下来就是conv1,使用
nn.Conv2d,它的卷积核大小无人实线残差结构还是虚线残差结构,它的第1层,第2层的卷积核大小都是等于3的。它的stride值为我们传入的参数,默认为1.如果stride=1就是对应实线的残差结构,没有改变特征矩阵的宽高;当stride=2时,那么就对应虚线残差结构,因为在虚线残差结构的第一个卷积层需要将输入特征矩阵的宽高缩减为原来的一半,所以需要将stride设置为2. 注意使用了BN的话,就不需要使用bias,因此将bias设置为False。 - 接下来在定义bn1以及relu激活函数,紧接着在定义第二层卷积层conv2,通过图1的残差结构图可以发现无论虚线还是实线残差conv2的stride都是等于1的,所以stride设置为1,然后定义bn2,以及下采样方法downsample等于我们传入的downsample.
- 最后定义正向传播forward过程:捷径分支
identity默认为输入x,对应的是下采样函数self.downsample等于None的话,也就是实线残差结构,可以直接将捷径分支identity与主分支的输出进行Add相加。如果self.downsample不等于None的话,说明对应的是虚线残差结构,就将捷径分支identity通过self.downsample进行下采样identity=self.downsample(x),然后与主分支的输出进行Add相加,然后通过Relu激活函数输出。
2.1.2 搭建 50层,101层,152层的残差结构
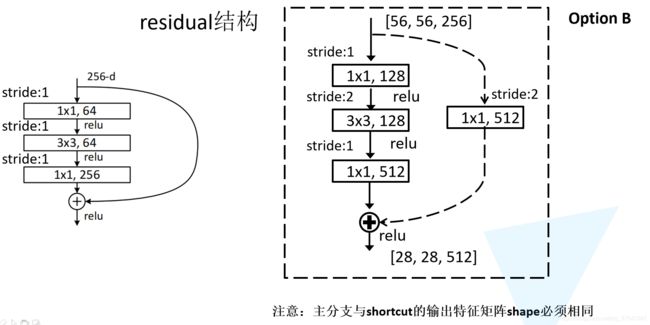
- 定义
Bottleneck类
class Bottleneck(nn.Module):
expansion=4
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(Bottleneck,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=out_channel,
kernel_size=1,stride=1,bias=False) #squeeze channel
self.bn1=nn.BatchNorm2d(out_channel)
#--------------------------------------------------------
self.conv2=nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn2=nn.BatchNorm2d(out_channel)
#--------------------------------------------------------
self.conv3=nn.Conv2d(in_channels=out_channel,out_channels=out_channel*self.expansion,
kernel_size=1,stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu=nn.Relu(inplace=True)
self.downsample=downsample
def forward(self,x):
identity = x
if self.downsample is not None:
identity =self.downsample(x)
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
out=self.relu(out)
out=self.conv3(out)
out=self.bn3(out)
out +=identity
out =self.relu(out)
return out
conv2层对于实线残差结构stride =1,对于虚线残差结构stride=2,所以stride是一个传入的参数,默认为1,根据传入的stride值进行调整- 对于
conv3而言,根据图2可以发现,实线和虚线残差结构stride都是为1。但它的卷积核个数是con1,conv2的4倍,所以这里的输出out_channel=out_channel*self.expansion(expansion=4)
2.2 ResNet网络结构搭建
定义ResNet类,继承`nn.Module,构造函数的参数包括:
block:残差结构,如果ResNet18,34,block 传入的就是BasicBlock。如果是ResNet50,101,152则block为Bottleneck残差结构blocks_num:定义所使用残差结构的数目, 这个是一个列表参数。对于ResNet34网络结构而言,我们的blocks_num=[3,4,6,3];对于ResNet101:blocks_num=[3,4,23,3]- num_classes:分类个数,默认1000
- include_top: 这个参数是为了方便以后我们能够在ResNet网络的基础上,去搭建更加复杂的网络,默认为True。include_top 之前的网络用来提取有效特征,include_top=True的话,加上了分类全连接层。
搭建网络的代码
class ResNet(nn.Module):
def __init__(self,block,blocks_num,num_classes=1000,include_top=True):
super(ResNet,self).__init__()
self.include_top=include_top
self.in_channel=64
#----------------7x7 conv --------------------
self.conv1=nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(self.in_channel)
self.relu=nn.Relu(inplace=True)
#----------------3x3 max pool ----------------
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
#------------------conv2_x--------------------
self.layer1 = self._make_layer(block,64,blocks_num[0])
#------------------conv3_x--------------------
self.layer2 = self._make_layer(block,128,blocks_num[1],stride=2)
#------------------conv4_x--------------------
self.layer3 = self._make_layer(block,256,blocks_num[2],stride=2)
#------------------conv5_x--------------------
self.layer4 = self._make_layer(block,512,blocks_num[3],stride=2)
#------------------average pool and fc--------
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d(1,1) #output size=(1,1)
self.fc=nn.Linear(512*block.expansion,num_classes)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
def _make_layer(self,block,channel,block_num,stride=1):
downsample = None
#------------------捷径分支是否需要downsample: 宽高压缩 或者 改变通道来判断
if stride !=1 or self.in_channel!=channel*block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,
stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
#conv2_x,conv3_x,conv4_x,conv5_x 一系列残差结构的第一层,只有第一层存在虚线残差结构,由于需要调整宽高或通道
layers = []
layers.append(block(self.in_channel,channel,downsample=downsample,stride=stride))
self.in_channel=channel*block.expansion
# conv2_x,conv3_x,conv4_x,conv5_x除了第一层外,其他层都是实线残差结构,可以直接堆叠
for _ in range(1,block_num):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.maxpool(x)
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
x=self.layer4(x)
if self.include_top:
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
_make_layer代码说明
- 利用_make_layer来搭建
conv2_1,conv3_1,conv4_1,conv5_1一系列残差结构 - 对于浅层网络
resnet18,resnet34他们conv2_x对应的输入输出特征矩阵shape是一样的,不需要虚线的残差;而对于更深层的网络resnet50/101/152,通过最大池化下采样之后它所得到的特征矩阵shape为56x56x64,但是它们conv2_x输出的特征矩阵是56x56x256,所以对于resnet50/101/152网络中的conv2_x所对应的一系列残差结构,它们的第一层也是虚线的残差结构。而对于conv3_1,conv4_1,conv5_1它不仅调整了channel,还改变了特征矩阵的高和宽。所以代码中对conv2_1,conv3_1,conv4_1,conv5_1的第一层捷径分支是否需要downsample进行判断,利用特征矩阵的宽高是否需要压缩 或者通道的改变来判断
if stride !=1 or self.in_channel!=channel*block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,
stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
conv2_x,conv3_x,conv4_x,conv5_x除了第一层外,其他层都是实线残差结构,可以直接堆叠
for _ in range(1,block_num):
layers.append(block(self.in_channel,channel))
ResNet34网络搭建
- ResNet34 是浅层的网络,对应的残差block是
BasicBlock - ResNet34中的
conv2_1,conv3_1,conv4_1,conv5_1一系列残差结构,所用的残差结构数目列表为[3, 4, 6, 3],即conv2_1堆叠了3个BasicBlock,conv3_1堆叠了4个BasicBlock,conv4_1堆叠了6个BasicBlock,conv5_1堆叠了3个BasicBlock
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
ResNet101网络搭建
- ResNet101 是深层的网络,对应的残差block是
Bottleneck - ResNet101中的
conv2_1,conv3_1,conv4_1,conv5_1一系列残差结构,所用的残差结构数目列表为[3, 4, 23, 3],即conv2_1堆叠了3个Bottleneck,conv3_1堆叠了4个Bottleneck,conv4_1堆叠了23个Bottleneck,conv5_1堆叠了3个Bottleneck
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
3. 基于迁移学习训练
- 首先打开
train.py脚本,由于需要使用迁移学习的方法,所以需要下载pytorch官方所提供的resnet网络的预训练模型.
import torchvison.models.resnet
- 通过按住
ctr+鼠标左键点击resnet,就可以跳转到官方所实现的resnet网络的源码中,找到model_urls根据链接就可以下载对应的resnet预训练权重了。 - 我们使用resnet34网络,因为对于花数据集不需要使用特别大的网络将链接复制到浏览器上进行下载。修改下载预训练权重名为
resnet34-pre.pth
3.1 图像预处理
- 对
训练图像进行:随机裁剪、水平翻转,ToTensor(像素归一化到(0,1),并且将shape从(H,W,C)调整为(C,H,W)), 图像减均值/标准差 - 对
验证图片进行:Resize,中心裁剪,ToTensor, 图像减均值/标准差
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
3.2 DataLoader
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path+"train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
- 当使用linux系统的话,记得将线程个数
num_works设置为>0的值,就能加速图像预处理的过程
3.3 载入预训练权重
net = resnet34()
# load pretrain weights
model_weight_path = "./resnet34-pre.pth"
missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
inchannel = net.fc.in_features
net.fc = nn.Linear(inchannel, 5)
net.to(device)
- 载入模型:1.首先通过
torch.load将预训练模型参数载入到内存中,但是我们还没有载入到模型当中,此时所得到的是一个字典。2.通过load_state_dict将权重字典载入模型中。注意因为预训练权重的全连接1000类的,如果我们resnet34(num_classes=5),载入预训练权重会出错。可以通过设置strict=False。或者将预训练权重参数删掉全连接参数进行加载。 - net.fc对应我们定义的
self.fc,通过net.fc.in_features获得全连接的输入channel,因为花卉数据集总共有5类,因此这里重新定义了全连接层
net.fc = nn.Linear(inchannel, 5)
3.4 模型训练
for epoch in range(3):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
- 记得训练时加上
net.train(),验证的时候加上net.eval(),千万不要忘了。因为这两个方式它能够控制网络中BatchNormalizion它的一个状态的。在训练和验证过程中BatchNormalizion的执行方法是不一样的
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。而在测试时,比如进行一个样本的
预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
BN训练与测试的差异:https://zhuanlan.zhihu.com/p/61725100
项目github代码:https://github.com/yuanxinshui/deep-learning-for-image-processing/tree/master/pytorch_classification/Test5_resnet
花朵数据集:https://download.csdn.net/download/weixin_38346042/85912871