深入理解Pytorch负对数似然函数(torch.nn.NLLLoss)和交叉熵损失函数(torch.nn.CrossEntropyLoss)
在看Pytorch的交叉熵损失函数torch.nn.CrossEntropyLoss官方文档介绍中,给出的表达式如下。不免有点疑惑为何交叉熵损失的表达式是这个样子的
loss ( y , class ) = − log ( exp ( y [ class ] ) ∑ j exp ( y [ j ] ) ) = − y [ class ] + log ( ∑ j exp ( y [ j ] ) ) \operatorname{loss}(y, \text { class })=-\log \left(\frac{\exp (y[\text { class }])}{\sum_{j} \exp (y[j])}\right)=-y[\text { class }]+\log \left(\sum_{j} \exp (y[j])\right) loss(y, class )=−log(∑jexp(y[j])exp(y[ class ]))=−y[ class ]+log(j∑exp(y[j]))
这个表达式y是网络的输出向量,是一组实数值,衡量每个类别的score值,而class则是样本类别的标签值,也是是数值。为何 − y [ class ] + log ( ∑ j exp ( y [ j ] ) -y[\text { class }]+\log (\sum_{j} \exp (y[j]) −y[ class ]+log(∑jexp(y[j])就能算出损失值呢?
本文参考了相关资料,对这个表达式推导过程做了个总结,如果你有和我一样的困惑,希望本文对你有所帮助。
让我们先从损失函数,以及交叉熵推导过程说起。
损失函数的意义以及作用
在监督式学习的模型训练中,损失函数主要是用来计算在给定样本输入由模型的计算的输出 y ^ \hat{y} y^ 与真实的标签 y y y之间的距离,给模型的优化过程指明方向。在多分类任务重,经常用到的就是交叉熵损失函数。 要理解交叉熵,先从信息量,熵说起。
信息量
假设 X X X是一个离散型随机变量,其取值集合为 χ \chi χ,概率分布函数 p ( x ) = Pr ( X = x ) , x ∈ χ p(x)=\operatorname{Pr}(X=x), x \in \chi p(x)=Pr(X=x),x∈χ ,则定义事件 X = x 0 X=x0 X=x0 的信息量为:
I ( x 0 ) = − log ( p ( x 0 ) ) I\left(x_{0}\right)=-\log \left(p\left(x_{0}\right)\right) I(x0)=−log(p(x0))
由于是概率所以 p ( x 0 ) p(x0) p(x0)的取值范围是 [ 0 , 1 ] [0,1] [0,1],绘制为图形如下:
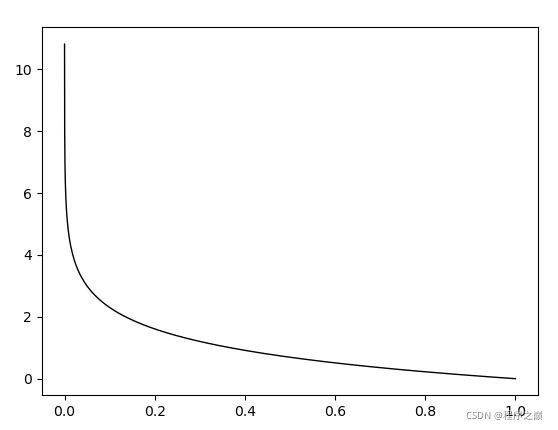
- 从这个图形可以看出来 I ( x 0 ) I\left(x_{0}\right) I(x0)的取值范围式0到正无穷大。
- 随着概率 p ( x 0 ) p(x0) p(x0)的越小, I ( x 0 ) I\left(x_{0}\right) I(x0)的取值越大,也就是信息量越大。
- 随着概率 p ( x 0 ) p(x0) p(x0)的越大, I ( x 0 ) I\left(x_{0}\right) I(x0)的取值越大,也就是信息量越小。
熵
有了信息量的定义,而熵用来表示所有信息量的期望,即:
H ( X ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) H(X)=-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(p\left(x_{i}\right)\right) H(X)=−i=1∑np(xi)log(p(xi))
其中n代表所有的n种可能性
对于n取值为2则表示实验结果只有两种可能性,因为两种可能性的概率之和为1,如果其中一个结果的的概率是 p ( x ) p(x) p(x)则另外一个结果是 ( 1 − p ( x ) ) (1-p(x)) (1−p(x))将上面所有的求和公式结果展开可以得到只有两个结果的熵的表达式为
H ( X ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) = − p ( x ) log ( p ( x ) ) − ( 1 − p ( x ) ) log ( 1 − p ( x ) ) \begin{aligned} H(X) &=-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(p\left(x_{i}\right)\right) \\ &=-p(x) \log (p(x))-(1-p(x)) \log (1-p(x)) \end{aligned} H(X)=−i=1∑np(xi)log(p(xi))=−p(x)log(p(x))−(1−p(x))log(1−p(x))
相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异
KL散度的计算公式:
D K L ( p ∥ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) D_{K L}(p \| q)=\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(\frac{p\left(x_{i}\right)}{q\left(x_{i}\right)}\right) DKL(p∥q)=i=1∑np(xi)log(q(xi)p(xi))
- n为事件的所有可能性
- DKL的值越小,表示q分布和p分布越接近
交叉熵
对KL散度计算公式展开,可以得到
D K L ( p ∥ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) ) − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) = − H ( p ( x ) ) + [ − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) ] \begin{aligned} D_{K L}(p \| q) &=\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(p\left(x_{i}\right)\right)-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right) \\ &=-H(p(x))+\left[-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right)\right] \end{aligned} DKL(p∥q)=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(p(x))+[−i=1∑np(xi)log(q(xi))]
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
H ( p , q ) = − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) H(p, q)=-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right) H(p,q)=−i=1∑np(xi)log(q(xi))
习惯上, y y y标记为网络的输出的话,n 表达为 C个种类,并且从0开始,那么交叉熵可以表达为:
H ( p , q ) = − ∑ i = 0 C − 1 p ( y i ) log ( q ( y i ) ) (公式1) H(p, q)=-\sum_{i=0}^{C-1} p\left(y_{i}\right) \log \left(q\left(y_{i}\right)\right) \tag{公式1} H(p,q)=−i=0∑C−1p(yi)log(q(yi))(公式1)
在机器学习中,我们需要评估label和predicts、之间的差距,使用KL散度刚刚好,即 D K L ( y ∥ y ^ ) D_{K L}(y \| \hat{y}) DKL(y∥y^),由于KL散度中的前一部分 − H ( y ) −H(y) −H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
机器学习分类如何使用交叉熵损失
假设我们模型的输出结果如图所示, y y y为模型对应的预测结果,一般情况下,对于多分类问题,有多少种种类就对应多少个输出值,记为 y 0 y_0 y0… y C − 1 y_{C-1} yC−1。
- 对于样本的标签,一般采用One-hot编码,One-hot编码的长度与标签的种类C一致,对没一个样本的标签One-hot编码所得到的数据,作为该样本标签的概率分布 p p p。对于C个类别标签,其第 i i i 的标签的One hot编码后每个位置的取值如下
p ( y i ) = 1 , 第 i 位 置 处 取 值 为 1 , 其 它 取 值 为 0 , 0 ≤ i ≤ ( C − 1 ) (公式2) p(y_i) = 1, 第i位置处取值为1,其它取值为0,0 \leq i \leq (C-1) \tag{公式2} p(yi)=1,第i位置处取值为1,其它取值为0,0≤i≤(C−1)(公式2) - q q q 是样本预测的概率分布,网络一般要通过对网络输出 y 0 y_0 y0… y C − 1 y_{C-1} yC−1进行softmax的计算,或者通过sigmod将网络输出转换成概率,得到预测结果的的概率分布。Pytorch中对应的softmax函数可以用接口nn.Softmax()
由softmax计算公式,我们可以得到 q ( y i ) q(y_{i}) q(yi)的表达形式
q ( y i ) = σ ( y i ) = e y i ∑ j = 0 C − 1 e y j 0 ≤ i ≤ ( C − 1 ) (公式3) q(y_{i}) = \sigma(y_{i})=\frac{e^{y_{i}}}{\sum_{j=0}^{C-1} e^{y_{j}}} \ \ \ \ \ \ \ 0 \leq i \leq (C-1) \tag{公式3} q(yi)=σ(yi)=∑j=0C−1eyjeyi 0≤i≤(C−1)(公式3) - 至此,由公式1,公式2, 公式3, 我们可以得到每个样本的交叉熵损失如下,这个公式4,在PyTorch中对应的就是负对数似然函数(torch.nn.NLLLoss),也就是对模型输出的softmax的第i项,取负对数。
L o s s = − ∑ i = 0 C − 1 p ( y i ) log ( q ( y i ) ) = − log e y i ∑ j = 0 C − 1 e y j = − log Softmax (公式4) Loss =-\sum_{i=0}^{C-1} p\left(y_{i}\right) \log \left(q\left(y_{i}\right)\right)=-\log \frac{e^{y_{i}}}{\sum_{j=0}^{C-1} e^{y_{j}}}=-\log \text{Softmax} \tag{公式4} Loss=−i=0∑C−1p(yi)log(q(yi))=−log∑j=0C−1eyjeyi=−logSoftmax(公式4) - 如果将公式4 最后一部分用对数展开那么可以得到 L o s s Loss Loss的表达式如下,这个公式5,在PyTorch中对应的就是交叉熵损失函数 为torch.cross_entropy()
L o s s = − y i + log ∑ j = 0 C − 1 e y j (公式5) Loss =-{y_{i}}+\log{\sum_{j=0}^{C-1} e^{y_{j}}} \tag{公式5} Loss=−yi+logj=0∑C−1eyj(公式5)
下面着重讲下这两个函数以及他们的相同点和不同点。
负对数似然函数(torch.nn.NLLLoss)
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
负对数似然损失函数,主要用于训练含有C个种类分类的训练任务中。
可选参数 weight 应该是为每个类分配权重的一维张量。当您的训练集不平衡时,这尤其有用。
参数input是网络输出值的每个类的概率的对数。input 是一个size为 ( m i n i b a t c h , C ) (minibatch, C) (minibatch,C)的张量。 通过在网络的最后一层添加 LogSoftmax 层,可以很容易地获得神经网络中的概率对数。
参数target是在 [ 0 , C − 1 ] [0, C-1] [0,C−1]取值范围内的类索引。
Target: 这个是真实的样本标签值,其size是 ( N ) (N) (N),分别表示每个样本的种类,这个大小和一个batch的训练样本的数量一致,其中Target的每个元素值满足, 0 ≤ targets [ i ] ≤ C − 1 0 \leq \operatorname{targets}[i] \leq C-1 0≤targets[i]≤C−1 ,在损失函数中用作样本标签值。
- 参数reduction 设置为“none”,那么损失可以描述为:
ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − w y n x n , y n , w c = weight [ c ] ⋅ 1 { c ≠ ignore_index } \ell(x, y)=L=\left\{l_{1}, \ldots, l_{N}\right\}^{\top},\quad l_{n}=-w_{y_{n}} x_{n, y_{n}}, \quad w_{c}= \operatorname{weight}[c] \cdot 1\{c \neq \text {ignore\_index}\} ℓ(x,y)=L={l1,…,lN}⊤,ln=−wynxn,yn,wc=weight[c]⋅1{c=ignore_index}
其中, x x x是 input, y y y 是 target, w w w 是 weight权重, N N N 一个batch 所包含的样本的数量.
- 参数reduction的设置为’mean’(这个值是reduction的默认值)和’sum’,那么损失可以描述为:
ℓ ( x , y ) = { ∑ n = 1 N 1 ∑ n = 1 N w y n l n , if reduction = ’mean’ ∑ n = 1 N l n , if reduction = ’sum’ \ell(x, y)= \begin{cases}\sum_{n=1}^{N} \frac{1}{\sum_{n=1}^{N} w_{y_{n}}} l_{n}, & \text { if reduction }=\text { 'mean' } \\ \sum_{n=1}^{N} l_{n}, & \text { if reduction }=\text { 'sum' }\end{cases} ℓ(x,y)={∑n=1N∑n=1Nwyn1ln,∑n=1Nln, if reduction = ’mean’ if reduction = ’sum’
其它参数:
- weight 权重(张量,可选)– 给每个类的手动重新缩放权重。如果给定,则必须是大小为 C 的张量
- size_average (bool, optional) – 已弃用(见reduction)。默认情况下,损失是批次中每个损失元素的平均值。请注意,对于某些损失,每个样本有多个元素。如果字段 size_average 设置为 False,则对每个小批量的损失求和。当 reduce 为 False 时忽略。默认值:True
- ignore_index (int, optional) – 指定一个被忽略且对输入梯度没有贡献的目标值。当 size_average 为 True 时,损失在未忽略的目标上取平均值。
- reduce (bool, optional) – 已弃用(见reduction)。默认情况下,损失根据 size_average 对每个小批量的观察进行平均或求和。当reduce 为False 时,返回每个批次元素的损失并忽略size_average。默认值:True
- reduction(字符串,可选)– 指定要应用于输出的减少方式:‘none’ | ‘mean’ | ‘sum’。 ‘none’:不应用任何减少,此时loss的输出为一维向量,其size和N一致,对应的是每个样本的损失。‘mean’:采用所有样本输出的加权平均值,‘sum’:将所有的样本的输出相加。注意:size_average 和reduce 正在被弃用,同时,指定这两个参数中的任何一个都将覆盖reduce。默认值:‘mean(平均)’
举例说明:
import torch
import torch.nn as nn
m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
print("Model ouput 3 samples and 5 class score for each sample: \n",input)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
print("Sample label value used as index, the label value in range(0, 5): \n",target)
output = loss(m(input), target)
print("Losses computed with nn.NLLLoss: ",output)
loss_formula = -1*(m(input)[range(input.shape[0]), target]).mean()
print("Losses computed with nn.NLLLoss formula: ",loss_formula)
运行结果:
Model ouput 3 samples and 5 class score for each sample:
tensor([[ 0.0727, -0.5552, -1.3034, 0.5908, 0.7858],
[-0.3638, 1.1226, -1.3350, 0.5818, -0.0582],
[ 1.3680, -0.7179, -0.3489, -0.5296, -0.1822]], requires_grad=True)
Sample label value used as index, the label value in range(0, 5):
tensor([1, 0, 4])
Losses computed with nn.NLLLoss: tensor(2.2232, grad_fn=<NllLossBackward>)
Losses computed with nn.NLLLoss formula: tensor(2.2232, grad_fn=<MulBackward0>)
Pytorch 中交叉熵损失函数torch.cross_entropy()
torch.nn.functional.cross_entropy(input, target, weight=None, size_average=None, \
ignore_index=-100, reduce=None, reduction='mean')
该接口将log_softmax 和 nll_loss 组合在一个函数中。在 C种分类的训练分类时很有用。
参数解读:
- Input: 其shape为 ( N , C ) (N,C) (N,C), N为一个batch的样本数量,C = 类数 。模型对于每个样本的输出 y 0 y_0 y0… y C − 1 y_{C-1} yC−1,分别对应于每个种类的得分值,也就是每个分类的score值。
- Target: 这个是真实的样本标签值,其size是 ( N ) (N) (N),分别表示每个样本的种类,这个大小和一个batch的训练样本的数量一致,其中Target的每个元素值满足, 0 ≤ targets [ i ] ≤ C − 1 0 \leq \operatorname{targets}[i] \leq C-1 0≤targets[i]≤C−1 ,在损失函数中用作样本标签值。
- 输出:标量。如果reduction 为’none’,则输出的size与Target的size相同。每个Target的值依次对应于每个种类的loss。
可选参数 weight 应该是为每个类分配权重的一维张量。当您的训练集不平衡时,这尤其有用。
input 应包含每个类的原始非标准化score值对应的是一组实数。是神经网络的输出的实数数值
input 必须是tensor, 其shape大小为 ( m i n i b a t c h , C ) (minibatch,C) (minibatch,C)。
该接口期望取值在 [ 0 , C − 1 ] [0,C−1] [0,C−1]范围内的类索引作为(大小为 minibatch 的)1D 张量的每个值的目标(target );如果指定了ignore_index,这个接口也接受这个类索引(这个索引不一定在类范围内)。
损失可以描述为:
loss ( y , class ) = − log ( exp ( y [ class ] ) ∑ j exp ( y [ j ] ) ) = − y [ class ] + log ( ∑ j exp ( y [ j ] ) ) \operatorname{loss}(y, \text { class })=-\log \left(\frac{\exp (y[\text { class }])}{\sum_{j} \exp (y[j])}\right)=-y[\text { class }]+\log \left(\sum_{j} \exp (y[j])\right) loss(y, class )=−log(∑jexp(y[j])exp(y[ class ]))=−y[ class ]+log(j∑exp(y[j]))
仔细观察下,官网中讲的这个公式不就是我们推导的的交叉熵公式4 吗,把 j j j的取值写完整,也就是
loss ( y , class ) = − log ( exp ( y [ class ] ) ∑ j exp ( y [ j ] ) ) = − y [ class ] + log ( ∑ j = 0 C − 1 exp ( y [ j ] ) ) \operatorname{loss}(y, \text { class })=-\log \left(\frac{\exp (y[\text { class }])}{\sum_{j} \exp (y[j])}\right)=-y[\text { class }]+\log \left(\sum_{j=0}^{C-1} \exp (y[j])\right) loss(y, class )=−log(∑jexp(y[j])exp(y[ class ]))=−y[ class ]+log(j=0∑C−1exp(y[j]))
对于样本不均衡情况下,需要指定 weight 参数,这种情况下,公式为:
loss ( y , class ) = weight [ class ] ( − y [ class ] + log ( ∑ j exp ( y [ j ] ) ) ) \operatorname{loss}(y, \text { class })=\text { weight }[\text { class }]\left(-y[\text { class }]+\log \left(\sum_{j} \exp (y[j])\right)\right) loss(y, class )= weight [ class ](−y[ class ]+log(j∑exp(y[j])))
损失在每个minibatch的观察中取平均值。如果指定了 weight 参数,那么这是一个加权平均值:
loss = ∑ i = 1 N loss ( i , class [ i ] ) ∑ i = 1 N weight [ class [ i ] ] \operatorname{loss}=\frac{\sum_{i=1}^{N} \operatorname{loss}(i, \text { class }[i])}{\sum_{i=1}^{N} \text { weight }[\text { class }[i]]} loss=∑i=1N weight [ class [i]]∑i=1Nloss(i, class [i])
除了上面的讲的input和target,其它参数,weight,size_average,ignore_index以及reduction,和torch.nn.NLLLoss基本一致。
举例说明:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
loss = nn.CrossEntropyLoss(reduction="mean")
input = torch.randn(3, 5, requires_grad=True)
print("Model ouput 3 samples and 5 class score for each sample: \n",input)
target = torch.empty(3, dtype=torch.long).random_(5)
print("Sample label value, the label value in range(0, 5): \n",target)
#第一种方式,采用pytorch交叉熵函数接口计算loss
output = loss(input, target)
print("Losses computed with nn.CrossEntropyLoss: \n",output)
#第二种方式,采用交叉熵公式计算loss
f_2 = input.exp().sum(-1).log().unsqueeze(-1)
f_1 = -1*input[range(target.shape[0]), target]
loss0 = (f_1+f_2).mean()
print("Losses computed with loss formula: \n",output)
运行结果:
Model ouput 3 samples and 5 class score for each sample:
tensor([[-0.7193, -0.0853, 0.2175, -0.1100, 0.2599],
[-3.0053, -0.1658, -1.0710, 0.5690, 0.9577],
[-0.2433, -1.9273, 0.0165, -0.9162, 0.5135]], requires_grad=True)
Sample label value, the label value in range(0, 5):
tensor([4, 4, 2])
Losses computed with nn.CrossEntropyLoss:
tensor(1.1528, grad_fn=<NllLossBackward>)
Losses computed with loss formula:
tensor(1.1528, grad_fn=<NllLossBackward>)
Backend Qt5Agg is interactive backend. Turning interactive mode on.
从运行结果来看,采用pytorch交叉熵函数接口计算loss和采用交叉熵公式计算loss所得到的结果是一致的。
参考资料:
极大似然估计 —— Maximum Likelihood Estimation
Negative log likelihood explained
深度理解机器学习中常见损失函数
交叉熵、相对熵和负对数似然的理解
19个损失函数汇总,以Pytorch为例
Pytorch详解NLLLoss和CrossEntropyLoss
详解torch.nn.NLLLOSS
一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉