深度学习基础知识点【更新中】
深度学习基础知识点
文章目录
- 深度学习基础知识点
-
- 1. 数据归一化
- 2. 数据集划分
- 3. 混淆矩阵
- 4. 模型文件
- 5. 权重矩阵初始化
- 6. 激活函数
- 7. 模型拟合
- 8. 卷积操作
- 9. 池化操作
- 10. 深度可分离卷积
- 11. 转置卷积
1. 数据归一化
过大的输入数据未归一化会导致损失过大,导致溢出无法正常训练。归一化方法有:Min-Max归一化、平均值归一化等。
为什么要数据归一化:
- 数值问题:标准化可以避免一些不必要的数值问题。因为激活函数sigmoid/tanh的非线性区间大约在 [ -1.7 , 1.7 ]。意味着要使神经元有效,线性计算输出的值的数量级应该在1(1.7所在的数量级)左右。这时如果输入较大,就意味着权值必须较小,一个较大,一个较小,两者相乘,就引起数值问题了。
- 梯度更新:若果输出层的数量级很大,会引起损失函数的数量级很大,这样做反向传播时的梯度也就很大,这时会给梯度的更新带来数值问题。
- 学习率:如果梯度非常大,学习率就必须非常小,因此,学习率(学习率初始值)的选择需要参考输入的范围,不如直接将数据标准化,这样学习率就不必再根据数据范围作调整。
2. 数据集划分
数据集一般划分为训练集、验证集和测试集。
训练集用于模型迭代训练。
在神经网络中,验证数据集用于:
- 寻找最优的网络深度。
- 或者决定反向传播算法的停止点。
- 或者在神经网络中选择隐藏层神经元的数量。
- 在普通的机器学习中常用的交叉验证(Cross Validation)就是把训练数据集本身再细分成不同的验证数据集去训练模型。
测试集用来评估最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
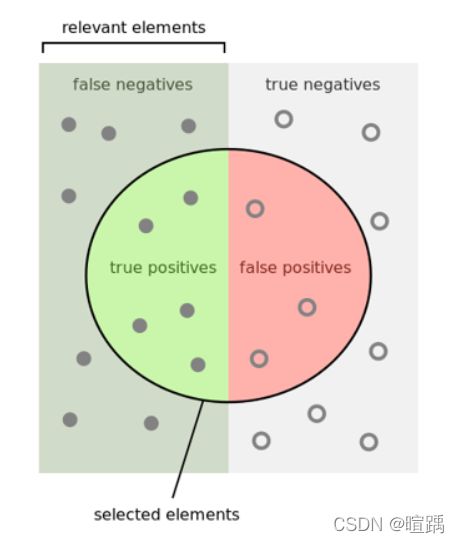
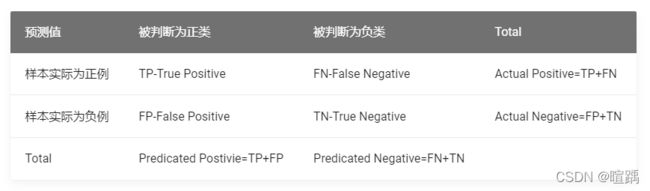
3. 混淆矩阵
- 正例中被判断为正类的样本数(TP-True Positive)
- 正例中被判断为负类的样本数(FN-False Negative)
- 负例中被判断为负类的样本数(TN-True Negative)
- 负例中被判断为正类的样本数(FP-False Positive)




4. 模型文件
目前绝大部分的深度学习框架都将整个AI模型的计算过程抽象成数据流图(Data Flow Graphs)。为了方便地重用AI模型的计算过程,我们需要将它运行的数据流图、相应的运行参数(Parameters)和训练出来的权重(Weights)保存下来,这就是AI模型文件的内容。
TensorFlow的Checkpoint Files用Protobuf去保存数据流图,用SSTable去保存权重;Keras用Json表述数据流图而用h5py去保存权重;PyTorch由于是主要聚焦于动态图计算,模型文件甚至只用pickle保存了权重而没有完整的数据流图。
TensorFlow在设计之初,就考虑了从训练、预测、部署等复杂的需求,所以它的数据流图几乎涵盖了整个过程可能涉及到操作,例如初始化、后向求导及优化算法、设备部署(Device Placement)和分布式化、量化压缩等,所以只需要通过TensorFlow的模型文件就能够获取模型完整的运行逻辑,所以很容易迁移到各种平台使用。
开放式神经网络交换(Open Neural Network Exchange,简称ONNX)是由微软、FaceBook、亚马逊等多个公司一起推出的,针对机器学习设计的开放式文件格式,可以用来存储训练好的模型。它使得不同的人工智能框架可以采用相同格式存储模型数据并交互。
5. 权重矩阵初始化
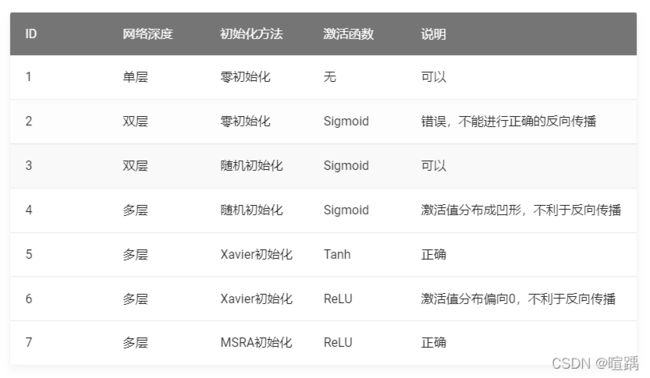
对于多层网络来说,绝对不能用零初始化!!如果初始值都是0,所以梯度均匀回传,导致所有W的值都同步更新,没有差别。这样的话,无论多少轮,最终的结果也不会正确。
标准正态初始化方法(随机初始化)保证激活函数的输入均值为0,方差为1。
Xavier初始化方法:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
MSRA初始化方法:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
以下是几种初始化方法的应用场景:
6. 激活函数
在线性变换后应用以引入非线性,帮助神经网络学习各种现象。
为什么要使用激活函数:非线性激活函数可以使神经网络逼近复杂函数。如果没有激活函数,多层神经网络和单层神经网络没有差别。
7. 模型拟合
网络的泛化问题:所谓泛化,就是模型在测试集上的表现要和训练集上一样好。
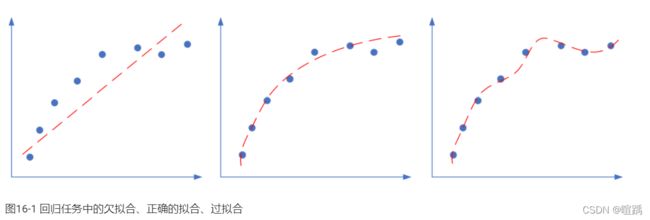
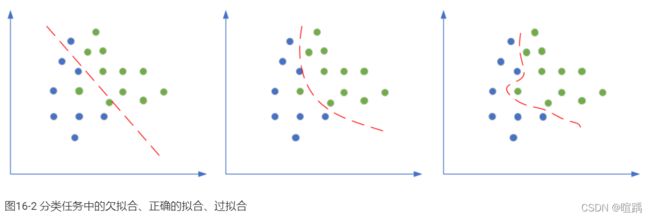
出现过拟合的原因:
- 训练集的数量和模型的复杂度不匹配,样本数量级小于模型的参数
- 训练集和测试集的特征分布不一致
- 样本噪音大,使得神经网络学习到了噪音,正常样本的行为被抑制
- 迭代次数过多,过分拟合了训练数据,包括噪音部分和一些非重要特征
解决过拟合问题:
- 数据扩展:过拟合的原因之一是训练数据不够,通过丰富的图像处理手段,我们往往可以把样本数量翻好几倍。
SMOTE(Synthetic Minority Over-sampling Technique),通过人工合成新样本来处理样本不平衡问题,提升分类器性能。 - 正则(L1正则使权重参数矩阵稀疏化;L2正则使权重矩阵中的值变小)
- 丢弃法(Dropout):在每个训练批次中,通过忽略一部分的神经元(让其隐层节点值为0),可以明显地减少过拟合现象。
- 早停法(Early stopping):在训练的过程中,记录到目前为止最好的验证集准确率,当连续N次Epoch没达到最佳准确率时,则可以认为准确率不再提高了。此时便可以停止迭代了。
- 集成学习法
- 特征工程(属于传统机器学习范畴,不在此处讨论)
- 简化模型,减小网络的宽度和深度
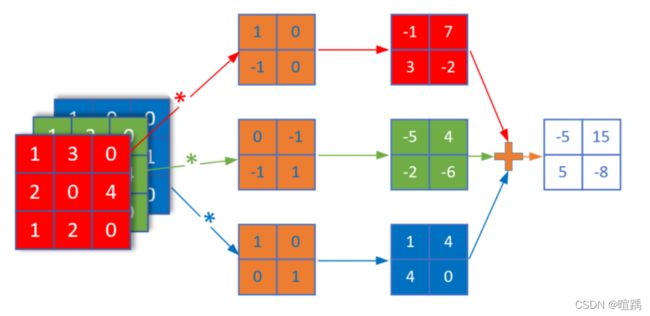
8. 卷积操作
- 多入单出的降维卷积
- 多入多出的同维卷积
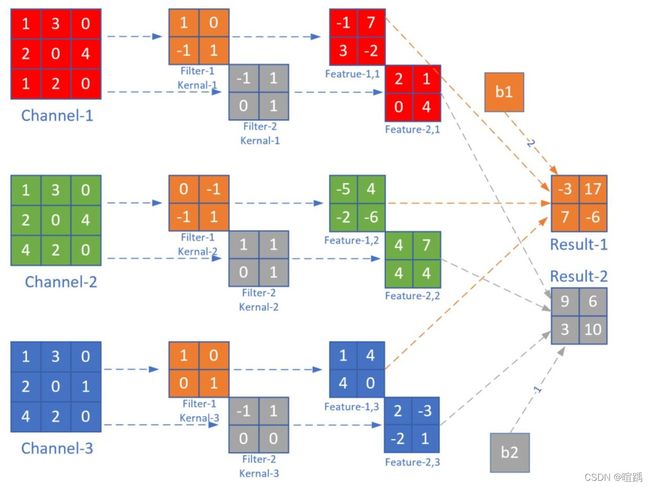
9. 池化操作
池化,又称为下采样(downstream sampling or sub-sampling)。池化方法分为两种,一种是最大值池化 Max Pooling,一种是平均值池化 Mean/Average Pooling。
- 最大值池化,是取当前池化视野中所有元素的最大值,输出到下一层特征图中。
- 平均值池化,是取当前池化视野中所有元素的平均值,输出到下一层特征图中。
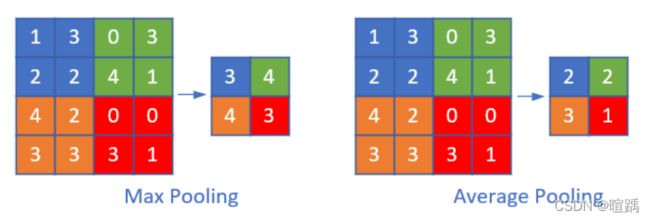
池化层的目的是:
- 扩大视野:就如同先从近处看一张图片,然后离远一些再看同一张图片,有些细节就会被忽略
- 降维:在保留图片局部特征的前提下,使得图片更小,更易于计算
- 平移不变性,轻微扰动不会影响输出:比如上图中最大值池化的4,即使向右偏一个像素,其输出值仍为4
- 维持同尺寸图片,便于后端处理:假设输入的图片不是一样大小的,就需要用池化来转换成同尺寸图片
10. 深度可分离卷积
相比常规卷积,深度可分离卷积的参数更少。
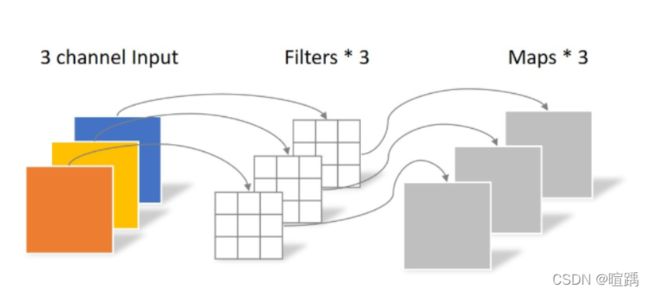
- 逐通道卷积(Depthwise Convolution):拆分为单个通道特征图,分别进行单通道卷积,然后重新堆叠到一起。
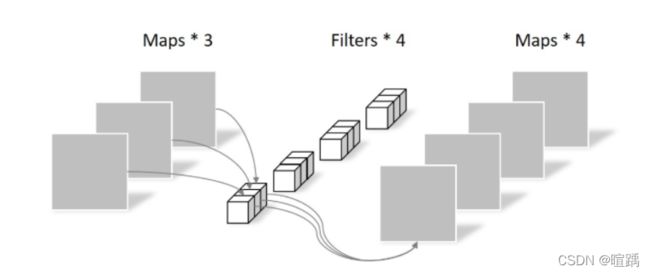
- 逐点卷积(Pointwise Convolution):将逐通道卷积输出得到的特征图进行第二次卷积,卷积核大小为1×1,滤波器的通道数与逐通道卷积输出的特征图的通道数一致。
11. 转置卷积
转置卷积(Transpose Convolution),一些地方也称为“反卷积”,在深度学习中表示为卷积的一个逆向过程,可以根据卷积核大小和输出的大小,恢复卷积前的图像尺寸,而不是恢复原始值。
>>> input = torch.randn(1, 16, 12, 12)
>>> downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1)
>>> upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1)
>>> h = downsample(input)
>>> h.size()
torch.Size([1, 16, 6, 6])
>>> output = upsample(h, output_size=input.size())
>>> output.size()
torch.Size([1, 16, 12, 12])