论文笔记:Fully-Convolutional Siamese Networks
一、基本信息
标题:Fully-Convolutional Siamese Networks for Object Tracking
时间:2016
论文领域:目标跟踪、深度学习
引用格式:Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking[C]//European conference on computer vision. Springer, Cham, 2016: 850-865.
二、研究背景
传统跟踪问题通过在线学习,使用视频本身作为训练数据。模型学习丰富程度有限。提到使用CNN提取特征,在不知道最终对象前,需要通过随机梯度拟合权重,速度受到限制。
学习自身特征:TLD、Struck、KCF。数据有限,导致模型有限。
深度学习:训练数据有限、实时性不够。
预训练:使用浅层方法,没有发挥端到端优势
SGD:时效性不行
三、创新点
使用Siamese架构,它对于搜索图像是完全卷积的:通过双线性层计算两个输入的互相关联,实现了密集而高效的滑动窗口评估。
Deep similarity learning for tracking
有这么一个函数 f ( z , x ) f(z, x) f(z,x),它可以计算两张图中描述相同对象得分。通过使用Siamese网络, f ( z , x ) = g ( φ ( z ) , φ ( x ) ) f(z, x)=g(\varphi(z), \varphi(x)) f(z,x)=g(φ(z),φ(x)),z和x分别输入两帧,经过 φ \varphi φ变换,最后可以使用相似函数g计算得分f。
Fully-convolutional Siamese architecture
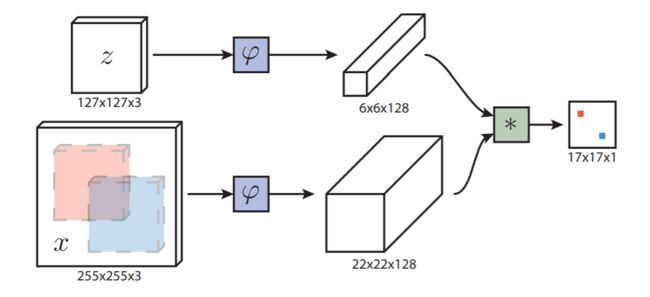
具体得分计算公式:
f ( z , x ) = φ ( z ) ∗ φ ( x ) + b 1 f(z, x)=\varphi(z) * \varphi(x)+b \mathbb{1} f(z,x)=φ(z)∗φ(x)+b1
φ \varphi φ是一个全卷积网络,可以兼容不同输入大小,z是追踪对象,x是需要判别的帧。z通过 φ \varphi φ后得到6x6x128特征图,把它作为卷积核,应用到x通过 φ \varphi φ后得到的22x22x128特征图上。结果就是得到17x17的得分图(尺寸取决于输入x和z的大小)。这样通过最后的卷积计算了255x255中17个区域的得分。
假设得到一个点的得分最高,那么如何确定真实位置,具体做法是:取中心+中心偏移量x步长
损失函数
ℓ ( y , v ) = log ( 1 + exp ( − y v ) ) \ell(y, v)=\log (1+\exp (-y v)) ℓ(y,v)=log(1+exp(−yv))
y ∈ { + 1 , − 1 } y \in\{+1,-1\} y∈{+1,−1}代表代表真实标签值, v : D → R v: \mathcal{D} \rightarrow \mathbb{R} v:D→R,对于一个得分地图的点y和v的计算如上,当v很大时,且真实标签为1,则损失小,否则损失大。相反同理。
对于整个得分地图(就是最后输出的17x17图),取了平均
L ( y , v ) = 1 ∣ D ∣ ∑ u ∈ D ℓ ( y [ u ] , v [ u ] ) L(y, v)=\frac{1}{|\mathcal{D}|} \sum_{u \in \mathcal{D}} \ell(y[u], v[u]) L(y,v)=∣D∣1u∈D∑ℓ(y[u],v[u])
使用SGD:
arg min θ E ( z , x , y ) L ( y , f ( z , x ; θ ) ) \arg \min _{\theta} \underset{(z, x, y)}{\mathbb{E}} L(y, f(z, x ; \theta)) argθmin(z,x,y)EL(y,f(z,x;θ))
确定训练对
只要x和z在视频里相隔不超过T帧,那么都可以作为一个训练对。
图片要进行归一化,但是不能破坏长宽比,而是用背景补充。

前面提到,训练时数据输入网络前要先把图像固定到特定的尺寸,论文里使用的尺寸为:模板127×127,待搜索图像255×255。固定图像尺寸的目的是使得跟踪的目标始终处于视频的正中心,如图2所示,这些图片截取自视频中不同的两帧。
这里不是简单的使用修剪或拉伸来处理的,如果这样做的话会丢失掉原图的信息。这里使用的做法是,如果bounding box的尺寸为(w,h),填充的边缘为p,那么缩放系数s的选择依据是使得缩放后的框框的面积等于一个固定的常数,即:
s(w+2p)×s(h+2p)=A
文中使用的A是127×127,图像边缘的填充为p=(w+h)/4
————————————————
版权声明:本文为CSDN博主「LCCFlccf」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/LCCFlccf/article/details/89072704
至于y怎么确定呢,也就是说什么叫做正样本什么叫做负样本呢?定义如下:
y [ u ] = { + 1 if k ∥ u − c ∥ ≤ R − 1 otherwise y[u]=\left\{\begin{array}{ll} +1 & \text { if } k\|u-c\| \leq R \\ -1 & \text { otherwise } \end{array}\right. y[u]={+1−1 if k∥u−c∥≤R otherwise
c是图片中心,k是网络最终总步长,如果距离中心不是很远那么是正样本,否则是负样本。
四、实验结果

在准确度不错的情况下,速度达到当时最先进水平
五、结论与思考
作者结论
在这项工作中,我们背离了传统的在线学习跟踪方法,并展示了一种替代方法,该方法侧重于在离线阶段学习强嵌入内容。与它们在分类设置中的使用不同,我们证明了对于跟踪应用,Siamese完全卷积深度网络能够更有效地使用可用数据。这反映在测试时,通过执行有效的空间搜索,也反映在训练时,每个子窗口有效地代表一个有用的样本,几乎没有额外的成本。实验表明,深度嵌入为在线跟踪器提供了丰富的特性来源,并使简单的测试时间策略能够很好地执行。我们相信,这种方法是对更复杂的在线跟踪方法的补充,并期待未来的工作能更彻底地探索这种关系
总结
本文提出使用典型Siamese Networks分别提取模板和待检测图,然后将模板的特征图作为卷积核,与待检测特征图进行卷积。
思考
那么这种做法是否能应用在目标识别领域?
但是由于本文的孪生网络是以端到端的形式学习出来的,那么可以认为,它训练出来的这个特征提取器,提取的特征更适合做卷积来获得最后的相似度得分图。
参考
【论文笔记】目标跟踪算法之Siamese-FC
Fully-Convolutional Siamese Networks for Object Tracking基于全卷积孪生网络的目标跟踪算法SiameseFC