Pytorch(三):可视化工具(Tensorboard、Visdom)
前言:在训练神经网络时,我们希望能够及时了解到网络训练过程中一些关键信息,包括损失曲线、验证集上的准确率以及输入图片各阶段特征的提取情况等,这些信息可以帮助我们掌控网络的整个训练过程。因此,为了更加直观地掌握网络训练过程的各种指标信息,将这些信息进行可视化是一个非常好的选择,下面本文将具体讲解Pytorch中提供的Tensorboard、Visdom这两种可视化工具。
目录
1、Tensorboard
1.1 Tensorboard的使用
1.2 Tensorboard中的方法
2、Visdom
1、Tensorboard
Tensorboard原本是专门为深度学习框架Tensorflow而配备的一款可视化工具,深受学术研究者的喜爱,后来Pytorch也提供了可以支持Tensorboard可视化的接口。在学习Tensorboard的使用之前,我们先了解一下Tensorboard的运行机制:①在python脚本中记录要可视化的数据;②将这些数据以event file形式保存到硬盘中;③终端从硬盘中读取event file在Tensorboard进行可视化,展示在web端。Tensorboard的web界面如下图所示:
1.1 Tensorboard的使用
第一步:从torch.utils.tensorboard模块中导入SummaryWriter类,代码实现如下:
from torch.utils.tensorboard import SummaryWriter必须通过SummaryWriter这个类才能在Python脚本中记录数据并以event file形式保存到硬盘中,SummaryWriter是提供创建event file的高级接口。
第二步,创建SummaryWriter类的对象,代码如下:
writer=SummaryWriter("./logs")括号中的参数是可视化数据保存时要创建的路径,代码运行之后目录中会出现如下图所示的文件夹。

第三步,通过Tensorboard中的方法向writer(events文件)中添加要可视化的内容,比如要可视化损失曲线,就要用add_scalar方法向writer中添加损失值标量,代码如下:
writer.add_scalar("train_loss",loss.item(),total_train_step)第一个参数是损失曲线图的名字,第二个参数是曲线图的纵坐标,第三个参数是曲线图的横坐标。
第四步,在Terminal终端中输入如下指令:
tensorboard --logdir “文件路径”
终端就会返回Tensorboard可视化的web端网址,如下图所示,点击网址即可进入Tensorboard可视化界面。
1.2 Tensorboard中的方法
①add_scalar:这个方法通常用来可视化网络训练过程中的各类标量指标,如损失、准确率、学习率等。
add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)这个函数常用到前三个参数,第一个参数是图像标题,第二个参数是纵坐标的值,第三个参数是横坐标的值。
示例:可视化![]() 函数图像,代码实现如下:
函数图像,代码实现如下:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("scalar_logs")
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()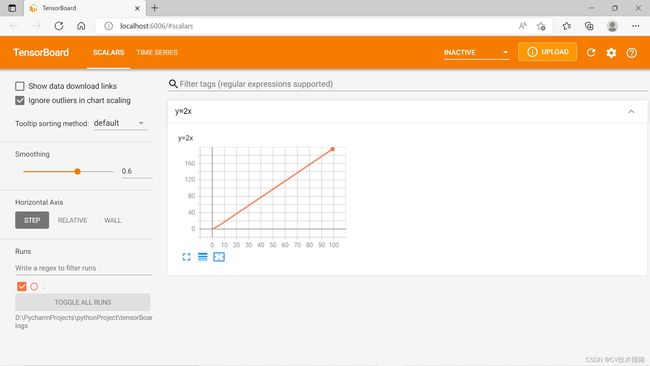
②add_scalars:该方法与add_scalar类似,唯一的区别就是该方法在一张图中可以绘制多条曲线。
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)当Y轴数据数量大于1时,使用writer.add_scalars()代替add_scalar函数。第一个参数是图像标题,第二个参数是纵坐标值组成的字典,第三个参数是横坐标值。
示例:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter("scalars_logs")
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()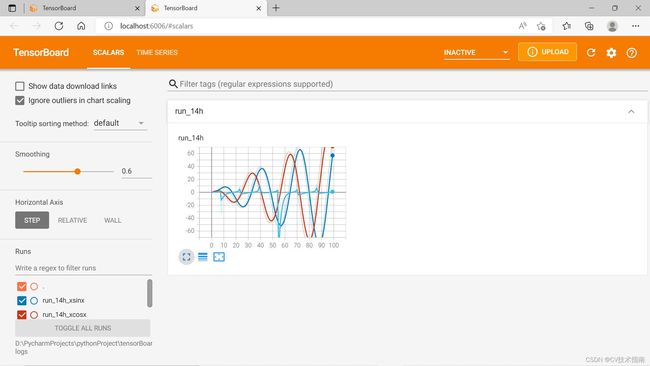
③add_histogram:这个方法用来可视化直方图和多分位数折线图。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)第一个参数是图的标题,第二个参数是横坐标(即建立直方图的值),第三个参数是纵坐标(即要记录的全局步长值)
示例:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter("histogram_logs")
for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()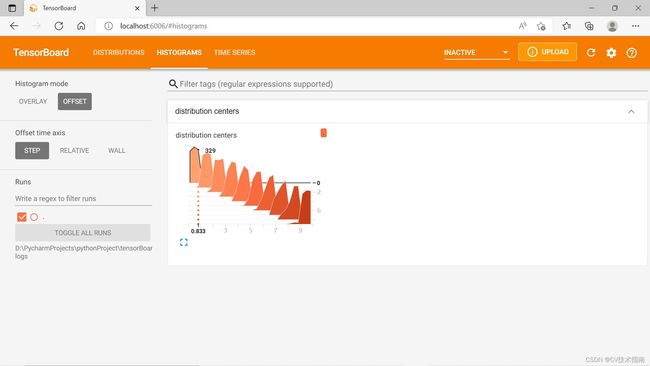
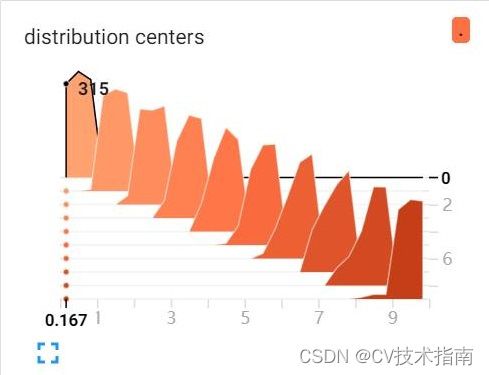
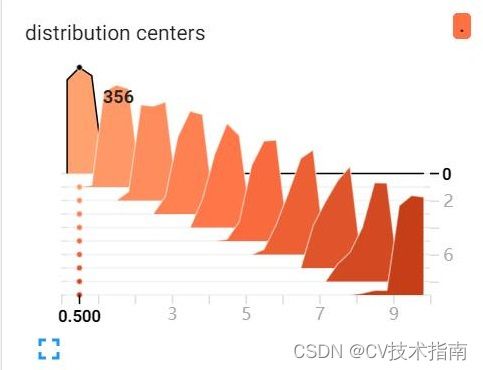
那怎么理解这个图呢, 看第一个数据块,它代表下面代码的调用,
writer.add_histogram('distribution centers', x , 0)此时global_step=0,相同global_step的数据会被放置在同一个层,上面示例中一共有10个global_step,即i的取值范围[0,10)。上图中(0.833,0,329)这个点代表global_step=0这层数据中在0.833附近的点有329个,每一层有1000个点,比如global_step=0这层中315+356+329刚好等于1000。
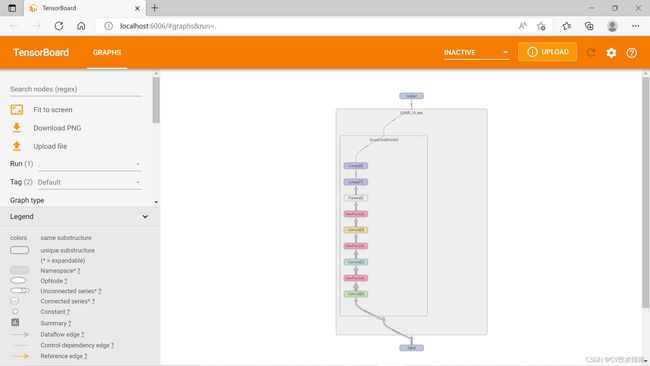
④add_graph:这个方法用来可视化模型的网络结构。
add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)
input_to_model:这个参数是输入图片,即训练集示例:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class CIFAR_10_Net(nn.Module):
def __init__(self):
super().__init__()
self.modle = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.modle(x)
return x
cifar_10_net = CIFAR_10_Net()
input = torch.ones((64, 3, 32, 32))
output = cifar_10_net(input)
writer = SummaryWriter("graph_logs")
writer.add_graph(cifar_10_net, input)
writer.close()
⑤add_image:这个方法是用来可视化相应的像素矩阵,例如输入图像或特征图。
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
参数解释如下:
tag:图片标题
img_tensor:图像数据,该数据可以是torch.Tensor、numpy.array以及string这几种类型的数据
global_step:要记录的全局步长值
dataformats:图像数据格式规范,有CHW,HWC,HW,WH等几种格式,默认是CHW,该参数一定要和img_tensor对应起来⑥add_images:该方法与add_image类似,区别就是该方法一次性可视化多张图像。在网络训练过程中,常用这个方法可视化图片或特征图。
add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')示例:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#tensorboard是一个用于神经网络训练过程可视化的网络服务器,其可以实现标量值,图像,文本等的可视化
dataset = torchvision.datasets.CIFAR10("../nn/data", train=False,transform=torchvision.transforms.ToTensor(),
download=True) # pytorch官网提供的一个下载数据集的函数
dataloader = DataLoader(dataset, batch_size=64) # DataLoader()函数就是数据加载器,其作用就是用来把训练数据分成多个小组,此函数每次抛出一个小组,
# batch_size参数就是限定每组训练数据的数量
class Tudui(nn.Module):#自定义一个Tudui类去继承nn.Moudle这个pytorch官网提供的神经网络模型
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("images_logs")#用于自动生成存放可视化内容的文件
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
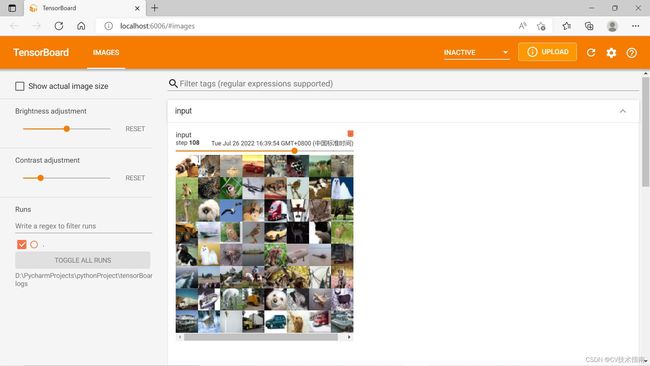
writer.add_images("input", imgs, step)#训练过程中用writer.add_images()函数向tensorboard添加图片
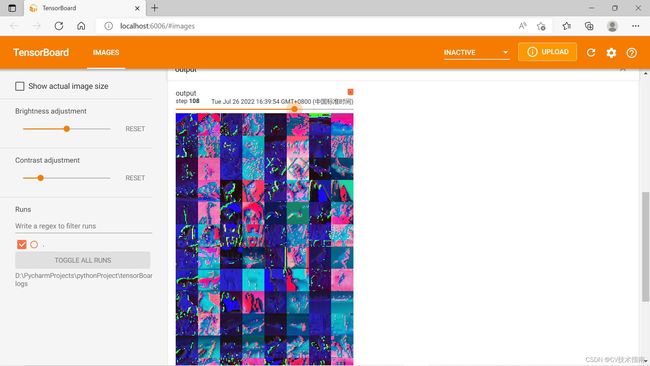
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1#下载的数据一共有10组,这条语句的作用是每完成一组显示之后就进入下一组显示
# 打开本代码生成的logs文件方法:在Terminal窗口输入语句tensorboard --logdir "D:\PycharmProjects\pythonProject\nn\logs",回车即可
⑦add_figure:这个方法是用来将matplotlib包中的figure对象可视化到Tensoboard的网页端,用于展示一些较为复杂的图片。
⑧add_pr_curve:这个方法是用来在训练过程中可视化Precision-Recall曲线,即观察在不同阈值下精确率与召回率的平衡情况。
⑨add_embedding:这个方法用来在三维空间中对高维向量进行可视化,默认情况下是对高维向量以PCA方法进行降为处理。
2、Visdom
Visdom是一个专门用于Pytorch的交互式可视化工具,可以对实时数据进行丰富的可视化,帮助我们实时监控在远程服务器上进行的科学实验,与Tensorboard类似,这里就不一一介绍了。这两种可视化工具各有千秋,能熟练使用一种即可。
Visdom可视化工具的具体内容可参考文章https://blog.csdn.net/weixin_41010198/article/details/117853358?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165880362116781818743913%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165880362116781818743913&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-117853358-null-null.142^v34^control,185^v2^control&utm_term=Visdom&spm=1018.2226.3001.4187