基于Tensorflow框架的人脸对齐、人脸关键点检测总结附代码(持续更新)
基于Tensorflow框架的人脸对齐、人脸关键点检测总结附代码(持续更新)
基于Tensorflow框架的人脸检测总结附代码(持续更新)
基于Tensorflow框架的人脸匹配总结附代码(持续更新)
基于Tensorflow框架的人脸活体检测、人脸属性总结附代码(持续更新)
最近利用人脸开源数据库WIDER FACE、64_CASIA-FaceV5、CelebA、300W_LP以及自己做的一个近200张照片的私人数据集复现了人脸检测、人脸匹配、人脸对齐、人脸关键点检测、活体检测、人脸属性等功能,并且将其集成在微信小程序中,以上所有内容将用大概5篇博客来总结。所有数据集下载链接附在下方,所有完整代码附在GitHub链接

WIDER FACE 数据集,包括32203个图像和393703个人脸图像,其中在尺度、姿势、遮挡、表情、装扮、光照等均有所不同。
LFW数据集,是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心坐标的人脸作为目标,其他区域的视为背景干扰。LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。
64_CASIA-FaceV5 该数据集包含了来自500个人的2500张亚洲人脸图片。
CelebA 包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记,广泛用于人脸相关的计算机视觉训练任务,可用于人脸属性标识训练、人脸检测训练以及landmark标记等。
300W_LP 该数据集是3DDFA团队基于现有的AFW,IBUG,HEPEP,FLWP等2D人脸对齐数据集,通过3DMM拟合得到的3DMM标注,并对姿态,光照,色彩等进行变化以及对原始图像进行flip(镜像)得到的一个大姿态3D人脸对齐数据集。


文章目录
-
- 1.人脸对齐/关键点业务介绍
- 2.人脸对齐/关键点方法介绍
- 3.人脸对齐/关键点问题挑战及解决思路
- 4.Tensorflow + SENet实现以及模型优化
1.人脸对齐/关键点业务介绍
什么是人脸对齐/人脸关键点检测
根据输入的人脸图像,自动定位出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛等人脸各部件轮廓点。
什么是人脸对齐/人脸关键点?
♦2D人脸 找到关键点(x,y)的坐标
♦3D人脸 利用深度学习找到五官轮廓信息
♦5,21,29,68,96,192…1000、8000 等关键点
■应用于表情识别、人脸编辑、人脸美妆、2维重建
人脸关键点算法评价指标:
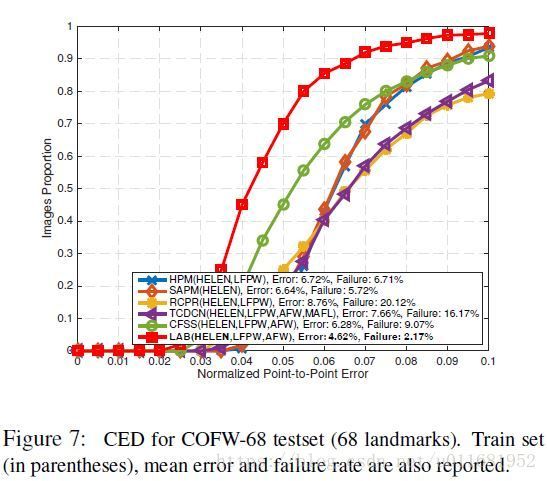
在人脸关键点定位算法中,常用的模型评估指标为the Cumulative Errors Distribution curve(CED):横坐标表示归一化点与点间误差时,LAB的失败率为2.17%;另外图中Error是指平均误差(MNE)。人脸对齐算法常用评价标准总结
2.人脸对齐/关键点方法介绍
传统方法:
基于形状学习的模型:人脸模型→点搜索→对齐→其他点的搜索定位
ASM模型为主动形状模型,即通过形状模型对目标物体进行抽象,其基本思路如下:
1.选取一组人脸图像的训练样本,用形状向量(由所有特征点的坐标组成)描述人脸的形状,首先将训练集中各样本对齐,使样本间形状尽可能相似;
2.采用主成分分析对对齐后的形状向量统计建模;
3.通过对关键点的搜索实现特定物体的匹配。
AAM模型是在ASM模型上进行改进,采用形状约束以及加入整个脸部区域的纹理特征。AAM 同 ASM 一样,主要分为两个阶段,模型建立阶段和模型搜索匹配阶段,其中模型建立阶段包括对训练样本分别建立形状模型和纹理模型,然后将两个模型进行结合,形成 AAM 模型。
ASM、AAM算法介绍
基于级联回归学习的模型:初始化 → 计算特征 → 计算变换量 → 更新初始化
CPR:为级联姿态回归算法用以计算图像中对象的2D姿态,CPR算法逐步细化随意指定的初始姿态,其中每一次姿态修正由不同的回归器确定。 每一个回归器执行简单图像测量依赖于先前回归器的输出结果; 整个系统从人工注释的训练数据集中自动学习。 CPR不限于刚性变换:“姿态”是对象外观的任何参数化变化,例如可变形和关节对象的自由度。
Cascaded Pose Regression
深度学习方法:
多级回归
DCNN:属于级联回归内核,该网络有三个层次的级联神经网络,改善了初始值不当导致陷入局部最优的问题,同时借助于CNN优质的特征提取能力,获得更为精准的关键点检测。
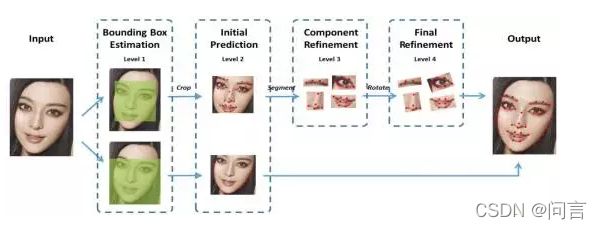
DCNN-Face++:在 DCNN 模型上进行改进,提出从粗到精的人脸关键点检测算法,实现了 68 个人脸关键点的高精度定位。该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计 51 个关键点,轮廓关键点包含 17 个关键点。针对内部关键点和外部关键点,该算法并行的采用两个级联的 CNN 进行关键点检测,网络结构如图所示。
多任务
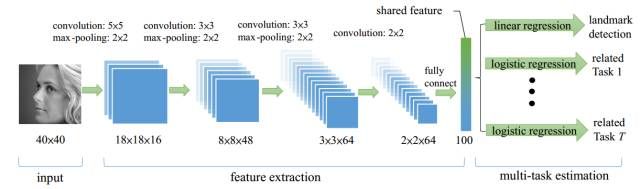
TCDCN:原作者认为,在进行人脸关键点检测任务时,结合一些辅助信息可以帮助更好的定位关键点,这些信息如,性别、是否带眼镜、是否微笑和脸部的姿势等等。作者将人脸关键点检测(5 个关键点)与性别、是否带眼镜、是否微笑及脸部的姿势这四个子任务结合起来构成一个多任务学习模型,模型框架如下图所示:
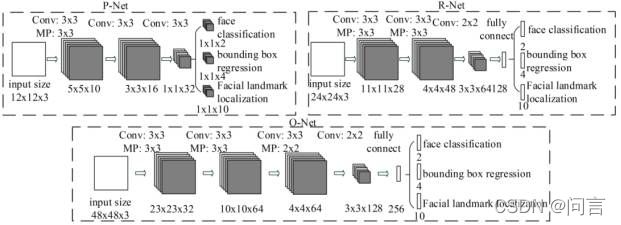
MTCNN:包含三个级联的多任务卷积神经网络,分别是 Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。网络结构如图所示:
直接回归
Vanilla CNN:网络结构与TCDCN网络结构一样,但是其特别之处是去掉了多任务学习而且使用了彩色图像,其次更替了损失函数,使用两眼间距离进行标准化,具体参考:人脸特征点检测:VanillaCNN
热图
DAN:2017 年,原作者Kowalski 等人提出一种新的级联深度神经网络——DAN(Deep Alignment Network),以往级联神经网络输入的是图像的某一部分,与以往不同,DAN 各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN 可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以 DAN 能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的主要创新点。DAN 基本框架如图所示:

此篇博客特别有意义感谢作者 不懂不学不问 深度学习网络模型部署——人脸关键点检测问题
2D人脸关键点定位在 → 3D人脸关键点定位发展中:首先2D人脸关键点是可见的语义信息,目前其检测精度较高,3D人脸关键点检测是当下的研究重点,其次3D人脸关键点定位(稠密人脸关键点定位)主要有:Dense Face Alignment, DenseReg, FAN, 3DDFA, PRNet 等
本项目使用300W-LP数据集(见开头)进行人脸68点关键点检测使用文件包中landmarks下AFW中的数据,其代码见后续。
3.人脸对齐/关键点问题挑战及解决思路
面临的困难:解决方案;
环境变化:数据增强,光照,旋转;
姿态变化:姿态分类、人脸对齐;
表情变化:数据增强,GAN;
遮挡问题:3D人脸关键点定位;


4.Tensorflow + SENet实现以及模型优化
总体分析:数据 → 网络结构 → 68点136维向量
SENet模型介绍:Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。

上图是SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入(C’xH’xW’)和输出(CxHxW),这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。解读Squeeze-and-Excitation Networks(SENet)
人脸关键点定位数据准备
读取图像数据,关键代码如下:
m = loadmat("300w-lp-dataset/300W_LP/landmarks/AFW/AFW_134212_1_0_pts.mat")
landmark = m['pts_2d']
m_data = cv2.imread("300w-lp-dataset/300W_LP/AFW/AFW_134212_1_0.jpg")
for i in range(68):
cv2.circle(m_data, (int(landmark[i][0]), int(landmark[i][1])),
2, (0,255, 0), 2)
cv2.imshow("11", m_data)
cv2.waitKey(0)
读取图像示例如下:
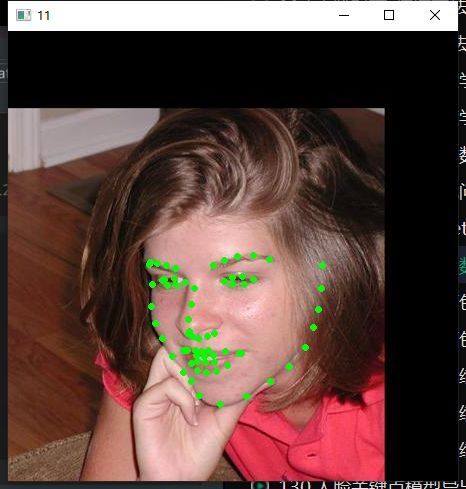
读取图像数据之后接下来的写数据关键代码为:
landmark_path_data = "300w-lp-dataset/300W_LP/landmarks"
landmark_path_folders = glob.glob(landmark_path_data + "/*")
#获取的文件存放在列表中
landmark_anno_list = []
#遍历landmarks文件夹下所有子文件夹
for f in landmark_path_folders:
landmark_anno_list += glob.glob(f + "/*.mat")
print(landmark_anno_list)
#保存模型
writer_train = tf.python_io.TFRecordWriter("train.tfrecords")
writer_test = tf.python_io.TFRecordWriter("test.tfrecords")
#遍历列表中所有文件
for idx in range(landmark_anno_list.__len__()):
landmark_info = landmark_anno_list[idx]
im_path = landmark_info.replace("300W_LP/landmarks","300W_LP").replace("_pts.mat", ".jpg")
print(im_path)
im_data = cv2.imread(im_path)
#取图像
landmark = loadmat(landmark_info)['pts_2d']
#获取人脸关键点
x_max = int(np.max(landmark[0:68, 0]))
x_min = int(np.min(landmark[0:68, 0]))
y_max = int(np.max(landmark[0:68, 1]))
y_min = int(np.min(landmark[0:68, 1]))
#调整人脸框位置
y_min = int(y_min - (y_max - y_min) * 0.3)
y_max = int(y_max + (y_max - y_min) * 0.05)
x_min = int(x_min - (x_max - x_min) * 0.05)
x_max = int(x_max + (x_max - x_min) * 0.05)
face_data = im_data[y_min : y_max, x_min : x_max]
sp = face_data.shape
im_point = []
for p in range(68):
im_point.append((landmark[p][0] - x_min) * 1.0 / sp[1])
im_point.append((landmark[p][1] - y_min) * 1.0 / sp[0])
face_data = cv2.resize(face_data, (128, 128))
ex = tf.train.Example(
features = tf.train.Features(
feature = {
"image" : tf.train.Feature(
bytes_list = tf.train.BytesList(value = [face_data.tobytes()])
),
"label": tf.train.Feature(
float_list=tf.train.FloatList(value=im_point)
)
}
)
)
if idx > landmark_anno_list.__len__() * 0.9:
writer_test.write(ex.SerializeToString())
else:
writer_train.write(ex.SerializeToString())
writer_test.close()
writer_train.close()
人脸关键点定位模型训练、调试与测试
在将数据打包好之后,接下来便是训练人脸关键点定位模型,其关键代码如下:
# read data
def get_one_batch(batch_size, type):
if type == 0: #train
file_list = tf.gfile.Glob("train*.tfrecords")
else:
file_list = tf.gfile.Glob("test*.tfrecords")
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(
file_list, num_epochs = None, shuffle = True
)
_,se = reader.read(filename_queue)
if type == 0:
batch = tf.train.shuffle_batch([se], batch_size,
capacity = batch_size,
min_after_dequeue = batch_size // 2)
else:
batch = tf.train.batch([se], batch_size,
capacity = batch_size)
features = tf.parse_example(batch, features = {
'image':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([136], tf.float32)
})
batch_im = features['image']
batch_label = features['label']
batch_im = tf.decode_raw(batch_im, tf.uint8)
batch_im= tf.cast(tf.reshape(batch_im,
(batch_size, 128, 128, 3)), tf.float32)
return batch_im, batch_label
#net
input_x = tf.placeholder(tf.float32, shape = [None, 128, 128, 3])
label = tf.placeholder(tf.float32, shape=[None, 136])
logits = SENet(input_x, is_training = True, keep_prob = 0.8)
#loss
loss = tf.losses.mean_squared_error(label, logits)
reg_set = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
l2_loss = tf.add_n(reg_set)
#learn
global_step = tf.Variable(0, trainable=False)
lr = tf.train.exponential_decay(0.001, global_step,
decay_steps = 1000,
decay_rate = 0.98,
staircase = True)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = tf.train.AdamOptimizer(lr).minimize(l2_loss + loss, global_step)
#save
saver = tf.train.Saver(tf.global_variables())
tr_im_batch, tr_label_batch = get_one_batch(32, 0)
te_im_batch, te_label_batch = get_one_batch(32, 1)
在模型进入训练后,使用tensorboard观察损失函数值变化趋势,如下图所示:

训练结束后,导出模型pb文件(模型固化)关键代码如下:
#net
input_x = tf.placeholder(tf.float32, shape = [1, 128, 128, 3])
logits = SENet(input_x, is_training = False, keep_prob = 1.0)
print(logits)
saver = tf.train.Saver(tf.global_variables())
#session
with tf.Session() as session:
coord = tf.train.Coordinator()
tf.train.start_queue_runners(sess = session, coord = coord)
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
session.run(init_op)
ckpt = tf.train.get_checkpoint_state("models")
saver.restore(session, ckpt.model_checkpoint_path)
output_graph_def = tf.graph_util.convert_variables_to_constants(session,
session.graph.as_graph_def(),
['fully_connected_9/Relu'])
with tf.gfile.FastGFile("landmark.pb", "wb") as f:
f.write(output_graph_def.SerializeToString())
f.close()
在保存pb文件之后,便是对其模型进行测试,其人脸关键点模型测试关键代码如下:
pb_path = "landmark.pb"
sess = tf.Session()
with sess.as_default():
with tf.gfile.FastGFile(pb_path, "rb") as f:
graph_def = sess.graph_def
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name = "")
im_list = glob.glob("images/*")
landmark = sess.graph.get_tensor_by_name("fully_connected_9/Relu:0")
for im_url in im_list:
print(im_url)
im_data = cv2.imread(im_url)
im_data = cv2.resize(im_data, (128,128))
pred = sess.run(landmark, {"Placeholder:0" : np.expand_dims(im_data, 0)})
print(pred)
pred = pred[0]
for i in range(0, 136, 2):
cv2.circle(im_data, (int(pred[i] * 128), int(pred[i+1] * 128)),
2, (0, 255, 0), 2)
cv2.imshow("11",im_data)
cv2.waitKey(0)
在个人数据集上进行测试,观察人脸关键点定位是否检测准确(根据结果图显示,在个人数据集中人脸关键点定位效果可以进一步提升,接下来要融合多个训练集进行训练,同时扩充私人数据集进行多次测试,寻求最优模型)


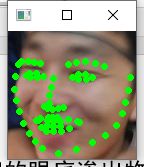
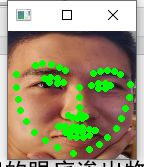
人脸关键点定位模型优化改进策略
- 选用其他主干网络进行实验,如其他边缘检测模型等等;
- 选用复合损失函数或者更适合的优化器;
- 对数据进行增强处理。或者使用GAN网络;
- 可以增添一个用以姿态分类的模块用以解决多姿态影响关键点检测的问题。