复盘:GBDT,梯度提升决策树,Gradient Boosting Decision Tree,堪称最好的算法之一
复盘:GBDT,梯度提升决策树,Gradient Boosting Decision Tree,堪称最好的算法之一
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
文章目录
- 复盘:GBDT,梯度提升决策树,Gradient Boosting Decision Tree,堪称最好的算法之一
-
- @[TOC](文章目录)
- GBDT:Gradient Boosting Decision Tree
- 说了半天,boosting的第一把金钥匙到底是啥?
- 接着我们来看一下GBDT的第二把金钥匙
- 为了回答每棵决策树到底在训练什么,我们围绕第三把金钥匙的求解目标,从损失函数入手
- 接下来就是GBDT的独到之处了
- 接下来我们来用GBDT去解一个实际的问题
- 总结
文章目录
- 复盘:GBDT,梯度提升决策树,Gradient Boosting Decision Tree,堪称最好的算法之一
-
- @[TOC](文章目录)
- GBDT:Gradient Boosting Decision Tree
- 说了半天,boosting的第一把金钥匙到底是啥?
- 接着我们来看一下GBDT的第二把金钥匙
- 为了回答每棵决策树到底在训练什么,我们围绕第三把金钥匙的求解目标,从损失函数入手
- 接下来就是GBDT的独到之处了
- 接下来我们来用GBDT去解一个实际的问题
- 总结
GBDT:Gradient Boosting Decision Tree
经常看面经,GBDT看得就很迷糊,今儿个就想彻底在美团面试之前好好把面经里面那些不会的,透彻梳理一下,学透了!
GBDT的知识,主要包括GBDT模型,GBDT模型的损失函数和GBDT模型的优化,求解。
GBDT可以说是机器学习中浅层模型的佼佼者,深受所有机器学习从业者的喜爱。
GBDT的全称是GPDT模型的中文名是梯度提升树,
在这个专栏里,对于GBDT的四个词语,我们先后遇到了梯度G和决策树DT,而提升B倒是第一次遇到。

因此在学习GBT前,我们先普及一下关于boosting的概念和性质,
Boosting叫做提升,它不是一个模型,也不是一个算法,更像是一个架构。
机器学习得到一个比随机去猜强一丢丢的弱的模型是很容易的,
而要想得到一个效果完美的强模型则是很困难的。
幸运的是,有学者曾经证明强可学习等价于弱可学习。
也就是说,在某些条件下,强模型等价于弱弱的模型,
至于如何等价就要靠提升boosting方法,
让一个弱弱的模型提升为一个强模型。
强模型很难被发现,但是弱模型就容易多了。
这就是boosting的核心思想,也形象的被称为三个臭皮匠,胜过诸葛亮。

boosting大家族的模型很像是一个包子,
包子的馅儿就是弱模型,通常也叫做基模型,取意为基础,
包子的皮儿是boosting方法,

不管是皮儿还是馅儿,单独吃味道都有所欠缺,
只有合在一起才能创造出美味的食物。
但是这个包子的馅儿是个弱模型,就算再弱的模型,也要遵循机器学习的三把金钥匙。
而boosting模型这个大包子是boosting方法+加弱模型,
更是一个模型,自然也遵循机器学习的三把金钥匙框架
下面,我们就来用机器学习的三把金钥匙
一并分析基模型和boosting模型。
说了半天,boosting的第一把金钥匙到底是啥?
这可能要结合基模型和boosting模型一起来展开基模型,
哪怕效果再弱,也和我们前面学习的模型完全一样,
因此基模型就是
Y等于FX,
但是boosting就没那么简单了。

Boosting的模型是个迭代多轮的加法模型,
Boostin每轮儿输出的是一个基模型FMX,
其中M表示第M轮儿迭代,
最终每轮儿迭代输出的模型经过加法求和,就得到了最终的boosting模型的输出,
也就是Y等于大型求和,m等于1到大M【看上图】FmX
当今在boosting大家族里被广泛应用的模型就是GBDT了,
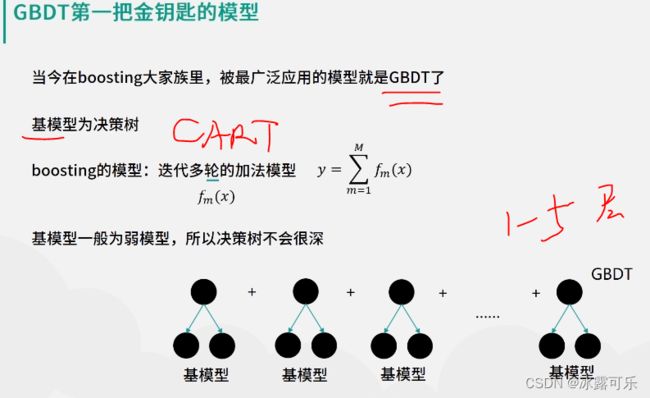
GBDT模型,其基模型就是DT,也就是决策数。
也就是说,对于GBDT下的每周迭代输出的FmX就是一个决策数。
最终的GBDT模型就是这里所有决策树输出结果之和。
别忘了,如此定的基模型采用的都是弱模型,因此通常GBDT基模型的决策树的树身不会太深,
一般会少于五层,更有激进的工程师喜欢设置只有一层的树桩,这些都是可以在实际实现过程中灵活处理。
接着我们来看一下GBDT的第二把金钥匙
我们以回归为例,回归决策树的损失函数,采用平方误差,所以GBDT也可以保持一致。
我们把平方误差的公式写一下。

也就是loss w等于大型求和:I等于一到N表示样本量,
括号Yi hat表示的是真实值
减去Yi,也就是预测值整体的平方,
第一把金钥匙告诉了我们模型是什么样子,第二把金钥匙就说明了损失函数,
这里的模型和损失函数都是参数W的函数。
而参数W就是每个基模型的决策树的参数,
也就是每个基模型的决策树的每个分裂特征和每个分裂特征的阈值。
在考虑其算法之前,我们先想一下此时要优化的目标变量是什么?
前面在学习决策树的时候,我们已经学会了如何求解一个独立决策树的参数,
然而现在问题变成了有这么多棵决策树,
而且决策树之间也存在先后关系,每棵决策树要训练的目标变量是什么,我们还不知道,
又如何求解决策树的参数?
为了回答每棵决策树到底在训练什么,我们围绕第三把金钥匙的求解目标,从损失函数入手
对于损失函数中的预测值Yi,
我们有Yi等于大型求和m等于一大M: Fm Xi
我们把大型求和进行适当的拆解,
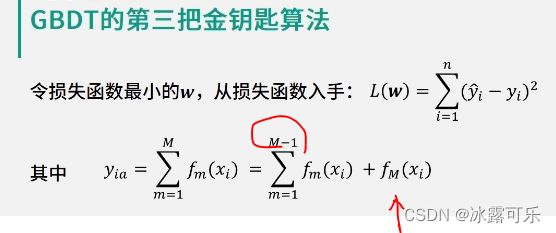
拎出最后一项就有了Yi等于大型求和:m等于1直到M减1:Fm Xi
加上F大M括号Xi,
我们把这个公式带到损失函数,你会得到LW,也就是损失函数,

那等于大型求和:I等于一到N括号Yi hat减去
大型求和:m等于1直到M减1:Fm Xi
再减去FM Xi整体的平方。
仔细观察上面的公式,你会发现这个损失函数中有三项,
其中第一项是真实值,也就是Yi hat。
第二项是截止到第M-1个数的预测值,
最后的第三项,则是第M个数的输出结果。
如果我们令前两项等于一个数,也就是ri,它表示的是训练第M轮数时,截止到当前的残差值,也就是误差,
那么,就会有损失函数LW等于上面最后一个公式,
这个公式表明,为了让损失函数的值最小,
在训练某个基模型时,其训练的目标就是去拟合残差
ri前面的内容成立的条件是损失函数为平方误差的情况。
更一般的,如果损失函数是某个奇形怪状的函数,
那么每个基模型的训练目标还是残差吗?显然不是了,
接下来就是GBDT的独到之处了
GBDT中规定,利用损失函数的负梯度,在当前模型的值作为残差的近似值,

也就是ri约等于负的LW的关于F大M减一括号,X的偏导
特别地,当损失函数采用平方误差时,
损失函数的负梯度就是先前推导的残差值。
看上面最后一项
接下来我们来用GBDT去解一个实际的问题
请看这个例题,在如下的回归问题中,特征假设只包含一个维度。

取值为一到五的自然数样本对应的真实值取值为负一到正一的自然数。
现在要利用GBDT算法建立一个模型,
假设G模型采用竖身为一的卡特数。
解析一下,G模型采用卡特回归数回归问题,
损失函数就采用平方误差函数,则残差公式为Ri约等于负的损失函数。

接下来,建模需要通过多轮的迭代,而每一轮学习的都是一棵卡通树。
学习的目标是残差题目,要求只用一层节点的CART数建模,
那么,采用平方误差最小的分类点和阈值就可以了。
就是说,咱们的阈值怎么定?争取让最后实际真实值跟预测值俩的误差最小,这么一个阈值你看咋合适,就选这个分裂阈值就行

因此,第一轮的输出结果就是X,小于1.5则,余则为负一,X大于1.5则,余则为0.5。
经过第一轮的模型,对每个样本可以计算出残差表,例如下边
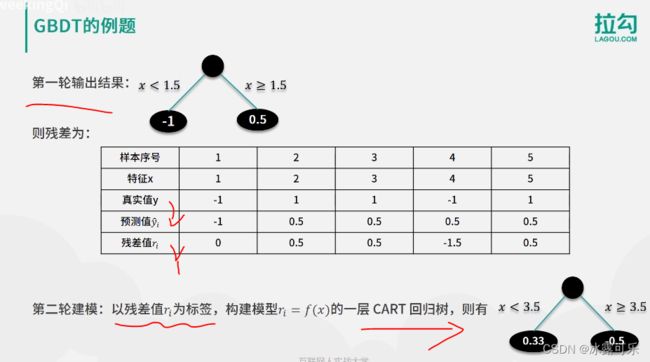
我们以样本三为例,样本三特征值为三,真实值为一,X等于三。因为X大于1.5,则预测值为0.5,
那么残差值就是真实值减去预测值,也就是0.5,
其他的样本?以此类推,这样在第二轮建模时,以残差值ri为标签,构建模型ri等于FX的一层CART回归数。
此时有如果X小于3.5,则预测值为0.33,如果X大于等于3.5,则预测为负0.5。
经过第二轮建模之后的模型如下,同样的可以计算残差,并进行第三轮的模型。

第三轮的模型,结果是第一轮的模型加上第二轮的模型。
经过重复前面过程五次之后,我们就得到了最终的模型。如图所示,

我们以X等于二为例,代表模型则有这五棵树输出的结果分别为0.50.33负0.250.25和负0.09,
最终预测的结果就是这五棵树的求和等于0.74。
最后我们做一个快速的总结,本节的内容看似复杂,其实也有规律可循。
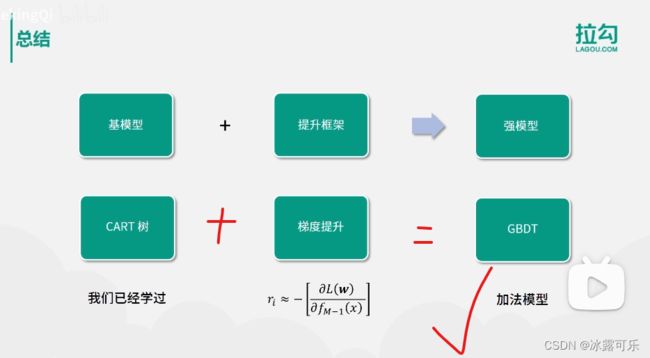
需要记住的是,提升方法,可以将一个弱模型提升为一个强模型。
对于GBDT而言,弱模型可以采用浅层的CART,
而提升方法的本质则是一个逐步迭代的加法模型。
对于每轮的迭代,采用损失函数的负梯度作为学习的目标,
也就是ri约等于负的LW关于F大M减1X的偏等,
最终就得到了GBDT模型了。
如何,这次终于清楚了吧???
总结
提示:重要经验:
1)GBDT,用弱鸡模型CART,通过预测上一个模型的残差ri=损失函数的负梯度值,不断累加和最后得到一个强模型的预测结果
2)boosting的想法,就是多个弱分类器不断串联最后得到强分类器的结果。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。