论文阅读|Lite-HRNet
Lite-HRNet: A Lightweight High-Resolution Network
Abstract
我们提出了一个高效的高分辨率网络 Lite-HRNet,用于人体姿态估计。 我们首先将 ShuffleNet 中的高效 shuffle 块简单地应用于 HRNet(高分辨率网络),从而产生比 MobileNet、ShuffleNet 和 Small HRNet 等流行的轻量级网络更强的性能。
我们发现 shuffle 块中大量使用的逐点 (1×1) 卷积成为计算瓶颈。 我们引入了一个轻量级单元,条件通道加权,以替换 shuffle 块中昂贵的逐点 (1×1) 卷积。 通道加权的复杂度与通道数量成线性关系,并且低于逐点卷积的二次时间复杂度。我们的解决方案从所有通道和多个分辨率中学习权重,这在 HRNet 的并行分支中很容易获得。 它使用权重作为跨通道和分辨率交换信息的桥梁,补偿了逐点(1×1)卷积所起的作用。 Lite-HRNet 在流行的轻量级网络上展示了人体姿态估计的优越结果。 此外,Lite-HRNet 可以以同样轻量级的方式轻松应用于语义分割任务。
Introduction
现有的高效网络 [5, 6, 53] 主要是从两个角度设计的。 一种是借鉴分类网络的设计,例如 MobileNet [17, 16] 和 ShuffleNet [28, 57],以减少矩阵向量乘法中的冗余,其中卷积运算占主导地位。 另一种是通过各种技巧来调解空间信息丢失,例如编码器-解码器架构 [2, 26] 和多分支架构 [53, 59]。
我们首先通过简单地结合 ShuffleNet中的 shuffle block和 HRNet 中的高分辨率设计模式来研究一个简单的轻量级网络。 HRNet 在位置敏感问题(例如语义分割、人体姿态估计和对象检测)的大型模型中表现出更强的能力。 目前尚不清楚高分辨率是否有助于小型模型。 我们凭经验表明,直接组合优于 ShuffleNet、MobileNet 和 Small HRNet1。
为了进一步实现更高的效率,我们引入了一个名为条件通道加权的高效单元,用于跨通道执行信息交换,以取代 shuffle 块中昂贵的逐点 (1×1) 卷积。 通道加权方案非常有效:复杂度与通道数量成线性关系,并且低于逐点卷积的二次时间复杂度。 例如,借助 64 ×64 ×40 和 32 ×32 ×80 的多分辨率特征,条件通道加权单元可以将 shuffle 块的整体计算复杂度降低 80%。
与作为模型参数学习的常规卷积核权重不同,所提出的方案权重以输入图为条件,并通过轻量级单元跨通道计算。 因此,它们包含所有通道映射中的信息,并作为通过通道加权交换信息的桥梁。 此外,我们从现成的 HRNet 并行多分辨率通道图计算权重,以便权重包含更丰富的信息并得到加强。 我们将生成的网络称为 Lite-HRNet。实验结果表明,Lite-HRNet 优于 shuffle blocks 和 HRNet(我们称之为 naive Lite-HRNet)的简单组合。 我们认为其优越性是因为在所提出的条件信道加权方案中,计算复杂度的降低比信息交换的损失更显着。
Contributions
• 我们简单地将 shuffle 块应用于 HRNet,引领了轻量级网络 naive Lite-HRNet。 我们从经验上展示了优于 MobileNet、ShuffleNet 和 Small HRNet 的性能。
• 我们提出了一种改进的高效网络 Lite-HRNet。 关键是我们引入了一个高效的条件通道加权单元来代替 shuffle 块中昂贵的 1×1 卷积,并且跨通道和分辨率计算权重。
• Lite-HRNet在COCO和MPII人体姿态估计的复杂度和精确度方面是最先进的,很容易推广到语义分割任务。
Related Works
Efficient blocks for classification
可分离卷积和组卷积在轻量级网络中越来越流行,例如 MobileNet [17, 36, 16],IGCV3 [37] 和 ShuffleNet [57, 28]。 Xception [9] 和 MobileNetV1 [17] 将一个普通卷积分解为深度卷积和逐点卷积。 MobileNetV2 和 IGCV3 [37] 进一步结合了关于低秩内核的线性瓶颈。 MixNet [39] 在深度卷积上应用混合内核。 EfficientHRNet [30] 将移动卷积引入HigherHRNet [8]。
跨通道的信息在分组卷积和深度卷积中被阻塞。点式解决方案被大量用来解决这个问题,但在轻量级网络设计中成本非常高。为了减少复杂性,采用分组1×1卷积和信道shuffing[57,28]或interleaving[56,47,37]来保持跨信道的信息交换。我们提出的解决方案是一种轻量级的方式,执行跨通道的信息交换,以取代昂贵的1×1卷积。
Mediating spatial information loss
计算复杂度与空间分辨率呈正相关。以空间信息损失为中介来降低空间分辨率是提高效率的另一种途径。编解码器结构被用来恢复空间分辨率,如ENET[34]和SegNet[2]。ICNet[60]将不同的计算应用于不同的分辨率输入,以降低整体复杂性。BiSeNet[53,50]将细节信息和上下文信息与不同的轻量级子网络解耦。我们的解决方案遵循 HRNet 中的高分辨率模式,以在整个过程中保持高分辨率表示。
Convolutional weight generation and mixing
动态滤波网络[21]动态地生成以输入为条件的卷积滤波器。Meta-Network[29]采用meta-leaner来生成学习跨任务知识的权重。CondINS[40]和SOLOV2[43]将这种设计应用到实例分割任务中,为每个实例生成掩码子网络的参数;CondConv[48]和动态卷积[5]学习一系列权值来混合每个样本对应的卷积核,从而增加了模型的容量。
注意机制[19,18,44,54]可以看作是一种条件权重的产生。Senet[19]使用全局信息来学习权重,以刺激或抑制通道映射。Genet[18]通过收集本地信息来利用上下文依赖来扩展这一点。CBAM[44]利用通道和空间注意力来提炼特征。
在某种意义上,所提出的条件信道加权方案可以被认为是基于条件信道的1×1卷积。除了计算成本较低外,我们还利用条件权重作为跨通道交换信息的桥梁,发挥了额外的作用。
Conditional architecture
与普通网络不同,条件体系结构可以实现动态的宽度、深度或内核。SkipNet[42]使用门控网络来跳过一些卷积块,以选择性地降低复杂性。空间变换网络学习扭曲以输入为条件的特征图。 可变形卷积学习以每个空间位置为条件的卷积核的偏移量。
Approach
Naive Lite-HRNet
Shuffle blocks
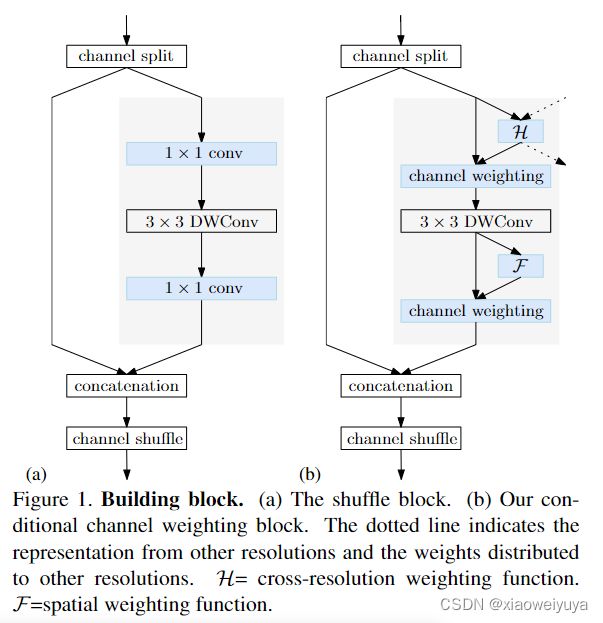
Shuffle Block会将通道首先分为两个部分,其中的一部分会送入一个1*1 Conv 3*3 DepthWise Conv和1*1 Conv中进行增强,处理完后会和另一部分拼接起来,最终会把通道重新shuffle。如图1.a所示。

HRNet
HRNet[41]从作为第一级的高分辨率卷积stem开始,逐渐地逐个添加高到低分辨率的流作为新的级。多分辨率流是并行连接的。主体由一系列阶段组成。在每个阶段,跨分辨率的信息被重复地交换。我们遵循Small HRNet设计,使用更少的层和更小的宽度来形成我们的网络。小的HRNet的茎由两个3×3的卷曲组成,步长为2。主体中的每一级包含一个剩余块序列和一个多分辨率融合。图2说明了Small HRNet的结构。

Simple combination
通过简单将Stem中的第2个3*3 Conv以及所有的Residual Block替换为Shuffle Block,并且将所有multi-resolution fusion中的Conv替换为Separable Conv,即可得到 Naive Lite-HRNet。
Lite-HRNet
1 ×1 convolution is costly
1×1卷积在每个位置执行矩阵-向量乘法:

X和Y是输入输出的特征图,W是1×1卷积核。它起着跨通道交换信息的关键作用,因为shuffle操作和深度卷积对跨通道的信息交换没有影响。
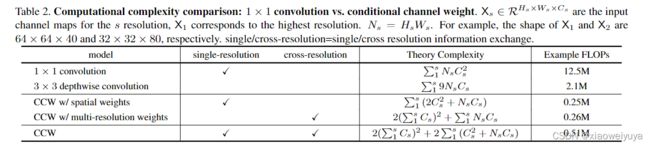
1×1卷积相对于通道数目C的复杂度是![]() ,3×3的深度卷积是线性关系
,3×3的深度卷积是线性关系![]() 。在shuffle block当中,,当C > 5时,两个1*1卷积的计算复杂度就会超过一个深度卷积的计算复杂度。表2给出了1×1卷积和深度卷积的复杂度比较实例。
。在shuffle block当中,,当C > 5时,两个1*1卷积的计算复杂度就会超过一个深度卷积的计算复杂度。表2给出了1×1卷积和深度卷积的复杂度比较实例。
Conditional channel weighting
为了降低计算复杂度,本文则是提出使用Element-wise weighting operation去代替1*1 Conv。第s个阶段有s个分支,第s分辨率分支的操作是:
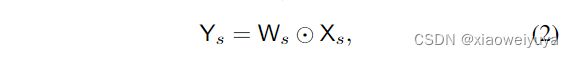
Ws是权重映射,3D-tensor的大小是Ws×Hs×Cs,该算法的复杂度是![]() ,远低于shuffle block中的1×1卷积。
,远低于shuffle block中的1×1卷积。
我们通过使用单一分辨率的通道和所有分辨率的通道来计算权重,如图1(b)所示,并表明权重在通道和分辨率之间交换信息的作用。
Cross-resolution weight computation

首先是对X1~Xs-1进行自适应平均池化AAP,得到X1'~Xs-1' ,AAP可以将任意输入大小输出到指定大小Ws×Hs,然后将X1'~Xs-1' 和Xs结合起来,然后使用1×1卷积、RELU、1×1卷积、sigmoid,产生由s个权重组成的权重图(W1'W2'...Ws'),每个对应着一种分辨率。
这里,每个分辨率的每个位置的权重取决于来自平均池化多分辨率通道图的同一位置的通道特征。 这就是为什么我们称该方案为跨分辨率权重计算。 s−1 权重图 W'1, W'2, . . . , W′s−1, 被上采样到相应的分辨率,输出 W1, W2, ... . . , Ws-1,用于后续的逐元素通道加权。
我们表明,权重图可以作为跨渠道和分辨率的信息交换的桥梁。 位置 i 的权重向量 wsi 的每个元素(来自权重图 Ws)接收来自同一池化区域的所有 s 分辨率的所有输入通道的信息,这很容易从公式 4 中的操作验证。通过这样的权重向量,该位置的每个输出通道在所有分辨率上从同一位置的所有输入通道接收信息。 换句话说,通道加权方案在交换信息方面与 1×1 卷积一样发挥作用。
![]()
另一方面,函数Hs(·)应用于小分辨率,计算复杂度很轻。 表 2 说明整个单元的复杂度远低于 1×1 卷积。
Spatial weight computation
对于每个分辨率,我们还计算与空间位置同质的空间权重:所有位置的权重向量 wsi 相同。 权重取决于单个分辨率中输入通道的所有像素:

其中Fs的实现为:

通过用空间权重![]() 对通道进行加权,输出通道中的每个元素接收来自所有输入通道的所有位置的贡献。我们比较了表2中1×1卷积和条件信道加权单元的复杂度。
对通道进行加权,输出通道中的每个元素接收来自所有输入通道的所有位置的贡献。我们比较了表2中1×1卷积和条件信道加权单元的复杂度。
Instantiation
Lite-HRNet由一个高分辨率stem和保持高分辨率表示的主体组成。作为第一阶段,主干有一个3×3的步长为2的卷积和一个shuffle block,主体有一系列模块化的模块。
每个模块由两个条件通道加权模块和一个多分辨率融合模块组成。每个分辨率分支的通道维度分别为C、2C、4C和8C。表1描述了详细的结构。

Connection
条件通道加权方案与条件卷积 [48]、动态滤波器 [21] 和挤压激励网络squeeze-excite-network[19] 具有相同的理念。 这些工作通过以输入特征为条件的子网络学习卷积核或混合权重,以增加模型容量。 相反,我们的方法利用了额外的效果,并使用从所有通道中学习到的权重作为跨通道和分辨率交换信息的桥梁。 它可以替代轻量级网络中昂贵的 1×1 卷积。 此外,我们引入了多分辨率信息来促进权重学习。
Experiments
dataset:COCO+MPII
Results
COCO val


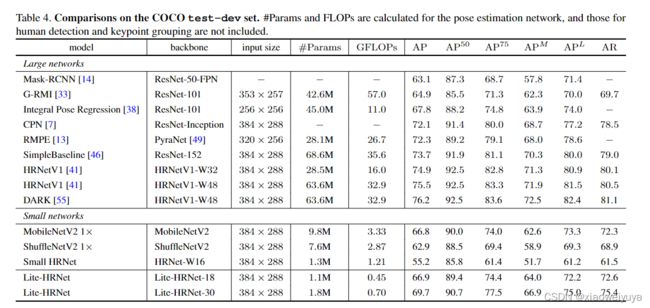
COCO test
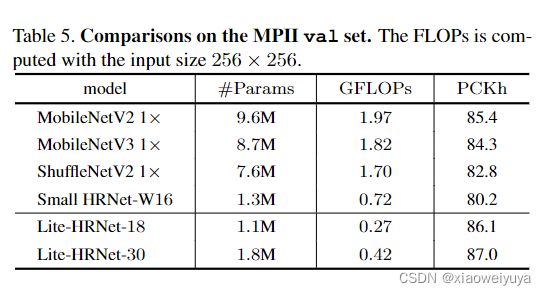
MPII val