论文阅读笔记:Recurrent recommender networks
论文提要
传统的推荐系统认为用户偏好和电影属性都是静态的,但其实它们都是随时间变化的。典型的如:用户偏好会被他们所看到的所影响,也会被电影评分所引导。本文作者采用RNN对用户的行为轨迹做预测。采用LSTM构建了一个自回归的模型,以适应user及movie的动态性。本文所论述的方法在多种数据集上的验证结果都是精准的。
解决的问题
推荐系统传统的解决方案对数据的时间效应和因果属性缺乏处理,典型情景如:
1. 用户对电影的看法是随时间变化的,这种变化会使得一些垃圾电影变为流行电影
2. 季节时令性:浪漫喜剧,圣诞电影,夏日大片等类型的movie的季节性尤其突出。
3. 用户兴趣:这个变化因素就更多了,通常很难显式建模。
作者认为,除了对时间演化进行建模的需求外,通常我们采用事后评估的方式是违反因果关系的基本要求的。换句话说,我们使用未来的评分来评估当前的评论时,我们违背了统计分析中的因果关系。这种评估机制不能够确定我们的系统能否在实践中运行良好。本文提出的是,我们能够通过一种显式的模型,处理随时间动态变化的用户偏好,基于当前的趋势,预测未来的行为。
同行中,考虑到时间因素的相关工作也有一些,如Probabilistic Matrix Factorization(PDF), TimeSVD++,AutoRec等。相较而言,作者认为自己设计的RRN在各方面都有一定优势。
解决方法
问题建模
考虑到用户偏好和电影属性包含时间动态性因子之后,此时推荐系统可以如下图描述:

其中,左图是与时间无关的推荐模型,右图是时间相关模型,其中用户和电影模型可用马氏链描述,推荐结果与用户和电影的时间状态相关。右图模型的关键挑战在于如何用现有的观测数据来预测未来状态。常用的做法是提取打分信息计算似然率然后反馈到潜在状态中,典型的算法有粒子过滤,序列蒙特卡罗等。作者基于RNN对该问题做了一定的简化,使用了一个潜在变量使得模型自回归,如下式:

zt表示t时刻的观测数据,ht表示潜在状态。进一步的,使用LSTM构建协同过滤系统,处理时变属性,是一个不错的选择方案,基于LSTM,上式可以被表示为:

其中,f, i, o表示遗忘门,输入门,输出门,它们控制着网络中信息的流动。接下来,LSTM用下面的式子简单的表示:
ht = LSTM(ht−1 , zt )
为了表示用户user和电影movie的时间依赖性,uj变量加上时间下标t表示用户j在时刻t时的状态,即ujt,所以该预测问题可下式表示:

输出rˆij|t表示用户i在时刻t对电影j的评分。学习出f,g,h后,我们可以直接推导出新的用户状态。通常的最优化问题是寻找使得输出最优的用户变量,我们要解决的问题是求解出能够发现最优用户变量的函数,该函数能够依序更新评分,从而能够基于我们的评分集做出前向预测在时刻t,这一点是我们的方法和普通方法的关键不同点。
用户状态的RNN和电影状态的RNN是类似的。作者详细的介绍了用户RNN的构建,用下式构建LSTM的输入yt:
yt :=Wembed[xt,1newbie,τt,τt−1]
τt,τt−1表示在t及t-1时刻的状态,xt的值表示t时刻用户对电影的评分,W是一个embedding操作。从而用户状态RNN如下式表示:
ut := LSTM(ut−1,yt)
事实上,用户状态依然可以拆分为两部分。一部分是稳定的,一部分是时变的。电影状态也是类似的。所以用户评分预测可以表示如下:
![]()
最后,总结一下整体的工作流程:作者取最近的观测状态作为输入,然后以最新的状态为基础,做状态更新并对未来做预测。显然该过程自然的考虑了之前的评分数据,符合因果关系。对于预测的评估可以转化为一个最优化问题,其实也就是加了修正项的最小平方误差。

其中theta表示所有被学习的变量。解决该最优化问题的关键挑战在于,求解每一次评分预测时,都依赖于用户的RNN和电影的RNN,作者提出一种简化方法,也称为子空间下降:在反馈传播用户评分并更新用户向量的时候,固定电影状态;对于电影向量的更新,也是如此。
实验
作者的实验在IMDb和Netflix数据集上都有验证。具体的实验效果参见下表:
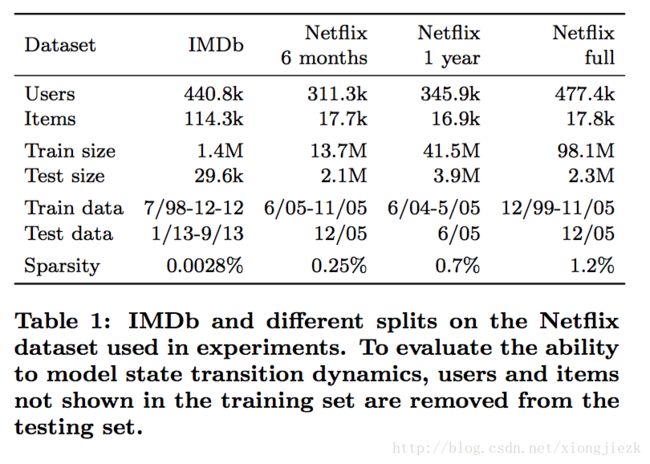
在实验的设置上,有以下细节点需要关注:
1. 网络结构:LSTM隐层数是1,隐层神经元是40,输入embedding维数是40,动态状态是20维,对于奈飞和iDMb数据分别设置20维和160维的静态因子。整个模型构建在深度学习框架MXnet上。
2. 训练:使用ADAM优化网络参数,使用SGD更新静态因子。对静态因子使用PMF做预训练。
3. 时间动态性处理(Temporal Dynamics):作者分外部源和内部源分别论述了电影的时间动态性。外部源,如电影的获奖因素等。内部源,如电影也有年龄,新上线的电影有评分下降的趋势,但随着时间的增加,该电影的评分又有增加的趋势。
4. 时间粒度及敏感性:时间粒度划分的越小,模型的状态更新会越频繁,short-term效果也越容易获取。但是对于LSTM,时间粒度划分越小,训练成本也越大。作者通过实验说明,预测的效果(RMSE)对时间粒度的大小并不是非常敏感。这可能是因为RNN的生成是完全一般的,它没有假定数据的形式或具体分布。
结论
作者认为其所设计的RRN主要有以下贡献:
1. Nonlinear, Nonparametric, Dynamic Recommender:无需手动选择特征,联合用户和物品状态,预测未来趋势。通过选择神经网络结构,学习用户和电影的动态嵌入。
2. Efficient Training:模型训练效率高,可以训练6年的电影数据,为超过100M数据评分。
3. Empirical Evidence:该模型预测的准确度比其他模型更高,能够自动获取出与时间相关的模式特征,和已知的时间模式相匹配。
本文贡献及我的思考
具体参见上文作者总结。
但我认为,本文更多的在于为RNN应用于推荐系统提供了一种思路,并基于奈飞和iDMb数据,和现有的一些其他方法做效果对比,突出了RNN也适用于推荐场景。
可能是我没有完全理解吧,本文结构在递进关系上感觉不是特别清晰,对模型的描述有些过于抽象,不是很好理解。不知是作者为了突出算法效果还是其他目的,文中太多地方在强调所设计的模型效果卓越,性能卓越。当然,在实验过程中,作者和多种算法的效果都有对比,有具体数据,这也是本文的一个优势。我们在做论文的过程中,也应如此。
文章引用
Wu C Y, Ahmed A, Beutel A, et al. Recurrent recommender networks[C]//Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. ACM, 2017: 495-503.