深度学习常用数据集简介
深度学习常用数据集简介
数据集
- 深度学习常用数据集简介
-
- CIFAR
- ImageNet
- SVHN
- MNIST
- FashionMNIST
CIFAR
CIFAR是由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集而来;
起初的数据集共分10类,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,所以CIFAR数据集常以CIFAR-10命名。
CIFAR共包含60000张32*32的彩色图像(包含50000张训练图片,10000张测试图片),其中没有任何类型重叠的情况。
后来CIFAR又出了一个分类更多的版本叫CIFAR-100,共有100类,将图片分得更细。
图片样例如下

ImageNet
ImageNet数据集是一个计算机视觉数据集,是由斯坦福大学的李飞飞教授带领创建。
该数据包含的大类别有:anmphibian、animal、appliance、bird、covering、device、fabric、fish、flower、food、fruit、furniture、mammal、musical instrument、plant、reptile、sport、structure、tool、tree、vegetable、vehicle、person。
该数据集包合 14,197,122张图片和21,841个Synset索引。
图片样例如下

ImageNet是一个根据WordNet层次结构(目前只有名词)组织的图像数据库,其中层次结构的每个节点都由成百上千的图像描述。该项目在推进计算机视觉和深度学习研究方面发挥了重要作用。研究人员可以免费获得这些数据,用于非商业用途。
与CIFAR-10数据集相比
相比CIFAR-10 , ImageNet 数据集图片数量更多, 分辨率更高,含有的类别更多(上千个图像类别),图片中含更多的无关噪声和变化,因此识别难度比CIFAR-10 高得多。
SVHN
SVHN(Street View House Number)Dateset 来源于谷歌街景门牌号码。
图片样例如下


MNIST
MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集,每个样本图像的宽高为28*28(下图展示的是一个大小为64的patch网格化成的8*8的格式)。此数据集是以二进制存储的,不能直接以图像格式查看,不过很容易找到将其转换成图像格式的工具。
基于pytorch的代码可以直接调用torchvision.datasets.MNIST()下载:
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean = [0.5],std = [0.5])])
dataset_train = datasets.MNIST(root = './data/',
transform = transform,
train = True,
download = True)
dataset_test = datasets.MNIST(root = './data/',
transform = transform,
train = False,
download = True)
图片样例如下

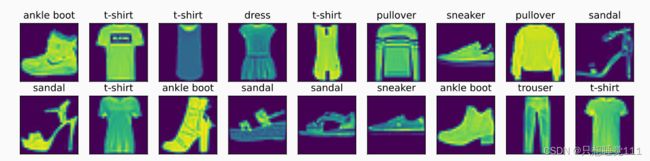
FashionMNIST
不同于MNIST手写数据集,Fashion-MNIST数据集包含了10个类别的图像,分别是:t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴)。
基于pytorch的代码可以直接调用torchvision.datasets.FashionMNIST()下载:
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean = [0.5],std = [0.5])])
dataset_train = datasets.FashionMNIST(root = './data/',
transform = transform,
train = True,
download = True)
dataset_test = datasets.FashionMNIST(root = './data/',
transform = transform,
train = False,
download = True)
图片样例如下