图片数据清洗
前言
数据对于深度学习算法模型的效果至关重要。通常,在对采集到的大量数据进行标注前需要做一些数据清洗工作。对于大量的数据,人工进行直接清洗速度会很慢,因此开发一些自动化清洗工具对批量数据首先进行自动清洗,然后再进行人工审核并清洗,可以很大程度上提高效率。
工具功能
根据收集到的需求,工具主要实现了以下功能:
- 统计数据信息(总占用空间、数量、损坏图片数);
- 去除已损坏图片,
- 去除模糊图片,
- 去除相似图片,
- 机动车车色分类,
- 昼夜分类
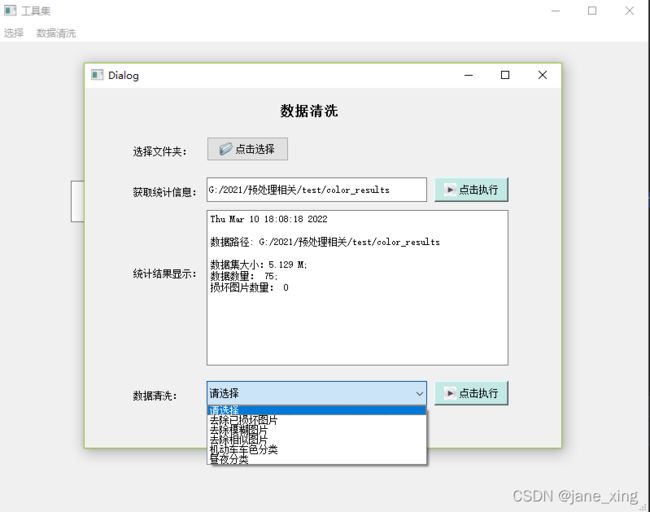
统计数据信息
# 获取数据集存储大小、图片数量、破损图片数量
def get_data_info(dir_path):
size = 0
number = 0
bad_number = 0
for root, dirs, files in os.walk(dir_path):
img_files = [file_name for file_name in files if is_image(file_name)]
files_size = sum([os.path.getsize(os.path.join(root, file_name)) for file_name in img_files])
files_number = len(img_files)
size += files_size
number += files_number
for file in img_files:
try:
img = Image.open(os.path.join(root, file))
img.load()
except OSError:
bad_number += 1
return size / 1024 / 1024, number, bad_number
去除已损坏图片
# 去除已损坏图片
def filter_bad(dir_path):
filter_dir = os.path.join(os.path.dirname(dir_path), 'filter_bad')
if not os.path.exists(filter_dir):
os.mkdir(filter_dir)
filter_number = 0
for root, dirs, files in os.walk(dir_path):
img_files = [file_name for file_name in files if is_image(file_name)]
for file in img_files:
file_path = os.path.join(root, file)
try:
Image.open(file_path).load()
except OSError:
shutil.move(file_path, filter_dir)
filter_number += 1
return filter_number
去除模糊图片
首先需要判断图片的清晰度,用opencv提供的拉普拉斯算子接口求得清晰度数值,数值越小,清晰度越低,也就越模糊(通常以100位分界值)。
# 去除模糊图片
def filter_blurred(dir_path):
filter_dir = os.path.join(os.path.dirname(dir_path), 'filter_blurred')
if not os.path.exists(filter_dir):
os.mkdir(filter_dir)
filter_number = 0
for root, dirs, files in os.walk(dir_path):
img_files = [file_name for file_name in files if is_image(file_name)]
for file in img_files:
file_path = os.path.join(root, file)
# img = cv2.imread(file_path)
img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), -1)
image_var = cv2.Laplacian(img, cv2.CV_64F).var()
if image_var < 100:
shutil.move(file_path, filter_dir)
filter_number += 1
return filter_number
还有很多图像模糊检测的方法,可以参考:https://www.cnblogs.com/greentomlee/p/9379471.html
去除相似图片
对于一些通过视频抽帧得到的图片数据,连续图片相似度会很高,需要剔除相似度较高的图片数据。
首先我们需要计算两张图片的相似度,计算相似度的方法通常有以下几种:
- 通过直方图计算图片的相似度;
- 通过哈希值,汉明距离计算;
- 通过图片的余弦距离计算;
- 通过图片的结构度量计算。
四种方法结果可能会不同。
参考:https://blog.csdn.net/weixin_35132022/article/details/112514520
下面是利用python opencv中通过直方图计算图片的相似度。去除相似图片过程通过遍历求每张图片和它之后的四张图片(这里比较之后的几张可以根据实际需求调整)的相似度,如果相似度超过阈值则剔除后面的图片。
# 计算两张图片的相似度
def calc_similarity(img1_path, img2_path):
img1 = cv2.imdecode(np.fromfile(img1_path, dtype=np.uint8), -1)
H1 = cv2.calcHist([img1], [1], None, [256], [0, 256]) # 计算图直方图
H1 = cv2.normalize(H1, H1, 0, 1, cv2.NORM_MINMAX, -1) # 对图片进行归一化处理
img2 = cv2.imdecode(np.fromfile(img2_path, dtype=np.uint8), -1)
H2 = cv2.calcHist([img2], [1], None, [256], [0, 256]) # 计算图直方图
H2 = cv2.normalize(H2, H2, 0, 1, cv2.NORM_MINMAX, -1) # 对图片进行归一化处理
similarity1 = cv2.compareHist(H1, H2, 0) # 相似度比较
print('similarity:', similarity1)
if similarity1 > 0.98: # 0.98是阈值,可根据需求调整
return True
else:
return False
# 去除相似度高的图片
def filter_similar(dir_path):
filter_dir = os.path.join(os.path.dirname(dir_path), 'filter_similar')
if not os.path.exists(filter_dir):
os.mkdir(filter_dir)
filter_number = 0
for root, dirs, files in os.walk(dir_path):
img_files = [file_name for file_name in files if is_image(file_name)]
filter_list = []
for index in range(len(img_files))[:-4]:
if img_files[index] in filter_list:
continue
for idx in range(len(img_files))[(index+1):(index+5)]:
img1_path = os.path.join(root, img_files[index])
img2_path = os.path.join(root, img_files[idx])
if calc_similarity(img1_path, img2_path):
filter_list.append(img_files[idx])
filter_number += 1
for item in filter_list:
src_path = os.path.join(root, item)
shutil.move(src_path, filter_dir)
return filter_number
机动车车色分类
方法一:传统算法(结果不理想)
使用opencv库函数进行处理。
1、将图片颜色转为hsv,
2、使用cv2.inRange()函数进行背景颜色过滤
3、将过滤后的颜色进行二值化处理
4、进行形态学腐蚀膨胀,cv2.dilate()
5、统计白色区域面积
参考:https://www.jb51.net/article/172797.htm
# 定义HSV颜色字典
def get_color_list():
dict = collections.defaultdict(list)
# 黑色
lower_black = np.array([0, 0, 0])
upper_black = np.array([180, 255, 46])
color_list = []
color_list.append(lower_black)
color_list.append(upper_black)
dict['black'] = color_list
# 灰色
# lower_gray = np.array([0, 0, 46])
# upper_gray = np.array([180, 43, 220])
# color_list = []
# color_list.append(lower_gray)
# color_list.append(upper_gray)
# dict['gray'] = color_list
# 白色
lower_white = np.array([0, 0, 221])
upper_white = np.array([180, 30, 255])
color_list = []
color_list.append(lower_white)
color_list.append(upper_white)
dict['white'] = color_list
# 红色1
lower_red = np.array([156, 43, 46])
upper_red = np.array([180, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red'] = color_list
# 红色2
lower_red = np.array([0, 43, 46])
upper_red = np.array([10, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red2'] = color_list
# 橙色
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([25, 255, 255])
color_list = []
color_list.append(lower_orange)
color_list.append(upper_orange)
dict['orange'] = color_list
# 黄色
lower_yellow = np.array([26, 43, 46])
upper_yellow = np.array([34, 255, 255])
color_list = []
color_list.append(lower_yellow)
color_list.append(upper_yellow)
dict['yellow'] = color_list
# 绿色
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list = []
color_list.append(lower_green)
color_list.append(upper_green)
dict['green'] = color_list
# 青色
lower_cyan = np.array([78, 43, 46])
upper_cyan = np.array([99, 255, 255])
color_list = []
color_list.append(lower_cyan)
color_list.append(upper_cyan)
dict['cyan'] = color_list
# 蓝色
lower_blue = np.array([100, 43, 46])
upper_blue = np.array([124, 255, 255])
color_list = []
color_list.append(lower_blue)
color_list.append(upper_blue)
dict['blue'] = color_list
# 紫色
lower_purple = np.array([125, 43, 46])
upper_purple = np.array([155, 255, 255])
color_list = []
color_list.append(lower_purple)
color_list.append(upper_purple)
dict['purple'] = color_list
return dict
# 颜色识别
def get_color(image):
print('go in get_color')
img_array = cv2.imdecode(np.fromfile(image, dtype=np.uint8), -1)
kernel_4 = np.ones((4, 4), np.uint8) # 4x4的卷积核
hsv = cv2.cvtColor(img_array, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = get_color_list()
print(color_dict)
for key in color_dict:
mask = cv2.inRange(hsv, color_dict[key][0], color_dict[key][1]) # mask是把HSV图片中在颜色范围内的区域变成白色,其它区域变成黑色
cv2.imwrite(key + os.path.splitext(image)[-1], mask)
erosion = cv2.erode(mask, kernel_4, iterations=1)
erosion = cv2.erode(erosion, kernel_4, iterations=1)
dilation = cv2.dilate(erosion, kernel_4, iterations=1)
dilation = cv2.dilate(dilation, kernel_4, iterations=1)
target = cv2.bitwise_and(img_array, img_array, mask=dilation)
binary = cv2.threshold(dilation, 127, 255, cv2.THRESH_BINARY)[1]
# binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
# binary = cv2.dilate(binary, None, iterations=2)
cnts, hiera = cv2.findContours(binary.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# cnts, hiera = cv2.findContours(binary.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = key
return color
方法二:深度学习模型
采用训练好的针对机动车ROI图像颜色分类模型,效果好太多了。
# 对机动车ROI图片按颜色分类
def classify_vehcolor(dir_path):
result_dir = os.path.join(os.path.dirname(dir_path), 'color_results')
if not os.path.exists(result_dir):
os.mkdir(result_dir)
color_list = dict_color.values()
for color in color_list:
color_dir = os.path.join(result_dir, color)
if not os.path.exists(color_dir):
os.mkdir(color_dir)
classify_number = 0
for root, dirs, files in os.walk(dir_path):
for dir in dirs:
result_dic = classify_color(os.path.join(root, dir))
for key, value in result_dic.items():
dst_path = os.path.join(result_dir, value)
try:
shutil.move(key, dst_path)
classify_number += 1
except Exception:
pass
img_files = [file_name for file_name in files if is_image(file_name)]
if len(img_files) != 0:
result_dic = classify_color(root)
for key, value in result_dic.items():
dst_path = os.path.join(result_dir, value)
try:
shutil.move(key, dst_path)
classify_number += 1
except Exception:
pass
return classify_number
昼夜分类
即对图片拍摄场景是白天还是黑夜进行分类。这里采用求图片的平均亮度进行粗略分类,经实测,准确率不高,但目前先采用该方法进行初步清洗吧,后续有时间再寻求更优算法。
# 对图片进行昼夜分类,根据图片的平均亮度
def classify_day_or_night(dir_path):
result_dir = os.path.join(os.path.dirname(dir_path), 'day_night_results')
if not os.path.exists(result_dir):
os.mkdir(result_dir)
item_list = ['白天', '黑夜']
for item in item_list:
item_dir = os.path.join(result_dir, item)
if not os.path.exists(item_dir):
os.mkdir(item_dir)
classify_number = 0
for root, dirs, files in os.walk(dir_path):
img_files = [file_name for file_name in files if is_image(file_name)]
for file in img_files:
file_path = os.path.join(root, file)
rgb_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), -1)
img = cv2.cvtColor(rgb_img, cv2.COLOR_BGR2GRAY)
brightness_value = img.mean()
print('brightness_value', brightness_value)
if brightness_value > 95:
key = '白天'
else:
key = '黑夜'
dst_path = os.path.join(result_dir, key)
try:
shutil.move(file_path, dst_path)
classify_number += 1
except Exception:
pass
return classify_number
工具界面展示