NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据读取
实现代码:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_' + str(batch_id))
# 加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding='latin1')
imgs = batch['data'].reshape((len(batch['data']), 3, 32, 32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path='E:\pythonProject\cifar-10-batches-py',
batch_id=1, mode='train')
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)输出结果:

可视化观察其中的一张样本图像和对应的标签,代码实现如下:
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
import matplotlib.pyplot as plt
image, label = imgs_batch[2], labels_batch[2]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn.pdf')

5.5.1.3 数据集划分
代码如下:
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path='E:\pythonProject\cifar-10-batches-py', mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path='E:\pythonProject\cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='E:\pythonProject\cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='E:\pythonProject\cifar-10-batches-py', mode='test')5.5.2 模型构建
使用Resnet18进行图像分类实验
代码如下:
from torchvision.models import resnet18
resnet18_model = resnet18()
# print(resnet18_model)什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练模型:
首先,在一个原始任务上预先训练一个初始模型,然后在目标任务上使用该模型,针对目标任务的特性,对该初始模型进行精调,从而达到提高目标任务的目的。在本质上,这是一种迁移学习的方法,在自己的目标任务上使用别人训练好的模型。对于文本语言来说,是有天然的标注特征的存在的,原因就在于文本可以根据之前的输入词语进行预测,而且文本大多是有很多词语,所以就可以构成很大的预训练数据,进而可以自监督(不是无监督,因为词语学习过程是依据之前词语的输出的,所以应该是自监督学习)的预训练。
迁移学习:
迁移学习(Transfer Learning)是机器学习中的一个名词,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
比较“使用预训练模型”和“不使用预训练模型”的效果
修改代码,两个对比:
resnet = models.resnet18(pretrained=True) //预训练
resnet = models.resnet18(pretrained=False) //不预训练得到结果:
[ Train ] epoch :24/30, step :15000/18750, loss :0.35322
[ Evaluate ] dev score :0.70030 dev loss :0.86372
[ Evaluate ] best accuracy performence has been updated :0.69470-->0.70030
[ Train ] epoch :28/30, step :18000/18750, loss :0.47557
[ Evaluate ] dev score :0.68210, dev loss :0.92323
[ Evaluate ] dev score :0.69590, dev loss :0.91344
[ Train ] Training done !
Process finished with exit code 0对比结果可以看出使用预训练的模型正确率更高,收敛速度更快。
5.5.3 模型训练
RunnerV3类代码实现如下:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
self.dev_scores = []
self.train_epoch_losses = []
self.train_step_losses = []
self.dev_losses = []
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
self.model.train()
num_epochs = kwargs.get("num_epochs", 0)
log_steps = kwargs.get("log_steps", 100)
eval_steps = kwargs.get("eval_steps", 0)
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
global_step = 0
for epoch in range(num_epochs):
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
logits = self.model(X).cuda()
y = y.to(dtype=torch.int64)
y = y.cuda()
loss = self.loss_fn(logits, y)
total_loss += loss
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
loss.backward()
if custom_print_log:
custom_print_log(self)
self.optimizer.step()
optimizer.zero_grad()
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
self.model.train()
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
trn_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
import torch
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
self.model.eval()
global_step = kwargs.get("global_step", -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
X, y = data
y = y.to(torch.int64)
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
loss = self.loss_fn(logits, y).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
@torch.no_grad()
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
self.dev_scores = []
self.train_epoch_losses = []
self.train_step_losses = []
self.dev_losses = []
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
self.model.train()
num_epochs = kwargs.get("num_epochs", 0)
log_steps = kwargs.get("log_steps", 100)
eval_steps = kwargs.get("eval_steps", 0)
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
global_step = 0
for epoch in range(num_epochs):
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
X = X.cuda()
logits = self.model(X).cuda()
y = y.to(dtype=torch.int64)
y = y.cuda()
loss = self.loss_fn(logits, y)
total_loss += loss
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
loss.backward()
if custom_print_log:
custom_print_log(self)
self.optimizer.step()
optimizer.zero_grad()
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
self.model.train()
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
trn_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
import torch
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
self.model.eval()
global_step = kwargs.get("global_step", -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
X, y = data
y = y.to(torch.int64)
X = X.cuda()
y = y.cuda()
logits = self.model(X).cuda()
loss = self.loss_fn(logits, y).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
@torch.no_grad()
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)训练代码:
import torch
import torch.nn.functional as F
import torch.optim as opt
def accuracy(preds, labels):
print(preds)
if preds.shape[1] == 1:
preds = torch.can_cast((preds >= 0.5).dtype, to=torch.float32)
else:
preds = torch.argmax(preds, dim=1)
torch.can_cast(preds.dtype, torch.int32)
return torch.mean(torch.tensor((preds == labels), dtype=torch.float32))
class Accuracy():
def __init__(self):
self.num_correct = 0
self.num_count = 0
self.is_logist = True
def update(self, outputs, labels):
if outputs.shape[1] == 1:
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
preds = torch.can_cast((outputs >= 0), dtype=torch.float32)
else:
preds = torch.can_cast((outputs >= 0.5), dtype=torch.float32)
else:
preds = torch.argmax(outputs, dim=1).int()
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")输出结果:
[Train] epoch: 0/30, step: 0/18750, loss: 8.48361
[Evaluate] dev_score: 0.05810, dev_loss: 12.02462
best accuracy performence has been updated: 0.00000 --> 0.05143
[Train] epoch: 4/30, step: 3000/18750, loss: 0.76241
[Evaluate] dev_score: 0.62389, dev_loss: 1.02014
best accuracy performence has been updated: 0.05143 --> 0.64120
[Train] epoch: 9/30, step: 6000/18750, loss: 0.55245
[Evaluate] dev_score: 0.73120, dev_loss: 0.86646
best accuracy performence has been updated: 0.64120--> 0.73652
[Train] epoch: 14/30, step: 9000/18750, loss: 0.56214
[Evaluate] dev_score: 0.71552, dev_loss: 0.83452
[Train] epoch: 19/30, step: 12000/18750, loss: 0.76234
[Evaluate] dev_score: 0.72003, dev_loss: 0.90214
[Train] epoch: 24/30, step: 15000/18750, loss: 0.60124
[Evaluate] dev_score: 0.72440, dev_loss: 0.82145
best accuracy performence has been updated: 0.73652 --> 0.71544
[Train] epoch: 28/30, step: 18000/18750, loss: 0.65241
[Evaluate] dev_score: 0.73246, dev_loss: 0.82426
best accuracy performence has been updated: 0.71544 --> 0.73650
[Train] Training done!5.5.4 模型评价
代码如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))输出结果:
[Test] accuracy/loss: 0.83144/0.56585.5.5 模型预测
# 获取测试集中的一个batch的数据
X, label = next(test_loader())
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits)
# 获取概率最大的类别
pred_class = paddle.argmax(pred[2]).numpy()
label = label[2][0].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label[0], pred_class[0]))
# 可视化图片
X=np.array(X)
plt.imshow(X.transpose(1, 2, 0))
plt.show()输出结果:
The true category is 5 and the predicted category is 5思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
不同层次的ResNet的解析
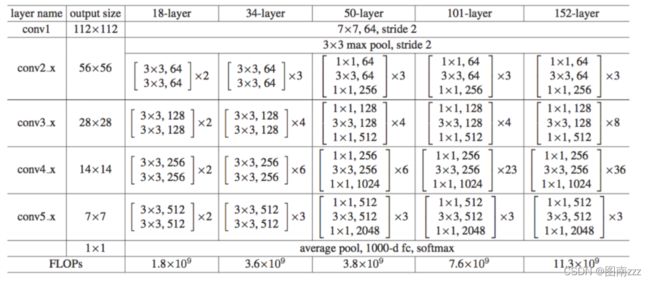
上表中一共有五种深度的ResNet,分别是18, 34, 50, 101和152,首先看图最左侧,我们发现所有的网络都分为五部分,分别是 conv1, conv2_x, conv3_x, conv4_x , conv5_x。
拿 101-layer 那列,首先有个 输入 7*7*64的卷积,然后经过 3 + 4 + 23+ 3 = 33 个 building block ,每个 block 为3层,所以有 33*3 = 99 层,最后有个 fc 层(用于分类),所有有 1+99+1=101层,确实有101层网络。
继续关注50-layer 和 101-layer 这两列,可以发现,他们唯一的不同在于 conv4_x, ResNet50有6个block,而 ResNet101有 23 个 block,插了17个block,也就是 17*3=51层。
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet:深度CNN网络的基石。
AlexNet:改良加深版的LeNet,包含8层变换,效果出众,掀起深度学习热潮。
VGG:从图像中提取CNN特征的首选算法,迁移学习优于LeNet。
GoogLeNet:LeNet 2.0版本,引入了Inception结构,通过更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
ResNet:主要解决了深度网络中的退化的问题,在VGG基础上提升了长度,加入了res-block结构,是当下主流网络。
总结
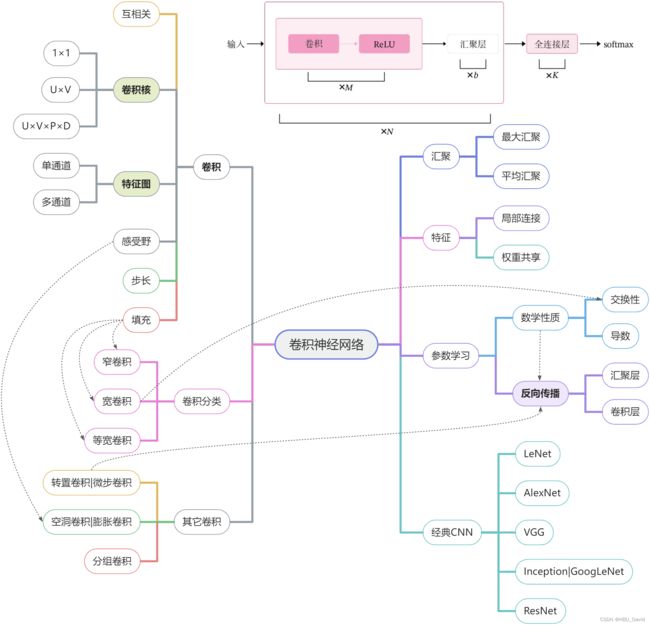
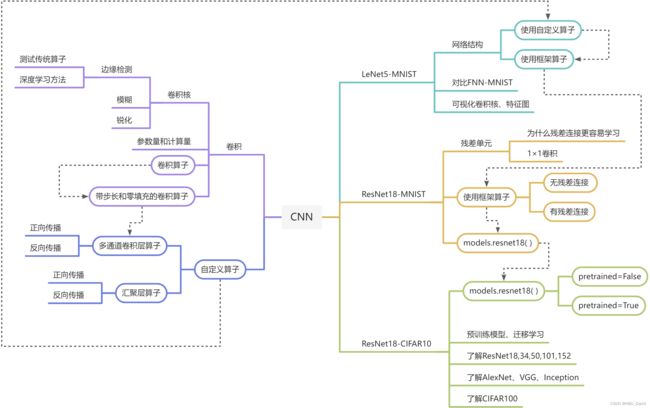
使用思维导图全面总结CNN(必做)
实验心得:学习了解了预训练模型和迁移学习,cifar10有关内容上一学期没有好好学过,现在尝试去了解了一下,也加深了对ResNet18网络的理解,就是用CPU训练太慢了点,下次实验之前要改用GPU.