[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear
UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Learning
https://arxiv.org/pdf/2201.04676.pdf
https://github.com/Sense-X/UniFormer
ICLR 2022
1 Introduction
从高维视频中学习多尺度时空语义是很困难的,因为视频帧之间的全局依赖很复杂。
在图1中,TimeSformer在浅层中学习视频信息,但是空间和时间注意力都过于冗余。
空间注意力主要集中于相邻的token(3*3局域中),忽略同一帧中的其他位置。
时间注意力主要关心相邻帧的token,忽略更远帧的信息。
另外,这样的局部信息是从所有层的全局toekn-to-token 相似性比较中学习得到的,计算量很大。
从图2可以看到,TimeSformer计算量大的同时,效果并不算非常好。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第1张图片](http://img.e-com-net.com/image/info8/6b9e0a47768b43b3a3be128f2080c215.jpg)
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第2张图片](http://img.e-com-net.com/image/info8/29bc3f2077cc4c0ab2c08e6a1690854e.jpg)
因此,我们将3D卷积和时空自注意力结合在一个简洁的transformer结构中,achieve a preferable balabce between efficiency and effectiveness,在计算量和精确度上达到平衡。
UniFormer与其他transformer的区别主要在于:
- relation aggregator分别处理 video redundancy and dependency,而不是在所有层都使用自注意力机制。在浅层,aggregator利用一个小的learnable matrix学习局部的关系,通过聚合小的3D邻域的token信息极大地减少计算量。在深层,aggregator通过相似性比较学习全局关系,可以灵活的建立远距离视频帧token之间的长程依赖关系。
- aggregator在所有层中同时编码时空信息
- 层级化构建网络结构
2 Method
2.1 Overview of Uniformer block
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第3张图片](http://img.e-com-net.com/image/info8/369a1916f2cc4259afeed1ae49c6775f.jpg)
UniFormer包含3个模块:
Dynamic Position Embedding (DPE),
Multi-Head Relation Aggregator (MHRA),
Feed-Forward Network (FFN)
输入Xin(C*T*H*W),首先使用DPE向所有的token中添加3D位置信息;
其次 MHRA 通过灵活地设计浅层和深层的token相似度学习方式 smartly tackles local video redundancy and global video dependency;
最后用FFN进行token的pointwise enhancement。
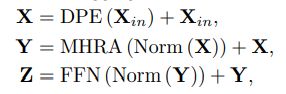
2.2 MULTI-HEAD RELATION AGGREGATOR
目标:solve large local redundancy and complex global dependency
之前的工作3D CNNs和时空transformers都只解决了这两个挑战中的一个。
MHRA以多头融合的方式进行token relation learning:
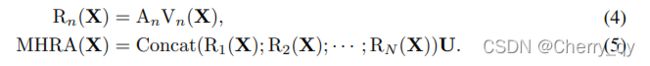
首先将输入 X (C*T*H*W) reshape 为 X (L*C),Rn()指第n个head的RA。
Vn() 是一个线性映射,将original token转换为context(L * C/N)。
An(L*L)是token相似度,在An的指导下aggregator可以对context进行总结。
RA中的关键就是如何学习视频中的An。
U(C*C)是一个可学习的参数矩阵,用于融合n个head。
2.2.1 local MHRA
在浅层中相邻token的视频信息相差很小,需要学习小的3D邻域中的局部时空信息,因此可以用local operator来减少redundancy。
将局部3D邻域中的token相似度设计为一个局部的可学习参数矩阵,其值仅取决于3D相对位置编码。
RA学习small tube Ωi(t*h*w)中 当前token Xi 与 其他token Xj 之间的局部时空相似性:
![]()
![]()
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第4张图片](http://img.e-com-net.com/image/info8/eb647e633f894bbd9faed2dd7cd9a55e.jpg)
2.2.2 Comparison to 3D Convolution Block
本文的方式可以看做MobileNet Block的时空扩展,V()实例化为逐点卷积PWConv,
局部token相似性An是一个时空矩阵,对每个输出通道(或head)Vn(X)进行处理,
relation aggregator Rn(X)可以看做一个深度卷积(DWConv)。
最后所有head结果concat并由线性矩阵U来结合,也可以被实例化为逐点卷积(PWConv)。
因此,local MHRA可以看成是MobileNet Block中PWConv-DWConv-PWConv的形式。
区别在于MHRA加上了FFN。
2.2.3 Global MHRA
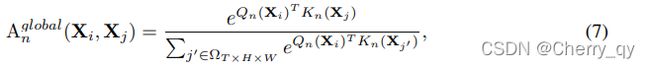
在深层,需要捕捉全局视频片段中的长程依赖关系。
Xj是全局3Dtube(T*H*W)中的any token,Q和K是两个不同的线性映射。
大多数video transformers在每个stage都使用自注意力,因此引入了很大的计算量。
为了减少点乘计算,之前的工作倾向于分割时间和空间注意力。
在MHRA中由于浅层的local relation aggregator节省了很多计算量,所以在深层中直接编码时空信息,
从而实现计算量与精度的平衡。
2.2.4 Comparison to Transformer Block
深层的MHRA可以看成是时空自注意力,此时Qn、Kn、Vn分别代表QKV,因此可以学习长期依赖关系。
2.3 DPE
![]()
用3D深度卷积来进行位置编码。Kernel size=3*3*3。
得益于共享参数和卷积的局部性,DPE可以适用于任意长度的视频序列。
2.4 FFN
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第5张图片](http://img.e-com-net.com/image/info8/0857f1e230aa43a6a5bf30173491e0d8.jpg)
2.5 Model Architecture
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第6张图片](http://img.e-com-net.com/image/info8/ec384e1e5457497d9153cd426badd4c0.jpg)
4 stages:通道数64,128,256,512。
设计了两个变体,在4 stages中的UniFormer block数量分别为:
UniFormer-S{5,8,20,7} UniFormer-B{3,4,8,3}
在前两个stage中使用MHRA with local token affinity,tube size 5*5*5,head number N与相应通道数一致,使用BN。
在后两个stage中使用MHRA with global token affinity,head dimension=64,使用LN。
所有stage 的FFN expand ratio=4。
在第一个stage前使用3*4*4卷积 stride2*4*4对时间和空间维度都进行下采样。
在其他stage前使用1*2*2卷积 stride1*2*2.
最后利用时空平均池化和全连接层来得到最终的预测结果输出。
2.5.1 Comparison to Convolution+Transformer Network
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第7张图片](http://img.e-com-net.com/image/info8/79661f2f5e3943a7bdbd54f79309bf16.jpg)
3 实验
3.1 comparisons
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第8张图片](http://img.e-com-net.com/image/info8/77d87ac549ad465da3d2e5a2c3a9202f.jpg)
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第9张图片](http://img.e-com-net.com/image/info8/18ee7f32be7541619d8af5c6754d5b33.jpg)
3.2 消融实验
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第10张图片](http://img.e-com-net.com/image/info8/bb167d15d24549ada43a2aa3622ddfc2.jpg)
3.2.1 UniFormer vs. Convolution: Does transformer-style FFN help?
表4(a)第2行:将浅层的Uniformer block替换为MobileNet block,实验结果证明FFN可以进一步融合token信息,提高分类精度。
3.2.2 UniFormer vs. Transformer: Is joint or divided spatiotemporal attention better?
表4(a)第3行:深层的MHRA可以看成是transformer block,但是同时进行时空注意力,而不是分别进行时间和空间注意力。
3.2.3 Does dynamic position embedding matter to UniFormer?
表4(a)第4行
3.2.4 How much does local MHRA help?
表4(a)第5678行
3.2.5 Is our UniFormer more transferable?
表4(c):joint 时空注意力对于迁移学习也更友好。
3.2.6 Empirical investigation on model parameters.
(1)local tube size
表4(b)选择5*5*5
(2)sampling method
表4(d)16*4表示采样16帧,frame stride为4. testing中的4*1表示 four-clip testing。密集采样在采样较少帧时效果更好,而当采样帧数增加时稀疏采样效果更好。
(3)testing strategy 图4
kinetics是一个场景相关的数据集,并且训练时采用密集采样方式,测试时使用multi-clip testing更好。
而SS 是一个时间相关的数据集,训练时采用稀疏采样方式,所以multi-crop testing更好。
multi-crop at test time:
提升网络性能经常用的数据扩充(Data augmentation)手段之一 。
在GoogleLeNet中描述的详细过程如下:将图片缩放到不同的4种尺寸(纵横比不变,GoogleLeNet使用的4种尺寸为:缩放后的最短边长度分别为:256,288,320和352)。对于得到的每个尺寸的图像,取左、中、右三个位置的正方形图像(边长就是最短边的长度),因此每个尺寸的图像得到3个正方形图像;然后再在每个正方形图像A的4个顶点和中心位置处裁剪出224*224的图像,此外再将这个正方形图像A缩放到224*224大小的图像,因此每个正方形图像得到6个224*224的图像;最后,再将所有得到的224*224的图像水平翻转。将这些图像分别输入神经网络进行分类,最后取平均,作为这个图像最终的分类结果。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第11张图片](http://img.e-com-net.com/image/info8/36f850f2f31d4fa1bb332d921bb5920f.jpg)
3.3 可视化
图5 展示最后一层中最受关注的区域
GGGG最关注关键目标,例如滑板和足球,比较所有层所有tokens的相似性。
LLLL注意力比较粗糙,不准确,没有全局视角。
LLGG可以捕捉到最综合的信息,非常精确。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第12张图片](http://img.e-com-net.com/image/info8/7f4c5069a6bd4531bb0288d7d585739f.jpg)
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第13张图片](http://img.e-com-net.com/image/info8/c7641b308506467db617a1de09a28ced.jpg)
图6 在kinetics-400上LLGG效果最好。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第14张图片](http://img.e-com-net.com/image/info8/c79227dc525a4892b1f05f232a8bf4d7.jpg)
图7 : gargling is often misjudged as brushing teeth, swing dancing is often misjudged as other types of dancing 因为这些类别通常基于空间细节来判断,LLLL效果好于GGGG。
playing guitar and strumming guitar are difficult to be classified, since their spatial contents are almost the same 这些类别需要长程依赖,因为GGGG效果更好。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第15张图片](http://img.e-com-net.com/image/info8/17de532d5eaa4148b74e55a2db4cb7eb.jpg)
附录:
表5:sampling method 16*4表示采样16帧,frame stride为4.
#frame 中的1*4表示 1-crop,4-clip testing。
以大步长采样时,相应的single-clip testing结果更好,因为稀疏采样可以cover更长的时间距离。
对于multi-clip testing,以步长4采样效果最好。
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第16张图片](http://img.e-com-net.com/image/info8/59337b4637b045958d166120645111fd.jpg)
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第17张图片](http://img.e-com-net.com/image/info8/c37c25c8182345cf877aa497503a3f50.jpg)
表7:不同参数量的模型对比
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第18张图片](http://img.e-com-net.com/image/info8/793bb7be0ae14f94ab2210431ddb0c78.jpg)
![[Video Transformer] UniFormer:Unified Transformer for Efficient Spatial-Temporal Representation Lear_第19张图片](http://img.e-com-net.com/image/info8/daf3b3ed250849f19ee2270d0829286b.jpg)