特斯拉是如何训练自动驾驶的?
来源:锦缎
如果机器人有大脑,会是什么样?
在科幻电影《机械姬》里,全球最大搜索引擎公司‘蓝皮书’CEO 纳森向观众展示了自己发明的机器人大脑,并留下这么一句话:‘人们认为搜索引擎是人们思考的事物,但其实那是人们思考的方式。’
该影片上映于 2015 年,被誉为人工智能爱好者必看的电影之一,拿下包括奥斯卡金像奖在内等多项国际电影大奖。但在众多奖项中,单项之冠是‘最佳女配角’,艾丽西卡·维坎德,也正是影片中智能机器人‘艾娃’的扮演者。
‘艾娃’是纳森给‘她’取的名字,为制造出能独立思考的人工智能,纳森利用自家搜索引擎‘蓝皮书’的算法来构建艾娃大脑的‘思维’,使之学会人类思考方式。
无独有偶,想让机器有人类思维,同样见之于特斯拉打造的自动驾驶 AI 上。2019 特斯拉自动驾驶日上,安德鲁·卡帕西(Andrej Karpathy,特斯拉 AI 总负责人)曾明确地向大众传达特斯拉自动驾驶是在模仿人类驾驶,因为现行的交通系统是基于人类视觉和认知系统来设计的。
由此,特斯拉开发出‘人工神经网络’,并利用大量有效的行车数据来训练它,在这一过程中不断完善并迭代视觉算法,终于在今年年中拿掉毫米波雷达,而随着超算 Dojo 浮出水面,长期被诟病只能算辅助驾驶的特斯拉,离真正的自动驾驶又近一步。
从学会开车,到比人类更懂开车、开得更好,当一名优秀的‘老司机’,是特斯拉自动驾驶持续优化的底层逻辑。
‘云端司机’的神经网络
纯视觉自动驾驶方案是特斯拉的独门绝技,但需建立对计算机视觉深度训练之上。
计算机视觉是一种研究机器如何‘看’的科学,当人类看到一张图片时,能清晰辨析图片里的事物,比如说美丽的风景照、或者一张小狗的照片,然而计算机看到的却是像素(pixel),像素是指由图像的小方格组成的,这些小方块都有一个明确的位置和相对应的色彩数值,计算机‘记住’的就是这堆数字字符,而不是具体事物。
如果想让计算机能像人类一样快速准确识别出图片里的事物,机器也有了人工大脑,来模拟人脑处理加工图像信息过程,分为输入层、隐藏层、输出层,里面有许多人工神经元,可视作人脑初级视觉皮层中的锥体细胞和中间神经元。
整个训练过程亦可类比小孩看图识物,通过一次次输入、对比、纠正,完成机器图像认知。通常在训练初期,人工神经网络识别结果的准确度非常低,输出结果和实际值相似度可能只有 10%;为了提高准确度,需要再将两者误差从输出层反向传播至输入层,并在反向传播中,修正神经网络隐藏层的参数值,经过上百万次的训练,误差逐渐将收敛,直至输入和输出端匹配度达到 99%。

上述过程是理解特斯拉自动驾驶 AI 的关键,只不过特斯拉开发的人工神经网络专注于驾驶领域,做一名专职云端司机。对它来说,最好的学习材料就是行车数据,大量、多样化、来自真实世界的驾驶训练数据集(training dataset)是自动驾驶 AI 能应对各种路况、交通问题的百宝书。
在影子模式的支持下,特斯拉全球百万车队每时每刻的行车数据都成为这位云端‘老司机’提升自身驾驶能力的养分。时至今日,特斯拉 Autopilot 已经能瞬间完成道路上各种动静目标、道路标识、交通符号的语义识别,反应速度甚至比人脑条件反射更快。
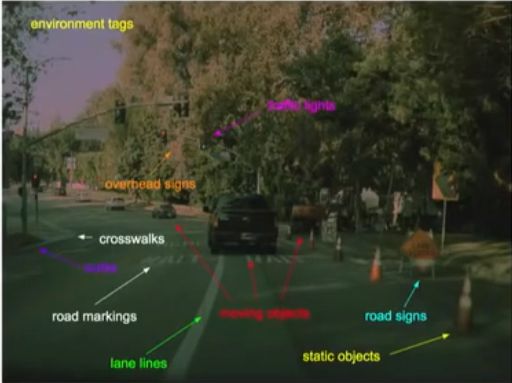
除了应对日常驾驶场景外,AI 司机还需要处理一些较为少见的长尾情况(Corner cases)。在 2020 年 Matroid 机器学习会议上,卡帕西以交通指标 STOP 为例,讲解 Autopilot 应对这些长尾情况的具体方法。
在日常驾驶过程中,车辆总会经过形形色色的 STOP 指标,最为正常的情况就是一个立在路旁或者路中、红底白字的 STOP 标识,但现实生活总会有些预料之外的情况发生,驾驶员偶尔会碰上一些奇奇怪怪、需要结合具体背景来理解意涵的指标,包括不限于以下:
无效 STOP 指标,比如被某人拿在手上,却无意义;下方附带文字说明的 STOP 指标,比如不限制右行;STOP 字母被树枝、建筑物遮挡的指标…这都是些出现频次不高却不胜枚举的情况。
遇到上述情况,人类驾驶员可以轻松识别出绝大部分情况下的‘STOP’,并很快作出行动反应。但对计算机来说,情况就变得复杂起来,毕竟它看到的不是具体的“STOP”,而是一堆无意义的数字代码,如果遇到现有训练数据集中没出现的情况,比如一些上述奇奇怪怪、较为少见的指标,自动驾驶神经网络就不能处理。

这部分少见的长尾数据通常无穷尽,但又必须在尽可能短的时间内学会应对,如果一切都让人工操作,无疑需要耗费巨大的时间成本和资源。尽管在 8 月 20 日 AI 大会上,卡帕西透露目前特斯拉标注团队规模已达千人级别,但在海量行车数据面前,千人还是显得杯水车薪,对此特斯拉内部开发了数据离线自动标注(Data Auto Labeling)以及自动训练框架‘数据引擎(Data Engine)’。
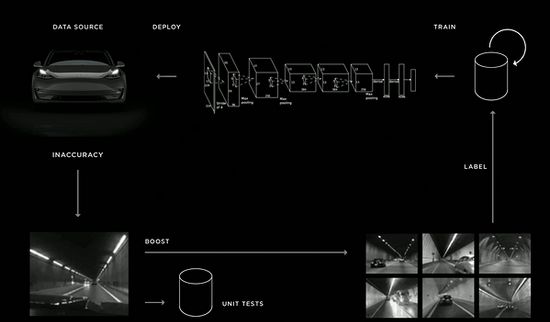
首先,特斯拉神经网络团队在对这些长尾情况有所了解后,会先编成一个样本数据集,并为此创造一个局部小型神经网络来学习、训练(与其他神经网络并行),通过 OTA 方式部署到全球英语地区特斯拉车辆上。
再利用车辆影子模式,但凡遇到实际驾驶情况和自动驾驶 AI 决策不一致的情况,这部分行车数据会自动上传至特斯拉后台数据引擎中,在被自动标注后,重新纳入已有的数据训练集中,继续训练原本的神经网络,直到新的数据被掌握。
就这样,在大量训练数据的喂养下,神经网络变得‘见多识广’、更加聪明,可以识别不同条件状况下的 STOP 标识,精确度逐渐从 40% 提升至 99%,完成单一任务学习。
不过,这仅仅是学习一个静态的信号,在汽车驾驶过程中会涌现无数静态和动态的信号,静态如路边大树、路障、电线杆等,动态的有行人、车辆等,而这些信号由摄像机捕捉到后交由神经网络训练、学习。目前特斯拉的自动驾驶神经网络已发展出九大主干神经(HydraNet)和 48 个神经网络,识别超过 1000 种目标。
然而,仅仅让自动驾驶 AI 学会开车还不够,还得让它开得像人类老司机一般驾轻就熟、安全又平稳。
摆脱拐杖,Autopilot 初长成
任何一位经验老道的司机,都能在不同路况下,轻易判断出前方车辆与我们的距离,从而为保障行车安全而留出一定车距。
但对传感器而言,要想判断物体远近必须要理解物体的深度,不然在他们眼中,距离我们 10 米和 5 米的两辆完全一样的车,就会被认为是一大一小的关系。
对此,有些车厂选择激光雷达路线来探测深度,而特斯拉则选择了纯视觉算法,模仿人类视觉来感知深度,不过特斯拉先是打造了毫米波雷达+视觉传感融合路线,直到今年 5 月,才正式官宣,拿掉毫米波雷达,上线纯视觉版本 Autopilot。
此事一出,社会各界一片哗然,很多人不能理解特斯拉为何要拿掉单价才 300 元、又能为行车安全增添保障的高性价比雷达。殊不知,在特斯拉早期多传感器融合路线中,毫米波雷达的存在就犹如小孩的学步车,只是帮助神经网络来学习训练深度标注(annotate)。
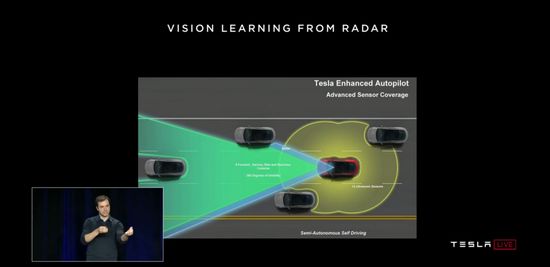
在 2019 年自动驾驶发布会上,卡帕西是这样介绍毫米波雷达的,他说:‘要想让神经网络学会预测深度,最好的方式还是通过深度标注的数据集进行训练,不过相对于人工标注深度,毫米波雷达反馈的深度数据精准度更高’,因此,引入毫米波雷达,实质是用以训练和提高神经网络对深度的预测。
值得一提的是,在他讲解时的背景幻灯片右下角上,清晰地注明了带有毫米波雷达的自动驾驶算法是‘Semi-Automonous Self Driving’,翻译过来是,半自动驾驶,明显彼时的特斯拉 Autopilot 只是个半成品。
直到特斯拉视觉算法在预测物体的深度、速度、加速度的表现,达到可替代毫米波雷达的水平,特斯拉的视觉算法才算真正独立。
在 2021 年 6 月 CVPR 大会上,卡帕西曾表示毫米波雷达收集数据中曾出现‘间歇性翻车’、甚至误判等情况。他举了三个具体例子,前方车辆急刹车、大桥下前车行驶速度以及对路边静止卡车的判断。
情况一:前方车辆出现急刹,毫米波雷达短时间内出现 6 次跟丢目标车的情况,跟丢状态下前车的位置、速度和加速度都归于零。
情况二:在行驶的汽车从大桥下通过时,雷达把一静一动的物体都当作静止物体;此时视觉传感却计算出行驶车辆的速度和位移,导致数据融合后的曲线传递出‘前车在减速并且刹车’的错误信息。
情况三:在高速路旁停着一辆白色大卡车,纯视觉算法在距目标车 180m 处就发现白色卡车,并作出预报,但融合算法直到 110m 处才作出反馈,足足延迟 5 秒。
上述案例里,纯视觉算法均输出稳定且大幅优于雷达+视觉融合算法,精准地跟踪到前车行驶状况并作出深度、速度、加速度等数据。
不仅如此,纯视觉算法还可以在雾、烟、尘等环境里保持对前方车辆的测速、测距工作,如此一来拿掉毫米波雷达也不奇怪了。根据特斯拉 AI Day 上最新发布的信息,目前特斯拉每周能够获得一万个人们恶劣环境下驾车的短视频,包括大雨、大雪、大雾、黑夜、强光等等情况,神经网络通过学习训练这些已经标注好的材料,实现在没有毫米波雷达的情况下,也可以精准感知前方车辆距离。

可以说,特斯拉宣布拿掉毫米波雷达的底气,是对自己纯视觉算法成熟的自信,并且在无监督自学的加持下,特斯拉纯视觉算法迭代和完善明显提速。
今年 7 月 10 日,特斯拉纯视觉版本的 FSD 正式在美开启内测,2000 名受邀车主通过 OTA 方式升级到 FSD Beta V9.0 版本,他们大多是特斯拉的粉丝兼中小型 KOL,Youtube 博主 Chunk Cook(以下简称 CC)就是其中之一,他还略懂工程学和航天学专业知识。
系统更新一结束,CC 开启新版 FSD 道路测试,并把测试视频上传至油管。视频中他来到一个车辆较多、车速较快的 T 路口进行转弯测试,结果显示,7 次中只有 1 次,FSD 顺利完成自动驾驶,其余都需要人工接管方向盘来完成驾驶。
但很快,随着 7 月底 FSD 推送新版本 V9.1,CC 发现升级后的 FSD 表现出乎他的意料。他又在相同道路进行了七次自动驾驶测试,结果显示,7 次中 4 次都较为顺利完成自动驾驶,但在转弯速度上有些‘磨蹭’,没有展现老司机应有的果断,但在综合得分上,新版本 Autopilot 优于旧版本。
8 月 16 日,特斯拉 FSD 又升级至新版本 V9.2,CC 同样抢先测试并上传视频,还是一个路段,不过测试时间改为夜间,他公开表示,此次最明显的改进是 Autopilot 的加速表现,在转弯时能像人类驾驶员一样果断加速。
前后一个月的时间,纯视觉 Autopilot 在同一条道路的表现进步迅速,身后正是人工神经网络强悍自学能力的体现。马斯克表示,FSD beta V9.3、9.4 都已在筹备中,会根据车主使用情况不断进行细节优化,改善用户体验,并预备在 V10 版本做出现重大的变化。
Dojo 上马,模拟极限
需要注意的是,大家惊艳特斯拉纯视觉 Autopilot 各种老司机操作时,也不能忘记这些路测大部分发生在北美地区,而在非英语地区,比如人口稠密的亚洲地区,其城市道路交通复杂度与地广人稀的北美迥异,而如何让神经网络学会应对各种路况交通,更值得思考。
收集实地数据是方法之一,但前提是你有大量车队在该地区驾驶,另一种解决方法则是对自动驾驶进行仿真测试。仿真,简单讲就是利用现实数据,将真实世界的实时动态景象,在计算机系统实现重新构建和重现。
除了能模拟不同城市的交通路况,而且仿真测试还能模拟一些极限场景,比如各种突发交通事件或者极为罕见的交通路况。在 AI DAY 上,特斯拉工程师举了具体例子,包括有行人在高速路上奔跑、行人数量庞大、或者非常狭窄的驾驶道路。
这些案例往往非常极端,在日常驾驶场景中出现的概率也微乎其微,但正因为此,通过仿真来训练神经网络才有真正价值,而只有通过训练,神经网络才能学会正确应对。
为了能真正起到训练作用,这些仿真测试必须充分还原现实场景,包括道路上各种行人、车辆、绿化林、路障、信号灯等等,几乎包含你在路上见到的所有交通要素。目前特斯拉已创建了 3.71 亿张车内网络训练的图像,以及 4.8 亿个标签,并且数据规模还在快速扩张中。

要知道,仿真测试可达到的逼真程度,与计算机可提供的数据处理能力成正比。特斯拉 AI 的仿真越强,对硬件算力、读写速度的要求越高。
马斯克曾在 2020WAIC 大会上表示,当下计算机视觉已经超越人类专家水平,但要保证计算机视觉实现的关键是算力的大小,为此特斯拉则准备好了顶级超算 Dojo,保证一切运算都能高效、准确完成。
在 AI day 上,超算 Dojo 揭开了庐山真面目,内置了 3000 颗 Dojo 1 芯片,并组装成峰值算力达到 1.1EFLOPS 的 ExaPOD,超越目前世界上最快的超算日本富岳,就成了全球第一。在发布会后,马斯克在推特上回复网友提问时表示,ExaPOD 的运算能力足以模拟人脑。
现阶段,Dojo 这台性能猛兽专注于训练特斯拉自动驾驶神经网络,有了它,神经网络的学习潜力一下子变得深不可测,而至此,特斯拉也集齐自动驾驶三要素,数据、算法、算力,为推进 L5 级别自动驾驶做好软硬件准备。
不过要想快进至自动驾驶终局,特斯拉还有很长的路要走,包括来自法律和道德层面的考验。