论文翻译:2020_Residual Acoustic Echo Suppression Based On Efficient Multi-Task Convolutional Neural Netw
博客作者:凌逆战(转载请注名出处)
论文地址:基于高效多任务卷积神经网络的残余声回波抑制
摘要
回声会降低语音通信系统的用户体验,因此需要完全抑制。提出了一种利用卷积神经网络实现实时残余声回波抑制的方法。在多任务学习的背景下,采用双语音检测器作为辅助任务来提高RAES的性能。该训练准则基于一种新的损失函数,我们称之为抑制损失,以平衡残余回波的抑制和nearend信号的失真。实验结果表明,该方法能有效抑制不同情况下的残余回波。
关键词:residual acoustic echo suppression, convolutional neural network, multi-task learning, suppression loss
1 引言
在语音通信系统中,当麦克风与扬声器处于一个封闭的空间中时,需要捕获麦克风与扬声器之间耦合产生的回声信号,需要声学回声消除(AEC)。 传统的AEC算法由两部分组成:自适应线性滤波器(AF)[1]和非线性回波处理器(NLP)[2]。 AEC中存在许多挑战,例如扬声器引起的非线性特性,而且很难找到AF输出与远端信号之间的非线性关系。 换句话说,在AEC系统中,为了完全去除残留的回声,NLP极有可能对近端信号造成实质性的破坏。
近年来,机器学习被引入到声学回声消除和抑制中。基于远端信号及其非线性变换信号[3],采用两层隐层的人工神经网络对残差回声进行估计。用远端信号和AF输出信号训练深度神经网络(DNN)可以预测更准确的掩码[4,5]。然而,由于相位信息的缺乏,在向神经网络输入幅度谱并估计输出幅度谱掩码时,很难在去除全部声回波[6]的同时保留近端信号。然而,由于增加了更多的输入特征,这样的相位谱使得模型过于复杂,无法应用于大多数个人终端[7,8]。在最近的一项研究中,相位敏感权值被用来利用AF输出和近端信号[9]之间的相位关系来修改掩模。
在本文中,我们提出了一种新的残余声回声抑制(RAES)方法,该方法采用一种高效的多任务卷积神经网络(CNN),将远端参考信号和AF输出信号作为输入,相敏掩模(PSM)作为目标。采用一种新的抑制损失来平衡残差回声抑制和近端信号保留之间的平衡。即使在传统的AEC中,精确的双语检测器(DTD)也是必不可少的,本文还将双语状态的估计作为提高掩模预测精度的辅助任务。实验结果表明,该方法在模拟和真实声环境中都能有效抑制残余回声,显著降低近端信号的失真。
本文的其余部分组织如下。第二节介绍了传统的AEC系统。本文第三节介绍了所提出的方法,第四节给出了比较的实验结果。最后,第五部分是全文的总结。
2 AEC框架
在AEC框架中,如图1所示,麦克风接收到的信号$d(n)$由近端信号$s(n)$和回声$y(n)$组成:
$$公式1:d(n)=s(n)+y(n)$$
AEC的目的是去除回波信号,同时保持近端信号的$\hat{s}(n)$。
回声$y(n)$包括两部分:线性回声(包括直接远端信号及其反射信号)以及扬声器引起的非线性回声。AF模块自适应估计线性回波$\hat{y}(n)$,并将其与麦克风信号$d(n)$相减,得到输出信号$e(n)$。传统的NLP从$e(n)$和$d(n)$计算抑制增益,进一步抑制残留回波。然而,在双端通话中使用这种方法时,近端信号极易受到严重的破坏。
3 提出的方法
3.1 特征提取
AF模块用于消除麦克风信号中的一部分线性回声。 有很多方法可以实现线性AF算法。 从理论上讲,所提出的RAES可以与任何标准AF算法一起使用,并且本文中使用了子带归一化最小均方(NLMS)算法。
输入特征包括如上所述的AF输出误差信号$e(n)$和远端参考信号$u(n)$的对数谱。 我们使用短时间傅里叶变换(STFT)将$e(n)$和$u(n)$转换到频域,采用大小为K的平方根汉宁窗,因此,频点的实际数量为K/2,丢弃直流bin。 我们将M帧串联作为输入特征,以提供更多的时间参考信息。 串联的另一个优点是,它可以推动网络学习回声和远端信号之间的延迟。
3.2 网络框架
本文网络的主干是受MobileNetV2的启发,其中大部分的全卷积操作被depthwise和pointwise卷积代替,以降低计算代价[10]。总体网络架构如图2所示,其中Conv()和Residual BottleNeck()()中的前三个参数分别为output channel、kernel size和stride size,如果没有指定,默认的stride大小为1。FC是指具有输入和输出尺寸的全连接层。Residual BottleNeck()的详细架构如图2 (a)所示,其中residual connection融合了high-dimension和low-dimension特征。
值得一提的是,在双向通话(double talk)中进行mask(掩膜)预测是一项具有挑战性的任务。通过4个Residual BottleNeck blocks提取特征后,我们在右分支中使用DTD预测任务,以减轻左掩模预测分支的负担。因此,多任务学习可以使网络更加关注双向通话掩码的预测,如果DTD任务检测到single talk period(单说话周期),则可以很轻松地将掩码(mask)设置为1或0。
a、Inverted Residual BottleNeck($C_{out}$, kernel, stride)
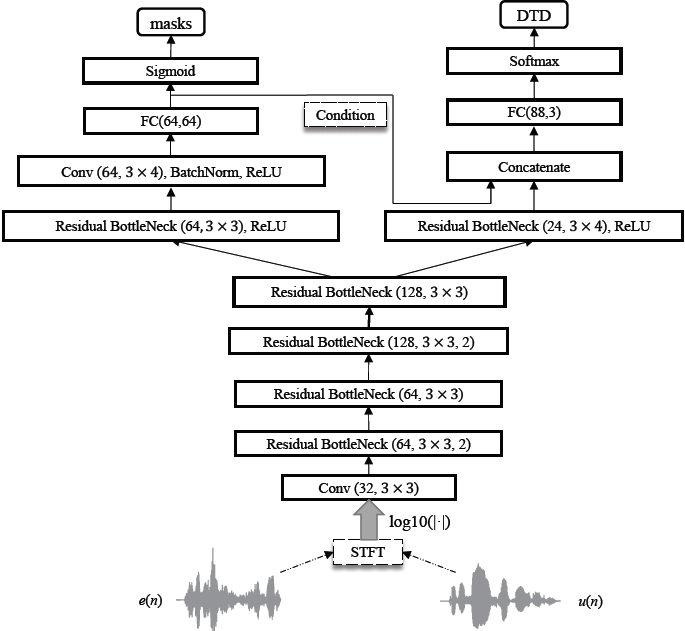
(b)总框架
图2 提出K = 128时的网络架构
3.2 训练targets与损失
理想振幅掩模(Ideal amplitude mask,IAM)在不考虑相位信息的情况下,常被用作语音增强和残差回波抑制的训练目标。在本文中,我们使用相位敏感膜(phase-sensitive mask,PSM)[11],其表达如下
$$公式2:g^{\mathrm{PSM}}(l, k)=\frac{|S(l, k)|}{|E(l, k)|} \cos (\theta)$$
其中$\theta=\theta^{S(l, k)}-\theta^{E(l, k)} \cdot S(l, k)$和$E(l,k)$表示第$l$帧和第$k$频率bin的near end(近端)和AF输出信号,PSM在网络中被截断在0和1之间。然后通过以下公式计算所提出的RAES $\hat{S}(l,k)$在频点$(l,k)$中的频域输出
$$公式3:\hat{S}(l, k)=g^{\mathrm{PSM}}(l, k) E(l, k)$$
最小平方误差(MSE)在训练过程中用作损失函数。为了完全消除回声,在某种程度上使近端信号失真是不可避免的。只要网络的估计不够完美,RAES要么会使近端信号失真,要么会保留一些残留回波,或者更糟,两者都有。一方面,从本质上讲,AEC的主要目的是消除麦克风信号中的所有回声,同时尽可能保留近端信号。因此,与保持近端信号质量相比,抑制回声的要求更高。另一方面,MSE损失是对称的度量,因为相同数量的正负偏差将被视为完全相同的损失。因此,直接使用MSE无法控制抑制回声和保留近端信号之间的折衷。本文的解决方案是应用参数Leaky ReLU函数来计算target与估计掩膜$\Delta(l, k)$在$(l,k)$频率bin上的加权均方距离,其抑制比为$\alpha$
$$公式4:\Delta(l)=\left\{\begin{array}{ll}
\frac{1}{K} \sum_{k=0}^{K-1}\left[g_{t}(l, k)-g_{e}(l, k)\right]^{2}, & \text { if } g_{t}(l, k)
\end{array}\right.$$
其中$g_t(l,k)$和$g_e(l,k)$分别是目标和估计在频点$(l,k)$的相位敏感掩模,我们称其为抑制损失。作为参数的$k$个频点中的抑制比$\alpha_k$被设置在0和1之间,k越小,抑制将越严重。可以通过设置不同的$k$值在每个频点中调整抑制程度。 为简化起见,我们在所有频点中都设置了相同的值。
根据以下规则获得第$l$帧中的DTD状态:
$$公式5:\operatorname{DTD}(l)=\left\{\begin{array}{ll}
0, & \text { if } \max (|y(l, k)|)<0.001 \& \max (|s(l, k)|)>0.001 \\
1, & \text { if } \max (|s(l, k)|)<0.001 \& \max (|y(l, k)|)>0.001 \\
2, & \text { otherwise }
\end{array}\right.$$
其中DTD状态0、1、2分别对应于信号近端通话、单远端通话和双端通话。由于数据集单方通话和双方通话之间的不平衡,将focusing参数$Y^*=2$的focal损失[12]作为DTD训练任务的损失函数,我们将[13]中的两种损失与两个权重结合起来,通过网络更新两个权重。