Swin-Transformer论文解析
目录
- Swin-Transformer
-
- Attention机制的发展历程
- Attention中Q、K、V的概念
- Attention的计算过程
- swin-transformer 与VIT的区别
- swin-transformer整体架构
- Patch Merging
- Swin-transformer Block
- Swin-transformer中的掩码机制
- 自注意力的复杂度计算
- Swin-Transformer的详细架构
- 效果比较
-
- ImageNet数据集
- COCO数据集
- 语义分割数据集ADE20K
Swin-Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang Stephen Lin, Baining Guo
Computer Vision and Pattern Recognition (2021)
Microsoft Research Asia
https://github.com/microsoft/Swin-Transformer
Swin: Shifted Windows
swin-transformer是什么?
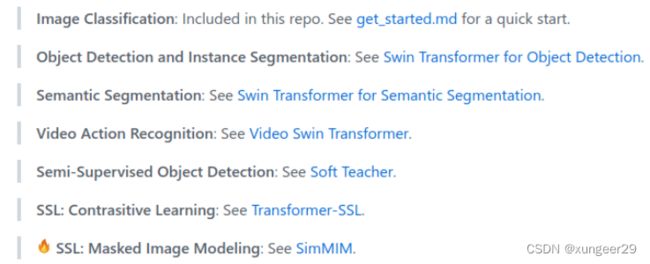
swin-transformer是可以用于计算机视觉任务的通用主干网络,可以用于图像分类、图像分割、目标检测等一系列视觉下游任务。
下面是swin-transformer在各个领域的一些应用
解决了什么问题?
- 与NLP领域不同,视觉领域同类的物体,在不同图像上/同一图像上的尺度会相差巨大;
- 相较于文本,图像的尺寸过大,计算复杂度较高;
优点是什么?
- 提出了一种层级式网络结构,解决视觉图像的多尺度问题;
- 提出Shifted Windows,极大降低了transformer的计算复杂度;
- 可以广泛应用到所有计算机视觉领域;
结论是什么?
Transformer完全可以在各个领域取代CNN
效果怎么样?
在ImageNet上并非SOTA,仅与EfficientNet的性能差不多
swin-transformer的优点不是在于分类,在分类上的提升不是太多,而在检测、分割等下游任务中,有巨大的提升.

在目标检测数据集COCO上,比当时的SOTA提高了2.7点左右的mAP
下面是paper with code上的最新截图,几乎全是Swin-Transformer的变体

在语义分割数据集ADE20K上,比当时的SOTA提高了3.2点左右的mAP
下面是paper with code上的最新截图,也几乎全是Swin-Transformer的变体

Attention机制的发展历程
-
Bengio团队于2014年提出Attention机制,用于机器翻译中,使模型自动寻找原文本中与预测目标单词相关的内容
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014. -
谷歌团队于2017年提出基于注意力机制的Transformer架构代替RNN
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]//Advances in Neural Information Processing Systems. 2017: 5998-6008. -
2018年Momenta提出SENet,开始将Attention机制与CNN结合,用于图像领域
Jie Hu et al. Squeeze-and-Excitation Networks. Computer vision and Pattern recognition (2018) -
谷歌大脑于2020年提出第一篇应用于图像领域纯Attention网络ViT
Alexey Dosovitskiy et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” arXiv: Computer Vision and Pattern Recognition (2020)
Attention中Q、K、V的概念
以商品搜索为例
Query:搜索引擎上输入的内容,例如商品名称
Key:搜索引擎根据Query为你匹配Key,例如商品的种类,颜色,描述
Value:搜索引擎根据Query和Key的相似度得到匹配的内容
Attention的计算过程
参考链接:https://jalammar.github.io/illustrated-transformer
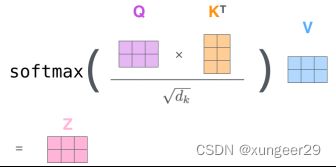
- 将输入单词转化成嵌入向量;
- 嵌入向量通过全连接层,得到q、k、v三个向量;
- 为每个向量计算一个score:score=k*v attention
- 为保持梯度稳定,score除以 (d_k为q, k, v的向量维度)
- 对score施以softmax激活函数;
softmax分数决定每个单词对编码当下位置(“Thinking”)的贡献 - softmax(score)点乘v,得到加权v向量
- v相加之后得到最终的输出结果z

swin-transformer 与VIT的区别

vit:
- 使用低分辨率的输入
计算复杂度与图像大小是二次函数关系 - 全局自注意力计算
- 特征图大小固定
将图像划分成16x16的patch,每一层的transformer得到的特征图都是16倍下采样的大小, 没有多尺寸特征,感受野相同;
可以通过全局的自注意力机制达到全局的建模能力,但是对多尺寸特征的提取能力弱,不利于目标检测、分割等下游任务,检测分割时只能从bottleneck上提取特征,无法从主干提取浅层特征;
自注意力始终在整图上进行,计算复杂度是图像尺寸的平方,无法使用大分辨率的图像;
swin-transformer:
- 使用任意尺度的输入
计算复杂度与图像大小是线性关系 - 在小窗口内计算自注意力
- 特征图大小递减
在小窗口内计算自注意力,而不是在整图上计算自注意力,当窗口大小固定,自注意力的复杂度就固定,整图的计算复杂度与图像尺度呈线性增长关系,利用了图像的局部性的先验知识;
局部性:同一个物体不不同部位,或语义相近的不同物体,大概率会出现在相邻的地方,所以对视觉任务来说,在小窗口内计算自注意力是合理的,在全局计算会造成计算的浪费;
swin-transformer整体架构
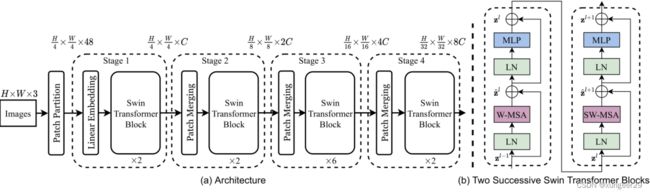
Stage1
- Patch Partition: 图像分块 patch size=4x4 443=48 2242243->565648
- Linear Embeding: 将图像patch映射成目标维度C 565648->565696
- swin-transformer block: 自注意力计算
Stage2
- patch merging: Pixel Shuffle的逆操作,将patch块合并,特征图大小减半,通道数翻倍,增大感受野,形成特征金字塔
- swin-transformer block: 自注意力计算
Stage3与Stage4重复Stage2,仅是swin-transformer block数量不同
Patch Merging

Pixel Shuffle的逆操作
将patch块合并,特征图大小减半,通道数翻倍
起到类似pooling层的作用,增大感受野,形成特征金字塔
有利于检测、分割等下游视觉任务
Swin-transformer Block

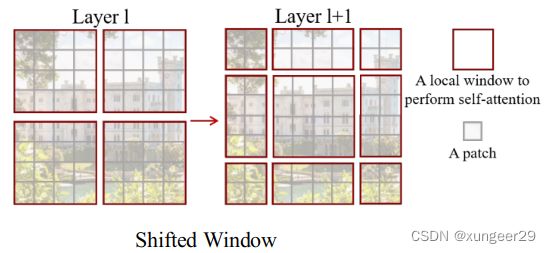
Swin Transformer结构中,
- 在网络第l层,采用规则的窗口划分图像,并在每个窗口内计算自注意力
- 在第l+1层中,窗口分区移位,产生新窗口
新窗口中的自注意力计算跨越了第l层中窗口的边界,提供了它们之间的联系,增强全局建模能力
Swin-transformer中的掩码机制
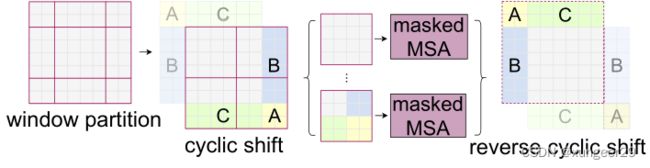
shifted-window存在的问题:
- shift之后窗口的数量增加
- 新增窗口大小不一致,无法进行批运算
常规解决方案:
将小窗口padding后进行批运算,但是会造成计算资源的巨大浪费
Swin-transformer解决方案:掩码机制
- 按照新窗口的划分切割特征图
- 特征图循环移位拼接,新窗口的大小相同(AB、AC等之间语义不同,不应该进行自注意力)
- 掩码机制计算:先将特征图拉长,在与转置之后的向量相乘,得到自注意力矩阵,mask矩阵内自注意力部分为赋值为0,非自注意力部分赋值为很大的负数,mask矩阵与自注意力矩阵相加
- 将计算完自注意力的特征图逆循环位移,还原原特征图位置

优点:没有增加额外的窗口数量,只需要一次计算就可以得到自注意力矩阵,提高了shifted-window的批计算效率;
自注意力的复杂度计算
普通多头自注意力:
![]()
基于窗口的多头自注意力:
![]()
计算复杂度由图像大小的二次函数变为了图像大小的一次函数
Swin-Transformer的详细架构
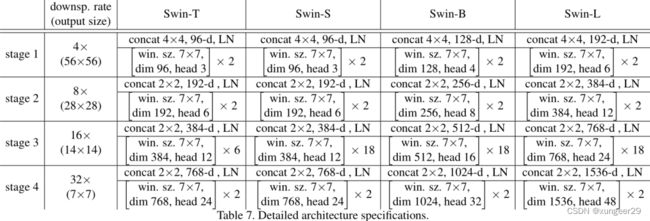
不同参数量的Swin-Transformer仅是stage3的swin-block
效果比较
ImageNet数据集
Swin相较于ViT有较大的提升,单仅与EffNet相差不多
提升数据集规模,ViT与Swin都有较大提升
Swin-transformer在分类上提升不多,但在检测与分割等下游任务上有巨大提升。

COCO数据集
不同算法框架下,Swin与CNN的比较

结论:Swin可以当作通用的骨干网络使用
相同同算法框架下,Swin与不同骨干网络的比较
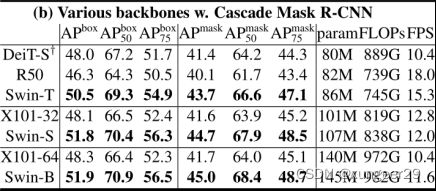
结论:相似参数量下,Swin的性能更好
极致性能的比较(各种方法都用上)
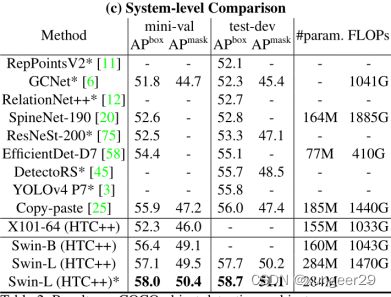
结论:Swin-L的性能最优
语义分割数据集ADE20K
各种方法都用上后的极致性能的比较
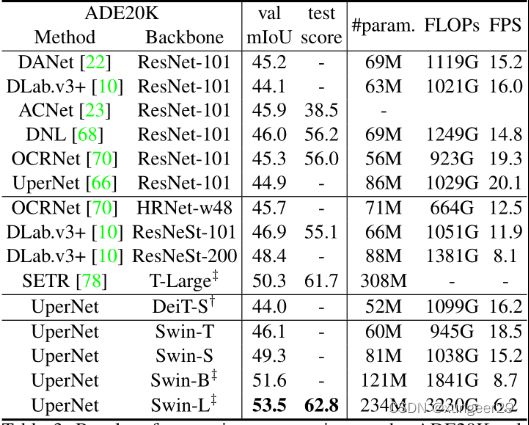
结论:Swin-L的性能最优(UperNet框架)