Swin-Transformer 详解
Swin-Transformer综合指南(用动画深入解释Swin-Transformer)
1. 介绍
Swin Transformer (Liu et al., 2021) 是一种基于Transformer的深度学习模型,在视觉任务中具有两眼的表现。与之前的 Vision Transformer (ViT) (Dosovitskiy et al., 2020) 不同,Swin Transformer 高效且精准,由于这些可人的特性,Swin Transformers 被用作当今许多视觉模型架构的主干。
尽管它已经被广泛采用,但我发现在这个主题中缺乏详细解释的文章。 因此,本文旨在使用插图和动画为 Swin Transformers 提供全面的指南,以帮助您更好地理解这些概念。
让我们开始吧!
2. Swin Transformer: ViT的升级版
近年来,Transformers (Vaswani et al., 2017) 已成为自然语言处理 (NLP) 任务中占主导地位的深度学习架构。 Transformer 在 NLP 中的巨大成功鼓舞着研究人员想方设法改进 Transformer,以使其适应计算机视觉任务。
2020 年,Vision Transformer (ViT) 获得了 AI 社区的广泛关注,它以纯粹的Transformer 架构而闻名,并在视觉任务中取得了可喜的成果。 尽管前景广阔,但 ViT 仍存在一些缺点:其中最为重要的是ViT 难以处理高分辨率图像,因为其计算复杂度为图像大小的平方; 此外,ViT 中的固定比例标记不适用于视觉元素具有可变比例的视觉任务。
研究人员追随着ViT的思想进行了一系列的研究,大多数的研究对标准的Transformer 架构进行了增强,以解决上文提到的缺点。 2021 年,微软研究人员发表了 Swin Transformer(Liu et al.,2021 ),可以说是继原始 ViT 之后最激动人心的研究之一。
3. Swin Transformer 的架构和关键概念
Swin Transformer 引入了两个关键的概念来解决原始 ViT 所面临的问题——分层特征图(hierarchical feature maps)和转移窗口注意力(shifted window attention)。 事实上,Swin Transformer 的名字来源于“Shifted window Transformer”。 Swin Transformer的整体架构如下所示。
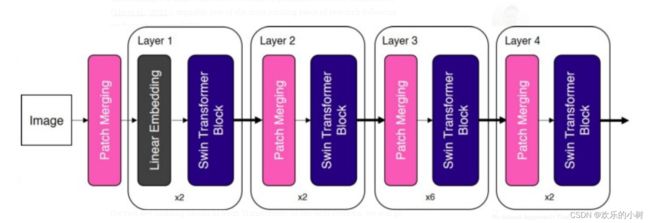 整体 Swin Transformer 架构。 改编自 Liu et al., 2021。 请注意,在论文中,“patch partition”被用作第一个块。 为简单起见,我使用“patch merging”作为此图中的第一个块,因为它们的操作相似。
整体 Swin Transformer 架构。 改编自 Liu et al., 2021。 请注意,在论文中,“patch partition”被用作第一个块。 为简单起见,我使用“patch merging”作为此图中的第一个块,因为它们的操作相似。
如您所见,“patch merging Block” 和 “Swin Transformer Block” 是 Swin Transformer 中的两个关键构建块。 在接下来的部分中,我们将详细介绍这两个块。
4. Hierarchical Feature Maps(分层特征图)
与 ViT 的第一个重大差别是 Swin Transformer 构建了“Hierarchical Feature Maps”。 让我们将其分为两部分,以更好地理解这意味着什么。
首先,“Feature Maps”只是从每个连续层生成的中间张量。至于'Hierarchical',在原文中,它指的是从一层到下一层合并出来的特征图(更多细节在下一节中),并且它有效地减少了特征图的空间维度(即下采样)。
 Swin Transformer 中的分层特征图。 当前特征图由上一层特征图合并产生并被下采样,创建具有层次结构的特征图。 请注意,为简单起见,省略了特征图的深度。
Swin Transformer 中的分层特征图。 当前特征图由上一层特征图合并产生并被下采样,创建具有层次结构的特征图。 请注意,为简单起见,省略了特征图的深度。
您可能会注意到,这些分层特征图的空间分辨率与 ResNet 中相同,这是作者有意为之,以便 Swin Transformers 可以方便地替换现有ResNet 视觉任务方法中的骨干网络。
更重要的是,这些分层特征图允许 Swin Transformer 应用于需要密集预测的领域,例如语义分割。 相比之下,贯穿于ViT 结构中在特征图即单一,同时分辨率低。
5. Patch Merging
在上一节中,我们已经了解到分层特征图是通过逐步合并和下采样来构建的。 在 ResNet 等卷积神经网络中,特征图的下采样是使用卷积操作完成的。 那么,我们如何在不使用卷积的情况下,使用纯粹的Transformer 网络中对特征图进行下采样呢?
Swin Transformer 中使用的无卷积下采样技术称为 Patch Merging。 在原文中,“Patch ”是指特征图中的最小单位。 换句话说,在一个 14x14 的特征图中,有 14x14=196 个补丁。
要将特征图下采样 n 倍,Patch Merging 将每组 n x n 个相邻补丁的特征连接起来。我知道这可能很难理解,所以我创建了一个动图来更好地说明这一点。
正如上面的动画所演示的那样, Patch Merging 将每个 n x n 的相邻补丁分组并在深度上将它们连接起来。 这有效地将输入向下采样 n 倍,将输入从 H x W x C 的形状转换为 (H/n) x (W/n) x (n^2*C),其中 H、W 和 C 分别指高度、宽度和通道深度。
6. Swin Transformer Block
Swin Transformer 使用 Window MSA (W-MSA) 和 Shifted Window MSA (SW-MSA) 代替了ViT所使用的多头自注意模块(multi-head self-attention (MSA) )。Swin Transformer 模块如下图所示。
 Swin Transformer 模块,带有 2 个子单元。 第一个子单元应用W-MSA,第二个子单元应用SW-MSA。改编自 Liu et al., 2021。
Swin Transformer 模块,带有 2 个子单元。 第一个子单元应用W-MSA,第二个子单元应用SW-MSA。改编自 Liu et al., 2021。
Swin Transformer 模块由两个子单元组成。每个子单元由一个归一化层、一个注意力模块,后接另一个归一化层和一个 MLP 层组成。 第一个子单元使用 Window MSA (W-MSA) 模块,而第二个子单元使用 Shifted Window MSA (SW-MSA) 模块。
7. Window-based Self-Attention
ViT 中使用的标准 MSA 执行全局自注意,Patch 之间的权重关系是针对所有其他 Patch 计算的。 这导致Patch 数量平方复杂度,使其不适合高分辨率图像。
为了解决这个问题,Swin Transformer 使用了基于 Window 的 MSA 方法。 一个 Window 只是一个 patch 的集合,注意力计算只在每个 Window 内进行。 例如,下图使用 2 x 2 块的 Window 大小,基于 Window 的 MSA 仅在每个窗口内计算注意力。
由于window大小在整个网络中是固定的,基于window的 MSA 的复杂度与patch的数量(即图像的大小)呈线性关系,这比标准的MSA 平方复杂度有了很大的改进。
8. Shifted Window Self-Attention
然而,基于窗口的 MSA 有一个明显缺点,将自注意力限制在每个窗口上会限制网络模型的能力。 为了解决这个问题,Swin Transformer 在 W-MSA 模块之后使用了 Shifted Window MSA (SW-MSA) 模块。
为了引入跨窗口连接,Shifted Window MSA 将窗口向右下角移动 M/2 倍,其中 M 是窗口大小(上面动画中的步骤 1)。
然而,这种Shifted操作会导致不属于任何窗口的“孤立” patch,以及patch不完整的窗口。Swin Transformer 应用了“循环移位 (Cyclic Shift) ”技术(上面动画中的第 2 步),它将“孤立”patch移动到带有不完整 patch 的窗口中。请注意,在这种Shifted操作之后,一个窗口可能由原始特征图中不相邻的patch组成,因此在计算时使用了 Mask,以限制对相邻 patch 的自注意。
这种移位窗口方法在窗口之间引入了重要的交叉连接,事实证明,它可以提高网络的性能。
 有无 shifted window MSA approach对比
有无 shifted window MSA approach对比
9. 结论
Swin Transformer 可能是继最初的 Vision Transformer 之后最令人兴奋的一项研究。 使用分层特征图和移动窗口 MSA,Swin Transformer 解决了困扰原始 ViT 的问题。 如今,Swin Transformer 通常用作广泛的视觉任务中的主干架构,包括图像分类和对象检测。
本文翻译自:A Comprehensive Guide to Microsoft’s Swin Transformer | by James Loy | May, 2022 | Towards Data Science https://towardsdatascience.com/a-comprehensive-guide-to-swin-transformer-64965f89d14c
https://towardsdatascience.com/a-comprehensive-guide-to-swin-transformer-64965f89d14c