(五十一)论文阅读 | 轻量级网络之GhostNet
简介

通过实验发现,普通卷积会产生大量冗余的特征图,本文提出一种 Ghost 模块在大幅减小模型计算量的同时保持模型精度。
论文地址 代码地址
0. Abstract
卷积神经网络中存在着大量冗余信息,论文提出的 Ghost 模块通过简单运算即可在一组固定特征图上产生更多的特征图。该模块即插即用,如本文通过堆叠 Ghost 模块得到的 GhostNet。实验结果表明,GhostNet 可以取得与 MobileNetV3 相当的结果。
1. Introduction
深度卷积神经网络通常具有较大的参数量和计算量,因此当前出现了许多针对移动设备的神经网络设计。如网络剪枝、低比特量化、知识蒸馏等,这些方法都是以预训练模型为基础。另一方面,直接设计轻量化的网络结构,如 MobileNet 和 ShuffleNet。
作者指出,预训练模型通常以包含冗余的特征信息来保证对输入图像的充分理解,如下图以 ResNet50 为例说明:
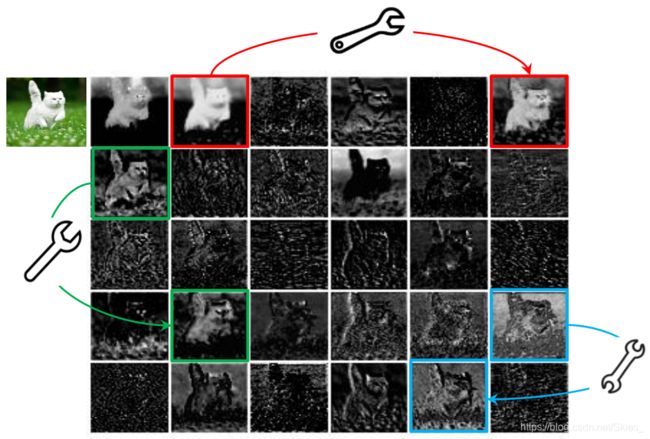
作者将箭头两端的特征图互称为 Ghost 特征图,作者认为这些特征图是神经网络成功的关键。这类,并非是要想办法直接去掉这些冗余的特征图,而是通过其他廉价的操作生成这些特征图。因此,本文提出 Ghost 模块用以解决这一问题。其大致思路是:首先通过普通卷积产生一组特征图,然后通过简单的线性变换产生更多的特征图。这样,该模块在不改变输入输出特征图的前提下,大幅减少模型的参数量和计算量。
2. Related Work
2.1 Model Compression
给定一个神经网络,模型压缩旨在降低其计算量和体积。如对神经元间剪枝以去掉非必要连接,对特征图的通道剪枝以移除非必要通道,模型量化以一组离散值表征神经网络,二值化使用单个比特的二元操作加速模型,张量分解根据网络权重的冗余性和低秩性减少参数,知识蒸馏基于大型网络训练小型网络。这类方法通常基于预训练模型实现。
2.2 Compact Model Design
随着在嵌入式设备上部署神经网络的需要,近年来出现许多轻量模型架构,主要是 MobileNet 系列和 ShuffleNet 系列。
3. Approach
3.1 Ghost Module for More Features
深度卷积神经网络通常包含大量卷积运算,从而产生大量的计算。尽管 MobileNet 和 ShuffleNet 使用深度卷积或通道混洗简化模型,但 1×1 卷积仍占据相当大的计算比。基于对上图的观察,作者提出使用较少的卷积核生成特征图,然后通过简单运算生成更多特征图。给定输入数据为 X ∈ R c × h × w X\in\mathbb R^{c\times h\times w} X∈Rc×h×w,普通卷积可表示为:
Y = X ∗ f + b (1) Y=X*f+b\tag{1} Y=X∗f+b(1)
其中, Y ∈ R h ′ × w ′ × n Y\in\mathbb R^{h'\times w'\times n} Y∈Rh′×w′×n 和 f ∈ R c × k × k × n f\in\mathbb R^{c\times k\times k\times n} f∈Rc×k×k×n 表示输出特征图和卷积核。该操作的计算量为:
n ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k (2) n\cdot h'\cdot w'\cdot c\cdot k\cdot k\tag{2} n⋅h′⋅w′⋅c⋅k⋅k(2)
由于输入通道数 c c c 和输出通道数 n n n 值较大,造成上述普通卷积较大的计算量。同时根据上图的现像,作者指出没有必要通过卷积生成那些冗余的特征图。作者假定最终的输出特征图是由少数特征图通过简单变换生成,而这些少数特征图由普通卷积产生。具体地, m m m 个特征图 Y ′ ∈ R h ′ × w ′ × m Y'\in\mathbb R^{h'\times w'\times m} Y′∈Rh′×w′×m 基于普通卷积得到: Y ′ = X ∗ f ′ (3) Y'=X*f'\tag{3} Y′=X∗f′(3)
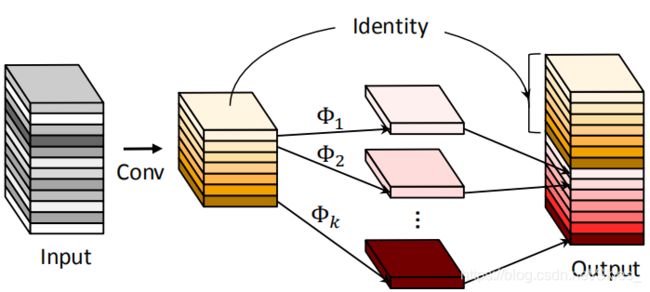
其中, f ∈ R c × k × k × m f\in\mathbb R^{c\times k\times k\times m} f∈Rc×k×k×m 且 m ≤ n m\leq n m≤n ,即卷积输出通道数小于输入。为了获得通道数为 n n n 的特征图,作者提出对上述卷积产生的特征图逐通道到得到通道数为 s s s 的特征图,这样得到的特征图通道数为 m × s = n m\times s=n m×s=n。
y i j = Φ i , j ( y i ′ ) , ∀ i = 1 , . . . , m , j = 1 , . . . , s (4) y_{ij}=\Phi_{i,j}(y_i'),\ \ \forall\ i=1,...,m,\ j=1,...,s\tag{4} yij=Φi,j(yi′), ∀ i=1,...,m, j=1,...,s(4)
其中, y i ′ y'_i yi′ 表示第 i i i 个特征图, y i j y_{ij} yij 表示由第 i i i 个特征图得到的第 j j j 个特征图, Φ i , j \Phi_{i,j} Φi,j表示线性变换。该过程如图所示:
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
# 输出特征图的通道数
self.oup = oup
# 普通卷积输出特征图的通道数
int_channels = math.ceil(oup / ratio)
# 其他通道的特征图由线性变换产生
new_channels = int_channels * (ratio - 1)
# 普通卷积
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, int_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(int_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
# 简单线性变换,通过分组卷积实现
self.cheap_operation = nn.Sequential(
nn.Conv2d(int_channels, new_channels, dw_size, 1, dw_size // 2, groups=int_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
# 拼接两部分的结果
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :]
Different from Existing Methods. 与逐点卷积相比,Ghost 模块中的卷积核大小可以自定义;主流方法使用深度卷积处理特征图,然后使用逐点卷积融合空间信息,Ghost 模块使用普通卷积产生少量特征图,然后通过线性变换得到更多特征图;与使用深度卷积或移位操作来处理特征图相比,Ghost 模块中的线性变换大大减少模型计算量;Ghost 模块中的恒等映射可以有效保留特征图的信息。
Analysis on Complexities. 由于 Ghost 模块可以获得与普通卷积相同大小的输出,因此可以直接嵌入普通神经网络。在 Ghost 模块中,存在一个恒等映射和 m ⋅ ( s − 1 ) = n s ⋅ ( s − 1 ) m\cdot(s-1)=\frac{n}{s}\cdot(s-1) m⋅(s−1)=sn⋅(s−1) 个线性变换,线性变换所用卷积核的平均大小为 d × d d\times d d×d。理论上, n ⋅ ( s − 1 ) n\cdot(s-1) n⋅(s−1) 个线性变换可以使用不同大小的卷积核,但在不同设备上不易实现,因此论文在同一 Ghost 模块中的线性变换使用相同大小的卷积核。因此,相比于普通卷积,Ghost 模块的加速比为:
r s = n ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k n s ⋅ h ′ ⋅ w ′ ⋅ c ⋅ k ⋅ k + ( s − 1 ) ⋅ n s ⋅ h ′ ⋅ w ′ ⋅ c ⋅ d ⋅ d = c ⋅ k ⋅ k 1 s ⋅ c ⋅ k ⋅ k + s − 1 s ⋅ d ⋅ d ≈ s ⋅ c s + c − 1 ≈ s (6) \begin{aligned} r_s&=\frac{n\cdot h'\cdot w'\cdot c\cdot k\cdot k}{\frac{n}{s}\cdot h'\cdot w'\cdot c\cdot k\cdot k+(s-1)\cdot\frac{n}{s}\cdot h'\cdot w'\cdot c\cdot d\cdot d} \\ &=\frac{c\cdot k\cdot k}{\frac{1}{s}\cdot c\cdot k\cdot k+\frac{s-1}{s}\cdot d\cdot d}\approx\frac{s\cdot c}{s+c-1}\approx s \end{aligned}\tag{6} rs=sn⋅h′⋅w′⋅c⋅k⋅k+(s−1)⋅sn⋅h′⋅w′⋅c⋅d⋅dn⋅h′⋅w′⋅c⋅k⋅k=s1⋅c⋅k⋅k+ss−1⋅d⋅dc⋅k⋅k≈s+c−1s⋅c≈s(6)
其中上述变换的依据是 d d d 的值与 k k k 相近,且 s ≪ c s\ll c s≪c。Ghost 模块的压缩比为: r c = n ⋅ c ⋅ k ⋅ k n s ⋅ c ⋅ k ⋅ k + ( s − 1 ) ⋅ n s ⋅ c ⋅ d ⋅ d ≈ s ⋅ c s + c − 1 ≈ s (7) r_c=\frac{n\cdot c\cdot k\cdot k}{\frac{n}{s}\cdot c\cdot k\cdot k+(s-1)\cdot\frac{n}{s}\cdot c\cdot d\cdot d}\approx \frac{s\cdot c}{s+c-1}\approx s\tag{7} rc=sn⋅c⋅k⋅k+(s−1)⋅sn⋅c⋅d⋅dn⋅c⋅k⋅k≈s+c−1s⋅c≈s(7)
3.2 Building Efficient CNNs
Ghost Bottlenecks. Ghost 模块:

GhostNet. 基于 Ghost 模块构建的 GhostNet:

Width Multiplier. 为构建不同大小的 GhostNet,文中提出缩放系数 α \alpha α 对网络宽度进行缩放。
4. Experiments
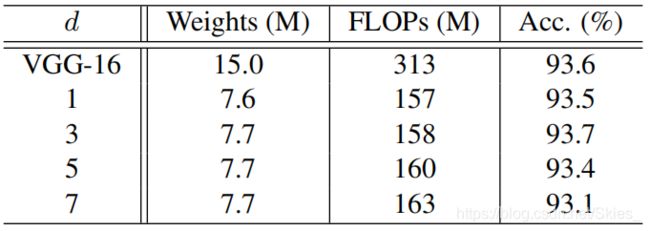
恒等映射时使用不同大小的卷积核:
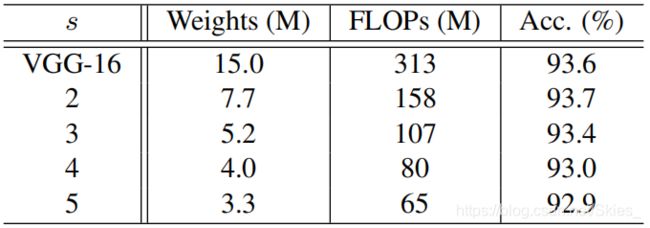
Ghost 中普通卷积产生的特征图的通道数:
与其他方法的对比:

5. Conclusion
论文提出 Ghost 模块来减少生成特征图的计算量,首先通过普通卷积得到较少特征图,然后通过线性变换(分组卷积)产生更多特征图。
参考
【1】Han K, Wang Y, Tian Q, et al. Ghostnet: More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 1580-1589.
【2】https://github.com/huawei-noah/ghostnet