ghostnet
CVPR 2020:华为GhostNet,超越谷歌MobileNet,已开源 - 知乎来自华为诺亚方舟实验室的一篇工作近日被CVPR 2020接受,提出了一种新型的端侧神经网络架构,GhostNet。作者:韩凯、王云鹤等。该架构可以在同样精度下,速度和计算量均少于SOTA算法。 该论文提供了一个全新的Ghos… https://zhuanlan.zhihu.com/p/109325275GhostNet论文解析:Ghost Module - 知乎简介: GhostNet是2020CVPR录用的一篇对卷积操作进行改进的论文。文章的核心内容是Ghost模块(Ghost Module), 可以用来替换任何经典CNN网络中的卷积操作,突出优势是轻量高效,实验证明使用了Ghost Module的Mobi…https://zhuanlan.zhihu.com/p/109420599GhostNet 解读及代码实验(附代码、超参、日志和预训练模型) - 知乎文章首发于极市平台微信公众号(ID:extrememart) 一、前言 二、论文阅读 三、代码实验 实验1. 训练模型 实验2. 计算Weights和FLOPs 实验3. 可视化特征图 四、Ghost Module下一步工作 方案1: 借助baselin…https://zhuanlan.zhihu.com/p/115844245对GhostNet中Ghost Module的理解以及对原论文的质疑 - 知乎GhostNet是华为诺亚方舟实验室提出的新型轻量化神经网络,在此次CVPR2020上横空出世,因为本人最近一直在了解一些轻量化手段,所以看到“超越MobileNetV3”这种标题的时候也不由得对其产生了兴趣,但深入了解之后…https://zhuanlan.zhihu.com/p/121757597
https://zhuanlan.zhihu.com/p/109325275GhostNet论文解析:Ghost Module - 知乎简介: GhostNet是2020CVPR录用的一篇对卷积操作进行改进的论文。文章的核心内容是Ghost模块(Ghost Module), 可以用来替换任何经典CNN网络中的卷积操作,突出优势是轻量高效,实验证明使用了Ghost Module的Mobi…https://zhuanlan.zhihu.com/p/109420599GhostNet 解读及代码实验(附代码、超参、日志和预训练模型) - 知乎文章首发于极市平台微信公众号(ID:extrememart) 一、前言 二、论文阅读 三、代码实验 实验1. 训练模型 实验2. 计算Weights和FLOPs 实验3. 可视化特征图 四、Ghost Module下一步工作 方案1: 借助baselin…https://zhuanlan.zhihu.com/p/115844245对GhostNet中Ghost Module的理解以及对原论文的质疑 - 知乎GhostNet是华为诺亚方舟实验室提出的新型轻量化神经网络,在此次CVPR2020上横空出世,因为本人最近一直在了解一些轻量化手段,所以看到“超越MobileNetV3”这种标题的时候也不由得对其产生了兴趣,但深入了解之后…https://zhuanlan.zhihu.com/p/121757597
ghostnet生动的阐述了会编故事的重要性,文章给一个自己的操作上了个大帽子,听起来有普遍的理论意义,ghostnet整体的架构和mobilenetv3是一致的,核心思想就是在bottleneck中用了两个ghost layer,ghost layer是一个3x3conv+3x3depthwise conv,去掉了1x1conv,意思是通过线性变化可以产生redundancy in feature map,这种redundancy其实可以理解成feature map的特征增强,conv的输入中引入了更多的特征数据。
1.Abstract
作者说the redundancy in feature maps is an important characteristic of those successful CNNs,cnn中特征图的冗余很重要,什么是特征冗余?其实就是特征相似的某一维度的卷积输出,在Ghost模块中通过cheap operations生成了更多的特征图,Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. 在基于intrinsic特征图,用了一系列的cheap cost的线性转化来生成许多能够充分揭示潜在intrinsic特征的ghost feature maps。意思就是在常规卷积生成的特征图上,作者用了一些线性变换,又生成一些所谓的ghost特征图,ghost特征就是相似的冗余特征,相似的冗余特征又是cnn之所有有效的关键。
但是,1.作者的这篇论文并没有给出线性变换真正有效的生成了所谓的ghost特征图,2.冗余特征是不是在cnn中起到了很大的作用,不一定,有可能conv+depth-wise只是简单的数据增强,3.所谓线性变换,作者用了dp-conv+relu,用了dp-conv还是线性的,加了relu其实不是线性的。
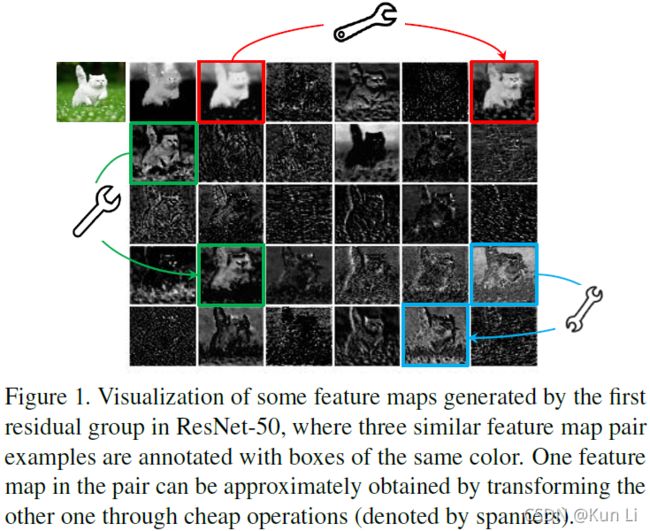
如上图,红色的,绿色的和蓝色的图都是一对,叫做冗余信息,小扳手就是cheap operation,特征图是resnet50第一个residual block后的输出。ghost就是幽灵的意思,ghostnet意思就是这些重影的这些特征图,名字取得好啊。
1.Introduction
ResNet-50 [16] has about 25.6M parameters and requires 4.1B FLOPs to process an image of size 224 x 224.
在well-trained的深度神经网络中,丰富甚至冗余信息的特征图保证了对输入数据的充分理解。例如,图1中展示的resnet50中生成的输入数据的一些特征图,其中存在许多similar pairs of feature maps,就像彼此的ghost一样。特征图中的冗余可能是成功的深度神经网络中的一个重要的特征,我们倾向于采用冗余特征图,而不是避免使用,但是要用一个cost-efficient的方式来利用冗余特征图。作者说这种similar pairs of feature maps就是ghost现象,这种现象是要利用的,所以有了后面conv+dp-conv,dp-conv是一一对应的conv,对每个维度的特征图用一个单一的核去生成对应的特征图,能够有效的构造这种pairs。(dp-conv可能自己都不知道自己还有这么个用处,用于产生 ghost pairs,当然文章也说你换个其他的线性转换也行,换其他的大概率不work)
2.Approach
2.1 ghost module for more features
这里有一点其实也挺重要的,作者说mobilenetv2等引入了dp-conv+pt-conv(dp用来分组,pt用来建立channel之间的练习,dp就是分组卷积,pt就是1x1卷积),这种方式构造高效cnn,但是剩余的1x1卷积让占用了大量的内存和flops。因此在ghost module里面是没有1x1conv的。
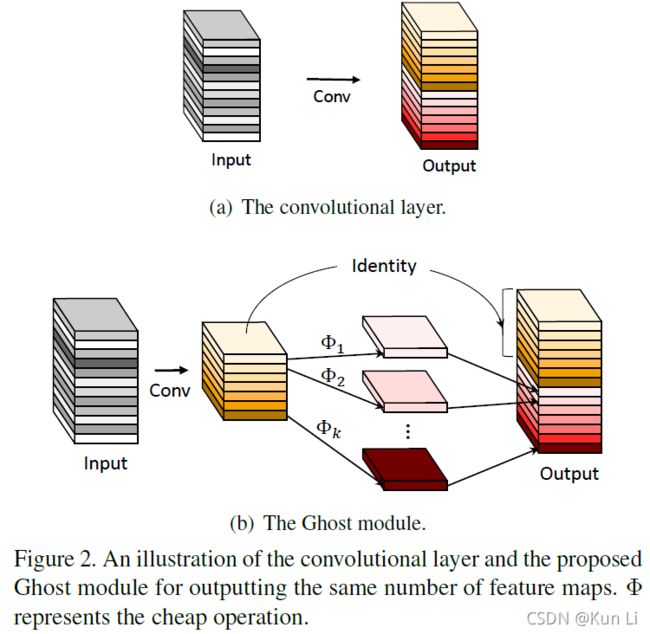
作者先说了常规卷积的做法,常规卷积的输出n个特征图中经常包含很多冗余,他们中彼此相似,指出其实不需要大量的flops和参数逐个去生成这些冗余特征图。作者先用常规cnn生成m个特征图(n/2),然后对这些特征图一一对应进行某种线性变换,生成对应的pair特征图(n/2),最后将这些特征图concat变成n,最外层连接一个shortcut,至于线性变换,是什么,其实就是3x3dp-conv。dp-conv确实是线性变换,但是实际的操作中,作者并不是dp-conv,而是dp-conv+bn+relu这样的非线性组合。作者的解释是depth wise也是一种卷积,其实可以学到很多仿射变换的效果(因为cuda不支持仿射变换的高效处理),确实带着relu会有一点理解偏差,但是初衷还是说用更简单的(比如平移、旋转、镜面反射、差分等等)。
每一个ghostbottleneck是由2个ghost layer组成的,结合代码来看一些,ghostbottleneck如下:
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x如果有降采样,在两个ghost layer之间用dp-conv来降维。ghost layer如下:
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]primary_conv是常规卷积,cheap operation是线性转换。输出时是两者concat,组成一个ghost pairs。因为上面对dp-conv的另类解释,用于生成similiar pairs of the feature map,所以不需要向之前的mobilenetv2那样前面加1x1conv和后面加1x1conv了,1x1conv的数量大大减少了,但是多了生成n/s的常规卷积块。
Analysiz on complexities.用ghost模块升级普通卷积的理论家速比是s,s就是对常规卷积输出n的特征图的分块,在作者这里stride=1的话是2,通道维度直接降一般,再和dp-conv生成出来的n/2concat,刚好还是n,shortcut支路过来的是直接add的(add完是不改变通道数目的)
4.experiments
4.1 toy experiments
这里有个很有意思的实验,作者想观察原始的特征图和通过线性变换生成的特征图两者之间的重建误差,图1上是resnet50的第一个residual block输出的特征图,作者选了红绿蓝色三对,把左边的输入,右边做输出,使用一个小的depthwise conv来学习两者之间的映射,下图表明,三对之间的mse都很小,就说明其实depthwise conv其实是对常规卷积产生特征图做了很好的重建,就是生成了所谓的ghost。

visualization of feature map.


图5是常规卷积生成的,图4左右红色是常规卷积生成的一半通道的特征图,右边是在左边特征图基础上用线性转换又提了特征的,图4强化了作者认为在深度神经网络中很重要的similar pairs。这里最大的问题是常规操作出来的pairs的占比是不知道的,理论上就认为pair起了很大的问题是不科学的,也不一定就是pair起了作用,也有可能就是边边角角的特征起了作用,dp-conv相当于在常规卷积上又提了一遍特征而已,虽然是对应通道提取的。看起来更像是做了更多的特征图数据增强,产生了不同尺度的特征,3x3的dp-conv感受野也是不同的,和常规conv出来的特征图出来concat,完全有可能是多尺度融合的结果。后面从数据增强的角度出发,n/2,一半是常规卷积,一半是depthwise conv,concat,那n/4呢,感觉可以切n/4,1/4conv,1/4dp-conv,1/4conv+dp-conv,1/4conv+conv,再concat,以此等等,感觉就是feature-map的数据增强增强,The redundancy in feature maps is an important characteristic,那也别冗余了,别ghost了,就是数据增强很重要。
论文最大的问题就是故事编的好,理论站不住脚。但是整体来看去掉了1x1conv,在bottleneck中引入了ghost layer,ghost layer里面用常规卷积先降维,在一一对应depthwise conv产生对应channel的特征图,直接concat。ghostnet之前也在我自己的项目上试过,效果一般。
2021.12.8:paperwidthcode 上imagenet top1 精度:75.7%,top5:92.7%,参数量:7.3m