文献阅读:ERNIE 2.0
0. 背景
机构:百度
作者:Yu Sun, Shuohuan Wang
发布地方:arxiv
面向任务:Natural Language Understanding
论文地址:https://arxiv.org/abs/1907.12412
论文代码:https://github.com/PaddlePaddle/ERNIE/
0-1. 摘要
预训练语言模型带来NLP领域的巨大飞跃就无需多言了,本文所提出的ERNIE 2.0除了能够捕获预训练语言模型中常见的句子或者词的共现之外,更重要的是能够捕获词汇、句法和语义信息。ERNIE 2.0的预训练是持续性地多任务的增量学习。实验结果表明,本文的模型16个自热语言处理任务上(包括GLUE benchmarks和多个中文任务)都超过BERT和XLNet。
1. 介绍
本文的贡献:
(1)提出一个可持续学习的预训练框架ERNIE 2.0。该框架以增量方式支持定制的训练任务和多任务预训练。
(2)构建了数个无监督的语言处理任务以验证本文模型的有效性,实验结果也证明ERNIE 2.0在中文任务上都显著超越BERT和XLNet。
(3)开源了该模型的源码和预训练模型
2. 相关工作
2-1. 语言表征的无监督迁移学习
利用海量无标注语料预训练语言模型能够学习到通用的语言表征,但是这些传统方法更多关注的是缺乏上下文依赖的词嵌入,如Word2Vec和GloVe。近年来基于上下文语境的语言表征,由于在多项自然语言处理任务上多次刷榜逐渐成为热点,比如ELMo、GPT、BERT、XLM(集成了两种方法以学习到跨语言模型,该模型只依赖单语数据的无监督学习方法和利用平行双语语料进行监督学习)、MT-DNN(在预训练的基础上联合多任务监督学习,所以其微调阶段是多任务学习)和XLNet(基于Transformer-XL而提出的一个通用的可学习双向上下文的自回归预训练方法)。
2-2. 持续学习
持续学习(Continual learning)致力于对数个任务按顺序依次训练模型,以确保模型在训练新任务时候,依旧能够记住先前的任务。正如人类能够不断地通过学习或历史经验积累获得信息,从而有效地发展新的技能。在持续学习下,模型由于掌握了先前的历史训练任务,从而一定程度上也能够完成新任务。
3. ERNIE2.0的框架
ERNIE 2.0的框架如Figure 1所示:

该框架也是由两阶段组成:预训练和微调。与以往采用少量预训练任务目标不同的是,本文的框架能够不断地引入大量的预训练任务,以不断提升模型在词汇、句法和语义上的表征能力。此外,本文框架能够通过多任务学习不断更新预训练模型。
3-1. 持续性的预训练
持续性预训练包括2个步骤,第一:用海量数据和相关先验知识持续构建无监督预训练任务;第二:通过多任务学习增量地更新ERNIE模型。
预训练任务的构建:
本文构建了3类任务,包括word-aware tasks, structure-aware tasks and semantic-aware tasks。这些任务都是无监督或弱监督,所以可以从海量数据中获取到。对于多任务的预训练,本文框架是在一个持续的学习模式中训练所有这些任务。本文会先用一个简单的任务训练一个初始模型,然后不断引入新的预训练任务对模型进行升级。对于一个新任务,先用前一个任务的参数进行初始化。然后,新任务将与之前的任务一起训练,以确保模型不会忘记它所学到的知识。【PS:这种不算增量学习吧,分明是全量?】
通过这种方式,ERNIE 框架可以不断学习,并积累知识,而积累到的知识有助于模型处理新任务。
从Figure 2中可以看出,本文框架包含一系列能够编码上下文信息的共享文本编码层。这些共享文本编码层可以是由RNN或者深度Transformer组成。编码层参数的更新是基于所有的预训练任务。

在本文的框架中存在2种损失函数,分别是序列级的损失和token级的损失。token级的损失与BERT类似。每个预训练的任务都有其特定的损失函数。在预训练期间,一个或多个句子级的损失函数联合多个的token级损失函数不断地更新模型。
3-2. 在下游任务上微调
通过对特定于任务在其监督数据上进行微调,ERNIE能够适用多种自然语言理解任务,如问答、自然语言推断和语义相似。每个下游任务在经过微调后都有自己的微调模型。
4. ERNIE 2.0 模型
为验证本文框架的有效性,实验过程中构建了数个非监督自然语言处理任务,并开发了一个称为ERNIE 2.0模型的预训练模型。本章节主要介绍框架中ERNIE 2.0模型的实现。
4-1. 模型结构
ERNIE 2.0主要由2个部分组成,分别是Transformer Encoder和Task Embedding。
Transformer Encoder:
与其他预训练模型如GPT、BERT、XLM一样,ERNIE 2.0模型也是采用一个多层Transformer作为encoder。Transformer通过self-attention能够捕获每个token在文本序列中的上下文信息,并生成上下文语境表征嵌入。对于给定的序列,其起始位置是预定义的分隔符[CLS];对于输入为多段的任务,不同段之间用预定义的[SEP]分隔。
Task Embedding:
模型中的task embedding是用以适用不同特性的任务。N个任务分别记为0~N,每个任务id有其特定的task embedding。具体来说,每个任务都有其特定的token embedding、position embedding和task embedding作为模型的输入。在微调阶段,可以选用任意一个任务id来进行模型的初始化。模型结构如Figure 3所示:

4-2. 预训练任务
在预训练阶段,本文基于训练语料构建了数个任务以捕获不同方面的信息。其中word-aware tasks是用以让模型捕获词法信息(lexical information),structure-aware tasks是为了让模型捕获句法信息(syntactic information ),semantic-aware tasks则是负责捕获语义信息。
4-2-1. Word-aware Pre-training Tasks
主要包括Knowledge Masking Task、Capitalization Prediction Task和Token-Document Relation Prediction Task。
Knowledge Masking Task:
ERNIE 1.0中已经提出通过知识集成(knowledge integration)来增强表征,具体来说是引入短语遮蔽(phrase masking)和命名实体遮蔽( named entity masking),并在训练过程预测被遮蔽掉的短语和命名实体,以学习到局部语境和全局语境的依赖关系信息。本文基于该Knowledge Masking Task来训练一个初级的模型。
Capitalization Prediction Task(首字母大写预测):
首字母大写的单词在一个句子中一般具有特定的语义。一个能够区分大小写的模型,在一些任务如命名实体识别上是有优势的;而不区分大小写的模型是适用于其他一些任务的。为了联合这两类模型的优势,添加一个预测该单词是否大写的任务。
Token-Document Relation Prediction Task:
本文还添加一个任务:预测段中的token是否出现在原始文档的其他段(segment)中。直觉上来说,在文档中出现的高频词一般是常用词或者是文档的主题词。因此,通过识别出一个段中文档的关键词,在一定程度上是有助于模型捕获到文档的关键词。
4-2-2. Structure-aware Pre-training Tasks
主要由Sentence Reordering Task和Sentence Distance Task组成。
Sentence Reordering Task:
句子重排任务是为了学习句子之间的关系。预训练该任务时,将给定的段落随机切分为1~m个片段(segment),再将这些片段随机排列组合一起。预训练模型需要识别这些排列组合的片段,其本质上是一个k类的分类问题,其中 k = ∑ n = 1 m n ! k=\sum_{n=1}^{m} n ! k=∑n=1mn!。从经验上来说,句子的重排任务能够让预训练模型学习到一个文档中句子之间的关系。
Sentence Distance Task:
这个任务是希望通过文档级的信息学习句子之间的距离。该任务是一个3分类问题,0表示在同一个文档中2个句子是近邻;1表示2个句子在同一个文档中,但是非近邻;2表示2个句子来自不同文档。
4-2-3. Semantic-aware Pre-training Tasks
主要由Discourse Relation Task和IR Relevance Task组成。
Discourse Relation Task:
除了上述的距离任务,还引入2个句子之间语义或修辞关系的预测任务。对于英文任务,采用Sileo et.al构建的数据集进行模型的预训练。对于中文数据集,采用Sileo et.al的方法,本文也自动构建了一个中文数据集用于预训练。
IR Relevance Task:
通过IR相关性任务,学习短文本在信息检索中的相关性。这是一个3类别的分类任务,用于预测query和title之间的关系。将query作为第一个句子,title作为第二个句子。0类别表示,query和title是强相关的,这意味着输入query后该title被点击了;1类别表示,两者是弱相关的,这意味着query输入后,搜索引擎返回的title没有被点击;2类别表示,query和title是完全无关的,二者在语义上是随机的。PS:百度搜索引擎的搜索日志作为预训练数据集。
5. 实验结果
本文对比了ERNIE 2.0和其他先进的预训练模型。对于英文任务,分别与BERT和XLNet在GLUE上对比;对于中文任务,分别与BERT和ERNIE 1.0在多个中文数据集上对比。
5-1. 预训练和实施
5-1-1. 预训练数据集
与BERT类似,其中一些英文数据集是来自于Wikipedia和BookCorpus。此外,还收集了一部分来自于Reddit的数据。再者,使用Discovery data作为话语的关系数据。对于中文数据集,主要来自于百科全书、新闻、对话和从百度搜索引擎中获取到的信息检索和话语关系数据。详见Table 1。

5-1-2. 预训练设置
为了方便与BERT对照,使用预BERT一样的Transformer设置。Base版的BERT有12层、12个self-attention heads和维度为768的隐藏层。XLNet模型的设置也和BERT一样。
5-2. 微调的任务
5-2-1. 英文任务
采用的是GLUE中的数据集,就不多介绍了。

5-2-2. 中文任务
采用9个中文数据集来验证ERNIE 2.0。其中包括机器阅读理解任务、命名实体任务、自然语言推断、语义相似、语义分析和问答。具体来说有以下9种:
- Machine Reading Comprehension (MRC): CMRC 2018 [27], DRCD [28], DuReader [29]
- Named Entity Recognition (NER): MSRA-NER (SIGHAN 2006) [30]
- Natural Language Inference (NLI): XNLI [31]
- Sentiment Analysis (SA): ChnSentiCorp 4
- Semantic Similarity (SS): LCQMC [32], BQ Corpus [33]
- Question Answering (QA): NLPCC-DBQA
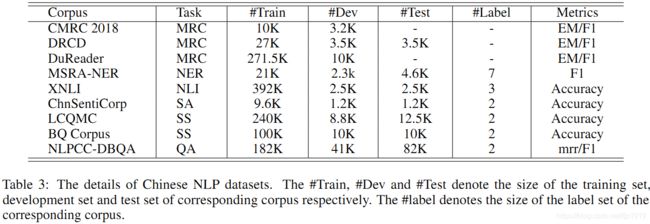
各个数据集的详细就不展开了。
5-3. 实施细节
在英文和中文数据集上微调的细节如下:

5-4. 实验结果
5-4-1. 英文任务结果
在GLUE上的实验结果:

5-4-2. 中文任务结果
在9个中文数据集上的实验结果如下:

6. 结论
本文提出一个可持续学习的预训练框架ERNIE 2.0,该框架能够以持续地在多任务上增量学习。此外,本文还构建3大类的预训练任务以学习语言的各方面特征,并基于这些任务训练了表达能力更强的ERNIE 2.0模型。ERNIE 2.0模型在GLUE和9个中文数据集上的测试结果表明该模型确实比BERT和XLNet有显著提升。后续将在ERNIE 2.0中引入更多的预训练任务以进一步提升模型的性能。