因果关系发现:推开认知世界的大门
在上一篇文章(灵魂三问:因果推断)中,我们介绍了什么是因果推断,为什么要以及如何进行因果推断。本文将围绕如下内容介绍如何进行因果关系发现研究:
-
因果发现的三个层级
-
因果发现的重要工具
-
因果发现的具体方法
(本文共4137字,预计阅读时长10分钟)
先从一组数据说起:为了研究某个治疗方案是否对某疾病有疗效,研究人员安排了治疗组和控制组进行实验,每组40人。治疗组将严格按照方案进行治疗,而控制组的人只能得到一些安慰剂。在实验进行一段时间后,得到两组病人的生存率,如图所示。

-
人群总体:50%(治疗组生存率) >40% (控制组生存率)
-
男性:60%(治疗组生存率) <70% (控制组生存率)
-
女性:20%(治疗组生存率) <30% (控制组生存率)
上面的数据给出一个令人迷惑的结论:从人群总体的角度,我们发现治疗组的生存率要高于控制组。但当区分性别来看,会完全颠覆之前的结论,即无论男性还是女性,治疗组的生存率均低于控制组。
你是不是也有一点糊涂?别担心,这就是困扰了统计学家60多年的著名的辛普森悖论,是因为仅通过学习某个条件概率,就去回答因果性问题而产生的。
一、认知因果的三个层次
图灵奖得主Judea Pearl提出,认知因果包含三个层级 1 。通过观察发现事物之间的关联只是第一个层级;在这之上,还需要对过程进行有目的的干预,才能去回答“如果进行了治疗,生存率是否会提高的问题”。认知因果的第三个层级是反事实推理,回答“假如没有…,那么…“这样的问题。
传统的机器学习最擅长做的是根据数据中呈现出来的相关性学习函数 f ( Y ∣ X 1 , … , X m ) f\left({Y|X}_1,\ldots,X_m\right) f(Y∣X1,…,Xm)去拟合条件概率 P ( Y ∣ X 1 , … , X m ) P\left(Y|X_1,\ldots,X_m\right) P(Y∣X1,…,Xm)。这种机器学习模型只学习到了认知因果的第一个层次即关联。
干预,是对所有可能影响因果关系的因子进行控制。如果不使用严格的控制实验,仅通过数据进行干预,需要引入由do算子定义的干预分布,直观地描述对 X i X_i Xi进行有意图干预时,其他变量概率分布的变化情况 2 。例如: P ( Y ∣ d o ( X ) = a ) P(Y|do\left(X\right)=a) P(Y∣do(X)=a)描述了当 X X X取值为 a a a时, Y Y Y所对应的分布。写成如下形式:
P ( X 1 , … , X i − 1 , X i + 1 … , X n | d o ( X i ) = a ) = P ( X 1 , … , X n ) P ( X i | p a i ) I ( X i = a ) P\left(X_1,\ldots{,X}_{i-1,}X_{i+1}\ldots,X_n\middle| d o\left(X_i\right)=a\right)=\frac{P\left(X_1,\ldots,X_n\right)}{P\left(X_i\middle|{pa}_i\right)}I(X_i=a) P(X1,…,Xi−1,Xi+1…,Xn∣∣do(Xi)=a)=P(Xi∣pai)P(X1,…,Xn)I(Xi=a)
其中, p a i {pa}_i pai表示所有产生 X i X_i Xi的原因; I ( X i = a ) I(X_i=a) I(Xi=a)为恒等函数,即当 X i X_i Xi的值为 a a a时,其值为1,当 X i X_i Xi的值不为 a a a时,其值为0。等式右边的除数 P ( X i | p a i ) P\left(X_i\middle|{pa}_i\right) P(Xi∣pai)表示在对 X i X_i Xi进行干预时,需要去除 p a i {pa}_i pai对 X i X_i Xi的影响。
如果能得到如下情况:
P ( X j ∣ d o ( X i = x , X \ i j = c ) ) ≠ P ( X j ∣ d o ( X i = x ′ , X \ i j = c ) ) P(X_j|do(X_i=x,X_{\backslash ij}=c))\neq P(X_j|do(X_i=x^\prime,X_{\backslash ij}=c)) P(Xj∣do(Xi=x,X\ij=c))=P(Xj∣do(Xi=x′,X\ij=c))
即在保持系统中除 X i X_i Xi和 X j X_j Xj外的其他变量不变的情况下, X i X_i Xi值的变化引起了 X j X_j Xj的分布变化,那么我们可以说 X i X_i Xi是 X j X_j Xj的直接原因。
我们以辛普森悖论为例,直观地理解干预分布和条件分布之间的差别。

用条件概率衡量治疗对生存率的影响,计算如下:

同理 P ( S = s u r v i a l | T = c o n t r o l ) = 40 % P\left(S=survial\middle| T=control\right)=40\% P(S=survial∣T=control)=40%。
用do算子衡量治疗对生存率的影响,计算如下:
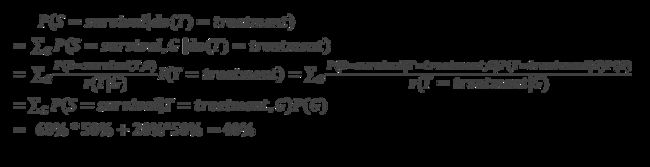
同理 P ( S = s u r v i a l | d o ( T ) = c o n t r o l ) = 60 % P\left(S=survial\middle| d o(T)=control\right)=60\% P(S=survial∣do(T)=control)=60%。
对比两组计算:条件概率中Gender对生存率的影响会因为Treatment而变化(见 P ( G ∣ T ) ) P(G|T)) P(G∣T));而干预分布中Gender对Treatment的影响(作为除数的 P ( T ∣ G ) ) P(T|G)) P(T∣G))受到严格控制,其对生存率的影响并不会因为Treatment变化。
通过干预的推理告诉我们通过治疗,人们的存活率为40%,要低于控制组的60%。但这些都是在研究总体效应或平均因果效应,如果针对特定事件或个体层面谈论个性化因果关系还需要进行反事实推理。比如在治疗了一段时间后,某病人的生存率提高,但这真是因为服用了特定的药物吗?还是因为听到了好消息?在反事实层,因为我们不可能观测到未曾发生的事情,只能在想象的世界里,推测现象原因为何。
二、因果发现的工具
因果发现旨在从一堆纷繁复杂的数据中,挖掘出不同变量之间因果影响的网络结构。为了进行因果发现,我们需要认识两个描述系统因果机制的工具:因果图和结构因果模型。
2.1 因果图
因果图是在贝叶斯网络的基础上定义的,它们都通过有向无环图(DAG)的形式并遵从马尔可夫性和忠实性假设,抓住图与数据交互的关键,实现了图的连接性和变量的独立性之间的联结。区别是,贝叶斯网络是由一系列条件概率描述的有向无环图,而因果图引入由do算子定义的干预,突破了条件概率只能学习到相关性的限制,从而到达认知因果的第二个层级,学习到更稳定的结构。下图直观地描述了五个变量之间的因果关系: X 1 X_1 X1是 X 2 X_2 X2和 X 3 X_3 X3的共同原因, X 3 X_3 X3和 X 4 X_4 X4又共同产生了 X 5 X_5 X5。
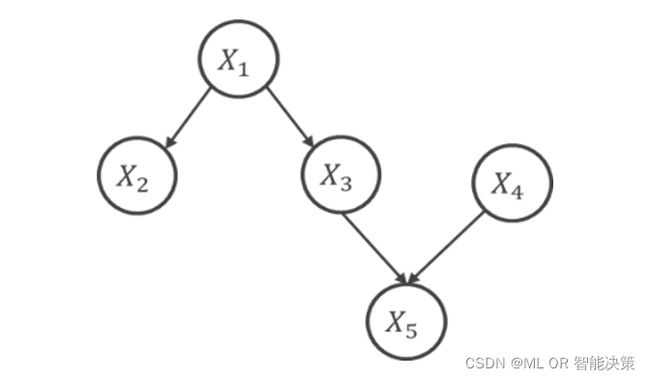
接下来我们识别有向无环图中的几个重要结构:

在head-to-tail和tail-to-tail中, X X X和 Y Y Y关于 Z Z Z条件独立,即 X ⊥ Y ∣ Z X\bot Y|Z X⊥Y∣Z,其中head-to-tail中的 Z Z Z为中间变量,tail-to-tail中的 Z Z Z为混淆变量;在head-to-head(v-结构)中, X X X和 Y Y Y无条件独立,或者说 X X X和 Y Y Y关于空集条件独立 X ⊥ Y ∣ ∅ X\bot Y|\emptyset X⊥Y∣∅, Z Z Z被称为对撞点。
我们需要严格控制混淆变量以消除其带来的偏差。然而,长期以来,统计学家时常困惑于具体应该控制哪些变量。如果控制中间变量,会切断 X X X和 Y Y Y之间的间接因果联系,得出 X X X对 Y Y Y没有影响的错误结论;如果控制对撞点,则会错误地认为 X X X对 Y Y Y有因果关系。后门准则和前门准则,可以帮助识别并消除因果图中的混淆变量,将do算子表示的干预分布转化成条件分布,在此基础上可以利用统计方法进行因果推断。
后门准则:后门路径定义为连接 X X X和 Y Y Y且包含了指向 X X X的箭头的所有路径。阻断 X X X和 Y Y Y之间的所有后门路径,可以防止 X X X的信息在非因果方向上的传递。存在对撞点的后门路径被认为时天然阻断的。
以研究“吸烟”(原因变量)对“癌症”(结果变量)的影响为例,“吸烟->焦油沉积->癌症”为因果路径,其中,“焦油沉积”为中间变量。“吸烟<-吸烟基因->癌症”为一条从“吸烟”到“癌症”的后门路径,该路径包含指向“吸烟”的箭头,其中**“吸烟基因“为混淆变量**。此外,整个因果图中只有一条从“吸烟”到“癌症”的后门路径。因此,控制了“吸烟基因”,我们就阻断了从“吸烟”到“癌症”的所有后门路径。
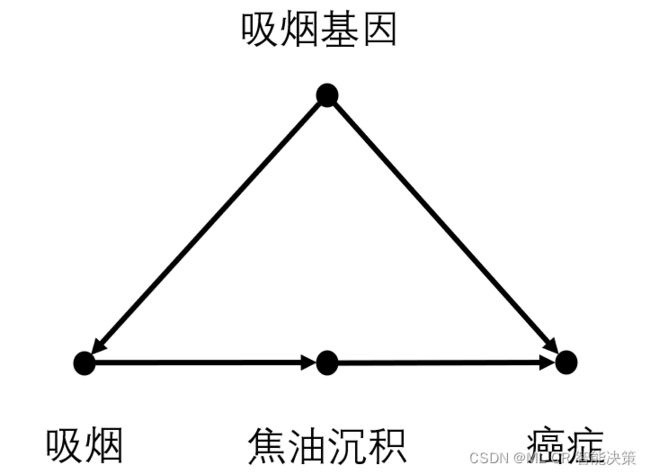
为了研究“吸烟”对“癌症”的因果效应,我们对“吸烟”使用do算子:
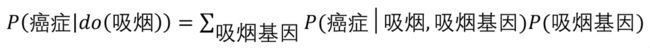
前门准则:前门路径就是指从 X X X到 Y Y Y的直接因果路径,即上述:“吸烟->焦油沉积->癌症“的路径。当因为缺乏必要的数据而无法阻断某条后门路径时,就要通过前门准则,将 X X X对 Y Y Y的因果效应分解为 X X X对 Z Z Z的因果效应和 Z Z Z对 Y Y Y的因果效应。
在吸烟的案例中,假设我们无法对吸烟基因进行测量,但是可以获取”吸烟“,”焦油沉积“,以及“癌症”这三个变量的数据。这时,我们将“吸烟”对“癌症”的平均因果效应 P ( 癌 症 ∣ d o ( 吸 烟 ) ) P(癌症|do(吸烟)) P(癌症∣do(吸烟)),转化为 P ( 焦 油 沉 积 ∣ d o ( 吸 烟 ) ) P(焦油沉积|do(吸烟)) P(焦油沉积∣do(吸烟))和 P ( 癌 症 ∣ d o ( 焦 油 沉 积 ) ) P(癌症|do(焦油沉积)) P(癌症∣do(焦油沉积))的加权。在计算 P ( 焦 油 沉 积 ∣ d o ( 吸 烟 ) ) P(焦油沉积|do(吸烟)) P(焦油沉积∣do(吸烟))时,路径“吸烟<-吸烟基因->癌症<-焦油沉积”中 “癌症”处出现的对撞天然地阻断了这条后门路径。在计算 P ( 癌 症 ∣ d o ( 焦 油 沉 积 ) ) P(癌症|do(焦油沉积)) P(癌症∣do(焦油沉积))时,存在后门路径“焦油沉积<-吸烟<-吸烟基因->癌症“,通过控制”吸烟“可以阻断。
利用前门准则,最终可以得到:

2.2 结构因果模型
结构因果模型也称作函数因果模型,旨在通过一系列函数方程对由图所描述的因果关系进行定义,将因果发现转化为函数估计问题 3 。
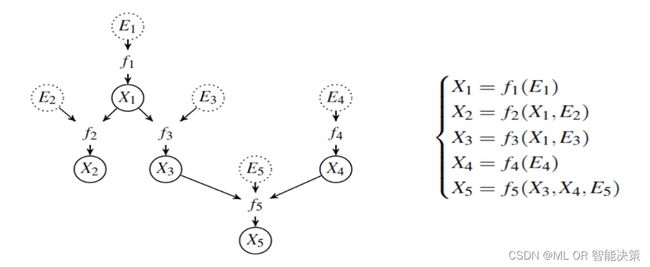
在结构因果模型中,除了因果变量 X j X_j Xj外,还有一组随机变量 E j E_j Ej,它们只影响所对应的 X j X_j Xj,且相互独立,用于描述 X j X_j Xj受环境影响产生的不确定性。
相比因果图,结构因果模型包含了更多的信息,其不仅蕴含了一个观测分布,还蕴含了干预分布和反事实分布,可以在因果图干预的基础上,进一步支持反事实推理。

找到一个结构因果模型就意味着找到数据蕴含的唯一的联合分布;根据马尔可夫假设,可以将其按照因果图进行分解,即 P ( X 1 , … , X d ) = ∏ j = 1 d P ( X j ∣ P a j ) P\left(X_1,\ldots,X_d\right)=\prod_{j=1}^{d}{P(X_j|{Pa}_j)} P(X1,…,Xd)=∏j=1dP(Xj∣Paj)。但当存在
head-to-tail以及 tail-to-tail结构时,我们观测到的联合分布是一致的。例如: X X X和 Y Y Y关于 Z Z Z相互独立,可以得到如下 ( X , Y ) (X,Y) (X,Y)的联合概率分布:

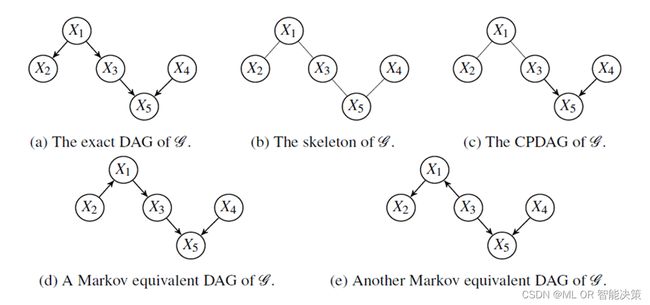
所以实际上,利用结构因果模型只能够确定一类具有相同骨架(无向图)和v-结构的部分有向无环图(CPDAG),即马尔可夫等价类。
下图中,(a)是真实的因果图,(b)是其骨架,(d)和(e)是(a)的所有马尔可夫等价图;(c)展示了图(a)马尔可夫等价类的CPDAG 4 。
当可以通过一个结构因果模型找到一个马尔可夫等价类时,我们就说他是可识别的。这需要对 N j N_j Nj和 f j f_j fj作相应的假设。当假设所有的 N j N_j Nj服从相互独立的高斯分布时,关于 f j f_j fj的形式和结构因果模型的可识别性有如下结果:

三、因果发现的具体方法
基于观测的因果发现,就是要对生成数据的因果结构进行估计。用于确定一个因果图的马尔可夫等价类的方法,主要包括两类:基于约束的方法和基于分数的方法。
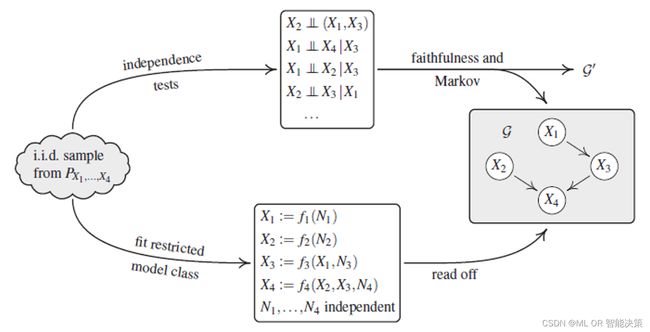
基于约束的方法主要通过一系列假设检验,判断在给定一个集合A后,两个节点之间是否条件独立。以该类方法中的PC算法为例 5 ,为了避免对所有可能的子集A进行搜索,在因果图构建过程中,从一个全连接图开始,通过逐渐增加条件集合的大小,来判断两个变量之间是否条件独立。如果可以找到一个集合使得两个变量之间条件独立,就可以去掉两个变量之间的边。当无法删除任何边时,就得到了因果图的骨架。如果两个变量 ( X , Y ) (X,Y) (X,Y)之间条件独立,即它们之间没有直接相连的边,但存在路径 X − Z − Y X-Z-Y X−Z−Y,且 Z Z Z无法使得 ( X , Y ) (X,Y) (X,Y)条件独立,那么就可以确定一个对撞结构(v-结构) X → Z ← Y X\rightarrow Z\gets Y X→Z←Y。在找到图中的所有v-结构后,就确定了CPDAG。
基于分数的方法主要通过对模型类型作相应的假设限制,直接拟合一个结构因果模型结构。拟合的效果通常由一个打分函数进行定义,通过求解
G ^ : = argmax G DAG over X S ( D , G ) \hat{\mathcal G}:= {\underset {\operatorname{\mathcal G\ DAG \ over\ X}}{\operatorname {argmax} }} \ \mathcal S(\mathcal D,\mathcal G) G^:=G DAG over Xargmax S(D,G)
得到最优的图结构。该打分函数通常包括两个部分:一是要最大化对数据的拟合程度;二是对图结构的复杂程度进行惩罚。在对最优图结构进行搜索时,可以使用贪婪搜索方法等局部搜索方法,也可以使用如动态规划、混合整数规划进行精确搜索。
通过有效地结合基于独立性和基于分数的混合方法,节约计算成本,得到更加准确有效的模型估计。
基于独立性和基于分数的方法,只能够确定CPDAG,要画出完整的因果图,可以借助成对比较方法去探索局部信息,主要是利用反映在数据中的因果产生机制的不对称性,确定因果方向。
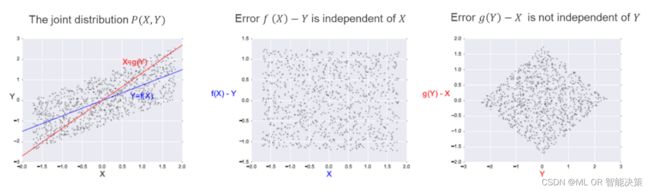
具体来讲:如果 X X X和 Y Y Y之间存在直接因果关系,根据概率公理无法区分因果方向,即 p ( x , y ) = p ( x ∣ y ) p ( y ) = p ( y ∣ x ) p ( x ) p\left(x,y\right)=p\left(x|y\right)p\left(y\right)=p\left(y|x\right)p(x) p(x,y)=p(x∣y)p(y)=p(y∣x)p(x)。考虑如下结构因果模型:
X ≔ E X X≔E_X X:=EX Y ≔ f ( X ) + E Y Y≔f\left ( X \right )+E_Y Y:=f(X)+EY
其中, E X ⊥ E_X\bot EX⊥ E Y E_Y EY。由 E X E_X EX和 E Y E_Y EY相互独立,可知 X X X与 [ Y ∣ X ] [Y|X] [Y∣X]相互独立;然而在非因果方向上 Y Y Y与 [ X ∣ Y ] [X|Y] [X∣Y]却不一定独立。如下图所示,区别于因果方向上的独立性,即 f ( X ) − Y f\left(X\right)-Y f(X)−Y与 E Y E_Y EY独立,用线性方程 g ( Y ) g(Y) g(Y)去拟合 X X X,得到的残差与 Y Y Y之间存在明显的相关性。
结语
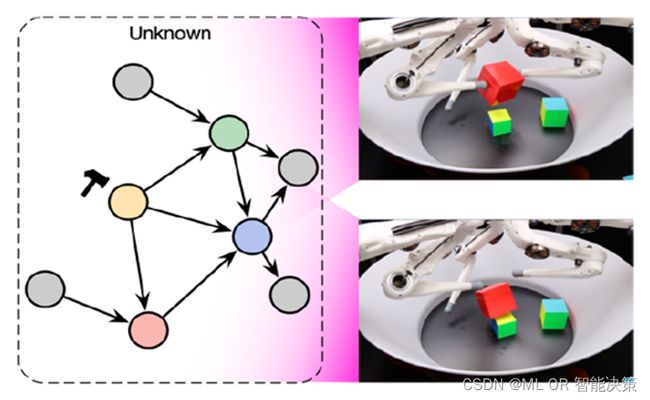
因果推理是非常强大的解释、分析和建模工具,与机器学习结合,可以提取更稳定和可解释的特征信息,增加模型的泛化能力。比如,在因果表征学习中,对一个复杂系统的因果环节进行解构,就可以在系统发生变化时,定位变化模块,解释变化原因,进行局部干预,甚至是反事实推理 6 。以下图为例,系统中一个机械手指的动作发生变化,造成了红色方块掉落。在右图所示的像素空间中,红色方块掉落也遮挡了背景中其他物体,这使得机械手指引起的变动信息与系统中其他互不相干的物体纠缠在一起,无法分解。在左图中,将整个系统的物理机制用因果图进行描述,那么只有机械手指对应的节点和红色方块节点及其子节点发生了变化。由此,在因果表征空间里实现了信息解耦。这种信息解耦,可以帮助探索事物内部的物理机制和逻辑关系,对视频跟踪监控、自动驾驶、飞行控制等自动化系统的精准智能感知、智能辨识与控制预测至关重要。
此外,因果推断在半监督学习、域适应、迁移学习或稳定学习、情景强化学习等多个领域都有极大的研究意义和应用价值。
(本文首发于微信公众号:ML OR 智能决策。分享更多干货,欢迎交流~)
参考资料
J. Pearl and D. Mackenzie (2018). The book of why. Basic Books. ↩︎
J. Pearl et al. (2016). Causal Inference in Statistics: A Primer. Wiley. ↩︎
J. Peters et al. (2017). Elements of Causal Inference: Foundations and Learning Algorithms. MIT Press. ↩︎
O. Goudet, et al. (2018). Learning Functional Causal Models with Generative Neural Networks. In Explainable and Interpretable Models in Computer Vision and Machine Learning, 39-88. ↩︎
M. Kalisch and P. Bühlmann (2007), Estimating high-dimensional directed acyclic graphs with the PC-algorithm. Journal of Machine Learning Research. ↩︎
B. Schölkopf, et al. (2021). Towards Causal Representation Learning. https://arxiv.org/abs/2102.11107. ↩︎