无监督学习之KMeans的数据分类与KNN分类结果对比
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
data = pd.read_csv("./data.csv",encoding="utf-8")
data.head()
x1 = data.loc[:,"V1"]
x2 = data.loc[:,"V2"]
x3 = data.drop(['labels'],axis=1)
y = data.loc[:,"labels"]
#建立KMeans模型并训练
KM = KMeans(n_clusters=3,init='random',random_state= 0)
#模型训练
KM.fit(x3)
#查看聚类中心
centers = KM.cluster_centers_
print(centers)
#无监督聚类的结果预测
y_predict = KM.predict(x3)
print(y_predict)
print(pd.value_counts(y_predict))#统计元素个数
print(pd.value_counts(y))
#结果矫正
y_corrected = []
for i in y_predict:
if i==0:
y_corrected.append(1)
elif i==1:
y_corrected.append(2)
elif i==2:
y_corrected.append(0)
print(pd.value_counts(y_corrected))
#准确率计算
accuray = accuracy_score(y,y_corrected)
print("KMeans精度:",accuray)
y_corrected = np.array(y_corrected)
flg1=plt.figure(figsize=(12,8))
#KNN建模部分与训练
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(x3,y)
#KNN的预测
y_predict_knn = KNN.predict(x3)
accuray_knn = accuracy_score(y,y_predict_knn)
y_predict_knn = np.array(y_predict_knn )
print("knn训练精度:",accuray_knn)
#KNN结果可视化
plt.subplot(1,3,1,)
plt.scatter(x1[y_predict_knn ==0],x2[y_predict_knn ==0],label='class 0')
plt.scatter(x1[y_predict_knn ==1],x2[y_predict_knn ==1],label='class 1')
plt.scatter(x1[y_predict_knn ==2],x2[y_predict_knn ==2],label='class 2')
plt.legend(loc='upper left')#显示数据label内容
plt.title("KNN_result")
plt.xlabel('x')
plt.ylabel('y')
#训练结果的展示
plt.subplot(1,3,2,)
plt.scatter(x1[y_corrected==0],x2[y_corrected==0],label='class 0')
plt.scatter(x1[y_corrected==1],x2[y_corrected==1],label='class 1')
plt.scatter(x1[y_corrected==2],x2[y_corrected==2],label='class 2')
plt.legend(loc='upper left')
plt.title("KMeans_result")
plt.xlabel('x')
plt.ylabel('y')
#数据可视化
plt.subplot(1,3,3,)
plt.scatter(x1,x2)
# #中心点的可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',c = 'r')#c表示颜色设置
plt.title("original_data")
plt.legend(loc='upper left')
plt.xlabel('x')
plt.ylabel('y')
plt.show()结果展示:
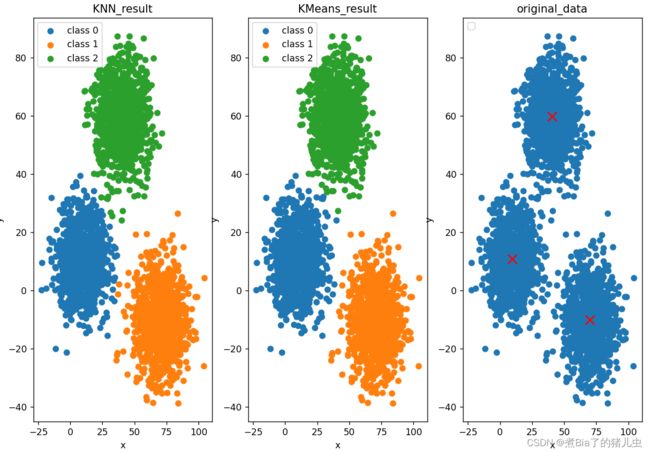

附件:逐步查看kmeans的每次迭代结果
#逐步查看KMeans模型的训练结果
centers= np.array([0,0,0,0,0,0]).reshape(1,-1)
for i in range (1,10):
KM = KMeans(n_clusters=3,random_state=1,init='random',n_init=1,max_iter=i)
KM.fit(x3)
centers_i = KM.cluster_centers_
centers_i_temp = centers_i.reshape(1,-1)
print(centers_i_temp.shape,centers.shape)
centers = np.concatenate((centers,centers_i_temp),axis = 0 )
y_predict = KM.predict(x3)
fig_i = plt.figure()
label0 = plt.scatter(x1[y_predict == 0], x2[y_predict == 0])
label1 = plt.scatter(x1[y_predict == 1], x2[y_predict == 1])
label2 = plt.scatter(x1[y_predict == 2], x2[y_predict == 2])
#
plt.title("diedai")
plt.xlabel('x')
plt.ylabel('y')
plt.legend((label0,label1,label2),('label0','label1','label2'),loc = 'upper left')
plt.scatter(centers_i[:,0],centers_i[:,1])
fig_i.savefig(r'C:\Users\99269\PycharmProjects\study day\无监督学习\2d_output\{}.png'.format(i),dpi=500,bbox_inches = 'tight')
plt.show()