ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation
ERNIE-Search:通过自动态蒸馏将交叉编码器与双编码器桥接,用于密集通道检索
Yuxiang Lu, Yiding Liu, Jiaxiang Liu, Yunsheng Shi, Zhengjie Huang, Shikun Feng Yu Sun, Hao Tian, Hua Wu, Shuaiqiang Wang, Dawei Yin and Haifeng Wang Baidu Inc. { luyuxiang, liujiaxiang, shiyunsheng01, huangzhengjie, fengshikun01, sunyu02, tianhao, wu_hua, wanghaifeng}@baidu.com { liuyiding.tanh, shqiang.wang}@gmail.com [email protected]
摘要
基于预训练语言模型(PLM)的神经检索器(如双编码器)在开放域问答(QA)任务中取得了良好的表现。
通过整合跨架构的知识提炼,它们的有效性可以进一步达到新的水平。然而,现有的大多数研究只是直接应用传统的蒸馏方法。他们没有考虑到教师和学生结构不同的特殊情况。在本文中,我们提出了一种新的蒸馏方法,显著提高了双编码器的跨架构蒸馏。我们的方法1)引入了一种自实时蒸馏方法,该方法可以有效地将后期交互(即ColBERT)提取到vanilla双编码器,2)结合级联蒸馏过程,与交叉编码器教师进一步提高表现。我们进行了大量实验,以验证我们提出的解决方案优于强基线,并在开放域QA基准上建立了新的最先进水平。
1引言
开放领域问答(QA)旨在通过大量语料库中的段落来回答因子问题,其中该任务的实际解决方案通常采用先检索再重新排序的范式。近年来,预训练语言模型(PLM)(Devlin等人,2018;Vaswani等人,2017)在许多自然语言处理任务上取得了巨大成功。基于PLM的重新检索器和重新排序器也为开放域QA提供了最先进的表现。特别是,双编码器(Reimers和Gurevych,2019;Karpukhin等人,2020;Guo等人,2021)和交叉编码器(Nogueira等人,2019b;Nogueira和Cho,2019))分别是最常用的检索器和重入器。
实证研究已经证实,更好的重新检索可以转化为更好的端到端质量保证系统(Karpukhin等人,2020),而具有大量参数的双编码器的有效性在很大程度上依赖于大规模带注释的训练数据,其获取成本很高(Qu等人,2020;Wang等人,2021)。最近,知识提取(KD)(Hinton等人,2015)已成为解决这一问题的重要组成部分,其中广泛的研究旨在将更有能力的教师提取为双编码器学生(Hofstätter等人,2021;Yang和Seo,2020;Lin等人,2021)。
这些方法也可以被视为教师产生的伪监督的数据挖掘(瞿等人,2020;杨等人,2020)。
更具体地说,交叉编码器和Col-BERT(Khattab和Zaharia,2020)是两种常用的教师模型。交叉编码器允许查询和通道之间的完全令牌级交叉交互,从而为双编码器学生提供更准确的监督(Hofstätter等人,2020;Yang和Seo,2020;Qu等人,2020;Ren等人,2021b;Yang等人,2020)。ColBERT是双编码器的一种变体,它以更具表现力的后期交互推进了双编码器(例如点积)的简单度量交互。它允许分批蒸馏负示例(Lin等人,2021,2020),这对于训练双编码器至关重要(Karpukhin等人,2020)。此外,还有少数研究采用了多教师蒸馏,即同时使用交叉编码器和ColBERT作为教师(Choi等人,2021;Hofstätter等人,2021)。值得注意的是,所有这些研究都证明,使用这种跨架构蒸馏设置改进双编码器是富有成效的,在这种设置中,教师比双编码器学生配备了更具表现力的查询通道交互。
尽管最初取得了成功,但一个被忽视的问题是,跨架构蒸馏提供的知识是否可以通过双编码器完全学习。这种令人担忧的担忧来自于证据表明交叉编码器中编码的底层语义,而双编码器本质上是不同的(杨和Seo,2020;高和Callan,2021)。当前的跨架构蒸馏方法可能是次优的,因为它们只是简单地将交叉编码器的预测(即硬标签或软标签)用作监督信号。更具体地说,通过表达性交叉交互(即交叉编码器)编码的知识是否可以通过具有简单度量交互(例如点积)的双编码器有效提取,这是值得怀疑的。
基于此,我们重新探讨了交叉交互(例如交叉编码器)、后期交互(例如ColBERT)和度量交互(例如双编码器)之间的关系,在此基础上,我们提出了一种新的蒸馏范式,改进了双编码器检索器的跨架构蒸馏(称为ERNIE搜索)。
我们首先介绍了交互蒸馏,其中教师和学生共享相同的编码层,但具有不同的交互方案。这种方法用于蒸馏后期相互作用(即ColBERT)→ 度量交互(即双编码器),其中学习简单的度量交互以模拟更具表现力的后期交互。由于教师和学生被限制共享相同的transformer编码器,该方法可以缓解两个模型具有不同知识表达方式的风险。
因此,它更集中于不同相互作用方案的蒸馏。
接下来,我们进行级联蒸馏,进行交叉作用的蒸馏→ 后期交互→ 度量交互。直觉是,后期交互模型(如ColBERT)可以被视为一个教师助手,弥合交叉编码器和双编码器之间的结构差距。更具体地说,我们利用ColBERT的后期交互来提取交叉编码器的细粒度令牌级交互知识,最终的双编码器可以进一步提取这些知识。
我们在两个大规模QA数据集上评估了我们提出的方法:MS MARCO Passage Rank-ing(Nguyen等人,2016)和Natural Question(NQ)(Kwiatkowski等人,2019),其中我们的结果达到了与几个基线相当或更好的表现。提出的解决方案在开放域QA任务上建立了新的最先进的表现。
2相关工作
2.1基于预训练语言模型的神经检索器
预训练语言模型(PLM),如BERT(Devlin等人,2018)和ERNIE(ERNIE)(Sun等人,2019),在许多自然语言处理任务中取得了巨大成功。基于PLM的检索器(例如,双编码器)的有效性也为开放域QA带来了显著突破(Reimers和Gurevych,2019;Karpukhin等人,2020;Liu等人,2021;Guo等人,2021)。与交叉编码器相比,双编码器在相关性建模上通常表现出有限的表达能力(Qu等人,2020)。为此,已经提出了各种方法来改进vanilla双编码器,例如复杂的预训练任务(Lee等人,2019;Chang等人,2020)、表现性轻量级交互(Humeau等人,2019;Khattab和Zaharia,2020;Ye等人,2022)和负示例挖掘(Qu等人,2020;Karpukhin等人,2020)。尽管这些方法提供了优化的结构和训练过程,但另一条研究路线旨在利用知识提炼(Hinton等人,2015)来解决数据稀缺问题(Wang等人,2021),这已被证明是帮助双编码器实现最先进表现的关键(Qu等人,2020;Ren等人,2021b)。
2.2检索器的知识提取
知识提炼(KD)(Hinton等人,2015)旨在通过更有效的教师模型改进有效的学生模型,这些模型通常具有相同的架构,但具有更多的层和维度(焦等人,2019;王等人,2020)。
与这种传统设置不同,检索器的KD通常遵循跨架构范式(Hofstätter等人,2020),其中教师模型的结构不同于双编码器。例如,交叉编码器被广泛用作教师模型,以在大规模未标记数据上提供弱监督信号(Hof-stätter等人,2020;Yang和Seo,2020;Qu等人,2020;Ren等人,2021b;Yang等人,2020)。另一种流行的选择是ColBERT(Khattab和Zaharia,2020),其结构更类似于双编码器,因此允许KD批量负示例(Lin等人,2021,2020)。此外,一些研究也试图通过多教师蒸馏提高表现(Choi等人,2021;Hofstätter等人,2021)。然而,他们都没有研究如何更有效地将教师的知识分解为具有不同架构的学生。在本文中,我们提出了一种新的蒸馏协议,该协议在跨架构蒸馏过程中弥补了固有的结构差距,可以显著提高双编码器的有效性。
3方法
本节描述了一种新的训练方法,用于开放域QA的密集通道检索,即ERNIE搜索。ERNIE-Search的核心思想是自我即时蒸馏,我们使用共享编码器和不同的交互方案联合训练教师和学生。在第3.1节中,我们首先介绍了开放域QA问题和不同的编码器架构。接下来,第3.2节和第3.3节分别介绍了ERNIE搜索的两种核心技术,即交互蒸馏和级联蒸馏。第3.4节描述了用于训练双编码器的正则化方法。
3.1准备工作
任务描述。我们首先描述了开放域QA的任务,如下所示。给定一个因子问题,需要一个系统使用大量文档来回答。假设我们的集合包含D个文档,即![]() 。我们首先将D个文档分成M个段落,以获得语料库
。我们首先将D个文档分成M个段落,以获得语料库![]() ,其中每个段落p i有k个tokens
,其中每个段落p i有k个tokens
![]()
。
双编码器。对于密集通道检索器,最近的研究通常开发一种双编码器架构。它包含E P(·)和E Q(·),这是分别将通道和查询映射到d维实值向量的密集编码器。
查询q和候选通道p的语义相关性可以使用其向量的点积作为
![]()
来计算。具体来说,我们使用预训练语言模型(PLM)作为两个编码器,产生特殊tokens(即[CLS])的表示作为输出。通过两种表示之间的简单度量交互(例如点积)计算相关性分数。
交叉编码器。研究人员开发了通道重新排序模型(即重新排序),以进一步改善检索候选通道后的端到端QA(Choi等人,2021;任等人,2021b;张等人,2021)。使用交叉编码器作为重编码器通常可以获得优异的表现。
与双编码器不同,交叉编码器计算相关性分数s ce(q,p),其中输入是q和p与特殊token[SEP]的串联。随后,输出的[CLS]表示被馈送到线性函数中以计算相关性分数。交叉编码器实现了每个transformer层的q和pin的交叉交互,因此有效但效率低。
ColBERT。ColBERT可以被视为具有后期交互的更具表现力的双编码器(Khat-tab和Zaharia,2020)。对于问题q和通道p,ColBERT的相关性分数计算如下:
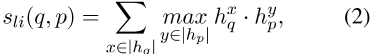
,其中h q和h p分别表示每个查询和通道token的输出表示。
3.2相互作用蒸馏
我们首先提出了相互作用蒸馏,它允许蒸馏后期相互作用(即Col-BERT)→ 度量交互(即双编码器)。
与传统的蒸馏范式不同,我们使用共享编码器和不同的交互方案联合训练教师(即ColBERT)和学生(即双编码器)。这将促使训练更加专注于将复杂的后期交互提取为简单的度量交互。
更正式地说,给定查询中的查询q和候选通道列表![]() ,我们将每个q、p对馈送到查询和通道编码器中,并输出token表示。基于最终表示,我们分别计算了具有度量交互(即,在双编码器中)和延迟交互(即,在Col-BERT中)的两个相关性分数
,我们将每个q、p对馈送到查询和通道编码器中,并输出token表示。基于最终表示,我们分别计算了具有度量交互(即,在双编码器中)和延迟交互(即,在Col-BERT中)的两个相关性分数![]() 和
和![]()
![]() 。我们可以将分数在候选通道上的概率分布公式如下:
。我们可以将分数在候选通道上的概率分布公式如下:
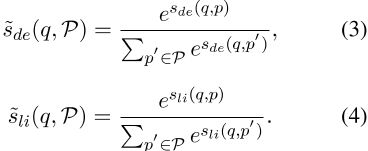
交互蒸馏的目标是用更简单交互(即s̃de)的分布模拟更具表达力交互(即s̃li)的分数分布,除了蒸馏损失(即,等式(5))外,如果损失可以通过KL散度作为
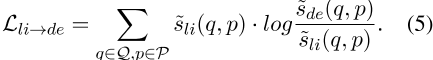
来测量,我们还可以在开放域QA任务中使用标记数据对两个交互方案进行训练,其中损失可以定义为
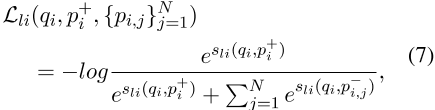
,其中N是负通道数。在每个输入三元组中,我们使用q i、p+i和p− i、 j分别表示查询、正通道和第j个负通道。最终损失函数是上述三种损失的组合,即
![]()
。图1说明了相互作用蒸馏。
我们使用两种不同的交互方案优化相同的编码器,其中简单的度量交互是从更复杂的度量交互中提取出来的。在训练期间,交互提取有效地弥合了不同交互之间的差距,并最终确定了可用于提取更复杂交互的模型。此外,它是高效的,因为它只需要一个前馈步骤就可以生成教师和学生的分数。

图1:交互蒸馏的图示。
3.3级联蒸馏
在交互蒸馏之后,我们可以通过从更强大的交叉编码器蒸馏来进一步改进双编码器。然而,交叉编码器的交互方案甚至比后期交互更复杂,在后期交互中,交叉编码器捕获的令牌级交互对于双编码器学习来说可能是不平凡的。为此,我们提出了级联蒸馏,旨在缓解交叉编码器和双编码器之间的差距。
级联蒸馏的基本直觉是将后期相互作用视为简化的令牌级交叉相互作用,以弥合上述差距。特别是,我们可以分解交叉作用的提取过程→ 度量交互分为两个级联步骤,即交叉交互→ 后期交互→ 度量交互,将知识从交叉编码器逐渐转移到双编码器。
交互作用→ 后期互动。为了将交叉编码器提取到代理ColBERT模型中,我们首先类似于相关分数的输出概率分布,其中损失可以定义为

,其中

在这里,我们使用s ce表示交叉编码器教师产生的相关分数。
尽管分数分布,令牌级交互对于后期交互模型(即ColBERT)的学习也至关重要。基于此,我们进一步引入了一个提取令牌级注意力的损失函数,即
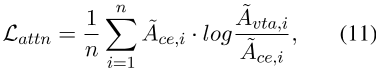
,其中

在这里,ce,i表示通过交叉编码器获得的最终级注意力图,li,i表示由matmul ![]() 计算的ColBERT的后期交互值。下标i表示n个头中的第i个头,l,k分别是查询和通道的长度。
计算的ColBERT的后期交互值。下标i表示n个头中的第i个头,l,k分别是查询和通道的长度。
后期交互→ 度量交互。为了进一步将ColBERT提取到双编码器中,我们采用与交互提取相同的程序,其中损失函数定义为等式(8)。
联合训练。整体级联蒸馏过程见图2。值得注意的是,这两个蒸馏过程是联合训练的的,其中最终损失函数在这里定义为
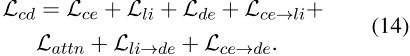
,L ce是标记数据上交叉编码器的监督训练损失,L de和L li分别在等式(6)和(7)中定义。
此外,在等式(14)中,我们还包括交叉编码器到双编码器(表示为![]() ,即
,即
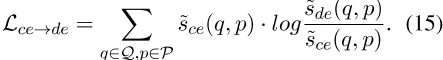
)的一般蒸馏损失。

图2:级联蒸馏的图示。
3.4双重正则化
受之前研究(吴等人,2021;高等人,2021b)的启发,我们还提出了一种正则化方法,即双正则化,用于训练双编码器。特别是,我们首先使用不同的dropout种子对给定的通道进行两次前馈,并获得两个通道表示。接下来,我们将查询表示分别与这两种表示交互,以获得输出分布s̃1 de和s̃2 de,它们被计算为等式(3)。基于此,双重正则化的目标是最小化两个分布之间的双向KL发散。
请注意,这两个输出分布是使用相同的查询表示法计算的。
此外,我们还可以在相互作用蒸馏期间应用双重正则化,即后期相互作用还将输出两个得分分布s̃1 li和s̃2 li。因此,双重正则化的最终损失函数由两个双向KL发散损失组成。
4实验
4.1实验装置
4.1.1数据集
我们在两个流行的开放域QA基准上进行了实验:MSMARCO通道排名(MSMARCO)(Nguyen等人,2016)和自然问题(NQ)(Kwiatkowski等人,2019)。
详细统计数据如表1所示。
4.1.2评估指标
根据之前的工作,我们报告MRR@10, Recall@50, Recall@1000关于MSMARCO的开发集,以及Recall@5, Recall@20和Recall@100在NQ的测试集上。平均倒数排名(MRR)计算重新检索第一个相关文档的秩的倒数。Recall@k (R@k)计算top-k检索到的段落包含正段落的问题的比例。
4.1.3实施细节
模型结构。我们的双编码器和交叉编码器使用ERNIE 2.0(Sun等人,2019)作为编码器,这是一个具有连续预训练框架的transformer。值得注意的是,双编码器应用了带有12层transformers的ERNIE 2.0的基本版本,而交叉编码器使用了带有24层transformers的ERNIE 2.0的大版本。此外,我们还对大型双编码器进行了实验,该编码器利用了具有24亿个参数的12层ERNIE。更多细节见表2。
训练详情。我们采用多步骤训练过程,其中每个步骤中训练的的模型用作下一步的预热模型。详细的训练过程描述如下:•步骤1。在对QA任务进行训练之前,我们首先在通用语料库上结合coCon密度更高的训练(Gao和Callan,2021)设置,通过交互蒸馏对PLM进行连续训练。
•第2步。接下来,我们在下游QA任务上训练一个具有交互蒸馏的双编码器检索器。特别是,训练集由PAIR提供(Ren等人,2021a),其中包括两部分:具有伪标签的未标记增强数据集和具有基本真值标签和伪标签的标记语料库。这一步中的训练过程也遵循配对的对比学习范式。值得注意的是,我们对不同的下游数据集使用不同的设置。对于MSMARCO,我们使用LAMB Optimizer,学习率为1e-5,批量大小为2048。对于自然问题,我们使用ADAM优化器,学习率为3e-5,批量大小为512。
•步骤3。随后,我们采用级联蒸馏来连续训练第2步获得的双编码器。注意,我们使用ERNIE 2.0 large初始化交叉编码器教师。在这一步中,我们首先使用第2步双编码器检索原始训练语料库中每个查询中前256个候选通道,并从前256个候选通道中随机抽取N个负通道和一个正通道。我们在MSMARCO上将N设置为127,在NQ上将N设置为31。对于这两个数据集,我们用16个查询或16×N查询-通道对的批量大小对我们的模型进行2个epochs的训练,使用ADAM优化器将学习率设置为1e-5。
实验环境。这项工作中的所有实现代码都基于深度学习框架飞浆(Ma等人,2019)和AMP(Micikevicius等人,2017)以及重新计算(Chen等人,2016),以减少GPU内存消耗。所有实验均在NVIDIA特斯拉A100 GPU上运行。

表1:MSMARCO和自然问题的详细统计。

表2:实验中使用的预训练语言模型的详细信息。
4.2实验结果
4.2.1通道检索结果
MS-MARCO和NQ检索表现的比较如表3所示。
4.2.2基线
我们将ERNIE搜索与以前考虑稀疏和密集通道检索器的最先进方法进行了比较。
顶部方框显示了稀疏检索器的表现。BM25(Yang等人,2017)是一种基于精确项匹配的传统检索器,DeepCT(Dai和Callan,2019)、doc2query(Nogueira等人,2019c)、DocTTTT-query(Nogueira等人,2019a)、GAR(Mao等人,2020)、COIL(Gao等人,2021a)是利用神经网络的增强方法。doc2query和docttttquery都使用新的查询生成方法来扩展文档。GAR还使用生成方法来扩展查询。DeepCT和COIL利用BERT来学习生成词汇权重或倒排列表。
中间部分显示了密集检索方法的结果。密集检索器包括DPR(Karpukhin等人,2020)、ANCE(Xiong等人,2020)、ME-BERT(Luan等人,2021)、ColBERT(Khattab和Zaharia,2020)、RocketQA(Qu等人,2020)、PAIR(任等人,2021a)、RokeckQAv2(任等人,2021b)、AR2(Zhang等人,2021)、Col-BERTv2(Santhanam等人,2021)。
4.2.3结果
表3的底部显示了ERNIE搜索和ERNIE搜索2的主要实验结果。4 B在MSMARCO和NQ数据集上。我们可以看到,ERNIE搜索可以大大优于基线对和RocketQAv2(检索器)。我们还观察到,ERNIE搜索:使用交互蒸馏和级联蒸馏方法训练的的检索模型达到了最先进的水平MRR@10在MSMARCO的基础版本双编码器和ERNIE搜索2。4 B在MSMARCO和NQ上实现了最先进的表现。ERNIE Search 2的详细信息。附录A.1中描述了4 B。
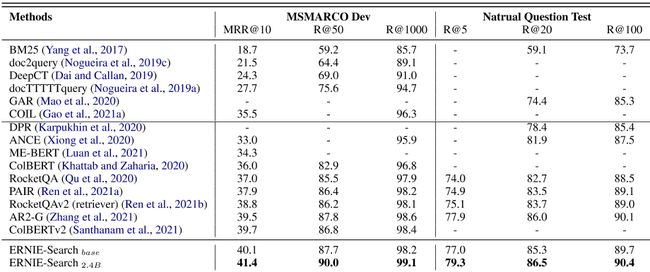
表3:MSMARCO和自然问题数据集的实验结果。我们复制原始论文的结果,如果原始论文中没有报告结果,我们将其留白。每个数据集的最高结果以粗体突出显示。

表4:MSMARCO开发数据集上列车后策略的消融。
4.3详细分析
我们进行了消融研究,详细分析了相互作用蒸馏和级联蒸馏。
4.3.1训练后策略分析
我们通过替换训练后策略中的优化形式来分析检索器的结果。表4显示了消融结果。该表中的所有实验均为无级联蒸馏阶段的训练。Vanilla Post-Train策略是指coCon-denser训练,Vanilla Finetune策略是指具有配对数据集的DPR训练,CB是指RocketQA中提出的跨批方法,ID是指应用交互蒸馏方法,其中蒸馏仅在本地GPU中的样本上进行,ID表示在CB策略下对从所有GPU收集的所有样本应用交互蒸馏方法,DualReg表示双重调节方法。我们首先实施普通的列车后策略(#1),以消除列车后的影响(#1与ERNIE2.0)。然后,我们在vanilla训练后模型(#2)上实验了微调策略,以消除微调策略的影响。最后,我们实现了具有ID的后期训练。实验结果表明,具有ID的后期训练可以改善MRR@10和R@1000指标(3对2)。
4.3.2相互作用蒸馏分析
在本节中,我们通过逐个逐步添加策略来分析交互蒸馏的结果。
表5显示了相互作用蒸馏的所有消融实验结果。此表中的所有模型均使用ID Post Train模型初始化。ID、CB、DualReg和ID的含义见第4.3.1节。结果表明,ID(#2 vs.1)、ID(#5 vs.4)、CB(#3 vs.2)和DualReg(#4 vs.3)都能带来改善。注意,双重注册带来0.31的好处MRR@10,但它R@50和R@1000分别略微下降了0.20和0.03(4比3)。ID、CB和DualReg的组合在所有三个指标上都获得了最大的好处。
4.3.3级联精馏分析
在本节中,我们分析了级联蒸馏的结果。我们对等式14中四种损失的不同组合进行了消融研究(硬标签交叉熵的三种损失除外)。
表6显示了检索器在级联蒸馏上的所有消融实验结果。我们可以看到,联合使用所有损失可以获得最佳性能。当烧蚀其中一个或多个损失时,回收器的性能较差,这表明级联蒸馏从所有损失中受益。
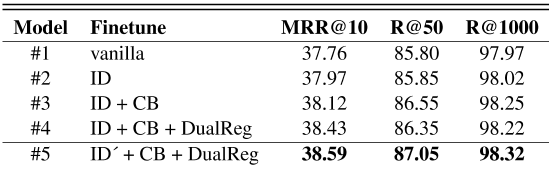
表5:MSMARCO开发数据集上交互蒸馏的消融。

表6:MSMARCO开发数据集上级联蒸馏的消融。
5结论
在本文中,我们提出了一种新的解决方案,该解决方案推进了开放域QA的跨架构蒸馏。特别是,我们提出了两种提取方法,即交互蒸馏和级联蒸馏,它们显著提高了双编码器作为检索器的有效性。我们在几个开放域QA基准上进行了大量实验,结果表明我们提出的解决方案达到了最先进的性能。我们期望这项工作能够激发更多关于跨架构蒸馏过程中不同交互方案之间关系的研究。
致谢
参考文献
Wei-Cheng Chang, Felix X Yu, Yin-Wen Chang, Yiming Yang, and Sanjiv Kumar. 2020. Pre- training tasks for embedding-based large-scale re- trieval. arXiv preprint arXiv:2002.03932.
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174.
Jaekeol Choi, Euna Jung, Jangwon Suh, and Won- jong Rhee. 2021. Improving bi-encoder document ranking models with two rankers and multi- teacher distillation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2192–2196.
Zhuyun Dai and Jamie Callan. 2019. Deeper text understanding for ir with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 985–988.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understand- ing. arXiv preprint arXiv:1810.04805. Luyu Gao and Jamie Callan. 2021. Unsupervised corpus aware language model pre-training for dense passage retrieval. arXiv preprint arXiv:2108.05540.
Luyu Gao, Zhuyun Dai, and Jamie Callan. 2021a. Coil: Revisit exact lexical match in information retrieval with contextualized inverted list. arXiv preprint arXiv:2104.07186.
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021b. Simcse: Simple contrastive learning of sentence em- beddings. arXiv preprint arXiv:2104.08821.
Jiafeng Guo, Yinqiong Cai, Yixing Fan, Fei Sun, Ruqing Zhang, and Xueqi Cheng. 2021. Semantic models for the first-stage retrieval: A comprehensive review. arXiv preprint arXiv:2103.04831.
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv:2006.03654.
Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2(7).
Sebastian Hofstätter, Sophia Althammer, Michael Schröder, Mete Sertkan, and Allan Hanbury. 2020. Improving efficient neural ranking models with cross-architecture knowledge distillation. arXiv preprint arXiv:2010.02666.
Sebastian Hofstätter, Sheng-Chieh Lin, Jheng-Hong Yang, Jimmy Lin, and Allan Hanbury. 2021. efficiently teaching an effective dense retriever with balanced topic aware sampling. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 113–122.
Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. 2019. Poly-encoders: transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring. arXiv preprint arXiv:1905.01969.
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2019. Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351.
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
Omar Khattab and Matei Zaharia. 2020. Colbert: efficient and effective passage search via contextual- ized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a bench- mark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent retrieval for weakly supervised open domain question answering. arXiv preprint arXiv:1906.00300.
Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. 2020. Distilling dense representations for rank- ing using tightly-coupled teachers. arXiv preprint arXiv:2010.11386.
Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. 2021. In-batch negatives for knowledge distillation with tightly-coupled teachers for dense retrieval. In Proceedings of the 6th Workshop on Representation Learning for NLP (RepL4NLP-2021), pages 163– 173.
Yiding Liu, Weixue Lu, Suqi Cheng, Daiting Shi, Shuaiqiang Wang, Zhicong Cheng, and Dawei Yin. 2021. Pre-trained language model for web-scale retrieval in baidu search. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 3365–3375.
Yi Luan, Jacob Eisenstein, Kristina Toutanova, and Michael Collins. 2021. Sparse, dense, and atten- tional representations for text retrieval. Transactions of the Association for Computational Linguistics, 9:329–345.
Yanjun Ma, Dianhai Yu, Tian Wu, and Haifeng Wang. 2019. Paddlepaddle: An open-source deep learning platform from industrial practice. Frontiers of Data and Domputing, 1(1):105–115.
Yuning Mao, Pengcheng He, Xiaodong Liu, Ye- long Shen, Jianfeng Gao, Jiawei Han, and Weizhu Chen. 2020. Generation-augmented retrieval for open-domain question answering. arXiv preprint arXiv:2009.08553.
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. 2017. Mixed precision training. arXiv preprint arXiv:1710.03740.
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. Ms marco: A human generated machine reading comprehension dataset. In CoCo@ NIPS.
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gus- tavo Hernández Ábrego, Ji Ma, Vincent Y Zhao, Yi Luan, Keith B Hall, Ming-Wei Chang, et al. 2021. Large dual encoders are generalizable retriev- ers. arXiv preprint arXiv:2112.07899.
Rodrigo Nogueira and Kyunghyun Cho. 2019. passage re-ranking with bert. arXiv preprint arXiv:1901.04085. Rodrigo Nogueira, Jimmy Lin, and AI Epistemic. 2019a. From doc2query to doctttttquery. Online preprint, 6.
Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. 2019b. Multi-stage document ranking with bert. arXiv preprint arXiv:1910.14424.
Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. 2019c. Document expansion by query prediction. arXiv preprint arXiv:1904.08375.
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. 2020. Rocketqa: An opti- mized training approach to dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2010.08191.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text trans- former.
arXiv preprint arXiv:1910.10683.
Nils Reimers and Iryna Gurevych. 2019. Sentence- bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10084.
Nils Reimers and Iryna Gurevych. 2020. The curse of dense low-dimensional information retrieval for large index sizes. arXiv preprint arXiv:2012.14210. Ruiyang Ren, Shangwen Lv, Yingqi Qu, Jing Liu, Wayne Xin Zhao, QiaoQiao She, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2021a. Pair: Lever- aging passage-centric similarity relation for improving dense passage retrieval. arXiv preprint arXiv:2108.06027.
Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, Qiaoqiao She, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2021b. Rocketqav2: A joint training method for dense passage retrieval and passage re-ranking.
arXiv preprint arXiv:2110.07367.
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2021. Col- bertv2: Effective and efficient retrieval via lightweight late interaction. arXiv preprint arXiv:2112.01488.
Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, et al. 2021. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137.
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. 2019. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
Kexin Wang, Nandan Thakur, Nils Reimers, and Iryna Gurevych. 2021. Gpl: Generative pseudo label- ing for unsupervised domain adaptation of dense re- trieval. arXiv preprint arXiv:2112.07577.
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers. Advances in Neural Information Processing Systems, 33:5776–5788. Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, Min Zhang, Tie-Yan Liu, et al. 2021. R-drop: regularized dropout for neural net- works. Advances in Neural Information Processing Systems, 34.
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. 2020. Approximate nearest neighbor negative contrastive learning for dense text retrieval.
arXiv preprint arXiv:2007.00808. Peilin Yang, Hui Fang, and Jimmy Lin. 2017. Anserini: Enabling the use of lucene for information re- trieval research. In Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval, pages 1253–1256.
Shuo Yang, Le Hou, Xiaodan Song, Qiang Liu, and Denny Zhou. 2021. Speeding up deep model training by sharing weights and then unsharing. arXiv preprint arXiv:2110.03848.
Sohee Yang and Minjoon Seo. 2020. Is retriever merely an approximator of reader? arXiv preprint arXiv:2010.10999.
Yinfei Yang, Ning Jin, Kuo Lin, Mandy Guo, and Daniel Cer. 2020. Neural retrieval for question answering with cross-attention supervised data aug- mentation. arXiv preprint arXiv:2009.13815. Wenwen Ye, Yiding Liu, Lixin Zou, Hengyi Cai, Suqi Cheng, Shuaiqiang Wang, and Dawei Yin. 2022. Fast semantic matching via flexible contextualized interaction. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, pages 1275–1283.
Hang Zhang, Yeyun Gong, Yelong Shen, Jiancheng Lv, Nan Duan, and Weizhu Chen. 2021. Adversar- ial retriever-ranker for dense text retrieval. arXiv preprint arXiv:2110.03611.
A附录
A.1 扩展到24亿个参数
一方面,较大的预训练语言模型在许多任务上显示出更好的表现(Raf-fel等人,2019;He等人,2020;Sun等人,2021)。
另一方面,(Reimers和Gurevych,2020)提出,增加索引维度通常会为密集检索器带来更好的表现。在此基础上,我们推测具有相似参数的密集检索器,在合理范围内增加隐藏大小优于层数。我们将在未来的工作中留下这方面的证明和实验。我们构建了具有24亿个参数的ERNIE搜索的更大版本,表示为ERNIE搜索2。4 B,由12个隐藏尺寸为4096和64个注意力头的层transformer编码器组成。我们选择这样的模型架构,而不是像DeBERTa 1那样具有更多层和更小隐藏大小的架构。5 B(48个层,1536个隐藏大小)(He等人,2020),用于更好的检索任务表现。
厄尼搜索2的训练过程。4 B描述如下。我们使用具有跨层参数共享的ALBERT xxlarge(Lan等人,2019)作为初始化模型。我们首先通过简单复制参数来取消共享参数(Yang等人,2021)。然后,我们遵循(Sun等人,2019)中的实验,持续预训练非共享模型,以获得ERNIE 2。4 B。
随后,我们对ERNIE 2进行后期训练和微调。4 B采用本文提出的交互蒸馏和级联分解方法得到ERNIE搜索2。4 B。
表3和表7中的结果表明,ERNIE搜索2。与全球技术法规XXL(Ni等人,2021)48亿个参数相比,4 B得到了显著改进,并在MSMARCO开发和NQ测试方面达到了最新水平。

表7:大型模型MSMARCO的实验结果。