python空气质量分析与预测_AQI(空气质量指数)分析与预测(一)
任务说明
期望能够运用数据分析的相关技术,对全国城市空气质量进行研究与分析,希望能够解决如下疑问:
哪些城市的空气质量较好/较差?【描述性统计分析】
空气质量在地理位置上,是否具有一定的规律?【描述性统计分析】
临海城市的空气质量是否有别于内陆城市?【推断统计分析】
空气质量主要受哪些因素影响?【相关系数分析】
全国城市空气质量普遍处于何种水平?【区间估计】
怎样预测一个城市的空气质量?【统计建模】
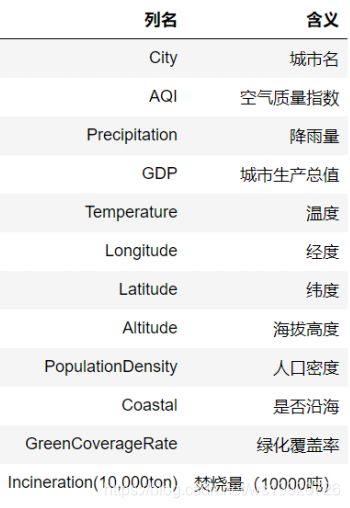
数据集描述
我们获取了2015年空气质量数据集,该数据集包含全国主要城市的相关数据以及空气质量指数。
读取数据
导入需要的库,同时进行一些初始化的设置
#导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
sns.set(style='darkgrid')
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')
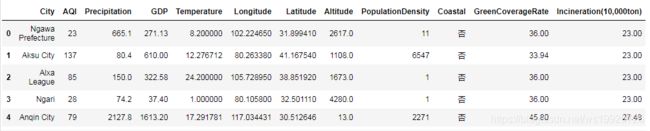
加载数据集
#加载之后可以使用head/tail/sample等方法查看数据的大致情况
data = pd.read_csv('data.csv')
data.head()
数据清洗
缺失值
1 缺失值探索
我们可以使用如下方法查看缺失值:
info
isnull
data.info()

data.isnull().sum(axis=0) #按列查找空值,并将空值累加
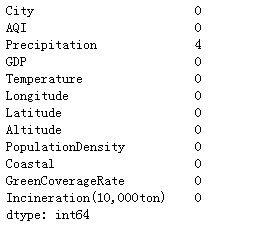
如上两种方式都可以看出,Precipitation列中有四个空值
2 缺失值处理
对于缺失值,我们可以使用如下方式处理:
删除缺失值
仅适用于缺失数量很少的情况
填充缺失值
1 数值变量
▷均值填充
▷中位数填充
2 类别变量
▷众数填充
▷单独作为一个类别
3 额外处理说明
▷缺失值小于20%,直接填充
▷缺失值在20%-80%,填充变量后,同时增加一列,标记该列是否缺失,方便参与后续建模
▷缺失值大于80%,不使用原始列,而是增加一列,标记该列是否缺失,方便参与后续建模
#查看数据分布情况
print(data['Precipitation'].skew()) #查看偏度值,确认左偏或右偏
![]()
偏度值大于0,轻微右偏
sns.distplot(data['Precipitation'].dropna())
#distplot中不允许有空值,故使用dropna函数将空值去除
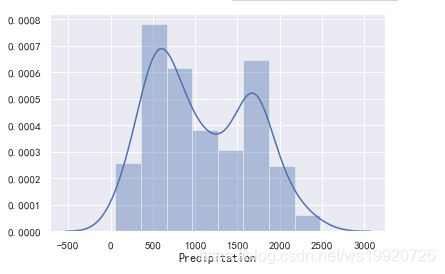
根据偏度值及图像可知,数据呈右偏分布,故使用中位数填充,代码如下:
data['Precipitation'].fillna(data[].median(), inplace=True)
异常值
1 异常值探索
我们可以使用如下方式,发现异常值:
通过describe查看数值信息
3σ方式
使用箱线图辅助
相关异常检测算法
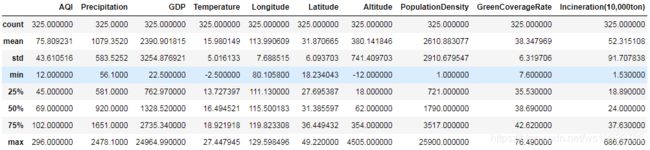
describe方法
调用DataFrame对象的describe方法,可以显示数据的统计信息,不过此种方法仅能作为一种简单的异常探索方式。
data.describe()
3σ方法
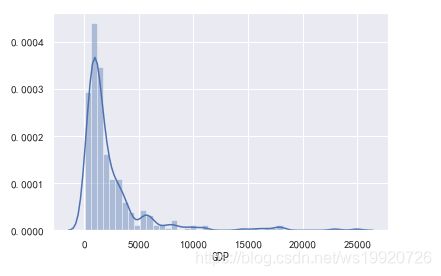
根据正态分布的特性,我们可以将3σ之外的数据,视为异常值。我们以GDP为例,首先绘制GDP的分布。
sns.distplot(data['GDP'])
print(data['GDP'].skew()) #偏度值
![]()
可以看出此列呈严重的右偏分布,也就是存在部分极大的异常值,可以获取这些异常值。
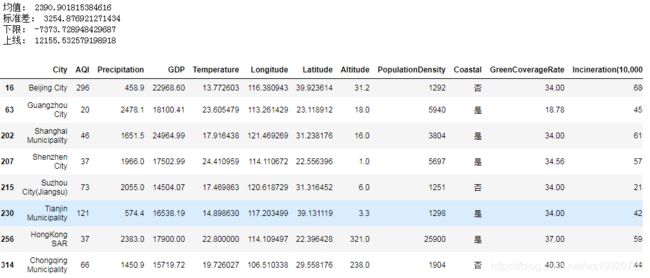
mean, std = data['GDP'].mean(), data['GDP'].std()
lower, upper = mean-3*std, mean+3*std
print('均值:',mean)
print('标准差:',std)
print('下限:',lower)
print('上限:',upper)
data[(data['GDP']upper)] #获取全部异常信息
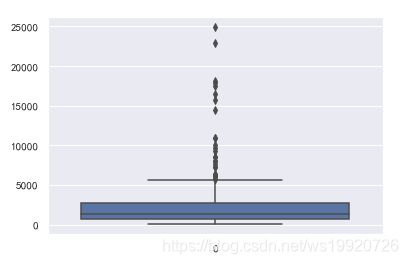
箱线图
箱线图是一种常见的异常检测方式。
sns.boxplot(data=data['GDP'])
2 异常值处理
对于异常值,我们可以采用如下的方式处理:
删除异常值
视为缺失值处理
对数转换
使用临界值填充
使用分箱法离散化处理
对数转换
如果数据中存在较大的异常值,我们可以通过取对数来进行转换,这样可以得到一定的缓解。例如,GDP变量呈现右偏分布,我们可以进行取对数转换。
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(15, 5)
sns.distplot(data['GDP'], ax=ax[0])
sns.distplot(np.log(data['GDP']), ax=ax[1])
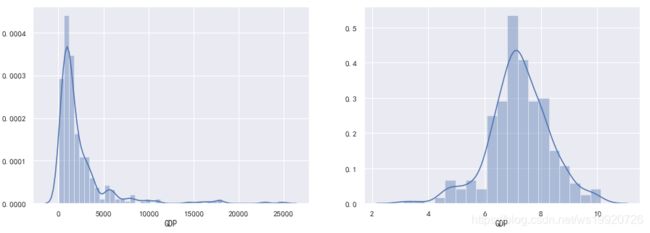
取对数的方式比较简单,不过也存在一些局限:
取对数只能针对正数操作,不过我们可以通过如下的方式进行转换:
np.sign(X) * np.log(np.abs(X)+1)
适合于右偏分布,不适合左偏分布
使用边界值替换
我们可以对异常值进行“截断”处理,即使用临界值替换异常值。例如:在3σ与箱线图中,就可以这样处理。
分箱离散化
有时候,特征对目标值存在一定的影响,但是这种影响可能未必是线性的增加,此时我们就可以使用分箱方式,对特征进行离散化处理。
重复值
1 重复值探索
使用duplicate检查重复值,可配合keep参数进行调整。
#发现重复值
print(data.duplicated().sum())
#查看哪些记录出现了重复值
data[data.duplicated(keep=False)] #显示所有重复值

2 重复值处理
重复值对数据分析通常没用,直接删除即可。
data.drop_duplicates(inplace=True) #删除重复值
data.duplicated().sum() #检验重复值是否成功删除
![]()