[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction
DeepReflect: Discovering Malicious Functionality through Binary Reconstruction [USENIX 2021]
Evan Downing Georgia Institute of Technology
Yisroel Mirsky Georgia Institute of Technology & Ben-Gurion University
Kyuhong Park Georgia Institute of Technology
Wenke Lee Georgia Institute of Technology
深度学习在恶意软件分类方面显示出有前景的结果。然而为了识别关键的恶意行为,恶意软件分析师仍然需要使用静态分析工具对未知的恶意软件二进制文件进行逆向工程。尽管机器学习可以用来帮助识别二进制文件的重要部分,但由于获取足够大的标记数据集的开销较高,有监督学习的方法是不切实际的。
为了提高静态(或手动)逆向工程的生产力,我们提出了DEEPREFLECT: 一种用于在恶意二进制文件中定位和识别恶意软件组件的工具。为了定位恶意软件组件,我们以一种新颖的方式使用无监督深度神经网络,并通过半监督聚类分析对组件进行分类,分析人员在他们的日常工作流程中逐步提供标签。该工具是实用的,因为它不需要数据标记来训练定位模型,并且 以最小/非侵害的 标记来增量训练分类器。
在我们与5名恶意软件分析师对26k个恶意软件样本的评估中,发现DEEPREFLECT平均减少了分析师平均 85% 逆向工程所需工作量。同时该方法还检测到80%的恶意软件组件,而使用基于签名的工具(CAPA)时只能检测43%。此外,DEEPREFLECT 与 SHAP(一种AI解释工具)的性能更好。
一句话: DEEPREFLECT: 一种用非监督学习神经网络做二进制文件中恶意组件的定位和识别的方法
开源地址: https://github.com/evandowning/deepreflect
导论
Motivations
(1) 安全公司每周会收到5百万个病毒样本, 预先对样本进行分类可以降低病毒分析的工作量.
(2) 现有的方法包括创建签名, 分类, 聚类等, 然而这些解决方案只预测样本的类别(例如,良性vs恶意,或一个特定的恶意软件家族)。他们无法定位或解释恶意软件样本本身的行为。
(3) 恶意代码分析者在实践中的工具需要两类功能: 1.定位恶意函数位置, 2.给恶意函数打标签
Challenges
(1) 区分良性的和恶意的软件是困难的,因为恶意软件和良性软件的行为经常在很高的程度上重叠。
(2) 自动标记和验证这些行为是困难的,因为没有单独标记恶意软件功能的数据集(不像恶意软件检测和分类系统使用开放的数据集)
Contributions
DEEPREFLECT的贡献主要有
(1) 使用一种无监督深度学习模型,可以在二进制文件中定位恶意函数
(2) 使用半监督聚类模型,通过很少的标签对识别的函数进行分类 (标签来源于分析者平时的工作流
为了定位二进制文件中的恶意软件组件,我们使用自动编码器(AE)。我们的直觉是,如果我们在良性二进制上训练AE,它将很难重构恶意二进制,特别是很难重构二进制中的恶意代码部分。因此重构误差可以用来识别恶意软件中的恶意组件。
为了对所定位的恶意软件组件进行分类,(1)对恶意软件样本中所有已识别的功能进行聚类,(2)使用分析师在其日常工作流程中所做的注释对集群进行标记。
无监督AE无需训练或使用半监督聚类模型,为恶意软件分析人员提供了直接的帮助,因为 (1) 通过对相关函数的重构错误进行排序,将分析人员的注意力吸引到关键函数上,(2) 过滤掉分析人员可能需要花费数小时甚至数天来解释的函数。
(3) 提出一种将机器学习应用到静态分析的新方法: 无监督学习做模型训练, 半监督学习做分类任务.
(4) 通过使用可以映射回原始二进制或控制流图的局部特征, 提出了一种使用解释框架定位恶意软件重要部分的方法
方案
Analyst Workflow
真实世界的恶意样本分析工作流程如图所示, 分析师得到一个恶意样本, 会首先进行文件扫描查看是否是已经存在于病毒库中, 如果存在则结束分析工作, 否则会用自定的沙箱执行该样本查看样本行为, 如果样本没有反沙箱机制则可以观察到恶意行为, 那么此时可以给该样本创建标签并加入数据库中, 如果恶意样本有反沙箱机制则不会观察到恶意行为, 需要人工进行静态逆向工程分析样本的功能.
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第1张图片](http://img.e-com-net.com/image/info8/33ecbcb7756b401a80d79142700b856e.jpg)
Proposed Solutions
恶意样本分析师通常会通过搜索特定字符串和API来识别函数行为, 但是这些特征在恶意软件中可以轻易被隐藏. DEEPREFLECT则是通过控制流图(CFG)特性和API调用的组合来识别这些相同的行为。
DEEPREFLECT通过学习正常情况下的良性二进制函数的样子来工作。因此,任何异常都表明这些功能没有出现在良性的二进制文件中,可能被用于促进恶意行为。
预期实现的目标:
(G1)准确识别恶意软件样本中的恶意活动
(G2)在静态分析恶意软件样本时集中分析人员的注意力
(G3)处理新的恶意软件家族
(G4)洞察恶意软件家族关系和趋势
Threat Model
(1) 假设进入系统的恶意软件已经脱壳
(2) 假设我们可以可靠地拆卸恶意软件,以提取基本的块和功能。
(3) 我们相信我们的机器学习模型和数据集是可靠的(攻击者不会主动试图攻击或阻碍我们的系统)。
Design
DEEPREFLECT的目标是识别恶意软件二进制文件中的恶意函数. 通过定位异常的基本块(regions of interest - RoI)来识别可能是恶意的函数。然后,分析人员必须确定这些函数表现出的行为是恶意的还是良性的。有两个主要步骤,(1)RoI检测和(2)RoI注释。RoI检测是使用自动编码器执行的,而注释是通过对每个功能的所有RoI进行聚类并对这些聚类进行标记来执行的。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第2张图片](http://img.e-com-net.com/image/info8/cd04eac083894c4fb641c3f4e2e70a3c.jpg)
首先定义什么是“恶意行为”。基于识别恶意软件源代码的核心组件(例如,拒绝服务功能、垃圾邮件功能、键盘记录器功能、命令与控制(C&C)功能、利用远程服务等)来生成ground truth。
这些很容易用MITRE ATT&CK框架来描述[9],该框架旨在标准化这些行为的术语和描述。只是MITRE框架有局限性, 在某些样本中有时不能将观察到的低级函数归为这些高级描述。所以本系统只考虑可以由MITRE框架描述的恶意函数.
RoI检测
检测的目标是自动识别恶意软件二进制文件中的恶意区域。例如希望检测C&C逻辑的位置,而不是检测该逻辑的特定组件(网络API调用connect()、send()和recv()等)。RoI检测的优点是,分析人员可以快速地找到负责启动和操作恶意行为的特定代码区域。之前的工作只专注于创建专门的签名,简单地将二进制文件识别为恶意软件或仅基于API调用的一些功能。
自动编码器是一个神经网络 M M M,它由一个编码器 E n ( x ) En(x) En(x)和一个解码器 D e ( e ) De(e) De(e)组成,前者将输入的 x x x压缩为编码 e e e,后者从给定的 e e e重构 x x x。
在像[43]的工作中,已经证明当在良性分布上训练时,自动编码器可以检测到恶意(异常)行为。当处理恶意样本时 M M M将无法重构 x x x中的特征,因为 M M M需要恶意的概念/模式。
给定样本的重构 M ( x ) = x ^ M(x) = \widehat{x} M(x)=x ,通常通过计算均方误差(MSE)并检查结果标量是否高于给定阈值 φ φ φ来识别恶意样本。
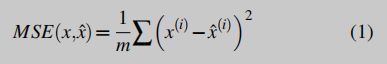
假设恶意软件的二进制文件与良性二进制文件相比包含类似但独特的功能。根据这种直觉,我们在一个代表各种行为和功能的多样的良性数据集上训练M。与以前的工作相比,识别整个样本是恶意的,我们识别每个样本中的恶意区域。准确来说需要计算局域MSE (localized MSE)
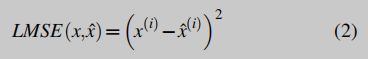
然后对得到的向量施加阈值 φ φ φ,以识别 M M M无法识别或理解的模式。每一个平方误差超过这个阈值的区域的集合用 R x R_x Rx来表示
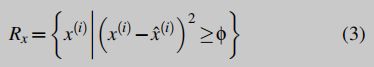
使用的特征必须1对1地映射到原始样本中(准确定位RoI)。因此,我们将每个二进制表示为 m × c m × c m×c矩阵,该矩阵使用 c c c特征捕获前 m m m个基本块来总结它们的每个活动。
c c c特征的灵感来自于之前的工作,即属性控制流图(ACFG)特征[23,75]。在这些工作中,选择ACFG特征来执行二进制相似性分析,因为他们假设这些特征(由结构和数值CFG特征组成)将在多个平台和编译器中保持一致。
我们的特征包括每个基本块中的指令类型的计数(为ACFG特征提取的指令类型的更详细形式)、CFG的结构特征和API调用的类别(用于总结恶意软件程序行为[18])。
在DEEPREFLECT中,我们将m设置为前20k个基本块 (因为95%的数据集样本有20k或更少的基本块)。设c为18个特征,概括每个基本块如下:
-
结构特点。我们使用的结构特征是每个基本块的子代数量和中间值。这些特征可以表示通常用于网络通信(例如连接、发送、recv)和文件加密(例如查找文件、打开、读取、加密、写、关闭)等操作的控制流结构。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第3张图片](http://img.e-com-net.com/image/info8/94510fd9ed18480581fe91eab2fdb847.jpg)
-
算术指令。我们使用的算术指令特性是每个基本块中包含的“基本数学”、“逻辑运算”和“位移位”指令的数量。这些特征可以用来表示数学运算是如何为更高层次的行为执行的。它们说明了函数如何与数字交互(例如,加密函数可能包含大量异或指令,混淆函数可能包含逻辑和位移位操作的组合,等等)。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第4张图片](http://img.e-com-net.com/image/info8/d7434cab7c154aa1b23276f6fe15c45e.jpg)
-
转移指令。我们使用的传输指令特性是每个基本块中的“堆栈操作”、“寄存器操作”和“端口操作”指令的数量。这些特征可以用来表示传输操作是如何为更高级别的行为执行的。它们说明了提供给函数的参数(以及从函数调用返回的值)如何与该函数中的其他数据交互。它可以表示复杂的逻辑和数据操作(例如,去混淆/解密可能涉及更多与移动相关的指令,而C&C逻辑将涉及更多与堆栈相关的指令,因为它调用更多的内部/外部函数)。
-
API调用类别。我们使用的API调用特性是每个基本块中与“文件系统”、“注册表”、“网络”、“DLL”、“对象”、“进程”、“服务”、“同步”、“系统信息”和“时间”相关的API调用的数量。这些分类的灵感来自于之前对恶意软件集群[18]的研究。这些特性可以用来表示执行恶意活动所需的高级库操作,如网络通信和文件系统、注册表和进程操作。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第5张图片](http://img.e-com-net.com/image/info8/331ce5707f8242fbbb4d756e0dc35377.jpg)
RoI注释
注释的目标是自动标记包含RoI的函数的行为。换句话说,管道的这一部分确定了恶意功能在做什么。分析师为标记集群所执行的初始工作是长尾分布。前面的工作相对重要,但随着他们继续为每个集群标记,工作量会减少。这个过程的优点很简单:它为分析人员提供了一种自动生成关于(未见)样本的报告和见解的方法。
设 x x x是从一组未打包的恶意软件中提取的特征。设 F F F是用BinaryNinja找到的 x x x中的函数集。对于每个 f i ∈ F f_i \in F fi∈F,我们将 f i f_i fi中的RoI表示为 q i q_i qi,其中 q i ⊂ R x q_i \subset R_x qi⊂Rx。创建聚类数据集的过程: 对每一个给定的恶意样本 x i x_i xi, 对于每一个 q i ≠ ∅ q_i \neq \varnothing qi=∅, 将 f i f_i fi的行为总结为 1 ∣ q i ∣ Σ q i \frac{1}{|q_i|}\Sigma q_i ∣qi∣1Σqi然后添加到集合 D D D中.
要将D中的函数聚类,首先将维数从18降至5,用主成分分析(PCA)来进行约简。接下来,我们使用HDBSCAN[6]聚类约简向量. (HDBSCAN是基于密度的聚类算法DBSCAN的变体, 可以识别非凸聚类(不像k-means)和自动选择簇密度的最佳超参数.
实验
对DEEPREFLECT的 (1)可靠性进行评估,方法是将其运行在我们编译的三个真实的恶意软件样本上,并将其与机器学习分类器、基于签名的解决方案和函数相似度工具进行比较; (2)内聚性,方法是让恶意软件分析师随机抽样并标记在野样本中识别的功能,并比较DEEPREFLECT如何将这些功能聚在一起。(3)聚焦, 通过计算分析人员在给定整个恶意软件二进制代码时逆向工程的函数量来评估; (4)见解, 通过观察共享相同函数的不同恶意软件家族以及DEEPREFLECT如何处理新传入的恶意软件家族来评估; (5)鲁棒性, 通过混淆和修改恶意软件的源代码来试图规避DEEPREFLECT以评估鲁棒性。
Dataset
良性数据集
从 CNET [4] 定义的22类文件中收集60261个PE文件, 使用Unipacker [11]进行脱壳, 排除掉脱壳失败的文件, 然后筛选出良性文件, 得到文件数据集总共23307个文件. 如Table 1所示.
恶意数据集
从VirusTotal [12] 收集64245个恶意PE文件, 然后用AVClass [62]获取恶意软件家族的标签信息, 接着Unipacker脱壳, 最后筛选出36396个恶意软件, 总共4407类家族. 最多的10个家族如Table 2所示.
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第6张图片](http://img.e-com-net.com/image/info8/98a331f44d79495db6e0ec4b53203757.jpg)
Evaluation Reliability
探索并对比在二进制文件中定位恶意软件组件时模型的性能。
Baseline
与用于定位样本中概念的通用方法和特定领域的方法进行比较: (1)SHAP(分类模型解释工具[40]),(2)CAPA [3] (FireEye的基于签名的工具,用于识别二进制文件中的恶意行为),和(3)FunctionSimSearch [5] (函数相似工具)。
对比实验
DEEPREFLECT vs SHAP。SHAP的目标是识别模型输入中影响模型分类决策的区域。虽然恶意软件分类器单独为分析人员提供输入的恶意软件家族,但SHAP将识别输入的最重要区域在哪里。因此它可以用来识别不同恶意软件家族和良性软件之间的区别。然而这可能不是高效的。每当发现一类新的恶意软件时,分析人员就必须不断地重新训练模型,而由于其递归算法(在神经网络中来回进行多次传递),SHAP本身很慢。DEEPREFLECT利用无监督学习,只需要通过一次神经网络就可以检索模型的输出,从而克服了这些问题。
DEEPREFLECT vs CAPA。CAPA [3] 是一个静态识别可执行程序中的功能的工具。它通过使用描述各种行为的签名来实现。例如,“连接到HTTP服务器”,“创建进程”,“写文件”等。由于CAPA是基于签名的,由于缺乏通用性,它有可能错过恶意行为,而DEEPREFLECT是使用无监督学习训练的,不存在这种限制。
DEEPREFLECT vs FunctionSimSearch。FunctionSimSearch是谷歌Project Zero[5]开发的功能相似度工具。我们用默认参数从数据集中训练一个良性函数数据库。在用我们的良性数据集训练他们的工具之后,我们用我们的地面真相数据集中的函数来查询它。我们指定该工具输出最常见的前1000个函数及其相似性分数。为了使用它作为异常检测器,我们预计不熟悉的函数(即恶意函数)的相似度分数将显著小于熟悉的函数。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第7张图片](http://img.e-com-net.com/image/info8/1bcb677d0933436a90a45d530459383d.jpg)
实验证明,DEEPREFLECT中的自动编码器定位方法通过识别二进制文件中的恶意行为实现了目标G1(准确识别恶意软件样本中的恶意活动)和G3(处理新的恶意软件家族),而无需对恶意软件样本或标记数据进行训练。此外,我们还证明了它优于流行的解释框架(SHAP)和基于签名的方法(CAPA)。最重要的是,DEEPREFLECT比SHAP(更慢,需要标记数据集)和CAPA(基于签名的解决方案)更实用,因为该模型不需要让专家为恶意软件或其组件标记的昂贵过程。
Evaluation Cohesiveness
为了评估DEEPREFLECT对由AE识别的恶意软件组件进行分类的能力,我们在5名经验丰富的恶意软件分析师的帮助下探索了半监督聚类模型的质量。
对于大量恶意软件样本函数的聚类,我们希望将FPR保持在5%的低水平(在工业和现实环境中,较低的FPR通常比TPR更有价值)。使用DEEPREFLECT来提取和聚类识别的函数。在对函数特征向量运行PCA之后,HDBSCAN使用默认的超参数生成了22469个集群。最大的集群包含6321个函数,最小的只有5个。共有59340个噪声点。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第8张图片](http://img.e-com-net.com/image/info8/317a77d9e8854328b1d5680f04447246.jpg)
在聚类可信度方面, 作者邀请5名经验丰富的分析师进行人工聚类恶意函数, 然后与DEEPREFLECT的结果进行对比.
尽管存在一些聚类错误,但有89.7%的分析师手工聚类函数与我们的工具创建的函数匹配。因此我们认为聚类结果是可信的。将来,HDBSCAN的参数可以通过调整来纠正这些差异。
Evaluation Focus
DEEPREFLECT的好处是它能够集中恶意软件分析人员的注意力,而不是让他们盲目地在每个二进制文件中的函数中搜索。DEEPREFLECT对于每个恶意软件二进制文件计算高亮显示的函数占所有恶意软件功能的百分比,分析假阳性和DEEPREFLECT潜在的排序方案,以优先考虑分析人员应该首先查看的高亮函数, 讨论假阴性以及如何在未来降低它.
减少工作量
对于每个恶意软件样本,我们提取了自动编码器发现的至少包含一个RoI的每个函数,并将其与二进制文件中内部函数的总数进行比较。如图5所示,大部分高亮显示的函数将分析人员需要查看的函数数量减少了至少90%。最小减少量为0%(即,所有功能都突出显示),最大减少量超过99.9999%,平均减少量为85%。满足目标G2(在静态分析恶意软件样本时集中分析人员的注意力)
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第9张图片](http://img.e-com-net.com/image/info8/0195cfe7fd194b6db57b87e0e83ba906.jpg)
Evaluation Insight
为了评估DEEPREFLECT是否为恶意软件家族及其行为的关系提供了有意义的见解,我们探索了集群多样性。Figure 4的左侧绘制了c中每个集群的不同族的数量。可以看出,族之间有许多共享的恶意软件技术和变体。
![[论文笔记] DeepReflect: Discovering Malicious Functionality through Binary Reconstruction_第10张图片](http://img.e-com-net.com/image/info8/bd00df28a87b4f9cb6ccfb2fd8bcd967.jpg)
为了检查DEEPREFLECT是否可以识别单例样本中的恶意函数,我们观察了数据集中的任何单例样本是否与其他恶意软件家族聚集在一起。事实上,我们发现DEEPREFLECT识别了1763个包含至少一个单例样本的集群。
我们发现DEEPREFLECT可以洞察恶意软件行为之间的关系, 满足目标G4(洞察恶意软件家族关系和趋势)。在部署中,此元信息可以与已识别的组件相关联,为分析人员提供即时的见解。
Evaluation Robustness
针对混淆的代码进行DEEPREFLECT鲁棒性评估
基于ollvm,我们使用五种技术来模糊rbot样本的源代码:(A)控制流扁平化,(B)指令替换,(C) 伪控制流,(D)组合技术(A) & (B),和(E)组合技术(B) & (C)。
Mimicry-like Attack
在恶意函数中插入良性代码进行模仿攻击, 该方法被用作测试抗混淆能力[10]的基准(通过插入良性代码来逃避检测). 但是DEEPREFLECT基本不受模仿攻击的影响, 大部分MSE结果在插入良性代码前后变化不大, 只在少部分结果上具有显著差异. 实验展示了攻击者面临的困难:并不是任何良性代码都可以插入恶意函数以躲避攻击。
总结
Related Works
[3] Capa. https://github.com/fireeye/capa.
[5] Functionsimsearch. https://github.com/googleprojectzero/functionsimsearch.
[9] Mitre att&ck. https://attack.mitre.org/versions/v7/matrices/enterprise/windows/.
[10] Obfuscation benchmarks. https://github.com/tum-i4/obfuscation-benchmarks.
[11] unipacker: Automatic and platform-independent unpacker for windows binaries based on emulation. https://github.com/unipacker/unipacker.
[12] Virustotal. https://www.virustotal.com/.
[18] Ulrich Bayer, Paolo Milani Comparetti, Clemens Hlauschek, Christopher Kruegel, and Engin Kirda.
Scalable, Behavior-Based Malware Clustering. In NDSS, volume 9, pages 8–11. Citeseer, 2009.
[23] Qian Feng, Rundong Zhou, Chengcheng Xu, Yao Cheng, Brian Testa, and Heng Yin. Scalable graph-based
bug search for firmware images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and
Communications Security, pages 480–491. ACM, 2016.
[40] Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, pages 4765–4774, 2017.
[43] Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. Kitsune: An ensemble of autoencoders for
online network intrusion detection. In The Network and Distributed System Security Symposium (NDSS) 2018, 2018.
[75] Xiaojun Xu, Chang Liu, Qian Feng, Heng Yin, Le Song, and Dawn Song. Neural Network-based Graph
Embedding for Cross-Platform Binary Code Similarity Detection. ACM Conference on Computer and Communications Security, 2017.
Insights
(1) 通过半监督学习的聚类算法给每个函数的行为进行聚类, 实现注释(打标签)的目的
(2) AutoEncoder可以用来检测恶意样本, 能不能用来识别函数 (保留意见)
(3) 考虑研究人机结对逆向的辅助型AI