fasterrcnn_resnet50_fpn 对于源码的个人理解
最近一直在天池上面看一些关于图像分类的代码,发现基本上都是yolo的调参,就想看看以前的模型是不是真的就跟不上时代了,然后去翻了翻torchvision.models,然后就选中了fasterrcnn_resnet50_fpn这网络,因为之前只是跟着教程跑了一遍,并没有详细的看过。花了点时间跑了一下天池最入门的街景字符编码数据集。在等数据跑的时候看看了源码。
1.先看一下fasterrcnn_resnet50_fpn的原理
说大白话,就是在resnet50的外面套了fpn,rpn和roi pooling 这3层皮。一层套一层跟包馄饨一样。
fpn:用来从resnet50的当中拿每一次降采样的数据,但是为了保证每一层拿到都是最佳的采样数据,他干了一件很巧的事情,其实还是残差模块的思想,如图:
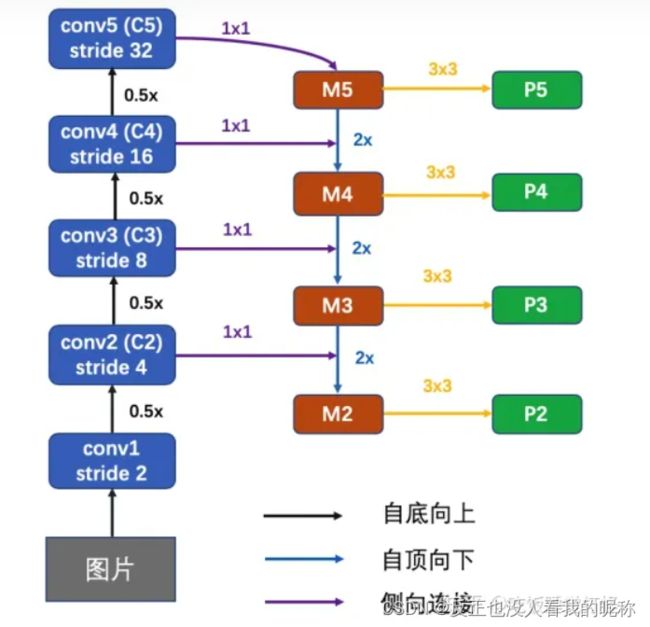
除了conv5最后一层是直接用的降采样后的结果之外,其他的从conv2-conv4都是不仅用原来采样的结果,并且还加上下层(图片缩小后的结果)的上采样(放大)的结果,以保证的到的特征是最好的。
rpn:拿到特征数据之后,rpn只干4件事:
1.种类回归和box回归
2.anchors 锚的产生
3.box过滤
4.损失计算,算种类的损失和box的损失
roi pooling:将特征的尺度固定,输出。
经过上面这几步之后最后统一再进行一次全连接层做物品分类和box回归。整个流程就结束了。
2.浅扒一下源码
model = torchvision.models.detection.fasterrcnn_resnet50_fpn()从这边直接进入,然后就能看到,一堆令人头大的东西
def fasterrcnn_resnet50_fpn(pretrained=False, progress=True,
num_classes=91, pretrained_backbone=True, trainable_backbone_layers=3, **kwargs):
"""Constructs a Faster R-CNN model with a ResNet-50-FPN backbone.
................
"""
assert trainable_backbone_layers <= 5 and trainable_backbone_layers >= 0
# dont freeze any layers if pretrained model or backbone is not used
if not (pretrained or pretrained_backbone):
trainable_backbone_layers = 5
if pretrained:
# no need to download the backbone if pretrained is set
pretrained_backbone = False
# 主干网络的设置
backbone = resnet_fpn_backbone('resnet50', pretrained_backbone, trainable_layers=trainable_backbone_layers)
# 定义FasterRCNN
model = FasterRCNN(backbone, num_classes, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls['fasterrcnn_resnet50_fpn_coco'],
progress=progress)
model.load_state_dict(state_dict)
return model其中最最关键的两行代码
# 主干网络的设置
backbone = resnet_fpn_backbone('resnet50', pretrained_backbone, trainable_layers=trainable_backbone_layers)
# 定义FasterRCNN
model = FasterRCNN(backbone, num_classes, **kwargs)2.1 先看backbond部分
发现是先将fpn包在resnet网络的外面,然后再传入到FasterRCNN中的。
点击resnet_fpn_backbone,发现
def resnet_fpn_backbone(
backbone_name,
pretrained,
norm_layer=misc_nn_ops.FrozenBatchNorm2d,
trainable_layers=3,
returned_layers=None,
extra_blocks=None
):
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained,
norm_layer=norm_layer)
# select layers that wont be frozen
assert trainable_layers <= 5 and trainable_layers >= 0
layers_to_train = ['layer4', 'layer3', 'layer2', 'layer1', 'conv1'][:trainable_layers]
# freeze layers only if pretrained backbone is used
for name, parameter in backbone.named_parameters():
if all([not name.startswith(layer) for layer in layers_to_train]):
parameter.requires_grad_(False)
if extra_blocks is None:
extra_blocks = LastLevelMaxPool()
if returned_layers is None:
returned_layers = [1, 2, 3, 4]
assert min(returned_layers) > 0 and max(returned_layers) < 5
return_layers = {f'layer{k}': str(v) for v, k in enumerate(returned_layers)}
in_channels_stage2 = backbone.inplanes // 8
in_channels_list = [in_channels_stage2 * 2 ** (i - 1) for i in returned_layers]
out_channels = 256
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels, extra_blocks=extra_blocks)最后return的是 BackboneWithFPN 这个类的forward方法,也就是说这么多代码全是参数准备。
其中的backbone需要进行特征金字塔的层包含 {'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'}
in_channels_list 接入FPN层的 in_channels_list
out_channels FPN 输出层的 channel,不对特征的宽高变化
再往上看一层 BackboneWithFPN
class BackboneWithFPN(nn.Module):
def __init__(self, backbone, return_layers, in_channels_list, out_channels, extra_blocks=None):
super(BackboneWithFPN, self).__init__()
if extra_blocks is None:
extra_blocks = LastLevelMaxPool()
# 根据需返回层的名字return_layers返回特征
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
# 特征金字塔,以输出的特征做特征金字塔
self.fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=extra_blocks,
)
self.out_channels = out_channels
def forward(self, x):
x = self.body(x)
x = self.fpn(x)
return x这个模块就是为了将特征金字塔进行输出。
到此为止主干网络的功能就全部完成,也就是Resnet50_fpn部分。
接下来看FasterRCNN部分
2.2 FastRCNN
model = FasterRCNN(backbone, num_classes, **kwargs)从这边点进去
class FasterRCNN(GeneralizedRCNN):可以看到FasterRCNN继承与GeneralizedRCNN ,而GeneralizedRCNN 继承于基类 nn.Module,GeneralizedRCNN作为抽象类的借口,去控制了整体的逻辑。细看GeneralizedRCNN的代码,最最主要的就是forward()的方法,但是回头去看FasterRCNN的代码,他并没有重写forward(),是全部继承自GeneralizedRCNN的forward()
super(FasterRCNN, self).__init__(backbone, rpn, roi_heads, transform)对于 GeneralizedRCNN 类,其中有4个重要的接口:
1. transform
2. backbone
3. rpn
4. roi_heads
这里的transform做了两件事情
1.将输入进行标准化,将输入图像减均值,除以方差
2.将图像和target中的目标框进行缩放。
然后将transform后的images.tensors输入到backbone主网络,输入到主网络里去提取特征图。
features = self.backbone(images.tensors)backbone 一般为 VGG、ResNet、MobileNet 等网络,在pytorch官方教程里面有相关的例子,官方的例子是换成了MobileNet。
拿到了特征图后,经过 rpn 模块生成 proposals 和 proposal_losses,接着进入 roi_heads 模块( roi_pooling + 分类), 最后经 postprocess 模块(进行 NMS,同时将 box 通过 original_images_size映射回原图)。
2.2 RPN模块的作用
去查看rpn.py 的forward()方法
def forward(self,
images, # type: ImageList
features, # type: Dict[str, Tensor]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
# type: (...) -> Tuple[List[Tensor], Dict[str, Tensor]]
# RPN uses all feature maps that are available
features = list(features.values())
objectness, pred_bbox_deltas = self.head(features)
anchors = self.anchor_generator(images, features)
num_images = len(anchors)
num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness]
num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]
objectness, pred_bbox_deltas = \
concat_box_prediction_layers(objectness, pred_bbox_deltas)
# apply pred_bbox_deltas to anchors to obtain the decoded proposals
# note that we detach the deltas because Faster R-CNN do not backprop through
# the proposals
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
proposals = proposals.view(num_images, -1, 4)
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
losses = {}
if self.training:
assert targets is not None
labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)
regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
loss_objectness, loss_rpn_box_reg = self.compute_loss(
objectness, pred_bbox_deltas, labels, regression_targets)
losses = {
"loss_objectness": loss_objectness,
"loss_rpn_box_reg": loss_rpn_box_reg,
}
return boxes, losses1.类别预测和框框的预测
objectness, pred_bbox_deltas = self.head(features)class RPNHead(nn.Module):
def __init__(self, in_channels, num_anchors):
super(RPNHead, self).__init__()
self.conv = nn.Conv2d(
in_channels, in_channels, kernel_size=3, stride=1, padding=1
)
self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1)
self.bbox_pred = nn.Conv2d(
in_channels, num_anchors * 4, kernel_size=1, stride=1
)
for layer in self.children():
torch.nn.init.normal_(layer.weight, std=0.01)
torch.nn.init.constant_(layer.bias, 0)
def forward(self, x):
# type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]
logits = []
bbox_reg = []
for feature in x:
t = F.relu(self.conv(feature))
logits.append(self.cls_logits(t))
bbox_reg.append(self.bbox_pred(t))
return logits, bbox_regRPNHead这里的原理其实非常的简单,就是经过一个3*3的卷积后,分成2个流,一个用于分类,一个用于预测框框。
2.anchors锚的产生
anchors = self.anchor_generator(images, features)if rpn_anchor_generator is None:
anchor_sizes = ((32,), (64,), (128,), (256,), (512,))
aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes)
rpn_anchor_generator = AnchorGenerator(
anchor_sizes, aspect_ratios
)anchor_generator的原理其实就是,在特征图的基础上产生指定大小的备选框,这边默认参数是32,64,128,256,512.这个参数是针对是针对 min_size = 800 设置的,这个设置,对图像尺寸较大的检测效果较好。对于小尺寸图片小目标的检测识别需要根据实际情况调节,每个anchor_sizes对应于一个特征图生成anchors,每个feature map特征点上根据aspect_ratios变形长宽比例不同的anchors。
对于 FPN 网络的输出的多个大小不同的 feature_maps,每个特征图都会接受处理,并设置 anchors。当处理完后获得密密麻麻的各种 anchors 了。
3.框框的过滤
self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)4.类别和框框的损失计算
loss_objectness, loss_rpn_box_reg = self.compute_loss(objectness, pred_bbox_deltas, labels, regression_targets)类别的损失时交叉熵
框框的损失,是在只考虑正样本的前提下的回归损失。
2.3ROI的构造
roi的主要构成是:box_roi_pool、 box_head 、 box_predictor
box_roi_pool : roialign将不同尺寸的特征图align到相同尺寸
box_head:将box_roi_pool输出特征做two stream 处理 一路用于目标分类,一路用于框回归
box_predictor:对box_head two stream 的特征做分类和回归预测,box_predictor最后输出维度是分类类别数