Python自用手册
Python自用手册
- 持续更新
转义字符
转义字符
\r 回车 直接退格到首行
\n 换行
\t 一个制表符 长度为 8
前面凑不齐8格字符,自动长度为8
例如 :
print("12345\ta")
12345 a
>>> print("12\ta")
12 a
>>> print("1234567\ta")
1234567 a
>>> print("12345678\ta")
12345678 a
字符串前 +r / R, 字符串不进行转义
a = r"asdasd\n"
print(a)
#输出
asdasd\n
删除变量和垃圾回收机制
- 可以通过 del 语句删除不在使用的变量
>>> a = 123
>>> del a
>>> a
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name 'a' is not defined
-如果对象没有变引用,就会被垃圾回收器回收,清空内存空间。
时间的表示
计算机中时间的表示是从”1970年1月1日00:00:00"开始,以毫秒(1/1000 秒)进行计算。 我们也把1970年这个时刻成为"unix 时间点”。这样, 我们就把时间全部用数字来表示了。python中可以通过time.time()获得当前时刻,返回的值是以秒为单位,带微秒(1/1000毫秒)精度的浮点值。例如: 1530167364.8566
>>> import time
>>> int(time.time())
1627375794
自增运算符
在python中并没有自增操作符号, ++, 要想实现自增使用的是i += 1,Python并不支持自增操作,Python 中变量是以内容为基准而不是像c中以变量名为基准,所以只要你的数字内容是5,不管你起什么名字,这个变量的ID是相同的,同时也就说明了python中一个变量可以以多个名称访问这样的设计逻辑决定了python中数字类型的值是不可变的,因为如果如上例,a和b都是5,当你改变了a时,b也会跟着变,这当然不是我们希望的,因此正确的自增操作应该a = a + 1 或者 a += 1,当此a自增后,通过id()观察可知,id 值变化了,即a已经是新值的名称
在Python中,无论是什么,只要值相同,变名相同,他们的内存地址是不变的,而C语言不-样, 值的存储是以变铭来区分的,一个变量具有独立的地址空间单位,但是Python有一个特殊的地方,为了 优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间,编译器会有一个小整数池的概念,小整数的定义 是[-5, 256] ,变量在这个范围内是会按照前面所说的,共用内存地址,超过这个值则使用单独的内存地址,Python仅仅对比较小的整数对象进行缓存(范围为[-5, 256])缓存起来,而并非是所有整数对象。需要注意的是, 这仅仅是在命令行中执行,而在Pycharm或者保存为文件执行,结果是不一样的,这是因为解释器做了-部分优化(范围是[-5,任意正整数])。
- 总结
- is比较两个对象的id值是否相等,否指向同一个内存地址;
- == 比较的是两个对象的内容是否相等, 值是否相等;
- 3.小整数对象[-5,256]在全局解释器范围内被放入缓存供重复使用;
- is运算符比== 效率高,在变量和None进行比较时,应该使用is。
条件表达式_三元运算符
# 语法结构
【条件为真的结果】if 条件 else 【条件为假的结果】
a, b = 2, 3
c = a if a > b else b
print(c) # 打印输出:
# 其条件的返回结果为引用
l = [1, 2, 3, 4]
a, b = 2, 3
(a if a > b else l).append(5)
print(l) # 打印输出: [1, 2, 3, 4, 5]
序列解包赋值
python中的解包可以这样理解: -个list是一个整体, 想把list中每个元素当成一个个体剥离出来,这个过程就是解包,我们来看下面这些例子
1. 将可迭代对象每一个变量赋值给一个变量
>>> name, age, date = ['Bob', 20, '2018-1-1"]
>>> name
Bob'
>>> age
20
>>> date
'2018-1-1'
>>> a,b,c = enumerate("a', 'b','")
>>> a
(0,'a")
#元组
>>> a,b,c= {"a":1, "b":2, "c":3}
>>> a
'a'
#字典
>>> a,b,c= {"a':1, "b:2, '':3}
a
>>> a,b,c= {"a":1, "b":2, "c":3}.items0
>>> a
("a', 1)
#字符串
>>> a,b,c = 'abc'
>>> a
'a'
#生成器
>>> a,b,c= (x + 1 for x in range(3))
>>> a
1
2. *号的使用
比如我们要计算平均分,去除最高分和最低分,除了用切片,还可以用解包的方式获得中间的数值
>>> first, *new, last= [94, 85, 73, 46]
>>> new
[85, 73]
用*来表示多个数值
注意带*号的变如果不在一个sequence中就会报错
*a = 'spam' #报错
故需要写成sequence序列的形式
*a, = 'spam'
print(a)
# 输出: ['s', 'p', 'a', 'm']
3.压包过程
>>> a = ['a','b','c']
>>> b =[1, 2, 3]
>>> for i in zip(a, b):
... print(i)
...
('a', 1)
('b', 2)
('c', 3)
细细拆解上面过程,可以看出步骤是这样的
先是zip函数将a b压包成为一个可迭代对象
对可迭代对象的每一个元素, 例如(("a', 1)) 进行解包 (i, j = ('a', 1))
>>> nums = 1,2, 3
>>> nums
(1, 2, 3)
#包与解包混合例子
>>> a= [0,1,2]
>>> b=[1,2,3]
>>> for i,j in zip(a, b): .
... print(i+j)
...
1
3
5
# 加入*号
>>>l = [('Bob', '1990-1-1', 60),
... ('Mary', '1996-1-4', 50),
... ('Nancy', '1993-3-1', 55),]
>>> for name, *args in l:
... print(name, args)
...
Bob ['1990-1-1', 60]
Mary ['1996-1-4', 50]
Nancy ['1993-3-1", 55]
#解包和压包结合可以实现类似矩阵转置操作
a= [[1,2,3],[4, 5, 6]]
for x, y in zip(*a):
print(x, y)
4. _的使用
- 当-些元素不用时,用
_表示是更好的写法, 可以让读代码的人知道这个元素是不要的
>>> person = ('Bob', 20, 50, (11, 20, 2000))
>>> name, *_ , (*_ , year) = person
>>> name
'Bob'
>>> year
2000
5.解包作为参数传入函数中
def myfun(a, b):
print(a + b)
# 列表元组的解包
>>>n=[1,2]
>>> myfun(*n)
>>> m = (1,2)
>>> myfun(*m)
# 字典的解包
>>> mydict = {'a':1, 'b':2}
>>> myfun(**mydict)
3
>>> myfun(*mydict)
ab # 这里由于是字典, 第一个*相当于解引用得到键值, 然后第二个*通过键值得到value
一个应用
>>> bob = {'name': 'Bob', 'age': 30}
>>> "{name}'s age is {age}".format(**bob)
"Bob's age is 30"
# 多返回值函数也涉及到了解包的过程
def myfun(a, b):
return a + 1, b + 2
>>> m, n = myfun(1, 2)
>>> m
2
>>> n
4
其实本身是一个元组
>>> p = myfun(1, 2)
>>> p
(2, 4)
运算符优先级
| 运算符说明 | Python运算符 | 优先级 | 结合性 | 优先级顺序 |
|---|---|---|---|---|
| 小括号 | () | 19 | 无 | |
| 索引运算符 | x[i] 或 x[i1: i2 [:i3]] | 18 | 左 | |
| 属性访问 | x.attribute | 17 | 左 | |
| 乘方 | ** | 16 | 右 | |
| 按位取反 | ~ | 15 | 右 | |
| 符号运算符 | +(正号)、-(负号) | 14 | 右 | |
| 乘除 | *、/、//、% | 13 | 左 | |
| 加减 | +、- | 12 | 左 | |
| 位移 | >>、<< | 11 | 左 | |
| 按位与 | & | 10 | 右 | |
| 按位异或 | ^ | 9 | 左 | |
| 按位或 | | | 8 | 左 | |
| 比较运算符 | ==、!=、>、>=、<、<= | 7 | 左 | |
| is 运算符 | is、is not | 6 | 左 | |
| in 运算符 | in、not in | 5 | 左 | |
| 逻辑非 | not | 4 | 右 | |
| 逻辑与 | and | 3 | 左 | |
| 逻辑或 | or | 2 | 左 | |
| 逗号运算符 | exp1, exp2 | 1 | 左 |
进制转换
(1) 字符串之间的进制转换
10进制转16进制: 类似的还有八进制oct(), 二进制bin()返回值都为字符串
hex(16) ==> 0x10
16进制转10进制:
int('0x10', 16) ==> 16
16进制字符串转为二进制
hex_str = '00fe'
print(bin(int(hex_str, 16)))
'0b11111110'
print(bin(int(hex_str, 16))[2:]) #结果'111111110'
二进制字符串转为16进制字符串
bin_str= '0b0111000011001100'
hex(int(bin_ _str,2))#结果'0x70cc'
enumerate()函数
-
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。
-
Python 2.3.以上版本可用, 2.6 添加start参数。
语法: enumerate(sequence, [start=0])
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(O, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start= 1))
#下标从1开始[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
>>>i = 0
>>> seq = ['one', 'two', 'three']
>>> for element in seq:
... print i, seq[]
... i += 1
0 one
1 two
2 three
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 twc
2 three
序列
列表

一个列表中, 可以存储不同的数据类型, 与 C/C++, Java数组的一个区别.
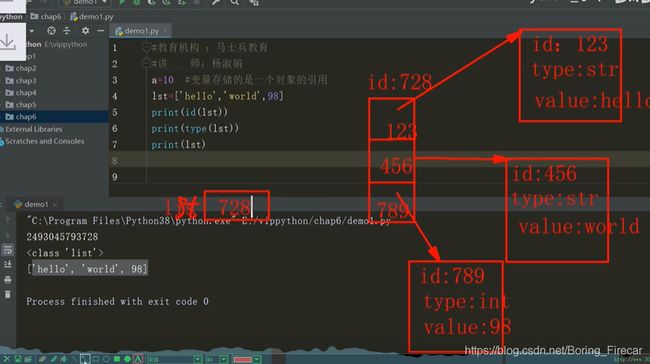
列表的每一个元素, 理解为并不是一个放 置实际的数据内容,其存放的元素可以看为其存放了一个地址,这个地址指向了其实际存放东西的数据,即像C/C + +的void*数组,故其可以存放不同的数据类型,其实实际存放的东西是-样的, 都是一个引用地址.
其索引有正向索引和负向索引:
正向索引 0 1 2 3 4 5
数据 [1, 2, 3, 4, 5, 6]
负向索引 -6 -5 -4 -3 -2 -1
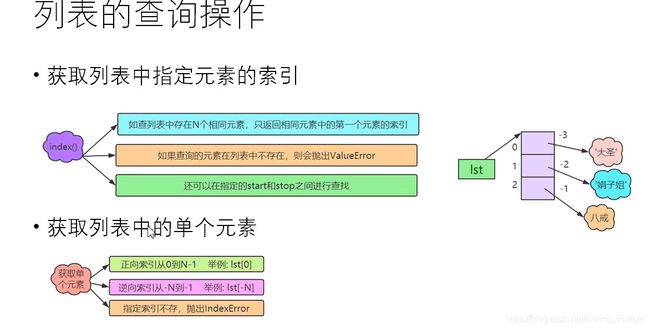
列表的查询操作
[idx]由索引得到索引对应的元素value / index(value)获取其idx
Ist = ["hello", "world", "hello", 98]print(st.index("hello")) #如果列表中有相同的元素只返回相同元素的第一个元素的索引
列表的切片操作
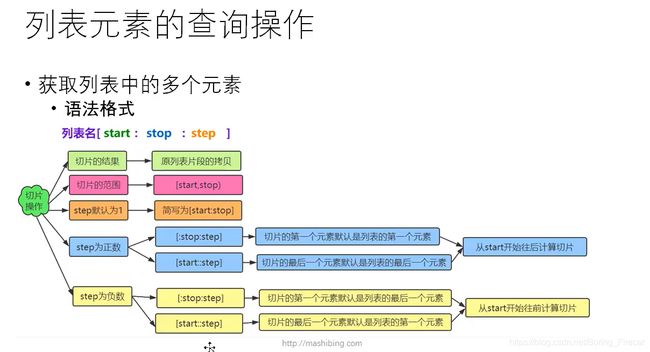
lst=[1,2,3,4]
print(lst[1:3]) #打印2 3
prnt(lst[3:]) #打印4
print(lst:[-1]) #打印4 3 2 1
print(lst[2::-1]) #打印3 2 1
print(lst[2:4:-1]) #打印[] 如果step负 数则start大于end不然输出空
列表元素的查询操作
(1) 判断指定元素在列表中是否存在
元素 in 列表名
元素 not in 列表名
(2) 列表元素的遍历
for 迭代变量 in 列表名:
操作
列表元素的增加操作
(1) append()方法,在列表末尾添加一个元素, 其返回值为None
st= [1,2,3]
lst.append(4)
print(lst) #打印1 2 3 4
l2= [5, 6, 7]
lst.append(l2)
print(lst) #打印 1 2 3 4 [5, 6, 7]
# append只会添加一个元素,故这里直接将l2整个列表对象当做一 个元素添加到lst中
(2) extend()方法,在列表末尾至少添加一个元素,其参数为可迭代对象
lst= [1,2,3]
lst.extend(4) #报错,其参数必须是个可迭代对象
l2= [4, 5, 6]
lst.extend(l2)print(lst) #打印1,2,3,4,5,6#对比上面append()添加时的情况
(3) insert(方法,在列表的任意位置添加一个元素
lst= [1,2,3]
lst.insert(1,4)
print(lst) #打印1 4 2 3 原本索引位置的元素均往后移动
lst.insert(100, 5) #打印1 4 2 3 100
#参1索引位置支持正向索弓和负向索引,若该索引|原本存在元素,则包括原来的元素和其后面的元素均向后移动
#同时若参1的索弓|超出范围即idx < -len(lst)此时当作索引0,若idx > len(st) - 1当作append()
(4)切片在列表的任意位置添加至少个元素, 实应该理解为替换
#这个操作其实不能说是添加,应该说更像是替换操作
lst= [1,2,3]
lst[0:2] = [4,4,4]
print(lst) #打印4 4 4 3, lst[0:2]返回的是1,2这里用[4,4,4]进行替换
lst[len(lst)::]= [5,5,5]
print(lst) #打印4 4 4 3 5 5 5 相当于extend()
列表元素的删除操作
(1) remove()方法,根据值删除,一次删除一个元素,重复元素只删除第一个, 元素不存在抛出ValueError
lst= [1,2,3]
lst.remove(2)
print(lst) # 打印1 3
(2) pop()方法,根据索引,删除一个指定索引位置上的元素,指定索引不存在抛出IndexError,不指定索引删除最一个元素, 其返回值为提取出来的元素
lst= [1,2,3]
lst.pop(1)
print(lst) #打印1 3
lst.pop()
print(lst) #打印1
(3) 切片:直接替换成[]
(4) clear() 清空列表,将列表所有元素清空lst.clear()
(5) del删除列表, del lst 将列表对象删除
列表元素的排序操作
(1) 调用列表的sort()方法
lst= [1,4,3,2]
lst.sort()
print(lst) # 打印 1 2 3 4
#指定reverse = True进行降序排序
lst.sort(reverse = True)
print(lst) # 打印 4 3 2 1
(2) 内置函数sorted(),并不会改变传入的原列表对象, 而是产生一个新对象返回
lst= [1,4,3,2]
sorted(lst)
print(lst) #打印1 4 3 2
print(sorted(lst)) #打印1 2 3 4
print(sorted(lst, reverse = True)) #打印4 3 2 1
列表生成式
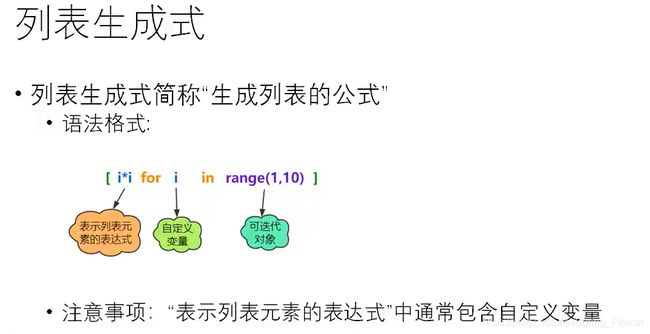
lst = [i*i for i in range(1,10)]
print(lst) #打印1,4,9, 16, 25, 36, 49, 64, 81
# 可应用于生成长度为n的列表,列表元素初始值自定义
lst = [0 for i in range(0,100)] #生成长度为100的列表,元素初值为0,类似C/C + +中定义-个int arr[100];
lst = [0]* 100 # 一种更快的方法
lst = [[0] * 100 for i in range(0,100)] #列表生成式生成一个100 * 100的二维列表
列表的注意事项
- 列表本身是python中的可变对象,这个可变理解为其本身list对应的那个地址内容可变但list本身存放这个list地址是不会变的。
lst= [1,2,3]
print(id(lst)) # 139848306455048
lst.append(4)
print(id(lst)) # 139848306455048两次均相同,调用append只是在原本Ist指向的区域多加了-个数据引用,这个数据指向4
lst = [1,2,3]
print(id(st)) # 139848306455112发生改变,这里让lst这个标识符对应的地址变为了[1 ,2,3]的地址故此时改变了
2.在python中,如果用一个列表list1乘一个数字 n 会得到一个新的列表 list2,这个列表的元素是list1的所有元素复n次,但如果list1中的元素是引用类型,比如列表时,就会发生一些意料之外的事
list1 = [[0, 0]]
list2= list1 * 2
print(ist2) # [[0, 0], [0, 0]]
list2[0][0]= 1
print(list1) # [1, 0]
print(list2) # [[1,0],[1,0]]
id(list2[0]) == id(ist2[1]) # True
此时list2[0] 和 list2[1] 有相同的地址
l1 = [1.2,3]
l2 = [0,0,0]
l1.append(l2
print(l1) #打印[1,2,3, [0, 0, 0]]
l2[2]= 3
print(l1) #打印[1, 2, 3, [0, 0, 3]
print(l2) #打印[0,0,3]
因为list本身是可变对象,支持修改,这里说的支持修改是其所指向地址的内容.这里把l2加到l1列表中,我们进行l2[2] = 3操作时并没有改变l2标识符指向的list对象的地址,只是改变了其list对象地址的部分数据内容,同样l1中的那个元素只是一个地址故这就造成了出现上面的原因.故为了不出现上面的那种情况,不是添加一个引用原本列表的地址,而是想创立一个新对象,添加的是这个新对象地址,使这两个列表互不相关,应采用下面这种写法
l1 = [1,2,3]
l2 = [0,0,0]
l1.append(list(l2))
print(l1) # 打印[1,2,3, [0, 0, 0]]
l2[2]= 3
print(l1) #打印[1,2,3,[0, 0, 0]]
print(l2) #打印[0,0,3]
字典
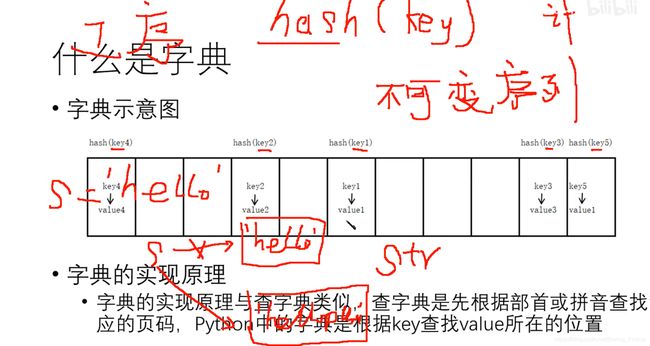
- 字典就是一个哈希表, 属于无序序列
- python3.7及以后的版本字典是有序的
字典由key值找到其value,故这就要求key值是个不可变对象, 因为一个对象的哈希值在生命周期内不应该改变,,一个对象的哈希值如果在其生命周期内绝不改变,就被称为可哈希(它需要具有hash()方法) , 并可以同其他对象进行比较(它需要具有eq()方法)。可哈希对象必须具有相同的哈希值比较结果才会相同。一个对象的哈希值在生命周期内不改变,就被成为可哈希。可哈希性使得对象能够作为字典键或集合成员使用,因为这些数据结构要在内部使用哈希值。可变容器(例如列表或字典)都不可哈希。
字典的创建

-
创建空字典
d = {} d = dict()
字典元素的获取
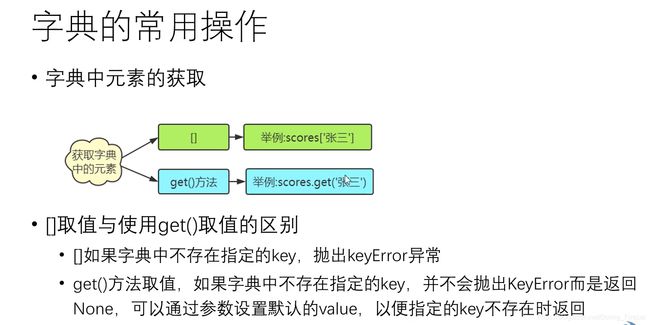
字典key值的查询
使用in / not in
d= {"张三": 100, "李四": 89, "王五": 45}
print("张三" in d) # True
元素的增删改
d= {"abc": 100, "edf": 89, "gg":45}
#字典元素的删除
del d["abc"]
#字典元素的新增
d["hack"] = 777
#使用update的方法添加一个/多个键值对
d2 = {"t":3, "w":4, "C":5}
d.update({"color": 111}) / d.update(d2)
#对原本元素的修改
d["edf"]= 90
print(d) #打印{'edf: 90, 'gg': 45, 'hack': 777}
#清空字典元素
d.clear()
获取字典视图的三个方法
(1) 获取字典中所有的key ---- keys()
d= {"abc": 100, "edf": 89, "gg": 45}
k = d.keys()
print(k) #打印dict_keys("abc', 'edf, 'gg'])
print(list(k)) # 打印['abc', 'edf, 'gg']
(2)获取字典中所有的value — values()
d = {"abc": 100, "edf": 89, "gg":45}
v = d.values()
print(v) #打印dict_values([100, 89, 45])
print(list(v)) # 打印[100, 89, 45]
(3)获取字典中所有的键值对— items()
d= {"abc": 100, "edf": 89, "gg": 45}
item = d.items()
print(item) # 打印dict_items(['abc', 100), ('edf, 89), ('gg', 45)])
print(list(item)) #打印[('abc', 100), ('edf , 89), ('gg', 45)]每个元素都是由元组组成
字典元素的遍历
使用for-in循环进行遍历
d= {"abc": 100, "edf": 89, "gg": 45}
for item in d:
print(item, d[item])
#打印
abc 100
edf 89
gg 45
- 使用for-in遍历的是字典的键值key
字典的特点

字典生成式
(1) 内置函数
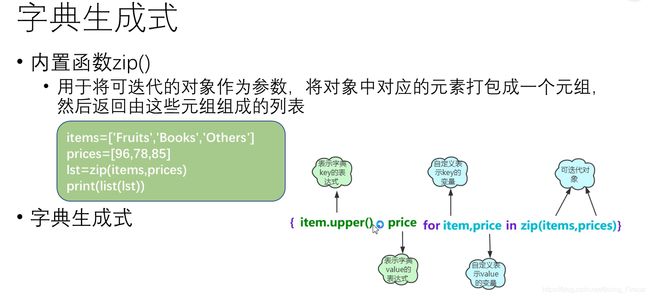
(2)字典生成式格式
{k:v for k;v in zip(1, 12)}
l1 = ["abc", "edf", "fg"]
l2 = [1,2,3]
d = {k:v for k, v in zip(l1, l2)}
print(d) #打印{'abc': 1, 'edf: 2, 'fg': 3}
collections.defaultdict()的使用
在Python里面有一个模块collections, 解释是数据类型容器模块。这里面有一个collections.defaultdict()经常被用到。主要说说这个东西。
这里的defultdict(function_factory>构建的是个类似dictionaryt的对象,其中keys的值, 自行确定赋值,但是values的类型, 是function factory的类实例,而且具有默认值。比如default(int)则创建一个类似dictionary对象, 里面任何的values都是int的实例,而且就算是一个不存在的key*,* d[key]也有-个默认值,这个默认值是*int()*的默认值0.
import collectionsdd
dd = collections.defaultdict(list) # value默认类型全为list
dd[key].append(22) #这样即使当key值不存在时也不会报错
dd[3]= 3 #只是默认value类型为空的list,但value还是可以是其他类型
元组

元组的创建方式

如果元组中只有一个元素,则不能省略逗号, t3= (‘Python’ ) --> str类型 t3 = (‘Python’,)–>元组类型
同样如果省略小括号,t3 = 12, -->元组类型,如果后面不加,则为int类型
- 空元组t = () / t = tuple()
特点不可变序列


t = (10, [20, 30], 9)
t[1] = 100 #报错'tuple' object does not support item assignment
t[1].append(100)
print(t) #打印(10, [20, 30, 100], 9)
#对于元组不可变序列的理解不可变的元组内的每个元素,而由之前的列表我们知道列表其实存放的是每个元素的地址引用,所以同样元组中的每一个元素并不是真正存放元素的地址,而是存储了真正元素存放地方的地址,而我们进行t[1] = 100这步操作时, t[1] 原本存储的是一个list的地址而这个赋值操作企图将t[1 ]存放的值修改为一个存放100这个整数值的地址,而对于元组来说其存放元素是不可变的,故报错,而我们进行t[1].append(100)这步操作时,实际操作的是在t[1]中列表所在地址上将其数据加上一个100, 并没有修改t[1]的内容.
元组的遍历
元组也是可迭代对象,所以也可以直接用for-in遍历
- 元组由于是不可变序列,故其没有元组生成式
集合

- 集合(set) 是一个无序的不重复元素序列
- 一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现-次,可用于去重p
- 一个集合中,每个元素的地位都是相同的,元素之间是无序的
集合的创建方式

- 可以使用列表来创建集合 set([1,2,3,4,5]) , 同理也可以使用元组类型
创建一个空集合
- s = set();
- s = {} 这样是创建一个空字典;
有时候我们会有一种错觉,认为集合是有序的,看下面一个案例
去除a里面的重复元素a=[1,3,2,6,2,4,3,1,2]
print(set(a))
#转list
print(list(set(a)))
{1,2,3,4,6}
从结果看,,发现使用集合去重后,自动从小到大排序了,提容易产生一个误区,得出集合会自动排序。这里排序的主要原因是python3版本,对于数据量很小的集合并且数字很少的时候,确实是做了一个排序。接下来把数字调大一点再看
#去除a里面的重复元素
a = [1,3, 122, 6,2, 4,3, 1, 2, 22, 34, 22, 99, 200]
print(set(a))
#转list
print(list(set(a))
#运行结果{1, 2, 3, 4, 34, 6, 99, 200, 22, 122}
这时候会发现,并没按从小到大排序,接着把数字换成英文字符
a = ["a","b","c", "d", "a", "c"]
print(set(a))
#转list
pritlist(set(a))
#打印
{'d', "b', 'a', 'c'}
['d', "b', 'a', 'c']
{'b', 'd', 'c','a'}
['b', 'd', 'c', 'a']
每次运行的结果都不一样,说明集合无序的。
集合相关操作

set看成的是没有value的字典其key同时也是它的value,它是靠key来确定的,
集合要在内部使用哈希值,故集合中的元素是可哈希类型的(hashable),故列表或者字典不能作为元素添加到集合中即add(list)是错误的,但可以用update(list);使用update(dict)时,添加的是字典的值
set集合的pop()方法,不像上面所述的那样,只是随机删除一个元素, 而是有一定的规律可循的, 我将我发现的规律总结如下:
#执行下面的代码,并查看输出结果:
print('pop(函数的输出结果看这里:)')
s1={4,2,1 5} #集合里只有数字
s2={'你','我','他'} #集合里无数字
s3={3,2,4,'你','X'} #集合里既有数字又有非数字
s1.pop() #元素是数字时,删除最小的数字,余数字升序排列
s2.pop() #元素非数字时,随机删除一个元素元素随机排序
s3.pop() #元素既有数字又含非数字时,如果删除的是数字,则一定删最小的,否则随机删除一个非数字元素
print(s1)
print(s2)
print(s3) #这个代码执行后,输出的结果是随机的
集合间的关系
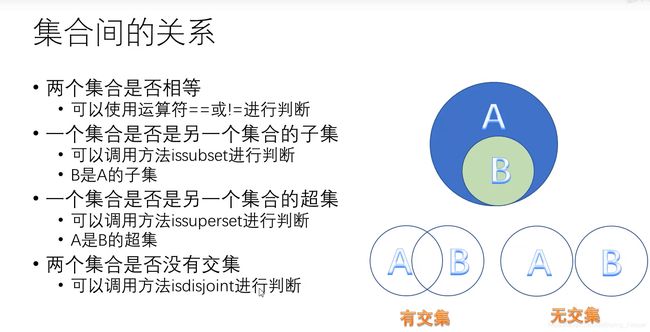
集合中数学操作
# 1.交集操作
s1={10,20,30,40}
s2 = {20, 30, 40, 50, 60}
print(s1.intersection(s2))
print(s1 & s2) #两种方式等价
#打印:{40, 20, 30}
# 2.并集操作
print(s1.union(s2))
print(s1 | s2)
#打印.{40, 10, 50, 20, 60, 30}
# 3.差集操作
print(s1.difference(s2))
print(s1 - s2) # s1中只有s1才有的元素的集
#打印{10}
# 4.对称差集
print(s1 .symmetric_difference(s2))
print(s1 ^ s2) #s1和s2两个集合各自独有的元素的并集
#打印{50, 10, 60}
集合生成式
格式: {i * i for i in range(1, 10)}
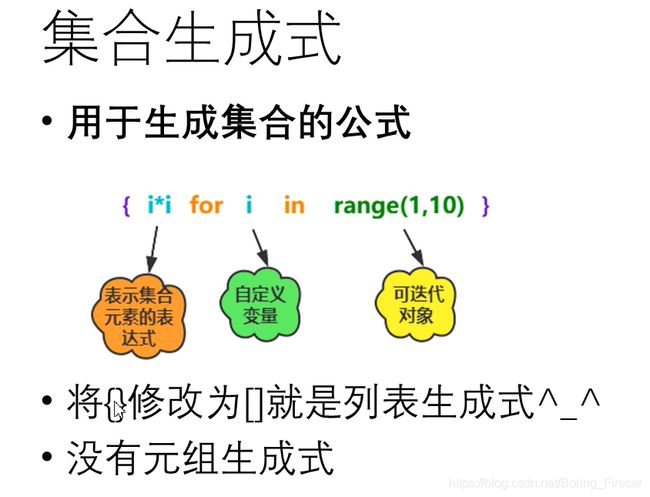
- 目前的可变数据:列表,字典,集合
- 不可变序列: 数字,字符串,元组
字符串
字符串定义
字符串是用单引号括起来的
其实字符串还可以用双引号、单三引号*、双三引号,下面的定义都是正确的
letter = '''刘总:
您好!
您发的货我们已经收到,明天就把余款付清。
祝: 商祺。
小徐
2016-06-12'''
如果用单引号这样定义则会报错,用单引号只能使用\n表示显示换行
letter = '刘总:\n 您好!\n 您发的货我们已经收到,明天就把余款付清。\n \n 祝: 商祺。\n 小徐\n 2016-06-12'
字符串的驻留机制


#交互模式
a = "abc"
b= "ab" + "c"
c= "".join(['ab', 'c'])
a is b # True
a is c # False
#此时a, b的内容在运行之前就已经确定了,而c的内容 要等到运行的时候调用join方法才能得到。故此时运行就需要开辟新的空间
s1 = "abc%"
s2 = "abc%"
s1 == s2 #True
s1 is s2 # False
在交互模式下,此时s1 字符串的内容并不符合标识符,因为%并不是标识符的符号,故此时不会产生驻留机制
但是写成文件直接运行会是True
#调用sys的intern方法强制2个字符串指向同一对象。
import sys
s1 = "abc%"
s2 = "abc%'
a = sys.intern(b)
a is b # True
n1 = "a#"
n2 = "b#"
n1 = sys.intern(n2)
print(n1, n2)
#打印b# b#

join()方法获取可迭代对象中的所有项目,并将它们连接为一个字符串。
必须将字符串指定为分隔符。
myTuple = ("Bill", "Steve", "Elon")
x= "#".join(myTuple)
print(x) #打印 Bill#Steve#Elon
print("".join(myTuple)) #打印BillSteveElon
字符串查询操作

str = "heleleo"
print(str.index("le")) # 打印: 2
print(str.rindex("le")) # 打印: 4
print(str.index("f")) # 打印: ValueError: substring not found
print(str.find("f")) #打印:-1
#统计一个字符串中每个字符出现的次数count()方法
str = "hello"
print(str.count('l')) #打印: 2
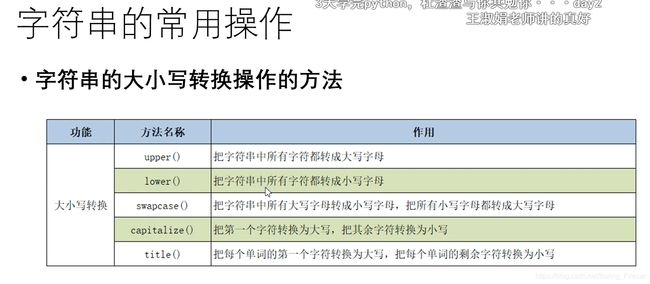
字符串大小写转换
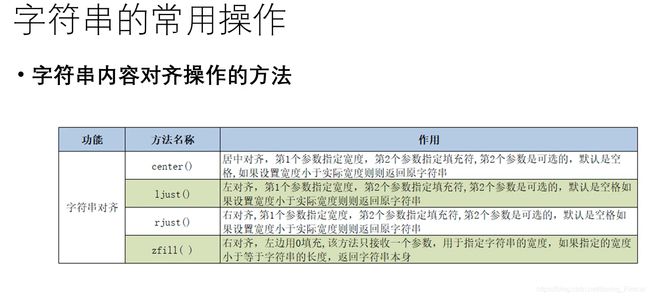
字符串内容对齐操作
str = "1234"
print(str.center(10, '*))
#打印:
***1234***
print(str.ljust(10, '*'))
#打印:
1234******
print(str.rjust(10, '*")
#打印:
******1234
print(str.zfill(10
#打印:
0000001234
这里有个细节就是使用zfill方法填充时,若字符串首尾为+ / - 则自动将+ / - 移动到首位。
s ='+123'
print(s.zfill(10))
#打印:
+000000123
s ='-123'
print(s.zfill(10))
#打印:
-000000123
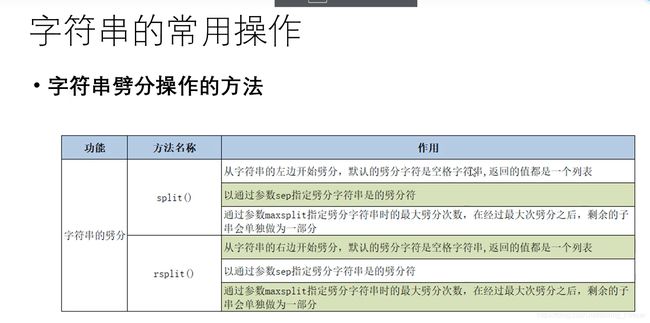
字符串的劈分操作
- 劈分操作的返回值是一个列表
s = "hello world Python"
lst = s.split()print(lst) # 打印['hello', 'world', 'Python']
s1 = "hello|world|Python"
print(s1.split(sep='l'))
print(s1.split('l')) # 两个等价 打印: ['hello', 'world', 'Python']
print(s1.split(sep='l', maxsplit=1))
print(s1.split('l', 1)) # 两个等价 打印: ['hello', 'world|Python']
字符串的判断操作

字符串的替换和合并

(1) replace()方法
s = "hello, Python Python Python"
print(s.replace("Python", "Java")) # hello, Java Java Java默认全部替换
print(s.replace("Python", "Java", 2)) # # hello, Java Java Python
(2) join()方法获取可迭代对象中的所有项目,并将它们连接为-个字符串。
必须将字符串指定为分隔符。
myTuple = ("Bill", "Steve", "Elon")
x="#".join(myTuple)
print(x) #打印Bill#Steve#Elon
print("".join(myTuple)) #打印BillSteveElon
字符串的比较操作

字符串的切片操作
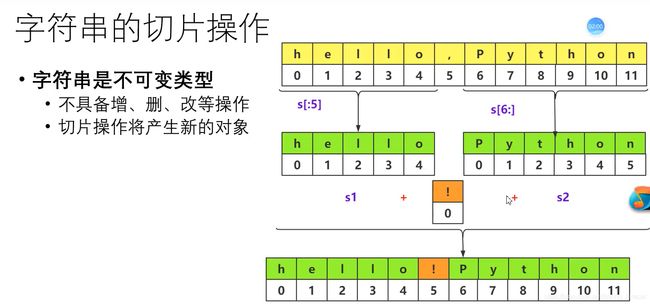
字符串倒序-->字符串属于不可变对象, 故这时会产生新对象
>>>str1 = '字符串的倒序'
>>>reverse = str1[::-1]
>>> print(reverse)
序倒的串符字
>>>"abcde"[::-1]
edcba
格式化字符串
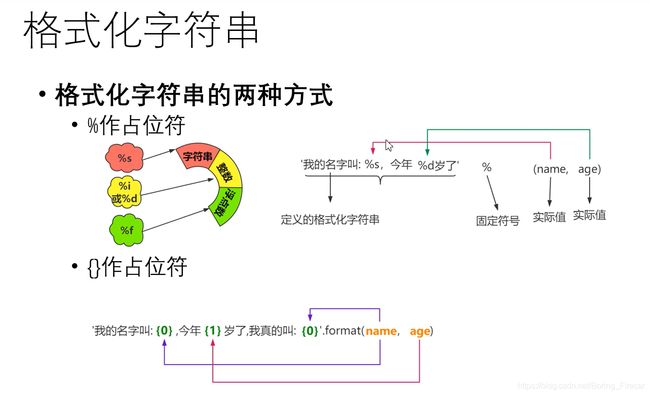
(1) % 作占位符
name= "小明"
age = 12
print("我的名字是%s,我的年龄为%d" % (name, age)) # 字符串 % (元组)
| 符号 | 格式化字符及其ASCII码 |
|---|---|
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号 八进制数 |
| %x | 格式化无符号 十六进制数 |
| %X | 格式化无符号 十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e, 用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
| %p | 用十六进制数格式化变量的地址 |
(2) {} 作为占位符,调用字符串的format方法
name = "小明"
age = 12
print("我叫{0},今年{1}岁" .format(name, age))
# 这里也可以不用0, 1,而用其他标识符如
"{name}'s age is {age}".format(name = "xxx", age = 123)
但这样写的话就要关键字传参了.
(3) f-string法,字符串前面加一个f,然后再里面用{}, {}里面放标识符
- 这种写法必须要Python解释器是3.6以后的版本才支持哦。
name = "小明"
age = 12
print(f"我叫{name},今年{age}岁")
salary = 10000
print(f'{salary:10}') # 指定宽度
10000 #默认右对齐
# 设置左对齐
print(f'{salary}:<10}')
10000
t= 1.2312
print(f'{t:10}')
1.2312
如果我们想指定小数点后保留几位,可以像这样{t:<10.2f}
'1.23 '
如果我们想在不足指定宽度的时候不是补空格,而是补数字0,可以像这样{salary:08}
16进制格式化数字
# 用x表示格式化为16进制,并采用小写格式
print(f'数字65535的16进制表示为: {65535:x}') #打印 : 数字65535的16进制表示为: ffff
#用X表示格式化为16进制,并采用大写格式
print(f'数字65535的16进制表示为: {65535:X}') #打印 : '数字65535的16进制表示为: FFFF'
字符串内容里有花括号的情况
采用f-string方式格式化的字符串内容本身就有{或者}符号, 一定要双写进行转义,否则会被当成是格式化占位符。
times1 = 1000
times2 = 2000
print(f"文章中{{符号出现了{times1}次")
print(f"文章中}}符号出现了{times2} 次)
# 打印
文章中{符号出现了1000次
文章中}符号出现了2000次
设置精度和宽度
print("%10d" % 99) # 10表示宽度
print("%.3f" % 3.1415826) # .3f表示精度,小数点后面三位
print("%10.3f" % 3.1415926) #打印: 3.142
# {}作占位符表示精度
print("{0:.3}".format(3.1415926)) #.3示-共就三位数字 打印:3.14
print("{0:.3f}".format(3.1415926)) # .3f表示三位小数 打印:3.142
print("{0:10.3}".format(3.1415926)) #同时设置精度和宽度,
#打印: 3.14
'税前薪资: %10s元' % 100000
'税前薪资: %10s元' % 10000
'税前薪资: %10s元' % 1000
%10s中的10就是指定了格式化结果至少10个字符。得到的结果为(默认为右对齐)
'税前薪资: 100000元'
'税前薪资: 10000元'
'税前薪资: 1000元'
如果我们希望是左边对齐,而不是右边对齐,就可以加一个“-“,像这样
'税前薪资: %-10s元' % 100000
'税前薪资: %-10s元' % 10000
'税前薪资: %-10s元' % 1000
得到结果为
'税前薪资: 100000 元'
'税前薪资: 10000 元'
'税前薪资: 1000 元'
比如,打印数字的时候,我们指定宽度,而且希望不足宽度补零,而不是补空格,就可以这样
'税前薪资: %010d元' % 100000
'税前薪资: %010d元' % 10000
'税前薪资: %010d元' % 1000
税前薪资: 0000100000 元
税前薪资: 0000010000 元
税前薪资: 0000001000 元.
对于小数的格式化
'税前薪资: %010f 元' % 1000.4522
'税前薪资: %010f 元' % 1008.6621
'税前薪资: %010f 元' % 1009.3351
得到结果为
'税前薪资: 1000.452200 元'
'税前薪资: 1008.662100 元'
'税前薪资: 1009.335100 元'
小数点默认补足六位,然后再根据宽度继续补,默认右对齐
字符串的开头结尾操作
(1) strip, lstrip, rstrip操作
# strip方法可以将字符串前面和后面的空格删除,但是不会删除字符串中间的空格
' 小 李:88 '.strip()
返回的就是 '小 李:88',去掉了前后的空格,但是中间的空格不会去掉
# lstrip方法将字符串前面(左边)的空格删除,但是不会删除字符串中间和右边的空格
' 小 李:88 '.lstrip()
返回的就是 '小 李:88 '
# rstrip方法将字符串后面(右边)的空格删除,但是不会删除字符串中间和左边的空格
' 小 李:88 '.rstrip()
返回的就是 ' 小 李:88'
(2) startswith 和 endswith
# startswith方法检查字符串是否以参数指定的字符串开头,如果是,返回True,否则返回False
# endswith方法检查字符串是否以指定的字符串结尾,如果是,返回True,否则返回False
str1 ='我们今天不去上学,我们去踢足球'
str1.startswith(我们) #返回True
str1.endswith(我们) # 返回False
编码和解码
(1) encode() 和 decode()
s = "好"
# (1) 编码encode()
print(s.encode(encoding = "GBK")) # 在GBK编码中,一个中文字符占两个字节打印:b"\xba\xc3'
print(s.encode(encoding = "UTF-8")) #在UTF-8编码中, -个中文占3个字节打印: b"xe5\xa5\xbd'
a = s.encode("GBK") #和上面的形式等价
b = s.encode("UTF-8")
print(type(a), type(b)) #打印: 字节类型数据
encode方法返回的是编码后的字节串对象bytes, 编码为字节串对象bytes就可存储到文件或者传输到网络中去了
# (2)解码decode将字节串解码为字符串
print(a.decode("GBK")) #打印:好
print(a.decode("UTF-8")) #出错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xba in position 0: invalid start byte
#用什么编码格式编码,要用对应编码格式解码,不然抛出异常
print(b.decode("UTF-8")) #打印: 好
print(b"xe4\xbd\xa0\xe5\xa5\xbd".decode('utf8')) # 你好
print(b"\xc4\xe3\xba\xc3".decode("gbk")) #你好
l= list("你好, 我是傻逼".encode("gbk"))
print(l)
#输出: [196, 227, 186, 195, 44, 32, 206, 210, 202, 199, 201, 181, 177, 198]
#每一个中文由高字节依次解码,例如'你' 这个字按照gbk编码为c4e3 --> 0xc4 转化为十进制196, 0xe3 --> 227
(2) chr函数和ord函数
ord函数(order) 返回一个字符对应的unicode编码,而chr函数(char) 正好反过来,它返回一个unicode编码对应的字符。他们都是python内置函数。
>>> chr(65)'A';
>>> ord('A')
65
>>> chr(20013)
中
>>> ord('中')
20013
ord()返回一个字符的unicode值。这个函数并没有其他参数,那就是说,给定一个字符, 就会有一个特定值对应。跟具体编码(utf-8, utf-16, gb2312) 无关。
(3)字符串编码为unicode转义数字
除了utf8,gbk 还有一种常见的编码方式,叫做’unicode-escape’,就是直接用unicode数字字符串表示字符,如下所示
>>> '白月羽'.encode('unicode-escape')
b'\\u767d\\u6708\\u9ed1\\u7fbd'
>>> '\u767d\u6708\u9ed1\u7fbd'
'白月黑羽'
直接用16进制数字创建bytes
>>> b'xb0\xd7\xd4\xc2\xba\xda\xd3\xf0'
b'\xb0\xd7\xd4\xc2\xba\xda\xd3\xf0'
>>> b'xb0\xd7\xd4\xc2\xba\xda\xd3\xf0'.decode("gbk")
'白月黑羽'
(4) 字节串和16进制表示字节的字符串
>>> a = b'hello,123'
>>> a.hex()
'68656c6c6f2c313233'
反向操作
>>> bytes.fromhex("68656c6c6f2c313233')
b'hello,123'
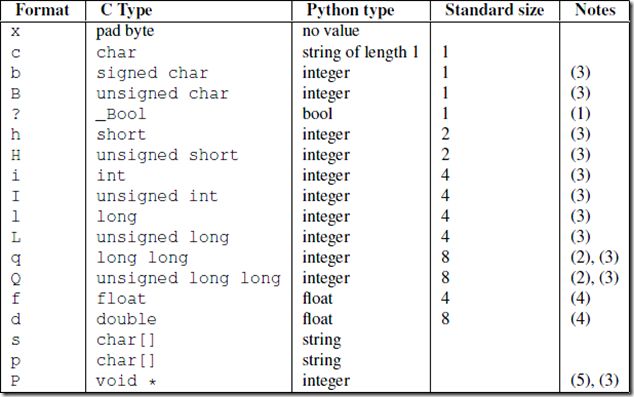
(5) struct模块
- 大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化
import struct #导入struct模块struct模块最重要的两个函数就是pack() 、unpack()方法
打包函数: pack(fmt, v1, v2, v3, ...)
解包函数: unpack(fmt, buffer)
其中,fmt是格式字符(format的谐音),struct模块支 持的格式化字符如下表
设置字节顺序

树莓派串口传输数据的一个具体例子
# python版本
import serial
import struct
import time
ser = serial.Serial("/dev/ttyAMA0",9600) #打开串口设置波特率为9600
ser.flushInput() #先清空缓冲区域
text = "soundn" #待发送的文本
def main():
text_len = len(text)
ecc=0
head = list()
head.append(0xfd)
head.append(0x00)
head.append(text_len + 3)
head.append(0x01)
head.append(0x01)
for i in range(5):
ecc ^= head[i]
ser.write(struct.pack('B',head[i]))#这里必须将转化为bytes类型发送,转为C语言的unsigned char
time.sleep(0.001)
for i in range(len(text):
print(struct.pack('B', ord(exi)))
ecc ^= (ord(text[i]))
ser.write(struct.pack('B', ord(text[i]))
time.sleep(0.001)
ser.write(struct.pack('B',ecc))
time.sleep(0.01)
if __name__ == '__main__':
main()
str = struct.pack("ii", 20, 400)
a1, a2 = struct.unpack("ii", str
print(a1, a2)
20 400
文件的读写
-
要写入字符串到文件中,需要先将字符串编码为字节串。
而从文本文件中读取的文本信息都是字节串,要进行处理之前,必须先将字节串解码为字符串。
文件的打开,分为 文本模式 和 二进制模式。
(1) 文本模式
-
通常对文本文件,都是以文本模式打开。
文本模式打开文件后,我们的程序读取到的内容都是字符串对象,写入文件时传入的也是字符串对象。
(2) 二进制(字节)模式
-
其实就文件存储的底层来说,不管什么类型的文件(文本、视频、图片、word、excel等),存储的都是字节,不存在文本和二进制的区别,可以说都是二进制。
所以 二进制模式 这个名词容易引起大家的误解, 如果让我来翻译,我觉得叫做字节模式更好。
读写文件底层操作读写的 都是字节。
以文本模式打开文件后, 后面的读写文件的方法(比如 read,write等),底层实现都会自动的进行 字符串(对应Python的string对象)和字节串(对应Python的bytes对象) 的转换。
我们可以指定open函数的mode参数,直接读取原始的 二进制 字节串 到一个bytes对象中。
1. open()函数
要读写文件,首先要通过内置函数open打开文件,获得文件对象。
open(
file,
mode='r',
buffering=-1,
encoding=None,
errors=None,
newline=None,
closefd=True,
opener=None
)
其中下面这3个参数是我们常用的。
-
参数file: file参数指定了要打开文件的路径。
file参数指定了要打开文件的路径。
可以是相对路径,比如’log.txt’ ,就是指当前工作目录下面的log.txt文件也可以是绝对路径,比如’ d:\projectlog\log.txt’ -
参数mode:
mode参数指定了文件打开的模式,打开文件的模式决定了可以怎样操作文件。常用的打开模式有
(1) r只读文本模式打开,这是最常用的一种模式函数的缺省值
(2) w只写文本模式打开(创建一个新文件写入内容, 或者清空某个文本文件重新写入内容,就应该使用’w’ 模式)
(3) a追加文本模式打开(从某个文件末尾添加内容,就应该使用’a’ 模式)
(4) rb二进制模式只读
(5) wb二进制模式写 -
参数encoding
encoding参数指定了读写文本文件时,使用的字符编解码方式。
调用open函数时,如果传入了encoding参数值:
后面调用write写入字符串到文件中,open函数会使用指定encoding编码为字节串;后面调用read从文件中读取内容,open函数会使用指定encoding解码为字符串对象
cp936编码觉得很是奇怪,原来cp936就是GBK是对国标的扩展,所以可以比国标GB2312对中文支持的更好些吧。
打开文件的时候,如果要指定打开模式和编码格式.
f = open("文件路径", "r", "utf8")
#这样写是错误的,因为这样这三个都算是位置传参,看open函数的参数第三个参数是buffering故应写为:
f = open("文件路径", "r", encoding = "utf8")
2. 写入文件
#指定编码方式为utf8
f= open('tmp.txt','w',encoding='utf8') # write方法会将字符串编码为utf8字节串写入文件
f.write("白月黑羽: 祝大家好运气”)
#文件操作完毕后,使用close 方法关闭该文件对象
f.close() # 在某些情况下,由于存在缓冲,对文件所做的更改可能要等到您关闭文件后才能显示。
3. 读文件
#指定编码方式为gbk, gbk编码兼容gb2312
f = open('tmp.txt, 'r', encoding = 'gbk')
# read方法会在读取文件中的原始字节串后,根据上面指定的gbk解码为字符串对象返回
content = f.read()
#文件操作完毕后,使用close 方法关闭该文件对象
f.close()
- read函数有参数size, 读取文本文件的时候,用来指定这次读取多少个字符。如果不传入该参数,就是读取文件中所有的内容
例如这样一个文件 tmp.txt
# 文件 tmp.txt
hello
cHl0aG9uMy52aXAgYWxslHJpZ2h0cyByZXNIcnZIZA==
f = open("tmp.txt")
tmp = f.read(3) # read方法读取3个字符
print(tmp) # 返回3个字符的字符串'hel'
tmp = f.read(3) # 继续使用read方法读取3个字符
print(tmp) # 返回3个字符的字符串'lo\n'换行符也是一个字符
tmp = f.read() # 不加参数,读取剩余的所有字符
print(tmp) # 返回剩余字符的字符串'cHl0aG9uMy52aXAgYWxslHpZ2h0cyByZXNlcnZlZA=='
f.close() # 文件操作完毕后,使用close 方法关闭该文件对象
读取文本文件内容的时候,通常还会使用readlines方法,该访法会返回-个列表。列表中的每个元素依次对应文本文件中每行内容。
f = open("tmp.txt")
linelist = f.readlines()
f.close()
for line in linelist:
print(line)
4. 二进制字节模式
(1) 以二进制形式读文件
# mode参数指定为rb就是用二进制读的方式打开文件
f = open("tmp.txt','rb')
content = f.read()
f.close() # 由于是二进制方式打开,所以得到的content是字节串对象bytes
# 内容为b"xe7\x99\xbd\xe6\x9c\x88\xe9\xbb\x91\xe7\xbe\xbd' 白月黑羽
print(content)
#该对象的长度是字节串里面的字节个数,就是12, 每3个字节对应-一个汉字的utf8编码
print(len(content))
(2) 以二进制形式写文件
- 此时传给write方法的参数不能是字符串,只能是bytes对象
# mode参数指定为wb就是用二进制写的方式打开文件
f = open('tmp.txt','wb')
content = '白月羽祝大家好运连连'#二进制打开的文件,写入的参数必须是bytes类型
#字符串对象需要调用encode进行相应的编码为bytes类型
f.write(content.encode("utf8"))
f.close()
如果你想在代码中直接用数字表示字节串的内容,并写入文件,可以这样
content = b"\xe7\x99\xbd\xe6\x9c\x88\xe9\xbb\x91\xe7\xbe\xbd'
f.write(content)
5. 写入缓存
原来,我们执行write方法写入字节到文件中的时候,其实只是把这个请求提交给 操作系统。
操作系统为了提高效率,通常并不会立即把内容写到存储文件中, 而是写入内存的一个缓冲区
等缓冲区的内容堆满之后,或者程序调用close 关闭文件对象的时候,再写入到文件中。
f = open("tmp.t", 'w', encoding='utf8')
f.write("白月黑羽:祝大家好运气) #等待30秒,再close文件
import time
time.sleep(30)
f.close()
执行该程序时,执行完写入文件内容后,会等待30秒,再关闭文件对象。
在这30秒还没有结束的时候,如果你打开tmp.txt,将会惊奇的发现,该文件中啥内容也没有! ! !
如果你确实希望,,在调用write之后, 立即把内容写到文件里面,可以使用文件对象的flush方法。
f = open('tmp.txt,'w' ,encoding='utf8)
f.write("白月羽:祝大家好运气)
#立即把内容写到文件里面
f.flush() #等待30秒,再close文件
import time
time.sleep(30)
f.close()
with语句
如果我们开发的程序在进行文件读写之后,忘记使用close方法关闭文件,就可能造成意 想不到的问题。
我们可以使用with语句打开文件,像这样,就不需要我们调用close方法关闭文件。Python解释器会帮我们调用文件对象的close方法。
# open返回的对象给f赋值, 相当于 f = open('tmp.txt')
with open('tmp.txt") as f:
linelist = f.readlines()
for line in linelist:
print(line)
Python对with的处理还很聪明。基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。
class Sample:
def __enter__(self):
print("In __enter__()")
return "Foo"
def __exit__(self, type, value, trace):
print("In __exit__()")
def get_sample():
return Sample()
with get_sample() as sample:
print(sample)
with语句处理异常
- with真正强大之处是通过__exit__()方法调用可以处理异常。
- Sample类的__exit__方法有三个参数 val, type 和 trace。 这些参数在异常处理中相当有用
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print("type:", type)
print("value:", value)
print("trace:", trace)
def do_something(self):
bar = 1/0
return bar + 10
with Sample() as sample:
sample.do_something()
程序运行:
type: <class 'ZeroDivisionError'>
value: division by zero
trace: <traceback object at 0x7f149de2b1c8>
Traceback (most recent call last):
File "with2.py", line 15, in <module>
sample.do_something()
File "with2.py", line 11, in do_something
bar = 1/0
ZeroDivisionError: division by zero
实际上,在with后面的代码块抛出任何异常时,__exit__()方法被执行。正如例子所示,异常抛出时,与之关联的type,value 和 stack trace传给__exit__()方法,因此抛出的ZeroDivisionError异常被打印出来了\。开发库时,清理资源,关闭文件等等操作,都可以放在__exit__方法当中。因此,Python的with语句是提供一个有效的机制,让代码更简练,同时在异常产生时,清理工作更简单。
函数
函数的调用和创建

函数的返回值
注释参数和返回值的写法
def fun(var: type) -> type: pass
函数的返回值
# (1) 没有返回值的函数
def function(ver: str):
print(var)
# (2) 单个返回值的函数
def function(ver: str) -> dict:
a = [ver,ver,ver]
return a
# (3) 多个返回值的函数
def function(var: str) -> [str, str, bool]:
a=ver
b="BBB"
c=True
return a, b, c
#注解不会做任何处理,只是存储在函数的__annotations__属性(一个字典)中:
print(function.__annotations__)
#打印: {'var': , 'return': [class 'str'>, , ]}
1.函数声明中的各个参数可以在:后增加注解表达式。
2.如果参数由默认值, 注解放在参数名和=号之间。
3.如果注解有返回值, 在)和函数末尾的: 之间增加->和一个表达式。那个表达式可以是任何类型。
函数返回值总结
(1)如果函数没有返回值,return 可以省略不写
(2)函数返回值如果是一个, 直接返回类型
(3)函数的返回值,如果是多个,返回的结果为元组
(4)并不支持给通过函数调用的方式直接给返回值赋值即不支持fun0 = xxx
函数的参数传递

def calc(a: int, b: int) -> None:
print("a= ",a,"b=",b)
calc(3, 4) #打印: a = 3 b= 4 位置实参
calc(b = 3, a = 4) #打印: a= 4 b= 3 关键字实参
def func(arg1, arg2, arg3=3, arg4= 'hello'):
print(arg1)
print(arg2)
print(arg3)
print(arg4)
func(1,2,3,"hello")
#关键字传参
func(arg1 = 1, arg2 = 2, arg3 = 3, arg4= 'hello')
#关键字传参时可以不按照参数的顺序
func(arg2 = 1, arg3 = 2, arg1 = 3, arg4 = 'hello')
#混合使用
func(1, 2, arg3 = 3, arg4='hello")
但是一旦某个参数指定了参数名,后面所有的参数必须指定参数名,像下面这样是不可以
func(1, 2, arg3 = 3, 'hello') #错误的调用方式
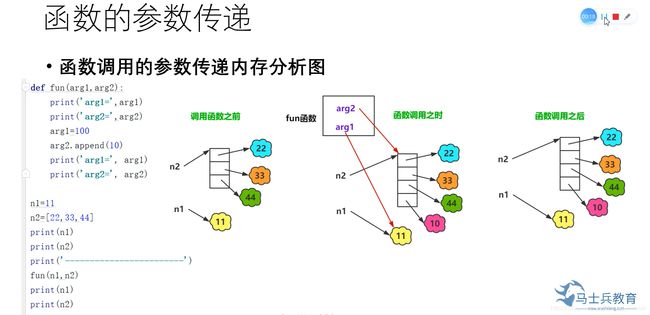
def fun(arg1, arg2):
print(" arg1 id:", id(arg1), "value:" , arg1)
print(" arg2 id:", id(arg2), "value :", arg2)
arg1 = 110
arg2.append(10)
print("arg1 id:", id(arg1), "value :", arg1)
print(" arg2 id :", id(arg2), "value :", arg2)
return
a = 11
b = [1,2,3,4]
print("a id:", id(a), "value:", a)
print("b id:", id(b), "value:", b)
fun(a, b)
print("a id:", id(a), "value:",a)
print("b id:", id(b), "value:",b)
#打印结果
a id: 140173760649440 value: 11
b id: 140173761541960 value: [1,2,3,4]
arg1 id: 140173760649440 value: 11
arg2 id: 140173761541960 value: [1,2,3,4] #到这步为止, arg1和arg2的内存地址还是跟a, b相同
#然后进行arg1 = 110, arg2.append(10),这里将arg1标识符所保存地址修改为指向110这个数据的地址.进行arg2.append(10), 这里通过arg2找到列表存储的地址,然后对该列表增加了一项10数据项,并没有修改arg2所保存的内存地址.因为列表是可变对象支持修改的故并不会产生新对象,支持原地修改arg1 id : 140173760652608 value : 110#可以看到arg1的地址和值均变了arg2 id: 140173761541960 value:[1,2,3, 4, 10] # arg2的地址没变,列表增加了- -项.a id: 140173760649440 value: 11 # 运行完函数后,a的地址没变,值也没变因为只是修改arg1指向的地址b id: 140173761541960 value:[1,2,3, 4, 10] #地址没变, 值变了,因为函数修改的就是list所指向的地址.
函数的参数定义
(1) 函数定义默认值参数
- 函数定义时,给形参设置默认值,只有默认值不符的时候才需要传递实参
def fun(a: int, b: int = 10) -> None:
print("a = ",a, "b = ", b)
#函数调用
fun(100) # 输出: a = 100 b = 10
函数调用的时候,函数的实参是从右往左依次入栈,然后给函数形参从左到右赋值时是依次出栈
故函数形参的默认值只能从参数表最右边开始设置,例如下面这种写法就是错误的写法.
def fun(a: int= 10, b: int)-> None: #错误的写法, a在b的左边, b没有默认值故a不能拥有默认值
print("a = ",a, "b = ", b)
若支持这种写法会出现什么情况,例如我们函数调用f(100);
实参从右到左入栈,这里只有一个实参,故栈中只有一个100,然后再从左到右依次出栈给形参赋值故100赋值给最左边的10,
但此时b并没有默认参数,而且栈中也没有其他数了,故缺少参数.
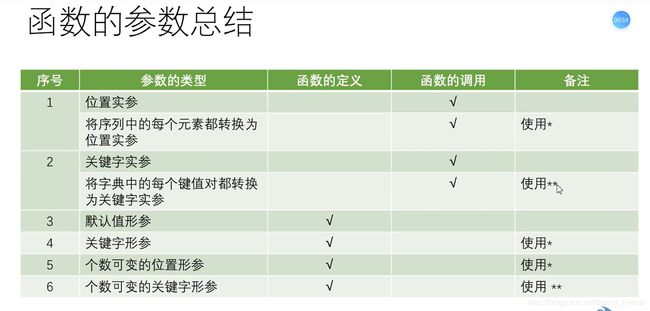
(2)个数可变的位置参数
-定义函数时,如果无法事先确定传递的位置实参的个数时,可以使用可变的位置参数
- 使用*定义个数可变的位置形参
- 其结果为一个元组
(3)个数可变的关键字形参
- 定义函数时,无法事先确定传递的关键字实参的个数,可以使用可变的关键字形参
- 使用**定义个数可变的关键字形参
- 其结果为一个字典
在一个函数中,可变位置参数最多只能有一个, 可变的关键字参数最多也只能有一个
# 1.个数可变的位置形参
def fun(a: int, b: int, *c: tuple) -> None: # c为个数可变的位形参
print("a = ",a,"b = ",b,"c = ",c)
fun(3, 4, 5, 6, 7, 8) #函数调用
#打印输出:a= 3 b = 4 c = (5,6,7,8)
* + 形参标识符,可以接受被其他参数接受后剩下的任意的形参(不包括赋值语句),放进一个元组里,这个元组的名字是前面的标识符(所以位置参数必须在此参数之前)
# 2.个数可变的关键字形参
def fun(a: int, b: int, **c: dict) -> None: # c为个数可变的关键字形参
print("a= ",a, "b=",b,"c= ",c)
fun(3,4,d=4,e=5,f=6) # 函数调用#打印输出: a = 3 b = 4 c = {'d':4, 'e':5, 'f':6}
** +形参标识符,可以接受被其他参数接受后剩下的任意赋值语句,放进一个字典中, 这个字典的名字这个标识符(所有关键字参数和默认参数必须在此参数之前,个数可变的位影参也要在此参数之前)
def f(*arg, a, b, c):显然不对,a, b, c没有默认参数,此时f(3,4,5,6)这样 无法调用,
这种情况只能通过关键字参数调用,def(3,4,5, a = 1,b = 2,c = 3)
def fun(a: int, b: int, C: int) -> None:
print("a = ",a)
print("b = ",b)
print("c =", c)
lst= [11, 22, 33]
fun(lst) # 报错: TypeError: fun0 missing 2 required positional arguments: 'b' and 'c'
#此时只是把lst整个列表当作一个对象赋值给a
fun(*lst) #故需要将序列每个位置转变为位置形参,则函数调用时其实参前面要加一个*,相对于解引用
#打印输出:
a = 11
b = 22
c = 33
同样对于序列也支持迭代器r = range(1,4)
#注意由于fun函数只支持3个位置参数,故迭代器若超过3个或者小于3个均会报错
fun(*r)
#打印输出:
a =1
b= 2
c= 3
(2) 将字典中的每一个键值对都转化为关键字形参
def fun(a: int, b: int, C: int) -> None:
print("a = ",a)
print("b = ",b)
print("c = ",c)
dic = {"a':111, 'b':222,‘':333}
fun(**dic)
#打印输出:
a = 111
b = 222
c = 333
(3) 关键字形参
- 即我们想让函数中的某些参数只能通过关键字传参的方式,而不能通过位置参数进行传参
#此时*关键字形参后面的参数c,d在函数调用时只能关键字传参,同时*前面的a, b不能使用关键字传参
def fun(a: int, b: int, *, c: int, d: int) -> None:
print("a = ",a)
print("b = ",b)
print("c = ",c)
print("d = ",d)
fun(1,2,3,4) # 报错: TypeError: fun0 takes 2 positional arguments but 4 were given
# 函数只提供2个位置形参,但调用时却传入4个位置实参
fun(1,2,c=3,d=4)
#打印输出:
a = 1
b = 2
c = 3
d = 4
若此时像上面这种c,d形参均没有默认参数则调用fun只能采用上面的形式
(1) 函数传入实参时,可变参数(*)之前的参数不能指定参数名
>>> def myfun(a, *b):
print(a)
print(b)
>>> myfun(a=1, 2,3,4)
File "" , line 1SyntaxError: positional argument follows keyword argument>>> >>>myfun(1,2,3,4)
1
(2,3,4)
变量的作用域

a = 100
def fun()-> None:
print("__________call__________")
print(a)
a = 3
print(a)
print("__________end___________")
fun()
print(a)
运行上述代码
__________call__________
Traceback (most recent call last):
File "global.py", line 11, in <module>
fun()
File "global.py", line 6, in fun
print(a)
UnboundLocalError: local variable 'a' referenced before assignment
报错, local variable ‘a’ referenced before assignment, 在函数外定义了一个变量 a ,然后在python的一个函数里面引用这个变量,并改变它的值,结果报错local variable ‘a’ referenced before assignment,报错原因是:python的函数中和全局同名的变量,如果你有修改变量的值就会变成局部变量,对该变量的引用自然就会出现没定义这样的错误了。
将上述代码进行修改
a = 100
def fun()-> None:
print("__________call__________")
a = 3
print(a)
print("__________end___________")
fun()
print(a)
运行上述代码
__________call__________
3
__________end___________
100
可知此时fun函数中的a其实是局部变量, 为什么上面一个例子中的a是全局变量呢?, 因为上面一个例子中, 我们先进行了print(a) 操作, 此时a只可能是全局变量, 故导致此时a这个标识符在fun函数中就是被看作一个全局变量, 而在这个例子我们直接进行了 a = 3这步操作相当于直接又声明了一个新的标识符与全局变量a并没有关系
接着修改
a = 100
def fun()-> None:
global a
print("__________call__________")
print(a)
a = 3
print(a)
print("__________end___________")
fun()
print(a)
运行上述代码得到:
__________call__________
100
3
__________end___________
3
在fun函数中我们这一句 global a, 使得我们在fun函数中使用的a都被当作是全局变量,故在函数中修改a指向的数据,
导致最后打印的print(a) 是已被修改后的数据
异常
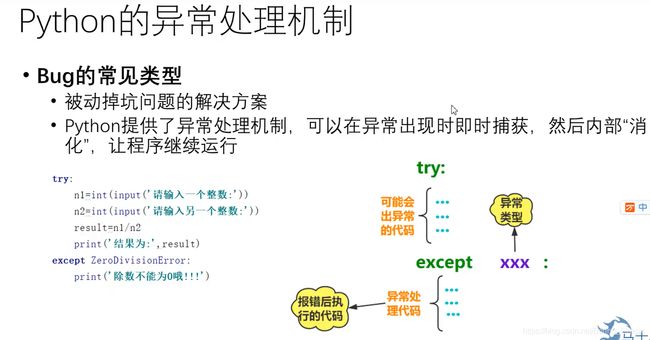
异常处理的语法结构


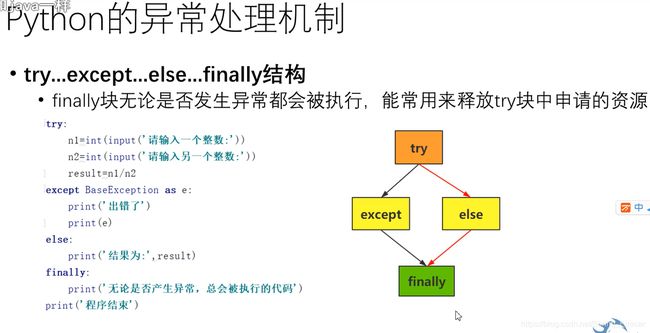
try:
a, b = map(int, input().split())
res= a / b
except BaseException as e:
print(e)
else:
print(res)
finally:
print("end")
#运行
#输入3,4
#输出:
0.75
end
#输入3, 0
#输出:
division by zero
end
常见错误类型和继承关系
(1) 常见的异常类型
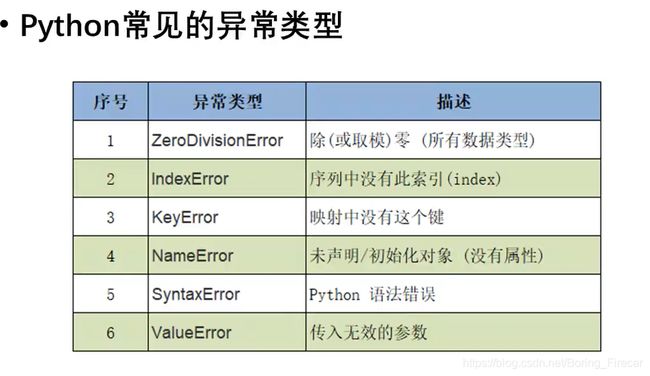
(2) 异常类型的继承关系
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StandardError
| +-- BufferError
| +-- ArithmeticError
| | +-- FloatingPointError
| | +-- OverflowError
| | +-- ZeroDivisionError
| +-- AssertionError
| +-- AttributeError
| +-- EnvironmentError
| | +-- IOError
| | +-- OSError
| | +-- WindowsError (Windows)
| | +-- VMSError (VMS)
| +-- EOFError
| +-- ImportError
| +-- LookupError
| | +-- IndexError
| | +-- KeyError
| +-- MemoryError
| +-- NameError
| | +-- UnboundLocalError
| +-- ReferenceError
| +-- RuntimeError
| | +-- NotImplementedError
| +-- SyntaxError
| | +-- IndentationError
| | +-- TabError
| +-- SystemError
| +-- TypeError
| +-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
自定义异常和主动抛出异常
(1) raise语句
- 有时候python自带异常不够用,如同java, python也可以自定义异常, 粗可以手动抛出。注意, 自定义异常只能由自己抛出。python解释器是不知道用户自定义异常是什么鬼的。
主动抛出异常。格式:主动抛出异常终止程序
raise 异常名称('异常描述')
raise RuntimeError('testerror")
(2)自定义异常
- python的异常有个大基类。然后继承的是Exception。 所以我们自定义类也必须继承Exception。
#最简单的自定义异常
class FError(Exception):
pass
try:
raise FError("自定义异常")
except FError as e:
print(e)
(3)自定义异常类模板
class CustomError(Exception):
def __init__(self,ErrorInfo):
super().__init__(self) #初始化父类
self.errorinfo = ErrorInfo
def __str__(self):
return self.ErrorInfo
if __name__ == '__main__':
try:
raise CustomError("客户异常")
except CustomError as e:
print(e)
traceback模块
- traceback模块是用来跟踪异常返回信息的
import traceback
try:
raise SyntaxError"traceback test"
except:
traceback.print_exc()
#打印信息:
File "raise.py", line 3
raise SyntaxError"traceback test"
^
SyntaxError: invalid syntax
类
类的创建

在Python类中规定,实例方法的第一个参数是实例对象本身 ,组约定俗成,把其名字写为self。其作用相当于java中的this, 示当前类的对象,可以调用当前类中的属性和方法。
class是面向对象的设计思想,instance (也即是object,对象)是根据class创建的一个类(class) 应该包含数据和操作数据的方法,通俗来讲就是属性和函数(即调用方法)
在python中,类是通过关键字class定义的: .
#class后面紧跟类名,即Person,类名通常大写字母开头,紧接着是(object),表示该类是从哪个类继承下来的,
#通常,如果没有合适的继承类,就使用object类, 这是所有类最终都会继承的类
class Person(object):
pass
(1)将Person类实例化,创建实例化是通过类名+()实现的
class Person(object):
pass
student = Person() # 创建类的实例化
print(student)
print(Person)
#打印输出
<__main__.Person object at 0x7fb81e096470>
<class '__main__.Person'>
可以看到,变量student指向的就是一个 Person的object,后面的0x0000026EE434D8D0 是内存地址,
每个object的地址都不一样, 而Person本身则是一个类
(2) 可以给实例变量绑定属性,比如:为student绑定name和score属性, python的类支持动态绑定属性,非常灵活
class Person(object):
pass
student = Person()
student.name = "Gavin" #为实例变量student绑定name属性类似于赋值操作
student.score = 100 #为其绑定score 属性print(student.name)print(student.score)
(3)类的 __init__方法
创建实例的时候,可以将我们认为必须绑定属性强制填写进去,在python中,是通过类中通常都会使用的一个方法,即def __init__(self) 方法,在创建实例变量的时候,就把name和score等属性绑上去
class Person(object):
def __init__(self, name, score):
self.name = name
self.score = score
student = Person('Gavin', 100) #传入 __init__方法中需要的参数
print(student.name)
print(student.score)
注意:
-
__init__ 方法的第一个参数永远是self,示创建的实例本身,因此,在__init__ 方法的内部,就可以把各种属性绑定到self, 因为self就指向创建的实例本身
-
使用了__init__方法,在创建实例的时候必须传入与__init__方法匹配的参数可以有默认参数,但是self不需要传,python解释器会自己把实例变量传进去
(4)类的其他实例方法
class Person(object):
def __init__(self, x, y):
self.x = x
self.y = y
def square(self):
squr = pow(self.x, 2) + pow(self.y, 2)
return squr
def add_square(self,z): #调用时传入变量,这也是个普通的局部变量,非实例变量
c = self.add()+self.square() + z # 同样这里调用如果c = add() + square() + z,同样未定义
return c
def add(self,z=16):
sum = self.x + self.y + z #不能写成 sum=x + y + z,不然会报x, y未定义
return sum
student = Person(3,4)
print(student.add())
print(student.square())
print('------------------')
print(student.add_square(16))
上述代码运行:
23
25
------------------
64
- self代表类的实例,而非类; self就是对象/实例属性集合
上面的例子中print(student.__dict__) #打印的就是self本身, self只存储属性,并没有方法#打印:{'x:3, 'y':4}
- self看似是整个对象,实际上清楚地描述了类就是产生对象的过程,描述了self就是得到了对象,所以self内的键值可以直接使用
class Box(object):
def mylnit(mySelf, boxname, size, color):
print(mySelf.__dict__) # 显示为{}空字典
mySelf.boxname = boxname
mySelf.__dict__['aa'] = 'w' #甚至可以像字典一样操作
mySelf.size = size
mySelf.color= color #自己写一个初始化函数,一样奏效甚至不用self命名。其它函数当中用标准sel
return mySelf #返回给实例化过程一个对象! 神奇!并且含有对象属性/字典
# def_ init_ (self, boxname, size, color):
# self.boxname = boxname
# self.size = size
#self.color = color #注释掉原来标准的初始化
def open(self, myself):
print(self)
print('-->用自己的myself,打开那个%s,%s的%s' % (myself.color,myself.size,myself.boxname)
print('-->用类自己的self,打开那个%s,%s的%s' % (self.color, self.size,self.boxname))
def close(self):
print('-->关闭%s,谢谢' % self.boxname)
#经过改造,运行结果和标准初始化没区别
b = Box().myInit('魔盒', '14m', '红色')
#b= Box(魔盒', '14m',红色") #注释掉原来标准的初始化方法
b.close()
b.open(b) #本来就会自动传一-个self, 现在传入b,就会让open多得到一个实例对象本身,print看看是什么。
print(b.__dict__) #这里返回的就是self本身,self存储属性, 没有动作。
print(b.aa)
#上述代码运行, 打印输出
{}
-->关闭魔盒,谢谢
<__main__.Box object at 0x7f92aecad6a0>
-->用自己的myself, 打开那个红色, 14m的魔盒
--> 用类自己的self,打开那个红色, 14m的魔盒
{"boxname': '魔盒’, 'aa': 'w', 'size': '14m', 'color': '红色'}
注意此处的: mySelf.__dict__['a']= 'w' #甚至可以像字典一样操作; 在b._ _dict_ 的结果 中显示为: 'a:w'
类属性/类方法/静态方法

(1) 类属性
实例属性每个实例各自拥有,相互独立; 而类属性有且只有1份,创建的实例都会继承自唯一的类属性。意思就是绑定在一个实例上的属性不会影响到其它的实例。如果在类上绑定-一个属性, 那么所有的实例都可以访问类属性,且访问的类属性是同一个,一旦类属性改变就会影响到所有的实例
class Person(object):
school = "XXXX" #类属性
def __init__(self, name, score):
self.name = name #实例属性
self.score = score #实例属性
print(Person.school) #类属性不用实例化对象能直接访问,是所有这个类所有实例共有的
#支持动态绑定类属性
Person.a = "a"
#同样也通过实例访问
st = Person("bob", 98)
print(st.school)
#例:请给Person类添加一个类属性count,每创建一个实例,count 属性就加1,这样就可以统计出-共创建了
#多少个Person的实例
class Person(object):
count=0
def __init__(self, name):
self.name = name
Person.count += 1
p1 = Person("Bob')
print(Person.count) # 1
p2 = Person('Alice'")
print(Person.count) # 2
p3 = Person("Tim")
print(Person.count) # 3
#当实例属性和类属性重名时,实例属性优先级高,它将屏蔽掉对类属性的访
p1.count= 666
print(p1.count) # 666 此时访问的是实例属性count = 666
print(p2.count) # 3 上面只是给p1这个实例绑定了count, p2, p3只有count这个类属性
print(p3.count) #3
(2) 类方法
- Python类方法和实例方法相似,它最少也要包含一个参数,只不过方法中通常将其命名为cls, Python会自动将类本身绑定给cls参数(注意,绑定的不是类对象)。也就是说,我们在调用类方法时,无需显式为cls参数传参。和self一样, cls参数的命名也不是规定的(可以随意命名)
#和实例方法最大的不同在于,类方法需要使用@classmethod修饰符进行修饰,例如:
class Person:
#类构造方法,也属于实例方法
def __init__(self):
self.name = "哈哈哈"
self.add = "12345"
#下面定义了一个类方法
@classmethod # 如果没有@classmethod修饰,则Python解释器会将info()方法认定为实例方法,而不是类方法
def info(cls):
print("正在调用类方法",cls)
#类方法推荐使用类名直接调用,当然也可以使用实例对象来调用(不推荐)。
# (1)直接类名调用
Person.info() #正在调用类方法(3)静态方法
- 静态方法,其实就是我们学过的函数,和函数唯一 的区别是,静态方法定义在类这个空间(类命名空间)中,而函数则定义在程序所在的空间(全局命名空间)中。
静态方法没有类似self、cls 这样的特殊参数,因此Python解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
# 静态方法需要使用@staticmethod修饰,例如:
class Person:
def_ init_ (self):
self.name = "哈哈哈"
self.add = "12345"
#下面定义了一个静态方法
@staticmethod
def info():
print("正在静态类方法")
#静态方法的调用,既可以使用类名,也可以使用类对象,例如:
Person.info()
p1 = Person()
p1.info()
在实际编程中,几乎不会用到类方法和静态方法,因为我们完全可以使用函数代替它们实现想要的功能,但在一些特殊的场景中(例如工厂模式中) , 使用类方法和静态方法也是很不错的选择。
类的封装

在Python中,有以下几种方式来定义变量:
xx:公有变量
_xx:单前置下划线,私有化属性或方法,类对象和子类可以访问,from somemodule import *禁止导入
__xx:双前置下划线,私有化属性或方法,无法在外部直接访问(名字重整所以访问不到)
__xx__:双前后下划线,系统定义名字(不要自己发明这样的名字)
xx_ :单后置下划线,用于避免与Python关键词的冲突
# 对于类的私有属性
class Person:
s = "hello"
def __init__(self):
self.name = "哈哈哈"
self.add = "12345"
self.__num = 666 # 私有属性
def show(self):
print(self.name, self.add, self.__num)
p1 = Person()
p1.show() #哈哈哈 12345 666
print(p1.name) #哈哈哈
print(p1.add) # 12345
print(p1.__num) # AttributeError: 'Person' object has no attribute '__num'
#这里直接通过实例p1,来对__num 访问说是没有这个属性,使用dir查看该实例有哪些属性和方法
print(dir(p1))
['_Person__num', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'add', 'name', 's', 'show']
#我们可以找到add, name这两项属性,还有__init__和show这两个方法.#我们没有找到num,但是有一项 _Person__num, 这里__num的名字已经被重整为 ”_Person__num” 了.
print(p1._Person__num) # 666
#注:虽然私有变可以通过 _类名__变量名来访问,但强烈建议不要这样做
单前置下划线的使用方法在使用不同方法导入模块后,否能使用模块中的私有属性和方法,有以下两种情况在使用from somemodule import *导入模块的情况下,不能导入或使用私有属性和方法在使用import somemodule导入模块的情况下,能导入并使用私有属性和方法
# test.py 文件
num = 10
_num = 20
__num = 30
def test():
print("---test---")
def _test2():
print("---test2---")
def __test3():
print("---test3---")
交互模式下测试
>>> from test import *
>>> num
10
>>> _num
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name '_num' is not defined
>>> __num
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name '__num' is not defined
>>> test()
---test---
>>> _test2()
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name '_test2' is not defined
>>> __test3()
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name '__test3' is not defined
>>> import test
>>> test.num
10
>>> test._num
20
>>> test.__num
30
>>> test.test()
---test---
>>> test._test2()
---test2---
>>> test.__test3()
---test3---
当然这里也可以用 from test import _num 这样也可以访问得到
类的继承

class Animal(object):
def __init__(self, name):
self.name = name
def greet(self):
print("Hello, I am %s" % self.name)
class Dog(Animal): #这里Dog并没有实现 __init__, 这里DOG类继承了Animal的 __init__
def greet(self): #重写了父类的greet的方法
super().greet()
print("WangWang...")
#在上面,Animal 是父类,Dog是子类,我们在Dog类重定义了greet方法,为了能同时实现父类的功能,
#我们又调用了父类的方法,看下面的使用:
>>> dog = Dog('dog')
>>> dog.greet()
Hello, I am dog.
WangWang...
super()函数是用于调用父类(超类)的一个方法。
super(函数是用于调用父类(超类)的一个方法。
# super的一个最常见用法可以说是在子类中调用父类的初始化方法了,比如:
class Base(object):
def __init__(self, a, b):
self.a = a
self.b = b
class A(Base):
def __init__(self, a, b, c):
super().__init__(a, b)
self.c = c
深入super
看了上面的使用,你可能会觉得’super’的使用很简单,无非就是获取了父类,并调用父类的方法。其实,在上面的情况下,super获得的类刚好是父类,但在其他情况就不一定了,super其实和父类没有实质性的关联。
让我们看一个稍微复杂的例子, 涉汲到多重继承,代码如下:
class Base(object):
def __init__(self):
print("enter Base")
print("leave Base")
class A(Base):
def __init__(self):
print("enter A")
super(A, self).__init__() # 这里是py2的写法, py3可以写作super().__init__()
print("leave A")
class B(Base):
def __init__(self):
print("enter B")
super(B, self).__init__()
print("leave B")
class C(A, B):
def __init__(self):
print("enter C")
super(C, self).__init__()
print("leave C")
obj = C()
上述类的继承关系
Base
/ \
A B
\ /
C
上述代码运行输出
enter C
enter A
enter B
enter Base
leave Base
leave B
leave A
leave C
如果你认为 'super’代表[调用父类的方法,那你很可能会疑惑为什么 enter A的下一句不是enter Base而是enter B。原因是, 'super 和父类没有实质性的关联,现在让我们搞清’super’是怎么运作的。
MRO 列表 (Method Resolution Order 方法解析顺序表)
事实上,对于你定义的每一个类, Python计算出一个方法解析顺序列表(MRO),它代表了类继承的顺序,我们可以使用下面的方式获得某个类的MRO列表:
print(C.mro())
#或者C.__mro__
#或者通过实例obj.__class__.mro()
#打印得到
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.Base'>, <class 'object'>]
那这个 MRO 列表的顺序是怎么定的呢,它是通过一个 C3 线性化算法来实现的,这里我们就不去深究这个算法了,感兴趣的读者可以自己去了解一下,总的来说,一个类的 MRO 列表就是合并所有父类的 MRO 列表,并遵循以下三条原则:
- 子类永远在父类前面
- 如果有多个父类,会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
super工作原理
def super(cls, inst): mro = inst.__class__.mro() return mro[mro.index(cls) + 1]
其中,cls 代表类,inst 代表实例,上面的代码做了两件事:
- 获取 inst 的 MRO 列表
- 查找 cls 在当前 MRO 列表中的 index, 并返回它的下一个类,即 mro[index + 1]
首先看类C的 __init__方法:
这里的self是当前C的实例,self.__class__.mro() 结果是:
[__main__.C, __main__.A, __main__.B,__main__.Base, object]
可以看到,C的下一个类是A,于是,跳到了A的__init__, 这时会打印出enter A,并执行下面一行代码:
super(A, self).__init__()
注意,这里的self也是当前C的实例,MRO列表跟上面是一样的, 搜索A在MRO中的下一个类,发现是B,于是,跳到了B的__init__, 这时会打印出enter B,而不是enter Base。
C3算法手动模拟
class F:
pass
class E:
pass
class D:
pass
class B(D,E):
pass
class C(D,F):
pass
class A(B,C):
pass
上面各类的继承关系
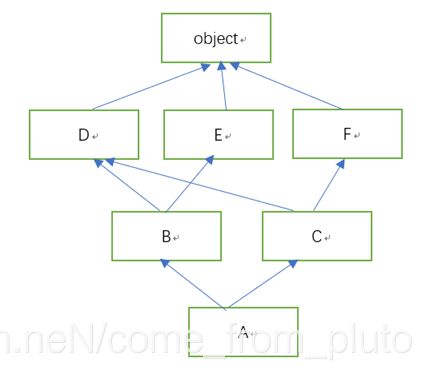
接下来开始计算出对应的MRO, 遵循的规则为广度优先遍历, 在这个规则的前提下又优先遍历左边的;
首先寻找整个图中入度为0的点, 也就是A, 那么A就成为MRO中的第一个。
然后去掉图中A节点及其A相关的连线, 再次寻找入度为0的点, 这时有B和C, 优先选择左边, 故这样B, C也跟着进入了MRO序列,现在MRO序列为 {A, B, C}, 注意每次遍历一定要把当前层选完才能遍历下一层。
再次去掉B, C以及相关的连线, 这时候入度为0也就是D, E, F,依次选择D, E, F进入MRO序列.
最后也使得object进入MRO序列
#将上诉代码改为
class A(C,B):
pass
#其MRO表又会有所不同其第一个父类C必定在另-个父类B的前面
方法重写
class Person:
def __init__(self, name, num):
self.name = name
self.num = num
def info(self):
print(self.name, self.num)
class Student(Person):
def __init__(self, name, num, hobby):
super().__init__(name, num)
self.hobby = hobby
def info(self): #写父类Person的info方法
super().info()
print(self.hobby)
st = Student("Bob", 502, "football")
st.info()
#运行上述代码输出打印:
Bob 502
football
object类和特殊属性

class Person:
pass
print(dir(Person))
# 打印得到
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
# Person类中并没有写任何东西, dir打印的结果全都是由object类继承过来的
p1 = Person()
print(p1) # 打印<__main__.Person object at 0x7f4391e67e48>默认调用__str__方法,打印地址
#现在添加Person的属性和方法
class Person:
def __init__(self, name, age):
self.name = name :
self.age = age
def __str__(self):
return f"the name is {self.name}, the age is {self.age}"
p1 = Person("Bob", 12)
print(p1) # the name is Bob, the age is 12. # 重写 __str__方法后打印的不是地址
| 名称 | 描述 | |
|---|---|---|
| 特殊属性 | __dict__ | 获得类对象或类实例对象所绑定的属性和方法的字典 |
| __class__ | 对象或类所属的类 | |
| __bases__ | 输出直接父类类型元素的元组 | |
| __base__ | 输出第一个直接父类 | |
| __mro__ | 输出方法解析顺序列表 | |
| __subclasses__ | 输出子类的列表 | |
| __doc__ | 类、函数的文档字符串,如果没有定义则为None | |
| 特殊方法 | ||
| __len__() | 通过重写该方法, 让内置函数len的参数可以是自定义类型 | |
| __add__() | 通过重写该方法, 让自定义函数具备 “+” 的功能 | |
| __new__() | 用于创建对象 | |
| __init__() | 对创建的对象进行初始化 |
#1.__add__()方法
a, b= 20, 100
c=a+b
#等价于两个整数类型的对象相加操作
d=a.__add__(b)
class Student:
def __init__(self, name):
self.name = name
def __add__(self, other):
return self.name + other.name
s1 = Student("Tom")
s2 = Student("Bob")
s = s1 + s2 #两个对象相加等价 s = s1.__add__(s2)
print(s) #输出TomBob
#2. __len__()方法
lst=[1,2,3, 4]
print(len(st)) #输出4
#等价形式
print(st.__len__()) #输出4
#如果不重写__len__()将自定义类型传入
print(len(s1)) # TypeError .object has no len()
#在上面的Student类中重写__len__()方法
def __len__(self):
return len(self.name)
print(len(s1)) #打印3,因为s1.name = "Tom",字符个数为3
__new__()方法 和 __init__()方法
class Person:
def __new__(cls, *args, **kwargs):
print(f"new方法被调用, cls = {id(cls)}")
print(args)
obj = super().__new__(cls)
print("obj的地址为: {0}".format(id(obj)))
return obj
def __init__(self, name, age):
print(f"__init__()被调用, self的地址为: {id(self)}")
self.name = name
self.age = age
print(f"Person类的地址为:id(Person)}")
p1 = Person("Tom", 12)
#打印输出:
Person类的地址为:14701128 # 15 line
new方法被调用, cls的地址为14701128 # 3 line
('Tom', 12) # 4line
obj的地址为: 139943584380296 # 6 line
__init__被调用, self的地址为: 139943584380296 # 10 line
#可以看到 __new__先被调用, 然后其args参数即传入的参数,不过这里并没有对args作处理
#然后打印了__new__参1的地址, 这个地址就是Person类的地址.
# __new__中调用父类的__new__最后返回一个obj,并打印这个返回的obj的地址
#然后调用__init__方法, 此时打印实例对象self的地址,发现这个地址就是new_中调用父类的_ new_ 返回的obj的地址
#故二者的关系就是创建一个实例对象时, 先通过__new__创建出一片空间,然后将这个地址返回,这个地址即实例对象地址
#然后__init__对这个地址进行初始化操作。
注意:
这里的__new__的至少有一个参1, cls;
多态
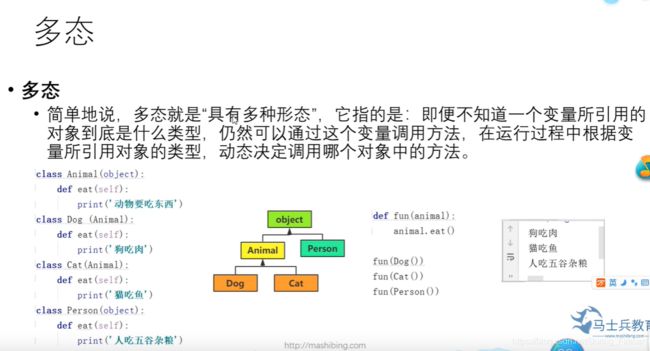
class Animal(object):
def eat(self):
print("动物要吃东西")
class Dog(Animal):
def eat(self):
print("狗吃肉")
class Cat(Animal):
def eat(self):
print("猫吃鱼")
class Person(object):
def eat(self):
print("人吃五谷杂粮")
def fun(obj):
obj.eat()
fun(Dog())
fun(Cat())
fun(Person())
#打印输出
狗吃肉
猫吃鱼
人吃五谷杂粮
这里我们定义一个fun函数 ,其内部实现为调用传入参数obj对象的eat方法,然后我们看出根据给fun传不同类型的参数我们发现其输出不相同,即函数本身的输出只跟变量所引用的类型有关,最后调用运行过程中根据变量的类型动态调用对象中的方法。这里fun(Dog()) 和 fun(Cat())就是典型的多态, 其实现基于继承的都是同一个父类然后对父类进行了写但对于Person类,它跟Animal类并没有关系,但依旧能调用,看起来具有多态的效果,而其实现是基于其类同样实现了一个叫eat的方法.

浅拷贝和深拷贝

(1) 变量的赋值操作
class A:
def __init__(self, a1, a2):
self.a1 = a1
self.a2 = a2
def show(self):
print(f"a1 = {self.a1}, a2 = {self.a2}")
class B:
def __init__(self, b1, b2):
self.b1 = b1
self.b2 = b2
def show(self):
print(f"b1 = {self.b1}, b2 = {self.b2}")
class C:
def __init__(self, obj_A, obj_B):
self.obj_A = obj_A
self.obj_B = obj_B
a= A(1,2)
b= B(3,4)
c1 = C(a, b)
c2 = c1
#赋值操作
print(c1 is c2)
#输出True c1 和c2指向同一内存地址,故属于赋值操作,并没有发生拷贝行为,只是地址赋值
(2)浅拷贝
import copy
a = A(1, 2)
b = B(3, 4)
c1 = C(a, b)
c2 = copy.copy(c1) # 浅拷贝
print(c1 is c2) # False, 说明此时c1和c2指向的是不同的地址区域
print(id(c1), id(c1.obj_A), id(c1.obj_B))
print(id(c2), id(c2.obj_A), id(c2.obj_B))
#打印输出
140266669242744 140266669242408 140266669242520
140266668749600 140266669242408 140266669242520
c1和c2都是C类对象的实例,从上面的打印可以看出,这是两个不同的实例,因为其id(c1) != id(c2),
但我们发现其子对象具有相同的地址,因为c1实例对象的两个实例属性为a和b,但这里虽然拷贝了但只是源对象的拷贝,
即重新又创建了C1的实例空间,但c1的两个实例属性并没有重新开辟-块新的空间,依然是原本a,b
c1.obj_A.a1 = 666
print(c2.obj_ A.a1) #输出666, 说明c2的子对象和c1是引用同一块地址
(3)深拷贝
import copy
a= A(1,2)
b= B(3, 4) .
c1 = C(a, b)
c2 = copy.deepcopy(c1) # 深拷贝
print(id(c1), id(c1.obj A), id(c1.obj B))
print(id(c2), id(c2.obj_ A), id(c2.obj_ B))
#打印输出
140178954398128 140178954397792 140178954397904
140178953905264 140178953966480 140178953966816
此时c1和c2的实例对象地址不相同,它们子对象的地址也不相同。说明源对象实例和其子对象实例都重新开辟了新的地址空间
c1.obj_A.a1 = 666
print(c2.obj_A.a1) #输出1,说明c2的子对象和c1并不是同-一个地址的引用, c1子对象的改变不会影响c2子对象
模块和库
- 一个模块就是一个py文件, 包含了这个文件所有的变量, 语句, 函数
导入模块
项目开发的的代码文件,可能有成百上千个。不同的代码文件,实现了不同的功能模块,就像一块块积木一 样。 这些功能模块文件最后合起来,实现了-个完整的软件。所以,在Python中,一个代码文件(也就是一个.py文件),我们也叫它一个模块(Module) 。
比如:
a.py文件,我们就可以称之为模块a,
b.py文件,我们就可以称之为模块b
(1)如果在一个模块文件中需要导多个其它模块
import aa, bb, CC
(2)如果我们要从1个模块里导入多个标识符,可以这样
from aa import func1, var1, func2, var2
from aa import* # 把aa模块所有可以导入的对象全部都导入了。
(3)如果我们需要从两个模块导入函数,恰好这两个函数是同名的,这是我们可以给其中一个起个别名,避兔冲突,比如
from save import savetofile
from save2 import savetofile as savetofile2
注意事项
当一个b模块从a模块导入了名字var1后,注意,b模块和a模块是各自有一个名为var1的变量,而不是两个模块共享一个名为var1的变量。
# a.py
var1 = 1
def changeVar1():
global var1
var1 = 2
def a_print():
print(f'in a: var1 is {var1}')
另外一个模块文件b.py, 从a中导入了名字var1 ,如下
# b.py
from a import var1, changeVar1, a_print
changeVar1()
print(f'in b: var1 is {var1}')
a_print()
当我们执行b.py文件时显示结果如下
in b: var1 is 1
in a: var1 is 2
从b.py文件开始分析,这里从a模块导入了名字var1, changeVar1, a_print. 然后调用了a模块的changeVar1()函数,该函数的作用是改变var1的值,然后接着下一句我们打印了var1的值发现并没有改变,而我们调用a模块中a_print()函数打印a模块中的var1值,发现是改变的值,在刚刚执行导入时,这两个var指向同一个对象,但是后来可以通过赋值语句,分别指向不同的数据对象。
如果要在多个模块中共享同一个数据对象,并且这个数据对象的值将来可能会改变。
即使共享的只是一个数字或者字符串变量, 也应该放在一个值可以变动的对象类型中,比如列表
# a.py
var1 = [1]
def changeVar10:
global var1
var1[0]= 2
print(f'in a: var1 is {var1}')
# b.py
from a import var1, changeVar1
changeVar1()
print(f'in b: var1 is {var1}')
#执行b.py文件
in a: var1 is [2]
in b: var1 is [2]
模块放入包中
当我们的项目模块文件特别多的时候,我们还需要将这些模块文件根据功能划分到不同的目录中。
这些放模块文件的目录,Python中把他们称之为包(Package)。
在Python 3.3以前的版本,包目录里面需要有一个名字为__init__.py 的初始化文件,有了它,Python才认为这是一个Python包。_
通常,这个初始化文件里面不需要什么代码,一个空文件就可以了。
当然你也可以在里面加入代码,当这个包里面的模块被导入的时候,这些代码就会执行。
Python 3.3以后版本的解释器,如果目录只是用来存放模块文件,就不需要一个空的__init__.py了
但是__init__.py 可以作为包的初始化文件,里面放入-些初始化代码,有独特的作用
下面是一个商城产品目录结构的例子
stock/ --- 顶层包
__init__.py --- stock包的初始化文件
food/ --- food子包
__init__.py
pork.py
beef.py
lobster.py
...
furniture/ --- furniture子包
__init__.py
bed.py
desk.py
chair.py
...
kitchen/ --- kitchen子包
__init__.py
knife.py
pot.py
bowl.py
...
最上层的是stock包,里面有3个子包 food、furniture、kitchen。
每个子包里面的模块文件都有名为stockleft的函数,显示该货物还剩多少件。
如果我们要调用这些模块里面的函数,可以像这样:
import stock.food.beef
# 注意导入的是 stock.food.beef,调用的时候一定要加上所有的包路径前缀
stock.food.beef.stockleft()
# 我们也可以使用from…import… 的方式,像这样
from stock.food.beef import stockleft
stockleft()
库的概念
如果你写的模块文件里面的函数,实现了通用的功能,经常被其它模块所调用,我们就可以把这些被调用的模块文件称之为库,库是个抽象的概念,只要某个模块或者一组模块,开发它们的目的就是给其它模块调用的,就可以称之库。
Python语言提供了功能丰富的标准库 。 这些标准库把开发中常用的功能都做好了。
我们可以直接使用它们。
这些标准库里面 有一部分叫做 内置类型(built-in types)和 内置函数(built-in functions)。
内置类型 和 内置函数 无须使用import导入,可以直接使用。
内置类型有:int、float、str、list、tuple
内置函数有: int,str,print,type,len 等等
还有些标准库,需要使用import导入,才能使用。
常见有 sys, os, time, datetime, json,random 等
比如,我们要结束Python程序,就可以使用sys库里面的exit函数
import sys
sys.exit(O)
命令行参数
$ python temp.py a b c d #运行
sys.argv == ["temp.py", "a","b","c","d"] #sys.argv是持有 5个元素的list对象
详解: argv是sys模块的一个全局变量,也称sys模块的一一个属性! argv本身为一个list类型的对该对象持有的第1个元
素是命令行中传入的模块名、从第2个元素开始(含),均为命令行中传入的参数!
注意: argv持有的每个元素的类型均为str (字符串)
比如,我们要得到字符串形式的当前日期和时间,可以使用datetime库
import datetime
#返回这样的格式'20160423'
datetime.date.today().strftime("%Y%m%d")
#返回这样的格式'20160423 19:37:36'
datetime.datetime.now0.strftime("%Y%m%d %H:%M:%S")
os模块
import os
print(os.getcwd()) #获取当前工作目录路径
print(os.path.abspath('.')) #获取当前工作目录路径
print(os.path.abspath('test.txt')) #获取当前目录文件下的工作目录路径
print(os.path.abspath("..") #获取当前工作的父目录!注意是父目录路径
print(os.path.abspath(os.curdir) #获取当前工作目录路径
比如,我们要获取随机数字,可以使用random库
from random import randint
#在数字1到8之间(包括1和8本身),随机取出一个数字
num = randint(1,8)
print(num)
解释器怎么寻找模块文件
(1)首先在解释器内置模块中寻找
当解释器看到这样的语句时
import xx
from xxx import yyy
它首先在解释器内置模块(builtin modules)中寻找 否有xxx。
所谓内置模块,就是内置在Python解释器程序中的模块,它们是用C语言编写,编译链接在解释器里面。
也就是说它们就是解释器的一部分,所以解释器运行时,它们就在解释器里面,无需查找。
比如: time, sys, gc, math, mmap等,就是内置模块
可以通过sys.builtin_module_names的值来查看哪些模块是直接包含在解释器里面的。
('_ast', '_codecs', '_collections', '_functools', '_imp', '_io', '_locale', '_operator', '_signal', '_sre', '_stat', '_string', '_symtable', '_thread', '_tracemalloc', '_warnings', '_weakref', 'atexit', 'builtins', 'errno', 'faulthandler', 'gc', 'itertools', 'marshal', 'posix', 'pwd', 'sys', 'time', 'xxsubtype', 'zipimport')
很容易把内置模块和前面提到的内置类型、内置函数这些名词搞糊涂。
概念上内置类型、内置函数应该也是属于内置模块的,在名叫builtins的内置模块里面。
内置类型、内置函数因为它们特别常用,所以被解释器特别优待,可以无需导入直接使用。
(2)在内置模块未找到,依次寻找sys.path包含的目录
#打印:
/usr/lib64/python36.zip
/usr/lib64/python3.6
/usr/lib64/python3.6/lib-dynload
/home/dd/.local/lib/python3.6/site-packages
/usr/local/lib64/python3.6/site-packages
/usr/local/lib/python3.6/site-packages
/usr/local/lib/python3.6/site-packages/cloud_init-19.1.3-py3.6.egg
/usr/lib64/python3.6/site-packages
/usr/lib/python3.6/site-packages
那么, sys.path里的路径是怎么来的
-
启动脚本文件所在的目录
启动脚本就是执行Python程序后面的参数脚本文件。
比如python first.py那么这个first.py就是启动脚本文件,脚本文件所在的目录会被加到sys.path中作为模块搜索路径。如果启动命令行,没有指定脚本文件,而是像这样$ python,直接启动了python交互命令行。
或者像这样python -m pytest[…]‘通过’-m参数执行某个模块,那么当前工作目录会被加到sys.path中作为模块搜索路径。 -
PYTHONPATH环境变量里的目录
我们可以在PYTHONPATH环境变量里面添加上多个目录作为模块搜索路径。多个目录之间的分隔符根据操作系统而定。Windows 下面是分号,Linux下面是冒号。
解释器启动的时候,‘PYTHONPATH 环境变里的目录会被加到’sys.path’ 中作为模块搜索路径。 -
Python解释器的缺省安装目录(installation-dependent default)
比如: Windows 下面就是在解释器安装目录中的lib/site-packages目录。
手动添加目录作为模块搜索路径
-
自己想添加一些目录,作为模块搜索路径,还有一 种方法:就是在代码中直接修改sys.path, 使用append或者insert方法, 把目录直接添加到该列表中。
具体实例
文件的目录结构
├── t1.py
├── t2
│ └── t2.py
└── xxu
└── test.py
t2模块如何导入t1模块
# t2.py
import sys
sys.path.append("..")
import t1 #先添加路径再导入模块t1
以模块运行脚本
-m mod run library module as a script (terminates option list)
"mod"是“module”的缩写,即“-m”选项后面的内容是 module(模块),其作用是把模块当成脚本来运行。
“terminates option list”意味着“-m”之后的其它选项不起作用,在这点上它跟“-c”是一样的,都是“终极选项”。官方把它们定义为“接口选项”(Interface options),需要区别于其它的普通选项或通用选项。
(1) 常见的典型用法
# 实现一个简单http服务器
python -m http.server 8000
# 注:在 Python2 中是这样
python -m SimpleHTTPServer 8000
python -m pydoc -p xxx # 生成 HTML 格式的官方帮助文档
python -m pdb xxx.py # 以调试模式来执行“xxx.py”脚本:
最后还有一种常常被人忽略的场景:“python -m pip install xxx”。我们可能会习惯性地使用“pip install xxx”,
或者做了版本区分时用“pip3 install xxx”,总之不在前面用“python -m”做指定。但这种写法可能会出问题。
(2) 运行原理分析
看了前面的几种典型用法,你是否开始好奇: “-m”是怎么运作的?它是怎么实现的?
对于“python -m name”,一句话解释: Python 会检索sys.path,查找名字为“name”的模块或者包(含命名空间包),并将其内容当成__main__模块来执行。
以“.py”为后缀的文件就是一个模块,在“-m”之后使用时,只需要使用模块名,不需要写出后缀,但前提是该模块名是有效的,且不能是用C语言写成的模块。
在“-m”之后,如果是一个无效的模块名,则会报错“No module named xxx”。
如果是一个带后缀的模块,则首先会导入该模块,然后可能报错:Error while finding module specification for ‘xxx.py’ (AttributeError: module ‘xxx’ has no attribute ‘__path__’。
两种写法都会把定位到的模块脚本当成主程序入口来执行,即在执行时,该脚本的 __name__ 都是”main“,跟 import 导入方式是不同的。
那么,“-m”方式与直接运行脚本相比,在实现上有什么不同呢?
直接运行脚本时,相当于给出了脚本的完整路径(不管是绝对路径还是相对路径),解释器根据 文件系统的查找机制, 定位到该脚本,然后执行 使用“-m”方式时,解释器需要在不 import 的情况下,在 所有模块命名空间 中查找,定位到脚本的路径,然后执行。为了实现这个过程,解释器会借助两个模块: pkgutil 和 runpy ,前者用来获取所有的模块列表,后者根据模块名来定位并执行脚本 2、对于包内模块
如果“-m”之后要执行的是一个包,那么解释器经过前面提到的查找过程,先定位到该包,然后会去执行它的“main”子模块,也就是说,在包目录下需要实现一个“main.py”文件。
换句话说,假设有个包的名称是“pname”,那么, “python -m pname”,其实就等效于“python -m pname.main”。
仍以前文创建 HTTP 服务为例,“http”是 Python 内置的一个包,它没有“main.py”文件,所以使用“-m”方式执行时,就会报错:No module named http.main; ‘http’ is a package and cannot be directly executed。
作为对比,我们可以看看前文提到的 pip,它也是一个包,为什么“python -m pip”的方式可以使用呢?当然是因为它有“main.py”文件:
python -m pip”实际上执行的就是这个“main.py”文件,它主要作为一个调用入口,调用了核心的"pip._internal.main"。
http 包因为没有一个统一的入口模块,所以采用了“python -m 包.模块”的方式,而 pip 包因为有统一的入口模块,所以加了一个“main.py”文件,最后只需要写“python -m 包”,简明直观。
相对导入和绝对导入
- Python 相对导入与绝对导入,这两个概念是相对于包内导入而言的。包内导入即是包内的模块导入包内部的模块。
前面我们说过. python的解释器查找模块文件的路径有:(1)在当前目录下搜索模块, (2)解释器内置模块, (3)sys.path包含的目录, (4)Python解释器的缺省安裝目录
相对导入与绝对导入
绝对导入的格式为import A.B 或 from A import B,相对导入格式为from . import B或from ..A importB,
.代表当前模块,…代表上层模块,…代表‘上上层模块(一般不使用) 依次类推。
相对导入可以避免硬编码带来的维护问题,例如我们改了某一顶层包的名,那么子包所有的导入就都不能用了。
但是存在相对导入语句的模块,不能直接运行,否则会有异常:
1.如果是绝对导入,一个模块只能导入自身的子模块或和它的顶层模块同级别的模块及其子模块
2.如果是相对导入,一个模块必须有包结构且只能导入它的顶层模块内部的模块
- 如果一个模块被直接运行,则它自己为顶层模块,不存在层次结构,所以找不到其他的相对路径。
文件的层次结构如下:
.
├── Analog.py
├── common_util.py
├── __init__.py
├── Mobile
│ ├── Analog.py
│ ├── Digital.py
│ ├── __init__.py
│ ├── __init__.pyc
└──
# Analog.py 外面的Analog.py 文件
def foo():
print("fuck ---> foo")
# Mobile/Analog.py文件 Mobile目录下的Analog.py文件
def foo():
print("Analog -> foo")
# Digital.py文件
from . import Analog
import sys
for i path in enumerate(sys.path):
print(i, path)
print(__name__)
print(__package__)
Analog.foo()
这里如果我们目前在Mobile目录下面直接运行Digital.py文件
$ python3 Digital.py
Traceback (most recent call last):
File "Digital.py", line 1, in <module>
from . import Analog
ImportError: cannot import name 'Analog'
我们看到是from . import Analog这句出错,出错原因是不能导入Analog,
我们现在不是在Mobile目录下吗,这句话不就是导入同一目录下的Analog模块吗,只不过我们这里用了相对导入,这里
的 from . 不就是表示从当前模块中导入 Analog吗, 我们目前位置Mobile下面就有Analog.py
这里就涉及Python脚本的两种运行方式
(1) 一是直接运行(top_level脚本) :
python Digital.py
(2)作为模块运行
python -m Digital
#或者
#从其它脚本文件中.
import Digital
这里我们直接运行一个脚本,则它自己为顶层模块,不存在层次结构。
所以找不到其他的相对路径。而我们这里写的相对导入, 这就导致了上面的报错
现在我们返回到Mobile的上级目录
$ python3 Mobile/Digital.py
Traceback (most recent call last):
File "Mobile/Digital.py", line 1, in <module>
from . import Analog
ImportError: cannot import name 'Analog'
还是不行, 还是找不到Analog, 故这种显示相对导入只能以模块方式运行
$ python3 -m Mobile.Digital
0
1 /usr/lib64/python36.zip
2 /usr/lib64/python3.6
3 /usr/lib64/python3.6/lib-dynload
4 /home/dd/.local/lib/python3.6/site-packages
5 /usr/local/lib64/python3.6/site-packages
6 /usr/local/lib/python3.6/site-packages
7 /usr/local/lib/python3.6/site-packages/cloud_init-19.1.3-py3.6.egg
8 /usr/lib64/python3.6/site-packages
9 /usr/lib/python3.6/site-packages
__main__
Mobile
Analog --> foo
可见它导入的是Mobile目录下的Analog, 这符合预期,因为from . import Analog 就是导入相对于Digital.py同一
模块的其他模块。
Python2.x 缺省为相对路径导入,Python3.x 缺省为绝对路径导入。绝对导入可以避免导入子包覆盖掉标准库模块(由于名字相同,发生冲突)。如果在 Python2.x 中要默认使用绝对导入,可以在文件开头加入如下语句:
from __future__ import absolute_import
这句 import 并不是指将所有的导入视为绝对导入,而是指禁用 implicit relative import(隐式相对导入), 但并不会禁掉 explicit relative import(显示相对导入)。
那么到底什么是隐式相对导入,什么又是显示的相对导入呢?
那么如果在Digital中引用Mobile中的Analog,则有如下几种方式
import Analog # 此为 implicit relative import
from . import Analog # 此为 explicit relative import
from Mobile import Analog # 此为 absolute import
隐式相对就是没有告诉解释器相对于谁,但默认相对与当前模块;而显示相对则明确告诉解释器相对于谁来导入。以上导入方式的第三种,才是官方推荐的,第一种是官方强烈不推荐的,Python3 中已经被废弃,这种方式只能用于导入 path 中的模块。
我们来看一个例子,还是上面的文件结构, 只是修改Digital.py文件为隐式相对导入
# Digital.py文件
import Analog # implicit relative import
import sys
for i, path in enumerate(sys.path):
print(i, path)
print(__name__)
print(__package__)
Analog.foo()
$python -m Mobile.Digital # 返回Mobile的上级目录用python2运行
(0, '')
(1, '/usr/lib64/python27.zip')
(2, '/usr/lib64/python2.7')
(3, '/usr/lib64/python2.7/plat-linux2')
(4, '/usr/lib64/python2.7/lib-tk')
(5, '/usr/lib64/python2.7/lib-old')
(6, '/usr/lib64/python2.7/lib-dynload')
(7, '/usr/lib64/python2.7/site-packages')
(8, '/usr/lib/python2.7/site-packages')
__main__
Mobile
Analog --> foo # 可知导入的就是Mobile目录下的Analog.py
如果我们用python3运行
$python3 -m Mobile.Digital
0
1 /usr/lib64/python36.zip
2 /usr/lib64/python3.6
3 /usr/lib64/python3.6/lib-dynload
4 /home/dd/.local/lib/python3.6/site-packages
5 /usr/local/lib64/python3.6/site-packages
6 /usr/local/lib/python3.6/site-packages
7 /usr/local/lib/python3.6/site-packages/cloud_init-19.1.3-py3.6.egg
8 /usr/lib64/python3.6/site-packages
9 /usr/lib/python3.6/site-packages
__main__
Mobile
fuck ---> foo
# 因为python3废弃了这种用法,这种用法只能导入path中的模块,故根据path,此时导入的是路径为当前目录下的Analog
# 而不是Mobile目录下的Analog
相对与绝对仅针对包内导入而言
最后再次强调,相对导入与绝对导入仅针对于包内导入而言,要不然本文所讨论的内容就没有意义。所谓的包,就是包含 init.py 文件的目录,该文件在包导入时会被首先执行,该文件可以为空,也可以在其中加入任意合法的 Python 代码。
相对导入可以避免硬编码,对于包的维护是友好的。绝对导入可以避免与标准库命名的冲突,实际上也不推荐自定义模块与标准库命令相同。
前面提到含有相对导入的模块不能被直接运行,实际上含有绝对导入的模块也不能被直接运行,会出现 ImportError:
例如修改Digital.py文件
# Digital.py 文件
from Mobile import Analog
import sys
for i, path in enumerate(sys.path):
print(i, path)
print(__name__)
print(__package__)
Analog.foo()
此时位于Mobile目录下运行
$python3 Digital.py
Traceback (most recent call last):
File "Digital.py", line 4, in <module>
from Mobile import Analog
ModuleNotFoundError: No module named 'Mobile'
返回Mobile目录的上级目录运行
$python3 Mobile/Digital.py
Traceback (most recent call last):
File "Mobile/Digital.py", line 4, in <module>
from Mobile import Analog
ModuleNotFoundError: No module named 'Mobile'
同样不行
还是只能以模块方式运行,这与相对导入时是一样的原因。要运行包中包含绝对导入和相对导入的模块,
可以用 python -m A.B.C 告诉解释器模块的层次结构。
返回Mobile目录的上级目录运行
$python3 -m Mobile.Digital
0
1 /usr/lib64/python36.zip
2 /usr/lib64/python3.6
3 /usr/lib64/python3.6/lib-dynload
4 /home/dd/.local/lib/python3.6/site-packages
5 /usr/local/lib64/python3.6/site-packages
6 /usr/local/lib/python3.6/site-packages
7 /usr/local/lib/python3.6/site-packages/cloud_init-19.1.3-py3.6.egg
8 /usr/lib64/python3.6/site-packages
9 /usr/lib/python3.6/site-packages
__main__
Mobile
Analog --> foo
环境变量
(1) path环境变量
环境变量中,我们接触最密切的恐怕就是 path 这个环境变量了。
因为很多程序都会根据它的值 决定自己的行为。
最典型的就是 命令行解释器(运行在命令行窗口中的), 有时也叫shell程序。
就是解释执行我们从 命令行窗口(术语是伪终端模拟器)输入命令的程序。
当我们在命令行窗口敲入如下一行指令的时候
python.exe hyhy.py
shell程序会接收到这行命令, 它会以空格作为分隔符,把指令分割为n个部分,第一个部分就是要执行的程序,后面的都是这个程序的参数。
那么第一个问题就是, 到哪里找这个程序 python.exe 呢?
这就是根据环境变量 path 的值决定的。
它会依次到环境变量 path 里面指定的目录下面, 一个个的找。
先在哪个目录下面找到了python.exe,就执行哪个目录下面的 python.exe。
- 不仅仅是 shell 要使用 环境变量 path, 很多其他程序也会使用,比如 Windows 操作系统寻找dll文件时,path里面指定的目录也是搜索路径之一。
(2) 修改环境变量
如果一个程序用到Windows系统配置里面的环境变量,当我们修改了系统配置里面的环境变量,注意,一定要重启这个程序。
比如:cmd命令行解释器。
如果你修改了环境变量path,比如添加了一个目录,注意一定要重启cmd。
因为cmd启动后,就保留了一份自己的环境变量,这是再去修改 配置环境变量,不会影响已经启动的cmd程序。
如果要使修改生效,必须重启cmd程序。
(3) 环境变量的继承
我们再来看一个例子, 刚才我们说,程序重启后,系统配置里面的环境变量就会生效。
我们再通过一个程序来看一下。
大家在集成开发环境 Pycharm,先运行一下,下面的Python程序
import os
print(f'环境变量 byhy :{os.environ['byhy']}')
可以发现,程序会报KeyError: ‘byhy’ 错误, 因为我们并没有这样的一个环境变量。
现在,我们去修改系統配置,添加这个环境变量。
然后,在重新运行程序(就像重启-样), 你会惊奇的发型,仍然会报错。
为什么?不重启程序,修改后的环境变量就会生效吗?
其实,每个程序启动后(运行的程序叫做进程),就会自己拷贝 一份 父进程 环境变量表,作为该 进程 的环境变量表。
父进程 通俗的说 就是 启动了这个程序的 程序。
我们是在 Pycharm 里面运行 Python 程序, Pycharm 就是 Python 程序的父进程。
如果我们在 命令行cmd 中运行 Python 程序, 命令行cmd 就是 Python 程序的父进程。
那怎么解决这个问题呢?
连 Pycharm 也重新启动一下,这样 Pycharm 的 环境变量也更新了,它的子进程当然也会使用更新后的环境变量 就可以了。
那 pycharm 和 cmd 的父进程又是谁呢? 是 Windows 桌面管理器 explorer
explorer启动时,会从注册表中读取 环境变量配置作为自己进程的环境变量。
后续用户启动的程序 大都是 直接 或者 间接的从 explorer继承的环境变量,当然也就使用了配置的环境变量。
前面的例子,我们重启 cmd窗口,可以有效的重新加载系统配置的环境变量,是因为 cmd窗口的父进程是 explorer。
explorer每次启动新的进程,会重新读取 配置环境变量, 作为子进程的环境变量。所以重启cmd就有效了。
但是 cmd 或者 pycharm 启动子进程, 并不会重新读取 配置环境变量,而是把自己的环境变量作为 子进程的环境变量。 当然,修改的配置不会生效。
那么是不是 只有explorer 启动的子程序,才能使用最新的 配置环境变量呢?
也不是,要看程序的设计,完全可以启动子程序时,重新读取 系统配置里面的环境变量给子程序使用。
下面有一个例子
# 代码文件 e1.py
import os,subprocess
def printEnv(filename):
with open(filename,'w') as f:
for k, v in os.environ.items():
f.write(f'{k}:{v}\n')
os.environ['A1'] = '白月黑羽1'
printEnv('e1.txt')
subprocess.Popen(
[r'c:\Python37\python.exe',r'h:\tmp\e2.py'],
shell=False
)
# 代码文件 e2.py
import os
def printEnv(filename):
with open(filename,'w') as f:
for k, v in os.environ.items():
f.write(f'{k}:{v}\n')
os.environ['A2'] = '白月黑羽2'
printEnv('e2.txt')
运行 e1.py 后, e1.py的代码会启动 e2.py。
所以程序运行时, e1.py 就是 e2.py 的父进程。
上面的程序运行后,可以发现 e2.py记录的 环境变量 是在 e1.py的基础上多一个 A2=白月黑羽2 。
可以证明:环境变量从父进程继承而来。
数据结构
number类型的常用操作
number类型分为 int, float, complex
(1) 基本操作
+ - * / // % divmod
(2) 常用内置函数
abs() 取绝对值
max() 取最大值, 不像C++只能两个数进行比较. 可以多个数进行比较, 可直接扔进去一个列表
max(1, 2, 3, 4, 5) --> 5
min() 取最小值
pow(x, y) --> x ** y
(3) math模块
import math
math.pi --> 圆周率
math.sqrt() --> 开平方根 对于n次方根 建议 x ** (1/n)
队列
在python中在刷题过程中不会用到线程和进程中的队列, 一般都是用list或者deque来实现队列的效果, 这里由于队列由于有pop出队的操作, 如果使用list则在出队的时候需要移动大量数据, 故这里队列一般用deque来实现
双端队列
>>> from collections import deque
>>> q = deque()
>>> q.append(1)
>>> q.append(2)
>>> q.append(3)
>>> print(q)
deque([1, 2, 3])
>>> t = q.popleft()
>>> t
1
>>> print(q)
deque([2, 3])
其常用的方法
pop() # 删除最后一个进入的元素, 并返回
appendleft() # 从左端插入一个元素
一般一个队列的用法就是 append() 来实现入队操作, popleft() 来实现出队操作
栈
同样我们一般刷题过程中用到的栈结构也用list或者deque来实现数据结构的功能, 但由于栈的操作只在栈顶进行操作,故我们这里用list就好了, 即我们把最后一个元素当作是栈顶。
直接就是 append() 进行入栈, pop() 进行出栈()
堆
Python没有独立的堆类型,而只有一个包含一些堆操作函数的模块。这个模块名为heapq(其中的q表示队列),它包含6个函数,其中前4个与堆操作直接相关。必须使用列表来表示堆对象本身。默认堆是小顶堆
# 常用操作
heap = []
heappush(heap, x) # 将x压入堆中
heappop() # 从堆中弹出最小的元素
heapify(heap) # 让列表具备堆特征
heapreplace(heap, x) # 弹出最小的元素,并将x压入堆中
nlargest(n, iter) # 返回iter中n个最大的元素
nsmallest(n, iter) # 返回iter中n个最小的元素
>>> from heapq import *
>>> from random import shuffle
>>> data = list(range(10))
>>> shuffle(data)
>>> heap = []
>>> for n in data:
... heappush(heap, n)
...
>>> heap
[0, 1, 3, 6, 2, 8, 4, 7, 9, 5]
>>> heappush(heap, 0.5)
>>> heap
[0, 0.5, 3, 6, 1, 8, 4, 7, 9, 5, 2]
元素的排列顺序并不像看起来那么随意。它们虽然不是严格排序的,但必须保证一点:
位置i处的元素总是大于位置i / 2处的元素(反过来说就是小于位置2 * i和2 * i + 1处的元素)。
这就是默认的小根堆, 称为堆特征
函数heappop弹出最小的元素(总是位于索引0处),并确保剩余元素中最小的那个位于索引0处(保持堆特征)。
虽然弹出列表中第一个元素的效率通常不是很高,但这不是问题,因为heappop会在幕后做些巧妙的移位操作。
>>> heappop(heap)
0
>>> heappop(heap)
0.5
>>> heappop(heap)
1
>>> heap
[2, 5, 3, 6, 9, 8, 4, 7]
函数heapify通过执行尽可能少的移位操作将列表变成合法的堆(即具备堆特征)。如果你的堆并不是使用heappush创建的,应在使用heappush和heappop之前使用这个函数。
>>> heap = [5, 8, 0, 3, 6, 7, 9, 1, 4, 2]
>>> heapify(heap)
>>> heap
[0, 1, 5, 3, 2, 7, 9, 8, 4, 6]
函数heapreplace用得没有其他函数那么多。它从堆中弹出最小的元素,再压入一个新元素。相比于依次执行函数heappop和heappush,这个函数的效率更高。
>>> heapreplace(heap, 0.5)
0
>>> heap
[0.5, 1, 5, 3, 2, 7, 9, 8, 4, 6]
>>> heapreplace(heap, 10)
0.5
>>> heap
[1, 2, 5, 3, 6, 7, 9, 8, 4, 10]
nlargest(n, iter)和nsmallest(n, iter)
分别用于找出可迭代对象iter中最大和最小的n个元素。
这种任务也可通过先排序(如使用函数sorted)再切片来完成,但堆算法的速度更快,使用的内存更少
>>> from random import shuffle
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> shuffle(l)
>>> l
[8, 2, 3, 9, 6, 7, 0, 1, 4, 5]
>>> heapify(l)
>>> l
[0, 1, 3, 2, 5, 7, 8, 9, 4, 6]
>>> nsmallest(3, l)
[0, 1, 2]
>>> nlargest(3,l)
[9, 8, 7]
python并没有内置的函数和方法来执行大顶堆的操作
故如果真的需要用到大顶堆的数据结构, 可以将堆中的所有元素都乘以 -1, 然后按照上面的操作即可。
最后取出堆顶元素时, 需要将其乘以 -1 得到原本的值. as