关于人工智能yolov5的训练,识别,模型转换相关的帮助文件——简单易懂还算详细
注意!!本文没有yolov5环境搭建相关的步骤知识,不过我很贴心的向你推荐三个搭建环境的精良博客,希望对您们有所帮助
写在前面的话:yolov5搭GPU训练环境真的很搞心态,一定要沉住气,放平心态,喝杯茶放松放松,认真仔细一目一行的看安装过程,开头三个博客写的都特别好,还有还有就是一样要看清楚对应的版本号,推荐CUDA不要安装11.4,因为我最后没找到配套的文件所以不得已又删了重新下的10.2,Torch下载安装的时"torch-1.10.1+cu102-cp37-cp37m-win_amd64.whl"这个文件,是可以和10.2的CUDA和python3.7搭配的。(小建议,不喜勿喷)从零开始完成Yolov5目标识别(一)准备工作_WZT725的博客-CSDN博客_yolov5目标识别从零开始进行yolov5训练!包含萌新踩坑过程https://blog.csdn.net/WZT725/article/details/123398828
史上最详细yolov5环境配置搭建+配置所需文件_想到好名再改的博客-CSDN博客_yolov5环境配置yolov5的配置过程总体来说还算简单,但是网上大部分博客都没有仔细介绍具体步骤,本文将从最细节的层面记录yolov5环境配置的全过程使用到的工具有1.anaconda,pycharm2.cuda10.2+cudnn-10.2-windows10-x64-v7.6.5.32+pytorch1.5.1+。。。。。。。。ps(pytorch只要大于等于1.5.1即可,本文将在之后说明安装步骤)所需资源:本博客免费提供所有win10的cuda和cudnn,百度云,提取码:elpt以及权重文件百度云,https://blog.csdn.net/qq_44697805/article/details/107702939使用YOLOv5模型进行目标检测!_Datawhale的博客-CSDN博客↑↑↑关注后"星标"Datawhale每日干货&每月组队学习,不错过Datawhale干货作者:陈信达,华北电力大学,Datawhale成员目标检测是计算机...https://blog.csdn.net/Datawhale/article/details/118425569
- train.py 文件就是用来训练模型的,用pycharm打开后进行调参,就可以进行模型训练了
步骤,或者说需要做的准备:
- 用Anacanda创建一个专门用于yolov5的python环境(Anacanda就相当于python的多环境管理器)
- 用labelImg做好的yolo标注文件(图片和txt文件),并放在正确的文件目录内(看下一条)
- 创建一个.yaml格式的训练配置文件,在里面写上下面信息
“被训练图片目录train”
“测试图片目录val”
“调试信息目录test”
“被检测目标的数量nc”
“被检测目标的名称names”

那么在data文件夹中就会有这样的目录格式
data
┗ datasets
┣ images
┃ ┣ train (这里放训练图片)
┃ ┣ val (这里放测试图片)
┃ ┗ test
┗ labels
┣ train (这里放标注信息txt)
┣ val (这里也放上标注信息txt)
┗ test- 然后在”.\data\hyps\”目录里面在创建一个.yaml文件,用来调整训练模型的具体参数(好像是叫超参数吧)
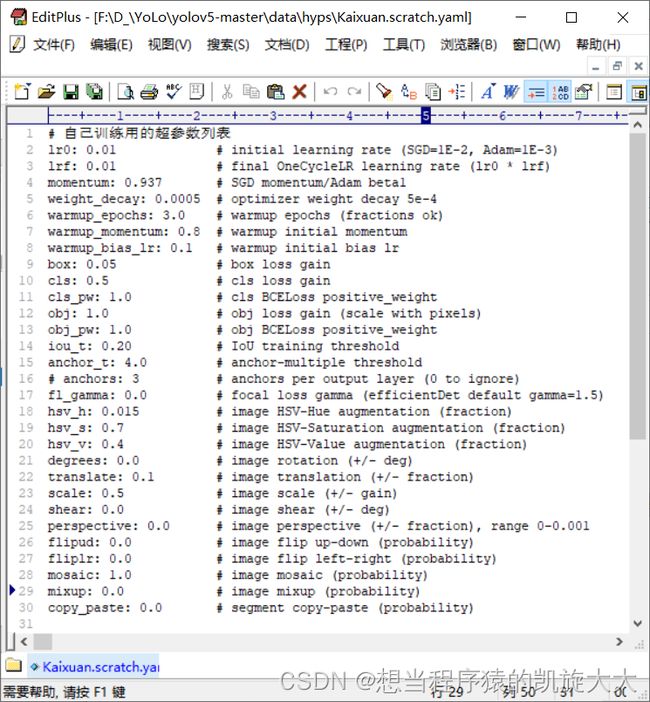 里面一些参数的具体意义在后面有英文注释,翻译一下勉强能看,实在看不了还可以百度
里面一些参数的具体意义在后面有英文注释,翻译一下勉强能看,实在看不了还可以百度
- 以上操作都做完后基本就可以开始进行模型训练了,训练也有两种方式:
- 用Pycharm打开工程后,先右上角
 图标配置python运行环境,还记得步骤第一步用Anacanda新建的那个python环境吗?就是选择那个环境。打开train.py这个文件,就会自动开始进行库检测,一般情况下应该是可以自己下的,如果没有自动下而且还报Error,不要慌张,如果是库没装就在下面终端
图标配置python运行环境,还记得步骤第一步用Anacanda新建的那个python环境吗?就是选择那个环境。打开train.py这个文件,就会自动开始进行库检测,一般情况下应该是可以自己下的,如果没有自动下而且还报Error,不要慌张,如果是库没装就在下面终端  里面pip install [库]手动安装一下
里面pip install [库]手动安装一下 - 在外部用cmd指令进行训练时,按Win+R输入cmd打开命令终端,输入activate [Anacanda新建的python环境名],比如我创建的python的环境是yolov5test,那么我就输入activate tolov5test然后回车就行了,在终端看到
这样的样式的时候,就代表你已经进入到你在第一步创建的python环境了;然后就是用cd命令来把cmd执行目录跳转到到你的yolov5目录中去,就比如我的yolov5在F:\D_\YoLo\yolov5-master这个目录,那我我在终端输入cd F:\D_\YoLo\yolov5-master就行了(注意:因为cmd默认是在C盘,如果要跨盘符跳转,可以先在cmd中输入f:然后回车,就可以跳转到F盘了,之后在用cd命令就能正常跳转目录了), ;在这之后,就可以先输入(yolov5test) C:\Users\Lenovo>_
这个命令进行模块安装,过程可能会很慢,需要耐心等待;在准备了那么多之后,就可以进行训练工作了,在cmd中先输入python -m pip install -r requirements.txt
看着是不是超级长,其实主要的也就是python train.py,后面的就是传入的参数“--参数类型 参数”,这里列举几个常用的:python train.py --weights weights/yolov5l.pt --data data/kaixuan.yaml --batch-size 16 --workers 16 --epochs 50
其实在上一个方法里也可以改这里每个参数后面的default来达到改参的目的;调完参后就可以愉快的进行模型训练了
什么?你说报错了?还看不懂?不慌,我这边稍微列举我遇到的几个报错信息:
1. OSError: [WinError 1455] 页面文件太小,无法完成操作。
问题:Anacanda安装的盘分配的虚拟内存太少或者没分配。
解决:此电脑右键 -> 属性 - > 高级系统属性 -> 高级 -> 设置 -> 高级 -> 更改 -> [驱动器中选择Anacanda安装的盘符] -> 自定义大小 -> [更改“初始大小”和“最大值”,参考值20480] -> 设置 -> 确定 -> 确定 -> 确定



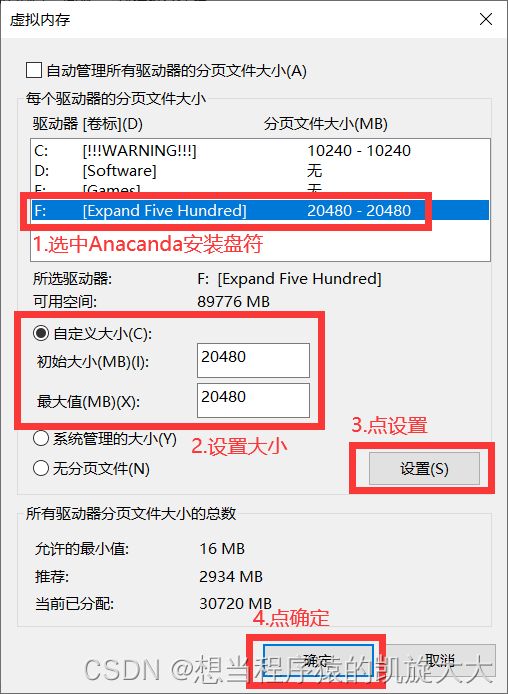
参考文章:[WinError 1455] 页面文件太小,无法完成操作。_Fate丶残影的博客-CSDN博客_python页面文件太小,无法完成操作
2. OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
问题:意思是要初始化一个libiomp5md.dll文件,但是发现这个文件已被初始化了。
解决:在本项目的环境目录下搜索libiomp5md.dll,直接删除搜索项第二个。
参考文章:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized._小唐Sir~的博客-CSDN博客_libiomp5md.dll
3. RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
问题:batch_size太大,内存不足。
解决:调小bantch_size,我GPU4G显存,写的是3.
参考文章:RuntimeError: Unable to find a valid cuDNN algorithm to run convolution_hye0501的博客-CSDN博客
4. Broken PipeError: [Errno 32] Broken pipe
问题:Windows使用DataLoader时设置num_workers的问题。
解决:改变--workers的值,写0或者8
参考文章:解决pytorch报错BrokenPipeError: [Errno 32] Broken pipe_Xavier Jiezou的博客-CSDN博客_broken pipe pytorch
5. RuntimeError: CUDA out of memory. Tried to allocate 144.00 MiB (GPU 0; 2.00 GiB total capacity; 1.29 GiB already allocated; 79.00 MiB free; 1.30 GiB reserved in total by PyTorch)
问题:显存被挤炸了。
解决:
- 换模型(--weights 这个参数所使用的模型,一般推荐yolov5l.pt,比较均衡,比yolov5x.pt小,比yolov5s.pt大)。
- 还是调小bantch_size。
参考文章: RuntimeError: CUDA out of memory(已解决) - 简书(他说的是可能会有程序占用所以显存才少)
解决:RuntimeError: CUDA out of memory. Tried to allocate 128.00 MiB (GPU 0; 2.00 GiB total capacity; 1 - it610.com(他说关掉一些功能减少显存占用)
- detect.py文件是用已训练模型来进行目标识别的文件
写在前面,看了上面的步骤5的第二条后相信你已经可以进入环境进行一些操作了,那么直接贴出指令
python detect.py --source ./data/images/example.jpg --weights weights/yolov5s.pt --conf-thres 0.25跟上面说的一样,这里面也是会传入一些参数,--source [被识别的文件或者文件夹路径] --weights [识别使用的模型路径] --conf-thres [置信度]
就这么简单,输出后的识别文件在runs/exp[?num]文件夹中
- export.py文件我理解是用来做模型格式转换的文件
为什么要做模型转换?当然是为了移植啊,就比如我,我会把训练好的.pt转换成.tflite文件,然后在移植到我自己的Android Studio工程中去。
值得注意的是,这个py文件可能第一次运行的时候也运行不同,也会提示一些库没安装,这里还是建议自己根据Error提示信息手动百度解决问题或者pip install [库名]手动下载。
指令:
python export.py --weights debug.pt --include tflite --img 320参数:--weights [被转换的.pt模型] --include [需要的转化后的模型格式,这里就是.tflite模型] --img [精度?]
重要提示:其实还有一个参数是--int8,这个没有参数,直接相当于声明一下,重点是有时候--int8和--img之间是有绑定关系的,但这也取决于被移植的程序的定义,我android studio程序中如果转换出来是--int8模型,但是--img不是320,那么打包出来的程序就会闪退报错,这也是我进行程序移植的时候踩的坑
