PyTorch基础知识(术语、概念)
目录
术语
概念
contiguous
65535LL
数组取值
Half数据类型
blob
CTCLoss
谱归一化
ONNX
Quantization
dynamic dispatch
Tensor的dispatch
Size, storage offset, stride
Protocol Buffer
Message
Specifying Field Types
Assigning Field Numbers
Specifying Field Rules
extension
in-place
KRSC layout
JIT 编译器
pin_memory
其他资料
术语
reduce:归约
broadcast:广播
将数据从一个节点(进程)传播到另一个节点(进程),比如归约后梯度张量的传播
gather:收集
把数据从其他节点(进程)转移到当前节点(进程),比如把梯度张量从其他节点转移到某个特定的节点,然后对所有张量求平均
Indexing:索引
Slicing:切片
Contraction:缩并
爱因斯坦求和约定:Einstein Summation Convention
Expand:扩增
Squeeze:压缩
概念
contiguous
contiguous表示数据在内存中是否连续存储。
先看以下代码
# Create a tensor of shape [4, 3]
x = torch.arange(12).view(4, 3)
print(x, x.stride())
> tensor([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
> (3, 1)
y = x.t()
print(y, y.stride())
print(y.is_contiguous())
> tensor([[ 0, 3, 6, 9],
[ 1, 4, 7, 10],
[ 2, 5, 8, 11]])
> (1, 3)
> False可以看出,对于x,在内存中我们需要移动3步才能达到新行(如从0到3),而我们只需要移动1步即可达到新列(如从0到1)。
对于y,在内存中我们需要移动1步即可达到新行(如从0到1),而我们需要3步才能达到新列(从0到3)。
其中x是contiguous的,而y不是。这是因为Pytorch内核中假设了column-major matrix。
65535LL
LL即long long类型
数组取值
冒号:取所有
-1:最后一个元素
[i:j]:从i开始不包括j
import numpy as np
a=np.random.rand(5)
print(a)
[ 0.64061262 0.8451399 0.965673 0.89256687 0.48518743]
print(a[-1]) ###取最后一个元素
[0.48518743]
print(a[:-1]) ### 除了最后一个取全部
[ 0.64061262 0.8451399 0.965673 0.89256687]
print(a[::-1]) ### 取从后向前(相反)的元素
[ 0.48518743 0.89256687 0.965673 0.8451399 0.64061262]
print(a[2::-1]) ### 取从下标为2的元素翻转读取
[ 0.965673 0.8451399 0.64061262]
Half数据类型
half数据类型:half数据类型用16位来表示浮点数。这比更为常用的float型的示数范围要小,但他是浮点数家族的新成员。有效位数(0-9)10bits,指数位(9-15)5bits,符号位1bits.
torch.half()将tensor投射为半精度浮点(16位浮点)类型
blob
从数学意义上说,blob是按C风格连续存储的N维数组。
For now, consider a blob to be a N-dimensional Tensor similar to numpy’s ndarray, but is contiguous.
注意pytorch里合并了caffe2的代码
CTCLoss
CTC 的全称是Connectionist Temporal Classification,中文名称是“连接时序分类”,这个方法主要是解决神经网络label 和output 不对齐的问题(Alignment problem),其优点是不用强制对齐标签且标签可变长,仅需输入序列和监督标签序列即可进行训练。
谱归一化
谱归一化约束,通过约束 GAN 的 Discriminator 的每一层网络的权重矩阵(weight matrix)的谱范数来约束 Discriminator 的 Lipschitz 常数, 从而增强 GAN 在训练过程中的稳定性。
ONNX
Open Neural Network Exchange(ONNX,开放神经网络交换)格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
Quantization
量化是将数值 x 映射到 y 的过程,其中 x 的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)。8-bit 低精度推理中, 我们将一个原本 FP32 的 weight/activation 浮点数张量转化成一个 int8/uint8 张量来处理
三种量化的方法
1.训练后动态量化
模型的执行时间是由内存加载参数的时间决定(不是矩阵运算时间决定),这种模式适合的模型是LSTM和Transformer之类的小批量的模型。
2.训练后静态量化
适用于内存带宽和运算时间都重要的模型,如CNN。
3. 训练中引入量化
这种方法可以可以保证量化后的精度最大。在训练过程中,所有的权重会被“fake quantized” :float会被截断为int8,但是计算的时候仍然按照浮点数计算。
dynamic dispatch
动态调度
例子:
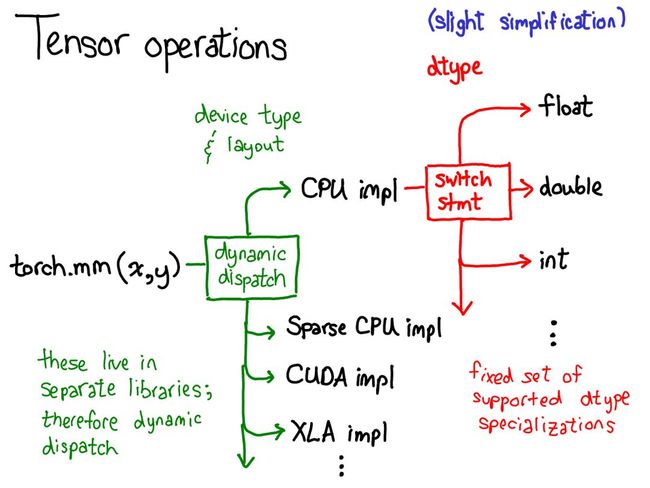
第一次调度基于设备类型和张量布局:比如是 CPU 张量还是 张量,是有步幅的张量还是稀疏的张量。这个调度是动态的:这是一个虚函数(virtual function)调用(这个虚函数调用究竟发生在何处是本演讲后半部分的主题)。
这里需要做一次调度应该是合理的:CPU 矩阵乘法的实现非常不同于 CUDA 的实现。这里是动态调度的原因是这些核(kernel)可能位于不同的库(比如 libcaffe2.so 或 libcaffe2_gpu.so),这样你就别无选择:如果你想进入一个你没有直接依赖的库,你必须通过动态调度抵达那里。
第二次调度是在所涉 dtype 上的调度。这个调度只是一个简单的 switch 语句,针对的是核选择支持的任意 dtype。这里需要调度的原因也很合理:CPU 代码(或 CUDA 代码)是基于 float 实现乘法,这不同于用于 int 的代码。这说明你需要为每种 dtype 都使用不同的核。
Tensor的dispatch
tensor分发,包括静态分发和动态分发。实现将对tensor的操作分发到不同的地方执行。
inline Tensor Tensor::add(const Tensor& other, Scalar alpha) const {
#ifdef USE_STATIC_DISPATCH
switch(tensorTypeIdToBackend(type_id())) {
case Backend::CPU:
return CPUType::add(const_cast(*this), other, alpha);
break;
case Backend::SparseCPU:
return SparseCPUType::add(const_cast(*this), other, alpha);
break;
default:
AT_ERROR("...");
#else // 动态分发
static auto table = globalATenDispatch().getOpTable(
"aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> Tensor");
return table->getOp
(tensorTypeIdToBackend(type_id()), is_variable())(
const_cast(*this), other, alpha);
#endif
} Size, storage offset, stride
pytorch中的storage指的是连续的内存块
tensor则是映射到storage的视图,把单条的内存区域映射成了n维的空间视图。
size是tensor的维度
storage offset:首元素相对于storage地址的偏移量,是数据在storage中的索引
stride是storage中对应于tensor的相邻维度间第一个索引的跨度
Protocol Buffer
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准。
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
在 protobuf 的术语中,结构化数据被称为 Message。proto 文件非常类似 java 或者 C 语言的数据定义。
Message
First let's look at a very simple example. Let's say you want to define a search request message format, where each search request has a query string, the particular page of results you are interested in, and a number of results per page. Here's the .proto file you use to define the message type.
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3;
}The SearchRequest message definition specifies three fields (name/value pairs), one for each piece of data that you want to include in this type of message. Each field has a name and a type.
Specifying Field Types
In the above example, all the fields are scalar types: two integers (page_number and result_per_page) and a string (query). However, you can also specify composite types for your fields, including enumerations and other message types.
Assigning Field Numbers
As you can see, each field in the message definition has a unique number. These numbers are used to identify your fields in the message binary format, and should not be changed once your message type is in use. Note that field numbers in the range 1 through 15 take one byte to encode, including the field number and the field's type (you can find out more about this in Protocol Buffer Encoding). Field numbers in the range 16 through 2047 take two bytes. So you should reserve the field numbers 1 through 15 for very frequently occurring message elements. Remember to leave some room for frequently occurring elements that might be added in the future.
The smallest field number you can specify is 1, and the largest is 229 - 1, or 536,870,911. You also cannot use the numbers 19000 through 19999 (FieldDescriptor::kFirstReservedNumber through FieldDescriptor::kLastReservedNumber), as they are reserved for the Protocol Buffers implementation - the protocol buffer compiler will complain if you use one of these reserved numbers in your .proto. Similarly, you cannot use any previously reserved field numbers.
Specifying Field Rules
You specify that message fields are one of the following:
required: a well-formed message must have exactly one of this field.optional: a well-formed message can have zero or one of this field (but not more than one).repeated: this field can be repeated any number of times (including zero) in a well-formed message. The order of the repeated values will be preserved.
For historical reasons, repeated fields of scalar numeric types aren't encoded as efficiently as they could be. New code should use the special option [packed=true] to get a more efficient encoding. For example:
repeated int32 samples = 4 [packed=true];extension
extension 用于解决字段扩展的场景,例如我们提供一个基础的 message,各个第三方都可以基于该 message 扩展新的字段,例如:
// base.proto
package base;
message Link {
optional string url = 1;
extensions 1000 to 1050;
}
// third-party-1.proto
package thirdparty1;
extend Link {
optional int32 weight = 1001;
}
// third-party-2.proto
package thirdparty2;
extend Link {
optional string ip = 1001;
}in-place
所谓的in-place操作,即就地操作,就是说一个函数的输入图像src与输出图像dst是同一图像。
caffe利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。
相同名字的bottom和top这些blob就是同一个blob,占用的是同一个空间。
简单来解释就是:int a;a = 0;a = 1;你可以无数次对这个a进行改变。
对于blob来说也是一样。至于谁先谁后,那就是看你的网络定义哪个layer在前,它就先计算。
如果有两个layer输出的blob名称是一样的, 那么它们的输入blob也一定会有这个blob ,也就是,如果layer不是对输入blob本身操作,就不允许输出blob同名。 比如:layer1和layer2的输入和输出blob都是blob1,它们都是对blob1进行操作,这是允许的,直接按顺序计算就可以了。 layer1的输入blob是blob1,输出blob是blob_out,layer2的输入blob是blob2,输出blob也是blob_out,那么这就是不允许的。 因为它们不是对它们的输入blob本身进行操作,假设你允许这样的操作,那么后运算的layer会将blob_out覆盖成后运算的结果,前面运算的blob_out的结果就消失了。 当然,layer1和layer2的输入和输出blob都是blob1,它们都是对blob1进行操作,比如layer1先计算,然后layer2后计算,计算layer2的结果也是会把layer1的结果给覆盖 ,只不过是网络已经不需要这个layer1的结果而已,因为它已经前向传播过去了
一般来说,convolution、pooling层应该没办法支持,因为top blob和bottom blob的size不一致。 目前已知的支持in-place操作的层有:ReLU层,Dropout层,BatchNorm层,Scale层
pytorch中很多张量的内置方法都有一个“下划线版本”,即原地(In-Place)操作,改操作会直接改变调用方法的张量的值。
KRSC layout
Input.Type of the filter layout format. If this input is set to CUDNN_TENSOR_NCHW, which is one of the enumerant values allowed by cudnnTensorFormat_t descriptor, then the layout of the filter is in the form of KCRS, where:
K represents the number of output feature maps
C is the number of input feature maps
R is the number of rows per filter
S is the number of columns per filter
If this input is set to CUDNN_TENSOR_NHWC, then the layout of the filter is in the form of KRSC.
JIT 编译器
JIT(Just-In-Time)是一组编译工具,用于弥合 PyTorch 研究与生产之间的差距。
它允许创建可以在不依赖 Python 解释器的情况下运行的模型,并且可以更积极地进行优化。使用程序注解可以将现有模型转换为 PyTorch 可以直接运行的 Python 子集 Torch Script。模型代码仍然是有效的 Python 代码,可以使用标准的 Python 工具链进行调试。
PyTorch 1.0 提供了 torch.jit.trace (追踪模式)和 torch.jit.script(脚本模式) 两种方式使现有代码与 JIT 兼容。一经注解,Torch Script 代码便可以被积极地优化,并且可以被序列化以在新的 C++ API 中使用,并且 C++ API 不依赖于 Python。
pin_memory
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。
而显卡中的显存全部是锁页内存!
当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。因为pin_memory与电脑硬件性能有关,pytorch开发者不能确保每一个炼丹玩家都有高端设备,因此pin_memory默认为False。
其他资料
https://www.cnblogs.com/jicanghai/p/9689726.html
https://www.imooc.com/article/80783
https://oldpan.me/archives/life-of-a-tensor
https://zhuanlan.zhihu.com/p/96879939
https://blog.csdn.net/fendouaini/article/details/90762023?utm_medium=distribute.pc_relevant_download.none-task-blog-baidujs-1.nonecase&depth_1-utm_source=distribute.pc_relevant_download.none-task-blog-baidujs-1.nonecase