Watermelon Book(二)线性模型
文章目录
- 线性回归
- 对数几率回归
-
- 线性类别分类
- 多分类学习
- 类别不平衡问题
基本形式:若给定 d个属性描述的示例x=(x1,x2,x3…xd),则线性模型试图学得一个 通过属性的线性组合来进行预测。
f(x)=W1*X1+W2*X2+...Wn*Xn=w(T)x+b
w=(w1;
w2;
w3;
wn;
)
线性模型形式简单、易于建模,但却蕴涵着机器学习中一些重要的基本思想.许多功能更为强大的非线性模型(nonlinear model)可在线性模型的基础上通过引入层级结构或高维映射而得.此外,由于w直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性(comprehensibility).
线性回归
给定数据集D = {(z1. y1),(z2, y2),. . . , (zm,ym)}。“线性回归”(linear regression)试图学得一个线性模型以尽可能准确地预测实值输出标记.对离散属性,若属性值间存在“序”(order)关系,可通过连续化将其转化为连续值。例如“身高”的取值“高”“矮”可转化为{1.0,0.0},如果身高的三值属性“高度”的取值“高”“中”“低”可转化为{1.0,0.5,0.0};若属性值间不存在序关系,假定有k个属性值,则通常转化为k维向量,例如属性“瓜类”的取值“西瓜”“南瓜”“黄瓜”可转化为(0,0,1),(0,1,0),(1,0,0).
- 如果输入属性的数目只有一个,我们忽略关于属性的下标即:
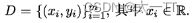
- 确定w和b(均方误差亦称平方损失)
 均方误差有非常好的几何意义,它对应了常用的欧几里得距离或简称“欧氏距离”(Euclidean distance).基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method).在线性回归中,最小二乘法就是试图找到一条直线.使所有样本到直线上的欧氏距离之和最小.
均方误差有非常好的几何意义,它对应了常用的欧几里得距离或简称“欧氏距离”(Euclidean distance).基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method).在线性回归中,最小二乘法就是试图找到一条直线.使所有样本到直线上的欧氏距离之和最小.
 令上面俩式为0可求得w和b的最优解:
令上面俩式为0可求得w和b的最优解:

 类似采用最小二乘法去求w和b
类似采用最小二乘法去求w和b

令上式为0可求得w表达式:
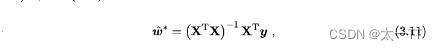
 然而,现实任务中X(T)X往往不是满秩矩阵。例如在许多任务中我们会遇到大量的变量,其数目甚至超过样例数,导致X的列数多于行数使得其不满秩.此时可解出多个w,它们都能使均方误差最小化.选择哪一个解作为输出,将由学习算法的归纳偏好决定,常见的做法是引入正则化(regularization)项.
然而,现实任务中X(T)X往往不是满秩矩阵。例如在许多任务中我们会遇到大量的变量,其数目甚至超过样例数,导致X的列数多于行数使得其不满秩.此时可解出多个w,它们都能使均方误差最小化.选择哪一个解作为输出,将由学习算法的归纳偏好决定,常见的做法是引入正则化(regularization)项.

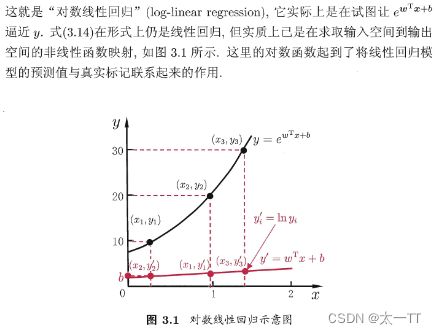

对数几率回归
如果使用线性模型进行分类任务,我们需要找一个单调可微的函数将分类任务的真实标记y与线性回归模型的预测值联系起来。




由此可看出,式(3.18)实际上是在用线性回归模型的预测结果去逼近真实标记的对数几率,因此,其对应的模型称为“对数几率回归”(logisticregression,亦称logit regression).特别需注意到,虽然它的名字是“回归”,但实际却是一种分类学习方法.这种方法有很多优点,例如它是直接对分类可能性进行建模,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题;它不是仅预测出“类别”,而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用;此外,对率函数是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可直接用于求取最优解.

线性类别分类
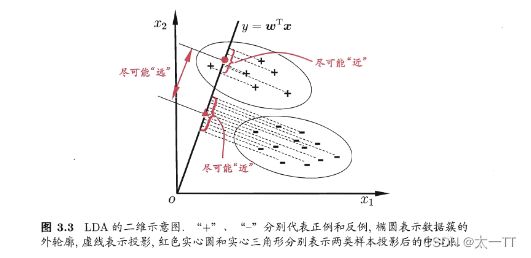
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的线性学习方法,在二分类问题上因为最早由[Fisher,1936]提出,亦称“Fisher判别分析”.
LDA的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别.



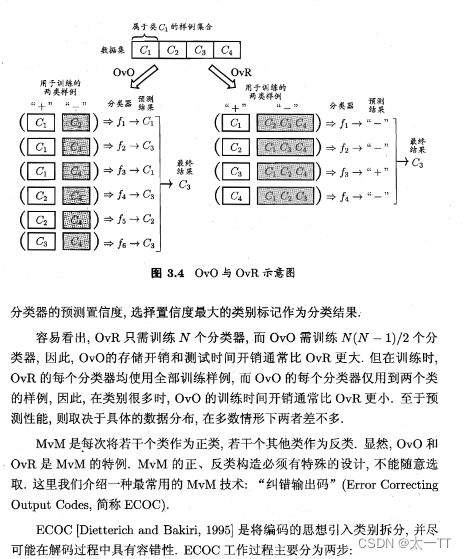
多分类学习



类别不平衡问题
前面介绍的分类学习方法都有一个共同的基本假设,即不同类别的训练样例数目相当.如果不同类别的训练样例数目稍有差别,通常影响不大,但若差别很大,则会对学习过程造成困扰.例如有998个反例,但正例只有2个,那么学习方法只需返回一个永远将新样本预测为反例的学习器,就能达到99.8%的精度;然而这样的学习器往往没有价值,因为它不能预测出任何正例.
类别不平衡(class-imbalance)就是指分类任务中不同类别的训练样例数目差别很大的情况.不失一般性,本节假定正类样例较少,反类样例较多.在现实的分类学习任务中,我们经常会遇到类别不平衡,例如在通过拆分法解决多分类问题时,即使原始问题中不同类别的训练样例数目相当,在使用OvR、MvM策略后产生的二分类任务仍可能出现类别不平衡现象,因此有必要了解类别不平衡性处理的基本方法.
从线性分类器的角度讨论容易理解,在我们用g = wTx+b对新样本z进行分类时,事实上是在用预测出的g值与一个阈值进行比较,例如通常在y >0.5时判别为正例,否则为反例.y实际上表达了正例的可能性,几率岂y则反映了正例可能性与反例可能性之比值,阙值设置为0.5恰表明分类器认为真实正、反例可能性相同,即分类器决策规则为

 我们采用新策略–再缩放
我们采用新策略–再缩放
再缩放的思想虽简单,但实际操作却并不平凡,主要因为“训练集是真实样本总体的无偏采样”这个假设往往并不成立,也就是说,我们未必能有效地基于训练集观测几率来推断出真实几率.现有技术大体上有三类做法:
- 第一类是直接对训练集里的反类样例进行“欠采样”(undersampling),即去除一些反例使得正、反例数目接近,然后再进行学习;
- 第二类是对训练集里的正类样例进行“过采样”(oversampling),即增加一些正例使得正、反例数目接近,然后再进行学习;
- 第三类则是直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将式(3.48)嵌入到其决策过程中,称为“阈值移动”(threshold-moving).
欠采样法的时间开销通常远小于过采样法,因为前者丢弃了很多反例,使得分类器训练集远小于初始训练集,而过采样法增加了很多正例,其训练集大于初始训练集.需注意的是,过采样法不能简单地对初始正例样本进行重复采样,否则会招致严重的过拟合;过采样法的代表性算法SMOTE[Chawlaet al.,2002]是通过对训练集里的正例进行插值来产生额外的正例.另一方面,欠采样法若随机丢弃反例,可能丢失一些重要信息;欠采样法的代表性算法EasyEnsemble [Liu et al.,2009]则是利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息.