大数据聚类技术
1.聚类的基本有关概念
聚类分析:将物理或抽象对象的集合分成相似的对象类的过程称为聚类。
簇:数据对象的集合,对象与同一簇中的对象批次相似,而与其他簇中的对象相异。
无监督学习:没有事先定义好的类
典型应用:①作为获得数据集中数据分布的工具②作为其他数据挖掘算法的预处理步骤
2.聚类方法的分类
①基于划分的聚类(partitioning methods):
给定一个由n个对象组成的数据集合,对此数据集合构建k个划分(k<=n),每个划分代表一个簇,即将数据集合分成多个簇的算法。每个簇至少有一个对象,每个对象必须仅且属于一个簇。具体算法包括:K-均值和K-中心点算法等。
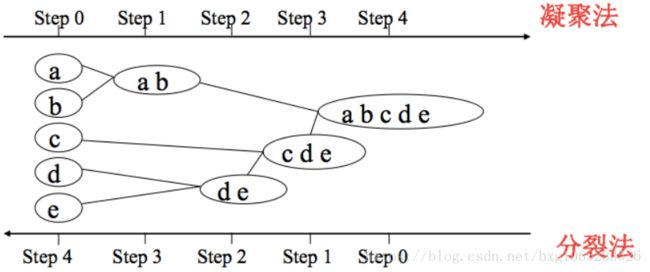
②基于层次的聚类(hierarchical clustering):
对给定的数据集进行层层分解的聚类过程。
(1)凝聚法:将每个对象被认为是一个簇,然后不断合并相似的簇,知道达到一个令人满意的终止条件;
(2)分裂法:先把所有的数据归于一个簇,然后不断分裂彼此相似度最小的数据集,使簇被分裂成更小的簇,直到达到一个令人满意的终止条件。
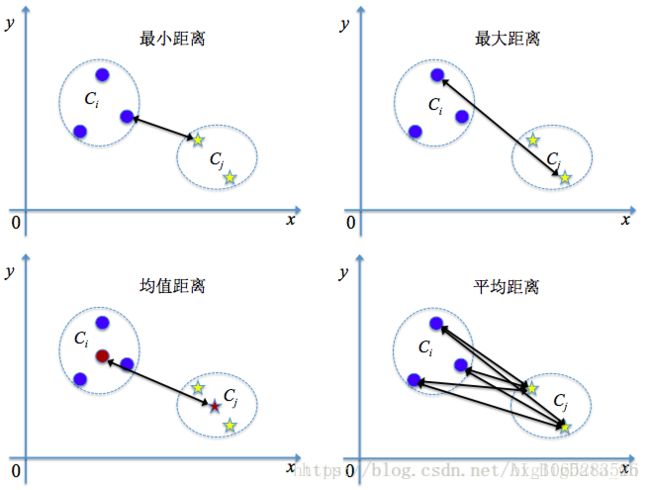
根据簇间距离度量方法的不同,可分为:最小距离、最大距离、平均值距离和平均距离等。
典型算法:CURE,Chameleon和BIRCH等。
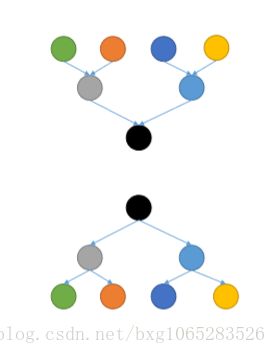
③基于密度的聚类(Density-Based Clustering):
只要某簇邻近区域的密度超过设定的某一阈值,则扩大簇的范围,继续聚类。可以得到任意形状的簇
典型算法:DBSCAN、OPTICS和DENCLUE。

④基于网格的聚类:
将问题空间化为有限数目的单元,形成一个空间网格结构,随后聚类在这些网格之间进行。算法速度较快。
典型算法:STING、WaveCluster和CLIQUE等。
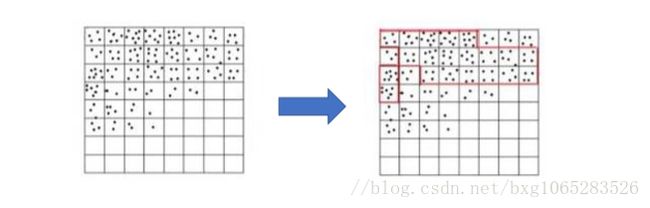
上述方法属于传统聚类方法,对于维度较低的数据集有效,而当维度较高,就可能不适合了。
二、评价标准
一各好的聚类算法有两个表现:
• high intra-class similarity 簇内高的相似度
• low inter-class similarity 簇间低的相似度
相似度的衡量标准是由距离函数d(i,j)表示,距离函数对于不同类型的问题一般不同。
其中二元变量:
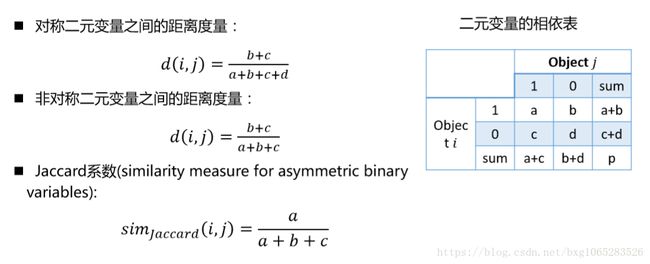
具体应用:

而对于连续型变量,经常使用的是 Minkowski distance
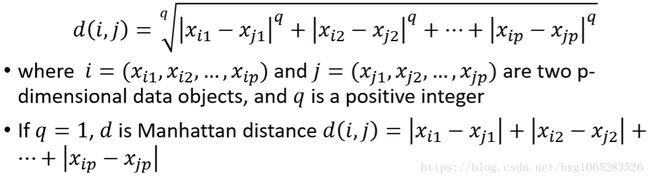

聚类学习是一种无监督的学习方式,事先并不清楚数据的结构,所以任何算法,聚类结果的合理性和有效性都有待评价。
①可伸缩性 即算法中模式数发生变化的情况。有些算法在模式数小的条件下,算法的性能很好,但是模式数增大后,算法性能下降。 如PAM算法是一种k-中心点算法,它对小的数据集合非常有效,但对大的数据集合则没有良好的可伸缩性。
②高维性 即算法中模式属性个数发生变化的情况。有些算法只擅长处理低维数据。在高维空间中聚类是一个挑战,特别是数 据有可能非常稀疏和偏斜。
③可解释性和可用性 就要求聚类结果可解释、易理解。
④发现任意形状的聚类 一个簇可能是任意形状的,但一般的聚类算法是基于欧氏距离和曼哈顿距离度量实现聚类,更 趋于发现球状簇。在这方面,基于密度的聚类方法较好。
⑤处理噪声数据的能力 噪声数据可能是数据本身不完整,也可能是孤立点数据(Outlier)。
⑥用于决定输入参数的领域知识最小化和输入记录顺序敏感性 一方面要求降低算法对输入参数的敏感程度,另一方面要求输入记录顺序对算法的结果影响小。 如经典的k-均值算法,需要预先给出簇的数目。
三、经典算法
(1)K均值算法
K均值(k-means)是一种无监督的聚类算法,这个算法需要事先知道簇的个数

具体步骤:

算法分析:
优势:执行和收敛过程相对较快,易理解。
局限性:必须事先知道聚类数; 算法要求簇是密集的、簇和簇之间的差异比较大;数据集的平均值的计算必须有适当的定义;不能用于非凸面的聚类;对于某些孤立数据和“噪声” 点敏感等。
(2)层次方法
部分参考点击打开链接
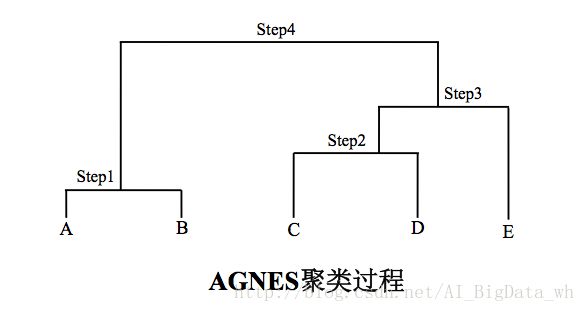
之前已经介绍层次方法的基本概念,其包括两种形式凝聚法和分裂法。
层次凝聚的代表是AGNES(AGglomerative NESting)算法。AGNES 算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度有多种不同的计算方法。聚类的合并过程反复进行直到所有的对象最终满足簇数目。
算法步骤
AGNES(自底向上凝聚算法)算法的具体步骤如下所示:
输入:包含n个对象的数据库。
输出:满足终止条件的若干个簇。
(1) 将每个对象当成一个初始簇;
(2) REPEAT
(3) 计算任意两个簇的距离,并找到最近的两个簇;
(4) 合并两个簇,生成新的簇的集合;
(5) UNTIL 终止条件得到满足。
距离计算
上述算法的关键在于如何计算聚类簇之间的距离?实际上每个簇是一个样本集合,因此只需要采用关于集合的某种距离即可。例如给定聚类簇Ci和Cj,两个簇的距离可以通过以下定义得到:

具体实例
使用AGNES算法对下面的数据集进行聚类,以最小距离计算簇间的距离。刚开始共有5个簇:C1={A}、C2={B}、C3={C}、C4={D}和C5={E}。
| 样本点 | A | B | C | D | E |
|---|---|---|---|---|---|
| A | 0 | 0.4 | 2 | 2.5 | 3 |
| B | 0.4 | 0 | 1.6 | 2.1 | 1.9 |
| C | 2 | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.5 | 2.1 | 0.6 | 0 | 1 |
| E | 3 | 1.9 | 0.8 | 1 | 0 |
Step1. 簇C1和簇C2的距离最近,将二者合并,得到新的簇结构:C1={A,B}、C2={C}、C3={D}和C4={E}。
| 样本点 | AB | C | D | E |
|---|---|---|---|---|
| AB | 0 | 1.6 | 2.1 | 1.9 |
| C | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.1 | 0.6 | 0 | 1 |
| E | 1.9 | 0.8 | 1 | 0 |
Step2. 接下来簇C2和簇C3的距离最近,将二者合并,得到新的簇结构:C1={A,B}、C2={C,D}和C3={E}。
| 样本点 | AB | CD | E |
|---|---|---|---|
| AB | 0 | 1.6 | 1.9 |
| CD | 1.6 | 0 | 0.8 |
| E | 1.9 | 0.8 | 0 |
Step3. 接下来簇C2和簇C3的距离最近,将二者合并,得到新的簇结构:C1={A,B}和C2={C,D,E}。
| 样本点 | AB | CDE |
|---|---|---|
| AB | 0 | 1.6 |
| CDE | 1.6 | 0 |
Step4. 最后只剩下簇C1和簇C2,二者的最近距离为1.6,将二者合并,得到新的簇结构:C1={A,B,C,D,E}。
层次聚类方法的终止条件:
- 设定一个最小距离阈值¯d,如果最相近的两个簇的距离已经超过¯d,则它们不需再合并,聚类终止。
- 限定簇的个数k,当得到的簇的个数已经达到k,则聚类终止。
性能分析
AGNES算法比较简单,但一旦一组对象被合并,下一步的处理将在新生成的簇上进行。已做处理不能撤消,聚类之间也不能交换对象。增加新的样本对结果的影响较大。
假定在开始的时候有n个簇,在结束的时候有1个簇,因此在主循环中有n次迭代,在第i次迭代中,我们必须在n−i+1个簇中找到最靠近的两个进行合并。另外算法必须计算所有对象两两之间的距离,因此这个算法的复杂度为 O(n2),该算法对于n很大的情况是不适用的。
(3)基于密度的聚类方法(Density-Based Clustering Methods)
DBSCAN算法:(参考链接点击打开链接)
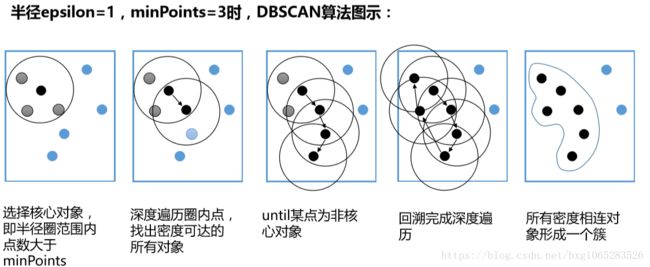
DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ϵϵ, MinPts)用来描述邻域的样本分布紧密程度。其中,ϵϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为ϵϵ的邻域中样本个数的阈值。
假设我的样本集是D=(x1,x2,...,xm),则DBSCAN具体的密度描述定义如下:
1) ϵ-邻域:对于xj∈D,其ϵ-邻域包含样本集D中与xj的距离不大于ϵ的子样本集,即Nϵ(xj)={xi∈D|distance(xi,xj)≤ϵ}, 这个子样本集的个数记为|Nϵ(xj)|
2) 核心对象:对于任一样本xj∈D,如果其ϵ-邻域对应的Nϵ(xj)至少包含MinPts个样本,即如果|Nϵ(xj)|≥MinPts,则xj是核心对象。
3)密度直达:如果xi位于xj的ϵ-邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。
4)密度可达:对于xi和xj,如果存在样本样本序列p1,p2,...,pT,满足p1=xi,pT=xj, 且pt+1由pt密度直达,则称xj由xi密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本p1,p2,...,pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于xi和xj,如果存在核心对象样本xk,使xi和xj均由xk密度可达,则称xi和xj密度相连。注意密度相连关系是满足对称性的。
从下图可以很容易看出理解上述定义,图中MinPts=5,红色的点都是核心对象,因为其ϵϵ-邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列的ϵϵ-邻域内所有的样本相互都是密度相连的。
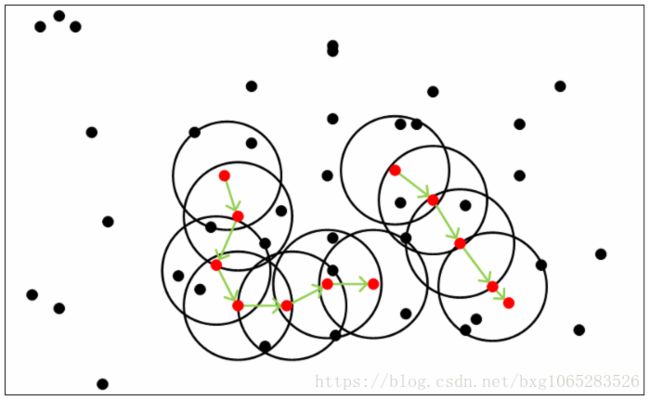
DBSCAN的聚类定义很简单:由密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的ϵ-邻域里;如果有多个核心对象,则簇里的任意一个核心对象的ϵ-邻域中一定有一个其他的核心对象,否则这两个核心对象无法密度可达。这些核心对象的ϵ-邻域里所有的样本的集合组成的一个DBSCAN聚类簇。
那么怎么才能找到这样的簇样本集合呢?DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
我们还是有三个问题没有考虑。
第一个是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
第二个是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。这和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。
第三种问题比较特殊,某些样本可能到两个核心对象的距离都小于ϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说BDSCAN的算法不是完全稳定的算法。
算法步骤:
输入:样本集D=(x1,x2,...,xm),邻域参数(ϵ,MinPts), 样本距离度量方式
输出: 簇划分C.
1)初始化核心对象集合Ω=∅, 初始化聚类簇数k=0,初始化未访问样本集合Γ = D, 簇划分C = ∅
2) 对于j=1,2,...m, 按下面的步骤找出所有的核心对象:
a) 通过距离度量方式,找到样本xj的ϵ-邻域子样本集Nϵ(xj)
b) 如果子样本集样本个数满足|Nϵ(xj)|≥MinPts, 将样本xj加入核心对象样本集合:Ω=Ω∪{xj}
3)如果核心对象集合Ω=∅,则算法结束,否则转入步骤4.
4)在核心对象集合Ω中,随机选择一个核心对象o,初始化当前簇核心对象队列Ωcur={o}, 初始化类别序号k=k+1,初始化当前簇样本集合Ck={o}, 更新未访问样本集合Γ=Γ−{o}
5)如果当前簇核心对象队列Ωcur=∅,则当前聚类簇Ck生成完毕, 更新簇划分C={C1,C2,...,Ck}, 更新核心对象集合Ω=Ω−Ck, 转入步骤3。
6)在当前簇核心对象队列Ωcur中取出一个核心对象o′,通过邻域距离阈值ϵ找出所有的ϵ-邻域子样本集Nϵ(o′),令Δ=Nϵ(o′)∩Γ, 更新当前簇样本集合Ck=Ck∪Δ, 更新未访问样本集合Γ=Γ−Δ, 更新Ωcur=Ωcur∪(Nϵ(o′)∩Ω),转入步骤5.
输出结果为: 簇划分C={C1,C2,...,Ck}
DBSCAN算法对参数比较敏感,同一个聚类若采用不同的MinPts聚类出的结果相差很大。
(4)CLIQUE算法----基于网格的聚类算法
CLIQUE算法是基于网格的空间聚类算法,但它同时也非常好的结合了基于密度的聚类算法,因此既能够发现任意形状的簇,又可以像基于网格的算法一样处理较大的多维数据。
CLIQUE算法把每个维划分成不重叠的社区,从而把数据对象的整个嵌入空间划分成单元,它使用一个密度阈值来识别稠密单位,一个单元是稠密的,如果映射到它的对象超过密度阈值。
算法原理:

CLIQUE识别候选搜索空间的主要策略是使用稠密单元关于维度的单调性。

CLIQUE优点:
(1)给定每个属性的划分,单遍数据扫描就可以确定每个对象的网格单元和网格单元的计数。
(2)尽管潜在的网格单元数量可能很高,但是只需要为非空单元创建网格。
(3)将每个对象指派到一个单元并计算每个单元的密度的时间复杂度和空间复杂度为O(m),整个聚类过程是非常高效的
缺点:
(1)像大多数基于密度的聚类算法一样,基于网格的聚类非常依赖于密度阈值的选择。(太高,簇可能丢失。太低,本应分开的簇可能被合并)
(2)如果存在不同密度的簇和噪声,则也许不可能找到适合于数据空间所有部分的值。
(3)随着维度的增加,网格单元个数迅速增加(指数增长)。即对于高维数据,基于网格的聚类倾向于效果很差。
四、约束聚类
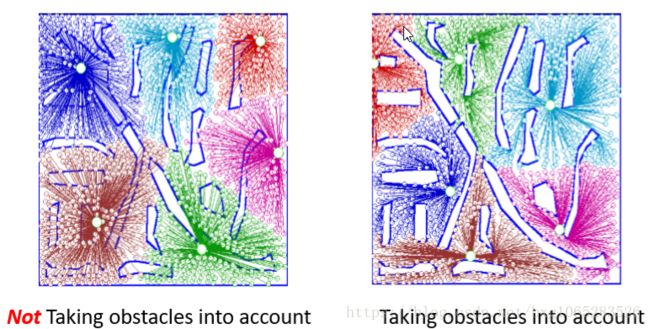
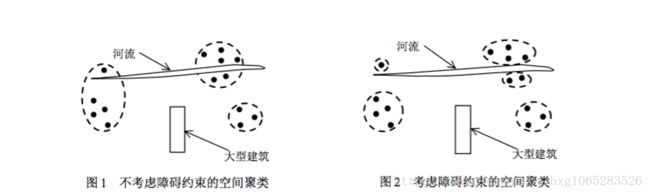
在聚类时是否将障碍考虑进去,对聚类结果影响很大。如下图所示:
约束分类:
(1)根据约束条件施加对象分类
聚类对象的约束(Constraint on Individual Objects):
• 这种约束条件限制参与聚类的对象,选择满足条件的对象进行聚类分析。
• 这种约束,可以将它提前到预处理阶段进行操作,将约束聚类转化为无约束聚类。
障碍约束(Obstacle Objects as Constraints):
• 例如:城市中存在河流、铁路、桥梁、湖泊、高山等,对城市中的对象按照空间距离聚类。
• 通过对距离度量函进行重新定义来实现去约束化。
参数约束(Clustering parameters as “constraints”):
• 某些约束通过参数的形式出现在聚类算法中,如簇的数目约束
簇约束(Constraints imposed on each individual cluster):
• 要求聚类结果中簇满足一定条件,如同一簇内相似度的偏差或簇内包含对象的总数在某个范围内等。
(2)根据约束条件执行的遵守程度分类
• 刚性约束条件:聚类时必须满足的条件。
• 具体分为两类刚性约束:Must-link:约束指明哪些实例对必须聚到同一簇中; Cannot-link:约束指明哪些实例对不能划分到同一簇中。
• 处理刚性约束条件的一般策略是,在聚类的指派过程中严格遵守约束。
• 柔性约束条件:聚类时应该最大可能满足的条件。
• 具有柔性约束的聚类是一个优化问题。
• 当聚类违反约束时,在聚类上施加一个惩罚。
• 此类聚类的最优化目标包含两部分:优化聚类质量和最小化违反约束的惩罚。
• 总体目标函数是聚类质量得分和惩罚得分的组合。
带障碍约束的空间聚类:
具有障碍物的空间数据集聚类,使得同一类中的数据相似 性最大,不同类之间的数据相异性最大。
五、大数据聚类
1.特征转换(Feature transformation)
只有在大多数维度是相关的情况下才有效。
2.特征选择(Feature selection)
3.子空间聚类(Subspace-clustering)
子空间聚类:找到相应的子空间,进而找到在相应子空间上的簇。
子空间聚类方法尽可能在数据集的不同子空间上进行聚类,每一个簇的子空间并不一定相同。
子空间聚类算法也需要相应的策略用于数据集中不同簇的特征子空间的搜索,不同的搜索策略得到的子空间往往不同,得到的聚类结果也往往不同。
根据搜索的方向的不同,可以将子空间聚类方法分成两大类:
(1)自顶向下的搜索策略
• 首先把整个数据集划分为 k 个部分,并为各个部分赋予相同的权值;
• 然后采用某种策略迭代的对各个部分进行不断地改进,并更新这些部分的权值;
• 迭代直到达到某种平衡或达到某种条件停止下来
(2)自底向上的搜索策略
• 利用了关联规则中的先验性质:频繁项集的所有非空子集也一定是频繁的,反之,所有非频繁项集的超级肯定是非频繁的。
• 自底向上子空间聚类算法一般是基于网格密度,采用自底向上搜索策略进行的子空间聚类算法。
自底向上算法:
• Clique:R Agrawal, et al. SIGMOD 1998
• ENCLUS:CHCheng, et al. SIGKDD, 1999
• MAFIA:S Goil, et al. 1999
• LTREE:B Liu, et al. 2000
• CBF:J W Chang, et al. 2000
• DOC:C M Procopiuc,et a1. 2002
自顶向下算法:
• Proclus:C Aggarwal, et al. SIGMOD 1999
分布式聚类
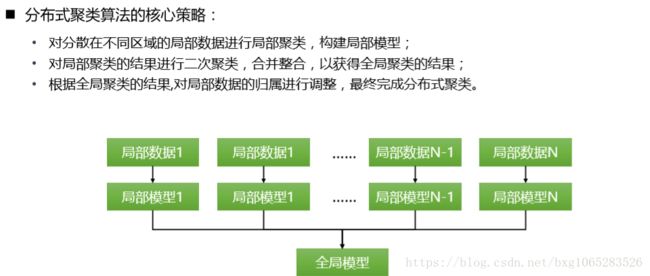
基于DBSCAN算法:

基于MapReduce的K-Means算法
