caffe从零开始学习2——mnist手写体数字识别例程
文章目录
-
- 前言
- 下载数据
- 数据的处理
- 进行训练
- 测试
- 绘制网络图
前言
上一篇文章讲解了caffe在虚拟机ubuntu16.04中的安装教程,本文章将利用caffe架构学习其中自带的mnist手写体数字识别例程,动手学习caffe的具体使用方法。
下载数据
首先,在data/mnist目录下有个脚本文件:get_mnist.sh,其源码如下:
#!/usr/bin/env sh
# This scripts downloads the mnist data and unzips it.
DIR="$( cd "$(dirname "$0")" ; pwd -P )"
cd "$DIR"
echo "Downloading..."
for fname in train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
do
if [ ! -e $fname ]; then
wget --no-check-certificate http://yann.lecun.com/exdb/mnist/${fname}.gz
gunzip ${fname}.gz
fi
done
可以看到这个脚本主要进行4个文件的下载,
train-images-idx3-ubyte //训练用的图像文件
train-labels-idx1-ubyte//训练用的标签文件
t10k-images-idx3-ubyte//测试用的图像文件
t10k-labels-idx1-ubyte//测试用的标签文件
执行以下命令进行下载
cd ~/caffe/data/mnist
./get_mnist.sh
下载完成

数据的处理
在Caffe根目录examples/mnist/下有个create_mnist.sh脚本,是进行数据转换的脚本:
!/usr/bin/env sh
# This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e
EXAMPLE=examples/mnist
DATA=data/mnist
BUILD=build/examples/mnist
BACKEND="lmdb"
echo "Creating ${BACKEND}..."
rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
echo "Done."
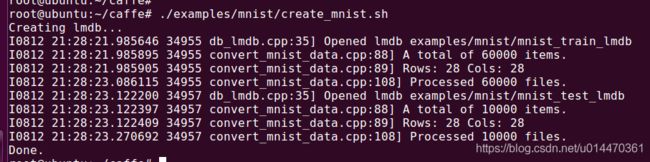
主要是用image文件和label文件来生成两个lmdb格式的文件,执行如下:
./examples/mnist/create_mnist.sh

进行训练
vim ./examples/mnist/train_lenet.sh
训练脚本的源码如下:
#!/usr/bin/env sh
set -e
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt $@
set -e,这句语句告诉bash如果任何语句的执行结果不是true则应该退出。这样的好处是防止错误像滚雪球般变大导致一个致命的错误,而这些错误本应该在之前就被处理掉。如果要增加可读性,可以使用set -o errexit,它的作用与set -e相同。
Linux脚本中$#、$0、$1、$@、$*、$$、$?这个几个参数的意义:
$#:传入脚本的参数个数;
$0: 脚本自身的名称;
$1: 传入脚本的第一个参数;
$2: 传入脚本的第二个参数;
$@: 传入脚本的所有参数;
$*:传入脚本的所有参数;
$$: 脚本执行的进程id;
$?: 上一条命令执行后的状态,结果为0表示执行正常,结果为1表示执行异常;
其中$@与$*正常情况下一样,当在脚本中将$*加上双引号作为“$*”引用时,此时将输入的所有参数当做一个整体字符串对待。比如输入参数有a b c三个参数,则“$*”表示“a b c”一个字符串。
继续查看脚本中lenet_solver.prototxt文件,各参数意义见备注:
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt" #网络文件
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100 #迭代多少个样本数,例如有5000个样本,一次测试要跑完这5000个样本,test_iter * batch需要等于5000
# Carry out testing every 500 training iterations.
test_interval: 500 #测试间隔,每训练500次,就进行一次测试
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01 #基础学习率,其他层的最终学习率是lr_ * base_lr
momentum: 0.9 #动量,常用的都是0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv" #学习策略
gamma: 0.0001 #inv学习策略的参数
power: 0.75 #inv学习策略的参数
# Display every 100 iterations
display: 100 #每训练100次显示一次,设置为0,不显示
# The maximum number of iterations
max_iter: 10000 #最大的迭代次数,10000次就停止了
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPU

由于是用虚拟机进行的训练,这里将最后一行GPU改为CPU。
继续查看lenet_solver.prototxt文件中lenet_train_test.prototxt文件,文件中的参数已经详细备注,参见注释:
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data" #输出
top: "label" #输出,一般data层输出有两个,data和label
include {
phase: TRAIN #include内部,训练阶段使用,若没写include,数据既用于训练,又用于测试
}
transform_param {
scale: 0.00390625 #1/256,归一化
}
data_param {
source: "examples/mnist/mnist_train_lmdb" #数据源
batch_size: 64 #每次批处理的个数,一般使用2的n次方,如64,128
backend: LMDB #选用数据的名称
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
# lr_mult:1 weight learn rate
# lr_mult:2 bias learn rate
# 输入:n*c0*w0*h0
# 输出:n*c1*w1*h1
# 其中,c1是参数中的num_output, 即生成的特征图个数
# w1=(w0+2*pad-kernel_size)/stride+1
# h1=(h0+2*pad-kernel_size)/stride+1
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1 #学习率系数,最终的学习率是这个数乘以solver.prototxt配置文件中国的base_lr。
}
param {
lr_mult: 2 #如果有两个lr_mult,则第一个是权值的学习率,第二个是偏置项的学习率,一般偏置项学习率是权值学习率的两倍。
}
convolution_param {
num_output: 20 #卷积核(filter)的个数
kernel_size: 5 #卷积核的大小,h x w x d,hxw是5x5大小,d是深度(隐含的),和前一层的深度数值一样,例如,前一层若是data层有rgb3个通道即深度是3,那么本层深度也是d=3,又比如前一层是卷积层,有20个特征图,深度是20,那么本层深度d=20
stride: 1 #卷积核的步长,默认是1
weight_filler {
type: "xavier" #权重的初始化,默认为consatant, 值都是0。很多时候我们选用"xavier"泽维尔算法来初始化,也可以设置为"gussian"
}
bias_filler {
type: "constant" #偏置项的初始化,一般为consatant, 值都是0
}
}
}
#pooling层的运算方法和卷积层是一样的
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX #池化方法,默认是MAX(固定区域内,例如对一个2x2的区域进行pooling运算,只保留4个值中最大的值)。 目前可用的方法有MAX,AVE(取平均)
kernel_size: 2 #池化核的大小
stride: 2 #池化的步长,默认是1。一般我们设置为2,即不重叠
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
#全连接层,是对之前的卷积与池化的特性进行再提取的过程,
#把之前的特征总结提取为向量的形式,再根据这个向量做一些分类、回归之类的任务
#输出是一个简单向量,参数和卷积层一样
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
#测试的时候输出准确率
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label" #输入IP2预测分类和label标签
top: "accuracy" #输出准确率
include {
phase: TEST
}
}
#SoftmaxWithLoss,输出loss值
#Softmax,输出似然值,准确率值
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
开始训练
./examples/mnist/train_lenet.sh
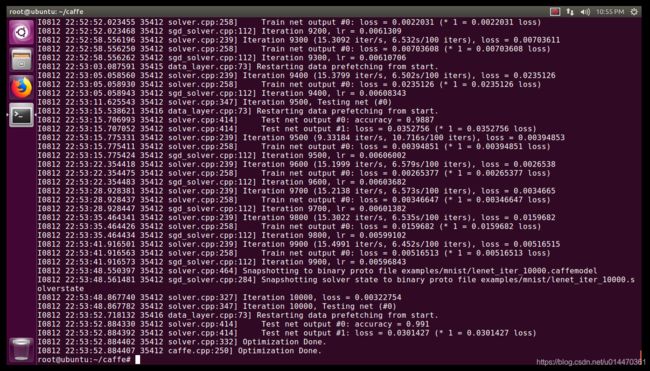
训练结束后会生成 lenet_iter_10000.caffemodel 权值文件。

测试
执行:
./build/tools/caffe.bin test \
-model examples/mnist/lenet_train_test.prototxt \
-weights examples/mnist/lenet_iter_10000.caffemodel \
-iterations 100
测试结果:

绘制网络图
上面已经对mnist例程进行了训练和测试,也可以看到测试的结果。这个例程的网络结构还是比较简单的,对比那种很复杂的网络文件,看起来就头疼了。
那有没有什么方法可以更方便的查看网络文件呢?
答案当然是有的!
下面就来学习绘制网络图。
先安装依赖库
apt-get install graphviz
pip install pydot
执行下面的指令来绘制网络图:
python ./python/draw_net.py ./examples/mnist/lenet_train_test.prototxt ./caffe_png/mnist.png --rankdir=LR

eog mnist.png

如上图,这样的网络图是不是好看多了~~~~