基于k近邻算法的干豆品种分类
摘 要
近年来,干豆由于其较高的营养价值和良好的口感越来越受到人们的欢迎。其种类繁多且易于种植,是世界食用作物中产量最高的一种。干豆品种分类对干豆培育方向、产量需求和品质改良具有重要意义。本文以k近邻算法为核心,借助图像处理技术对已有13611粒干豆图像数据集进行了特征提取,共有16个特征,并在颗粒种获得了12个尺寸和4种形状形式;然后利用KNN分类模型通过10折交叉验证创建性能指标,得到总体正确分类率为xxx。
关键词 图像分类;干豆的分类;KNN算法;特征学习
引言
豆类与谷类拥有一样悠久地种植历史,且与人类历史发展息息相关。大约从公元前6000年起,豆类就逐渐被人们用作食物。在中东,考古学家们发现了小扁豆、豌豆、巢菜和蚕豆等;在坦桑尼亚和巴西,考古学家门在公元前8000年的动物化石中发现了刀豆和葫芦巴;西班牙人曾在公元前4 000年食用芸豆。由于人们的迁徙、经济交流和战争,许多豆科植物,如花生仁、大豆、芸豆、扁豆、豇豆和青豆,从它们的发源地或物种多样性中心传播到世界各地。在水产养殖业不发达的时期,豆类食品是人们最重要的蛋白质来源。一些欧美国家在养殖业发展后,一方面将豆类作为人类的食物,另一方面将其种子和枝条用于饲养家禽和家畜,使得植物蛋白转化为动物蛋白,从而更改人们食材构成成分。进到21世纪,在非洲、亚太、中东地区、南美洲等养鱼业尚不比较发达的国家和地区,豆类仍然是当地人最重要的蛋白质来源。大家使用豆类的方法能够归纳为6种:使用完善的干种子;使用未熟的种子;使用未成熟的豆荚;使用出芽的种子;使用豆类生产商品;将种子中的蛋白进一步生产制造和生产加工。伴随着食品产业的发展,豆类的食用方法除开做成水果罐头、冷藏、研磨成粉、生豆芽外,还可以制成植物肉和植物牛奶,作为蛋白质的来源。其他利用方法,如绿肥作物,可增加土壤有机质和耕地面积。此外,豆类广泛用于造纸业、纺织业、石油化工业和制药业。根据FAO资料,豆类食品中的大豆蛋白占人类总摄入蛋白的22%。从古至今,豆类一直在中国人民的日常生活中发挥着重要作用。食品成分多样化和营养成分均衡化的实际需要以及我国人民优良的饮食习惯促进豆类成为特种杂粮、高蛋白食品和时令蔬菜。在饮食文化上,豆类中的木豆、刀豆、豌豆、白藊豆、小豆和绿豆等均具有药用价值。随着细胞生物学的发展,左旋多巴和普通菜豆绿色植物血凝素等药用成分的获取已经现代化。绿豆具备清热去火的功效,可做成夏天醒神健康饮品。我国多种豆类还是重要的外贸商品,如多花菜豆、普通菜豆、利马豆、豇豆、黑豆、豌豆、扁豆、扁豆、鹰嘴豆等,均销往多个国家和地区。
随着人们对健康生活方式的认识逐渐提高,动物脂肪被植物脂肪取代,使后者成为大家日常生活中的重要食物之一,而豆类粮食作物油是植物脂肪的主要来源。随着豆类粮食作物种植面积逐渐增加,人们对其种植质量和产量的要求也逐渐提高。在此条件下,种子质量就成了豆类栽培的关键。无论是产量还是病害,人工对种子分类非常耗时且效率低下,尤其是在大批量生产时,更需要将分级和分类的任务自动化。在过去的十年中,图像处理技术和CVS被用于研究干豆种子分类。这些系统允许根据质量、颜色和大小等参数对种子品种进行分类。
种子分类的第一步是在评估所进行的研究时获得数字图像,通过图像处理技术在获得的图像上提取种子的特征,特别是形态、颜色和形状特征。其中,颜色特征对分类成功率有很大影响。然而,豆类品种的种子颜色十分相似,给特征分类又带来新的困难。目前,学术界主要集中在对豆类作物遗传多样性、农艺特征、生理学等其他领域的探索,尚未涉猎对大量标准品种进行分类的研究。
本研究的主要目的是提供一种可用于批量生产的干豆识别技术,用于对干豆基本类型进行分类,该干豆包含形态相似的特征,没有明显的颜色特征。使用交叉验证的方法创建了KNN分类模型,并进行了性能优化。
1 数据预处理
干豆数据采集与人工标记是建立干豆品种识别模型的基础。本节主要介绍干豆数据集的构建过程。
1.1 数据采集
数据集中一共10000多条数据,每个数据包含16个特征,1个标签(该条数据对应的种子类别),一共有7类种子。
每个特征都为定距数据,即:取值范围为连续取值的数值数据。
部分特征是通过其他特征计算出来。(这让我想到线性相关)。
各类种子的个数如下:
Seker(2027), Barbunya(1322), Bombay(522), Cali(1630), Dermosan(3546), Horoz(1928) ,Sira(2636)。
下面是各特征的最小值、最大值、平均值、标准差:

表1 不同品种牡丹花图像个数
从表中可以看出,不同特征之间,数据的量级差别较大,数据范围跨度差别很大,面积的最大值达到了254616,而一些特征的最大值还不到1.0,数据值域很小。

图1 拍摄的⼲⾖图像样本
2 KNN模型
KNN算法是一种模式识别方法,根据对象进行分类。一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。也就是说,该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
该方法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最邻近点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。另外还有一种 Reverse KNN法,它能降低KNN算法的计算复杂度,提高分类的效率。
2.1 核心思想
KNN算法的核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
2.2 算法流程
总体来说,KNN分类算法包括以下4个步骤:
①准备数据,对数据进行预处理。
②计算测试样本点(也就是待分类点)到其他每个样本点的距离。
③对每个距离进行排序,然后选择出距离最小的K个点。
④对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。
2.3 损失函数
干豆品种识别属于多分类任务,本文选用交叉熵函数作为模型的损失函数,用于评估卷积神经网络预测输出的类别概率分布与真实分布之间的差异,交叉熵损失函数对于不均衡的样本对网络的准确率的消极影响具有较好的抑制作用。
3 KNN算法实现
一个样本在特征空间中的k个最近邻的样本中的大多数都属于某一个类别,则该样本也属于这个类别。其中k表示最近邻居的个数(距离计算使用欧氏距离)。

图3 KNN预测示意图
3.1 算法实现思路
1.将数据随机划分训练集和测试集
2.计算测试集中单条记录与训练集数据之间的欧式距离
3.将计算的距离进行由小到大排序
4.找出距离最小的前k个值
5.计算找出的值中每类种频次,少数服从多数原则,返回频次最高的类别,即为该种子的类别。
3.2 预测结果

图4训练结果图1
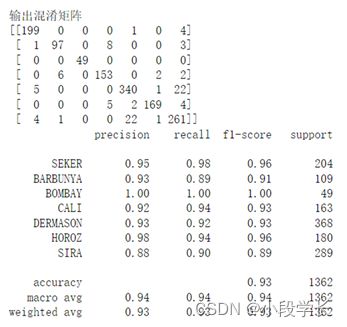
图5训练结果图2
4 对算法的优化
因为不同的特征之间数据的量级差距比较大,而且一些特征的值域范围非常大(面积、周长等特征),很可能导致在算法计算的过程中,将数据取值较小、值域范围较小的特征给忽略掉。
基于上述情况,决定采用均值方差归一化进行优化。(使用StandardScaler)。
我用了现成的库。
具体何时均值方差归一化有 两种方式:
1:划分训练集和测试集之前,进行均值方差归一化。
2:划分训练集和测试集之后,在分别进行均值方差归一化。
5 结论
本文采用KNN算法建立干豆图像分类模型,用于自动对不同干豆品种进行分类。结果表明,模型具有较高的准确率,分类性能表现良好。此外,此模型结构还可以用于不同地区的干豆品种分类,并可以利用机器学习方法、深度学习等算法进行进一步改进。
在研究过程中,干豆品种的形状及大小是通过二维图像获取的。在基于二维图像的机器学习技术中,每个干豆品种的形状差异可以用作单独的变量。如果将方差系数也包括在每个品种的形状和大小变量中,干豆品种分类的成功率可能还会提高。
参 考 文 献
[1]刘义.基于LANDSAT8TM数据的九三管理局大豆与豆类遥感分类监测[J].现代化农业,2016(04):59-60.
[2]郑小东,高洁,张晓煜.基于颜色空间转换的混合豆类分类识别[J].中国粮油学报,2015,30(04):102-106.
[3]陈中. 酶钝化豆类种子胰蛋白酶抑制子的研究[D].华南理工大学,2000.
[4]宫崎尚时,刘多刚.绿豆类的亲缘关系与分类[J].国外农学-杂粮作物,1985(03):40-43.
[5]周宏. 基于左右手运动想象的脑电信号的分类研究[D].大连交通大学,2012.
[6]王冰玉,刘勇军.基于信噪比的KPCA-SVM-KNN算法的股价预测研究[J].计算机与数字工程,2022,50(04):685-690.
[7]白洁. 基于改进K邻近算法的短期风功率预测方法研究[D].东北大学,2019.DOI:10.27007/d.cnki.gdbeu.2019.000565.
[8]张硕. 基于KNN算法的空间手势识别研究与应用[D].吉林大学,2017.
[9]刘昊,谭勇,刘春宇,石晶,苗馨卉,蔡红星,辛敏思,高雪,杨艺帆.基于散射光谱的材质分类识别研究[J].长春理工大学学报(自然科学版),2017,40(01):23-26.
[10]徐剑,王安迪,毕猛,周福才.支持隐私保护的k近邻分类器[J].软件学报,2019,30(11):3503-3517.DOI:10.13328/j.cnki.jos.005573.
[11]朱林杰,赵广鹏,康亮河.改进的KNN分类异常点检测方法[J].甘肃科技纵横,2022,51(01):8-11.
[12]蔡孟翔. 基于SVM的改进加权KNN算法对不均衡数据的分类与应用[D].安徽大学,2020.DOI:10.26917/d.cnki.ganhu.2020.001074.
附录代码
import openpyxl
import random
import numpy as np
import operator
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler # 均值归一化
from sklearn.metrics import confusion_matrix # 生成混淆矩阵
from sklearn.metrics import classification_report # 分类报告
# 使用KNN算法实现对干豆种子的分类
def openfile(filename):
"""
打开数据集,进行数据处理
:param filename:文件名
:return:特征集数据、标签集数据
"""
# 打开excel
readbook = openpyxl.load_workbook(filename)
# 获取sheet
sheet = readbook['Dry_Beans_Dataset']
# 数据集中数据的总数量
n_samples = sheet.max_row - 1
# 数据集中特征的种类个数
n_features = sheet.max_column - 1
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,列数为特征值的种类个数
data = np.empty((n_samples, n_features))
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,1列
target = np.empty((n_samples,), dtype=np.object)
index = 0
for i in sheet.values:
if (index != 0):
data[index - 1] = np.asarray(i[0:-1], dtype=np.object)
target[index - 1] = np.asarray(i[-1], dtype=np.object)
index += 1
else:
index += 1
return data, target
def random_number(data_size):
"""
该函数使用shuffle()打乱一个包含从0到数据集大小的整数列表。因此每次运行程序划分不同,导致结果不同
改进:
可使用random设置随机种子,随机一个包含从0到数据集大小的整数列表,保证每次的划分结果相同。
:param data_size: 数据集大小
:return: 返回一个列表
"""
number_set = []
for i in range(data_size):
number_set.append(i)
random.shuffle(number_set)
return number_set
def split_data_set(data_set, target_set, rate=0.1):
"""
说明:分割数据集,默认数据集的10%是测试集
:param data_set: 数据集
:param target_set: 标签集
:param rate: 测试集所占的比率
:return: 返回训练集数据、测试集数据、训练集标签、测试集标签
"""
# 计算训练集的数据个数
train_size = int((1 - rate) * len(data_set))
# 随机获得数据的下标
data_index = random_number(len(data_set))
# print(data_index)
# 分割数据集(X表示数据,y表示标签),以返回的index为下标
# 训练集数据
x_train = data_set[data_index[:train_size]]
# 测试集数据
x_test = data_set[data_index[train_size:]]
# 训练集标签
y_train = target_set[data_index[:train_size]]
# 测试集标签
y_test = target_set[data_index[train_size:]]
return x_train, x_test, y_train, y_test
def data_diatance(x_test, x_train):
"""
:param x_test: 测试集
:param x_train: 训练集
:return: 返回计算的距离
"""
distances = np.sqrt(sum((x_test - x_train) ** 2))
return distances
# 只传入一个k值
def knn(x_test, x_train, y_train, k):
"""
:param x_test: 测试集数据
:param x_train: 训练集数据
:param y_train: 训练集标签
:param k: 邻居数
:return: 返回一个列表包含预测结果
"""
# 预测结果列表,用于存储测试集预测出来的结果
predict_result_set = []
# 训练集的长度
train_set_size = len(x_train)
# 创建一个全零的矩阵,长度为训练集的长度
distances = np.array(np.zeros(train_set_size))
# 计算每一个测试集与每一个训练集的距离
# i 代表测试集记录、indx代表训练集记录
for i in x_test:
for indx in range(train_set_size):
# 计算数据之间的距离
# 传入测试集、训练集
distances[indx] = data_diatance(i, x_train[indx])
# 此时计算完了 测试集第i条记录 和 所有训练集的 欧氏距离
# y = x.argsort()
# argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y
# 排序后的距离的下标,从小到大,下标代表在训练集中的下标
sorted_dist = np.argsort(distances)
class_count = {}
# 取出k个最短距离,并且计算每一个标签的数量
for i in range(k):
# 获得下标所对应的标签值 y_train 代表 训练集标签
sort_label = y_train[sorted_dist[i]]
sort_label = (str)(sort_label)
# 将标签存入字典之中并存入个数
count = class_count.get(sort_label, 0) + 1
class_count[sort_label] = count
# 对标签的个数 进行排序,从大到小排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# 将出现频次最高的放入预测结果列表
predict_result_set.append(sorted_class_count[0][0])
# 返回预测结果列表
return predict_result_set
def knnChangeK(x_test_item, x_train, y_train, min_k, max_k):
"""
传入k的范围 [min_k,max_k)
:param x_test_item: 单个测试记录
:param x_train: 训练集数据
:param y_train: 训练接标签
:param min_k: 最小k值
:param max_k: 最大k值
:return: 该单个测试记录对应不同k值下的预测结果
"""
# 预测结果列表,用于存储不同k值下测试集预测出来的结果
predict_result_set = []
# 训练集的长度
train_set_size = len(x_train)
# 创建一个全零的矩阵,长度为训练集的长度
distances = np.array(np.zeros(train_set_size))
# 计算该测试记录与每一个训练集的距离
for indx in range(train_set_size):
# 计算数据之间的距离
# 传入测试集、训练集
distances[indx] = data_diatance(x_test_item, x_train[indx])
# 此时计算完了 该条记录 和 所有训练集的 欧氏距离
# 排序后的距离的下标,从小到大,下标代表在训练集中的下标
sorted_dist = np.argsort(distances)
class_count = {}
# 枚举k的取值范围
# 取出k个最短距离,并且计算每一个标签的数量
for k in range(min_k, max_k):
for index in range(k):
# 获得下标所对应的标签值 y_train 代表 训练集标签
sort_label = y_train[sorted_dist[index]]
sort_label = (str)(sort_label)
# 将标签存入字典之中并存入个数
count = class_count.get(sort_label, 0) + 1
class_count[sort_label] = count
# 对标签的个数 进行排序,从大到小排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# 将出现频次最高的放入预测结果列表
predict_result_set.append((int)(sorted_class_count[0][0]))
# 返回预测结果列表
return predict_result_set
def score(predict_result_set, y_test):
"""
:param predict_result_set: 预测结果列表
:param y_test: 测试集标签
:return: 返回测试集精度
"""
count = 0
for i in range(0, len(predict_result_set)):
if predict_result_set[i] == y_test[i]:
count += 1
# 预测对的结果 / 总预测数
score = count / len(predict_result_set)
return score
def convertNameToCode(name):
"""
根据名字转换成相应的代码
:param name: 姓名
:return: 编码
"""
if name == "SEKER":
return 0
if name == "BARBUNYA":
return 1
if name == "BOMBAY":
return 2
if name == "CALI":
return 3
if name == "DERMASON":
return 4
if name == "HOROZ":
return 5
if name == "SIRA":
return 6
if __name__ == "__main__":
filename = r'D:\desktop\学习\自学\DryBeanDataset\Dry_Bean_Dataset.xlsx'
bean_dataset = openfile(filename)
# 特征集
feature = bean_dataset[0]
# 标签集
target = bean_dataset[1]
# 对数据进行均值归一化处理
scaler = StandardScaler()
# 在数据集划分前对训练集和测试集统一进行处理
feature = scaler.fit_transform(feature)
# 将标签集从字符串转成对应的编码(int类型 便于计算)
for i in range(len(target)):
target[i] = convertNameToCode(target[i])
# 数据划分
x_train, x_test, y_train, y_test = split_data_set(feature, target)
x = []
y = []
result = []
min_k = 5
max_k = 21
# 初始化result
for i in range(max_k - min_k):
result.append([])
for i in x_test:
# 遍历测试集的每一条数据 列表大小为 max_k-min_k
x_test_item_result_list = knnChangeK(i, x_train, y_train, min_k, max_k)
for j in range(len(x_test_item_result_list)):
result[j].append(x_test_item_result_list[j])
for i in range(len(result)):
accuracy = score(result[i], y_test)
x.append(i + min_k)
y.append(accuracy)
print(x)
print(y)
plt.plot(x, y)
plt.xlabel('k-value')
plt.ylabel('accuracy-value')
plt.title(u'result map')
plt.show()
# 混淆矩阵
print("输出混淆矩阵")
conf_mat = confusion_matrix(y_test.astype('int'), result[0])
print(conf_mat)
# 精确度,召回率,F1值-F1值是精确度和召回率的调和平均值:
target_names = ['SEKER', 'BARBUNYA', 'BOMBAY', 'CALI', 'DERMASON', 'HOROZ', 'SIRA']
report = classification_report(y_test.astype('int'), result[0], target_names=target_names)
print(report)
欢迎大家加我微信交流讨论(请备注csdn上添加)
