ECA 注意力模块 原理分析与代码实现
前言
本文介绍ECA注意力模块,它是在ECA-Net中提出的,ECA-Net是2020 CVPR中的论文;ECA模块可以被用于CV模型中,能提取模型精度,所以给大家介绍一下它的原理,设计思路,代码实现,如何应用在模型中。
一、ECA 注意力模块
ECA 注意力模块,它是一种通道注意力模块;常常被应用与视觉模型中。支持即插即用,即:它能对输入特征图进行通道特征加强,而且最终ECA模块输出,不改变输入特征图的大小。
- 背景:ECA-Net认为:SENet中采用的降维操作会对通道注意力的预测产生负面影响;同时获取所有通道的依赖关系是低效的,而且不必要的;
- 设计:ECA在SE模块的基础上,把SE中使用全连接层FC学习通道注意信息,改为1*1卷积学习通道注意信息;
- 作用:使用1*1卷积捕获不同通道之间的信息,避免在学习通道注意力信息时,通道维度减缩;降低参数量;(FC具有较大参数量;1*1卷积只有较小的参数量)
下面分析一下,ECA是如何实现通道注意力的;首先看一下,模块的结构:

ECA模型的流程思路如下:
- 首先输入特征图,它的维度是H*W*C;
- 对输入特征图进行空间特征压缩;实现:在空间维度,使用全局平均池化GAP,得到1*1*C的特征图;
- 对压缩后的特征图,进行通道特征学习;实现:通过1*1卷积,学习不同通道之间的重要性,此时输出的维度还是1*1*C;
- 最后是通道注意力结合,将通道注意力的特征图1*1*C、原始输入特征图H*W*C,进行逐通道乘,最终输出具有通道注意力的特征图。
二、1*1卷积 学习通道注意力信息
注意,这部分是重点!注意,这部分是重点!注意,这部分是重点!
首先回想一下,使用FC全连接层时,对输入的通道特征图处理,是进行全局学习的;
如果使用1*1卷积,只能学习到局部的通道之间的信息;
那么问题来了,如果输入通道特征图,它的尺寸比较大,即1*1*C特征图,它的通道数较多;用一个小卷积核,做1*1卷积操作,合适吗?
显然不太合适,应该用卷积核比较大的,来捕获多一些通道之间的信息。
同理,如果输入通道特征图,它的尺寸比较小,用一个大卷积核,做1*1卷积操作,也不太合适。
在做卷积操作时,它的卷积核大小,会影响到感受野;为解决不同输入特征图,提取不同范围的特征时,ECA使用了动态的卷积核,来做1*1卷积,学习不同通道之间的重要性。
动态卷积核是指:卷积核的大小通过一个函数来自适应变化;
- 在通道数较大的层,使用较大的卷积核,做1*1卷积,使得更多地进行跨通道交互;
- 在通道数较小的层,使用较小的卷积核,做1*1卷积,使得较少地进行跨通道交互;
卷积和自适应函数,定义如下:
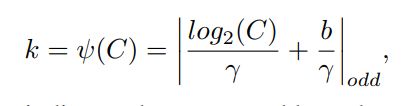
其中k表示卷积核大小;C表示通道数;| |odd表示k只能取奇数;![]() 和b表示在论文中设置为2和1,用于改变通道数C和卷积核大小和之间的比例。
和b表示在论文中设置为2和1,用于改变通道数C和卷积核大小和之间的比例。
三、代码实现
ECA 通道注意力模块,基于pytorch版本的代码如下:
class ECABlock(nn.Module):
def __init__(self, channels, gamma = 2, b = 1):
super(ECABlock, self).__init__()
# 设计自适应卷积核,便于后续做1*1卷积
kernel_size = int(abs((math.log(channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
# 全局平局池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 基于1*1卷积学习通道之间的信息
self.conv = nn.Conv1d(1, 1, kernel_size = kernel_size, padding = (kernel_size - 1) // 2, bias = False)
# 激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 首先,空间维度做全局平局池化,[b,c,h,w]==>[b,c,1,1]
v = self.avg_pool(x)
# 然后,基于1*1卷积学习通道之间的信息;其中,使用前面设计的自适应卷积核
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# 最终,经过sigmoid 激活函数处理
v = self.sigmoid(v)
return x * v
四、ECA应用在模型中
ECA模块可以被用于CV模型中,能较有效提取模型精度;它是即插即用的,用法和SE模型差不多的。
应用示例1:
在主干网络(Backbone)中,加入ECA模块,加强通道特征,提高模型性能;
应用示例2:
在主干网络(Backbone)末尾,加入ECA模型,加强整体的通道特征,提高模型性能;
应用实例3:
在多尺度特征分支中,加入ECA模块,加强加强通道特征,提高模型性能。
总体评价:ECA和SE很像,它就是在学习通道注意力信息时,把FC全连接层改为1*1卷积而已;参数较少,但模型提升效果,不一定有SE模块好。
相关参考信息
论文名称:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文链接:https://arxiv.org/pdf/1910.03151.pdf
论文代码:https://github.com/BangguWu/ECANet
本文只供大家参考与学习,谢谢~
后面还会介绍其它注意力模型:SK-Nets、CBAM、DANet、CA等注意力模块。