深度学习图像处理目标检测图像分割计算机视觉 02--图像特征与描述
深度学习图像处理目标检测图像分割计算机视觉 02--图像特征与描述
- 摘要
- 一、图像特征与描述
-
- 1.1、颜色特征
- 1.2、几何特征提取
- 1.3、基于特征点的特征描述子
-
- 1.3.1、几何特征:关键点
- 1.3.2、几何特征:Harris角点
-
- 1.3.2.1、Harris角点程序
- 1.3.3、FAST角点
- 1.3.4、几何特征:斑点
- 1.3.5、局部特征:SIFT
-
- 1.3.5.1、SIFT程序
- 1.3.6、局部特征:SURF
-
- 1.3.6.1、SURF程序
- 1.3.7、ORB特征
-
- 1.3.7.1、ORB特征代码
- 1.3.8、实现图像的拼接
- 二、文献阅读
-
- 2.1、摘要
- 2.2、介绍
- 2.3、方法
-
- 2.3.1、 NASGAN网络
- 2.3.2、深度生存学习
- 2.4、结果
- 2.5、总结
- 总结
摘要
本周主要进行了图像特征与描述算法的学习,以及文献的阅读。图像特征与描述算法抓主要讲的是把同一地点不同方位的两张图拼成一张图的原理。利用的是图像的特征,包括颜色特征,几何特征,基于特征关键点的描述子,其他特征提取等。文献阅读是关于基于区域适应的深度学习用于对PD-L1染色组织图像的自动T肿瘤细胞(TC)评分和生存分析,讲的是两个系统的对照,第一个系统学会复制肿瘤细胞(TC)评分的病理学评估,用于患者分层。第二个系统不需要对TC评分进行假设,直接从总体生存时间和事件信息中学习患者分层。
一、图像特征与描述
1.1、颜色特征
颜色空间有RGB,HSV等,量化颜色直方图就是统计像素的数量,但是也有一些问题,量化出来的图比较稀疏。这会给后续的计算带来一些问题。


由于量化颜色直方图带来的稀疏的问题,所以采用聚类颜色直方图。



1.2、几何特征提取
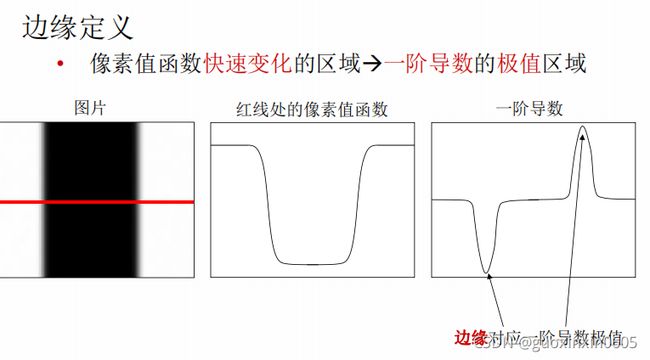
边缘就是像素变化明显的区域,也就是一阶导数的极值区域,具有明显的语义信息,它可以用于物体的识别和几何、视角的转换。






1.3、基于特征点的特征描述子

1.3.1、几何特征:关键点


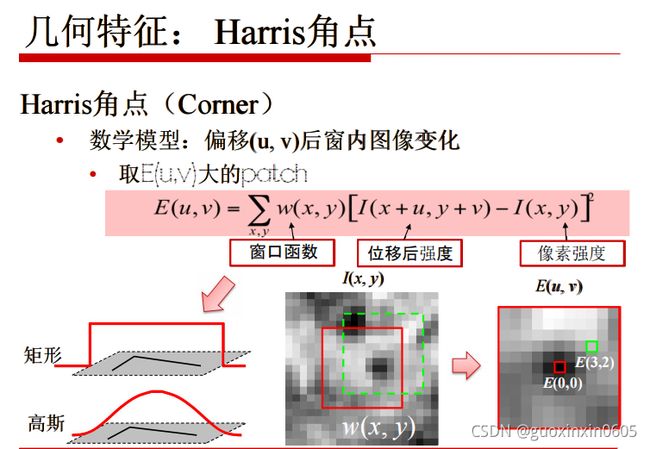
1.3.2、几何特征:Harris角点



1.3.2.1、Harris角点程序
import numpy as np
import cv2 as cv
filename = 'chessboard.png'
img = cv.imread(filename)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
gray = np.float32(gray)
#找到harris-corner,harris角点是一种显著点,在角点的任何方向上移动小观察窗,会导致大的像素变动。
dst = cv.cornerHarris(gray,2,3,0.04)
#result is dilated for marking the corners, not important
dst = cv.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255]
cv.imshow('dst',img)
if cv.waitKey(0) & 0xff == 27:
cv.destroyAllWindows()

1.3.3、FAST角点

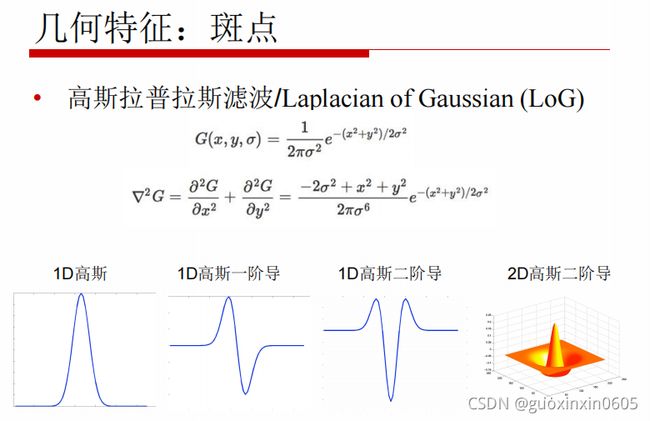
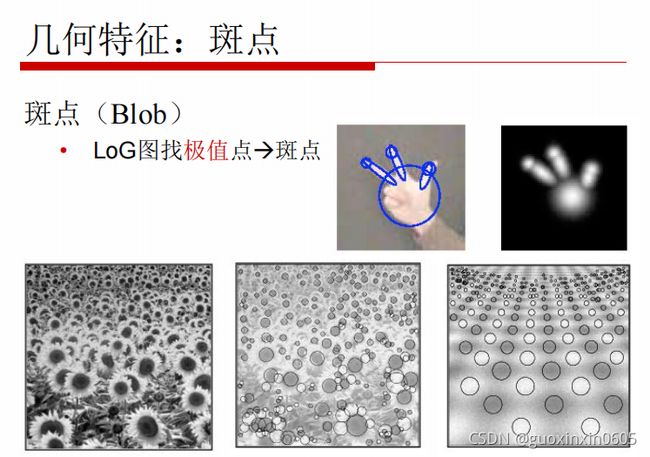
1.3.4、几何特征:斑点


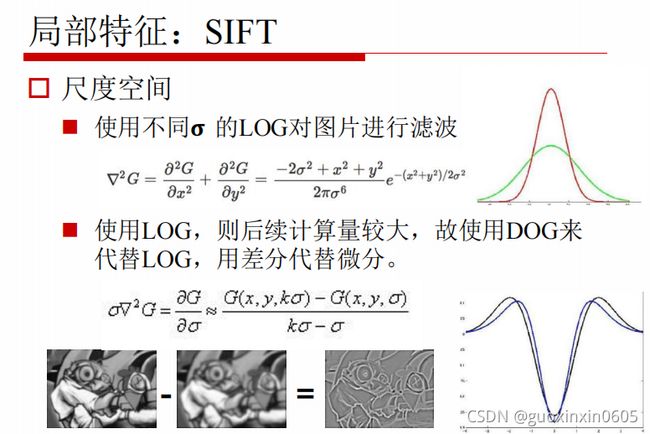
1.3.5、局部特征:SIFT
SIFT是基于尺度不变的特征,它适合于在海量特征数据库中进行快速的、准确的查找。




1.3.5.1、SIFT程序
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
#海量特征数据库中进行快速的、准确的查找
gray= cv.cvtColor(img,cv.COLOR_BGR2GRAY)
sift = cv.xfeatures2d.SIFT_create()
kp = sift.detect(gray,None)
img=cv.drawKeypoints(gray,kp,img)
cv.imshow("SIFT", img)
cv.imwrite('sift_keypoints.jpg',img)
cv.waitKey(0)
cv.destroyAllWindows()

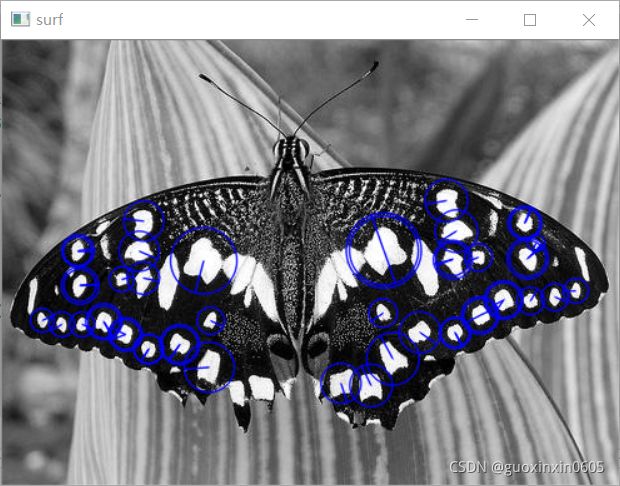
1.3.6、局部特征:SURF
在讲局部特征之前,先讲一下Haar-like特征,Haar-like特征有几个特征,比如边缘特征、线性特征、中心特征以及对角线特征等等构成特征模板,他的特征值代表了图像的灰度变化情况。


SURF的作用就是找出图像上一些比较大的斑块,并且给出图像的主方向,但是这个主方向在实际中不一定具有物理意义,主要是对于计算机而言可以实现旋转不变性,也就是说同一个物体从不同的角度拍摄图片,计算机可以识别这是同一个物,这就是旋转不变性。





1.3.6.1、SURF程序
import numpy as np
import cv2 as cv
img = cv.imread('butterfly.jpg',0)
#运行结果就是找到图像上一些比较大的斑块,并且找出主方向,这个主方向是为了让电脑方便识别
#具体的物理意义不太还描述,主方向就是为了体现旋转不变性。
surf = cv.xfeatures2d.SURF_create(400)
#kp, des = surf.detectAndCompute(img,None)
surf.setHessianThreshold(50000)
kp, des = surf.detectAndCompute(img,None)
img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)
cv.imshow('surf',img2)
cv.waitKey(0)
cv.destroyAllWindows()
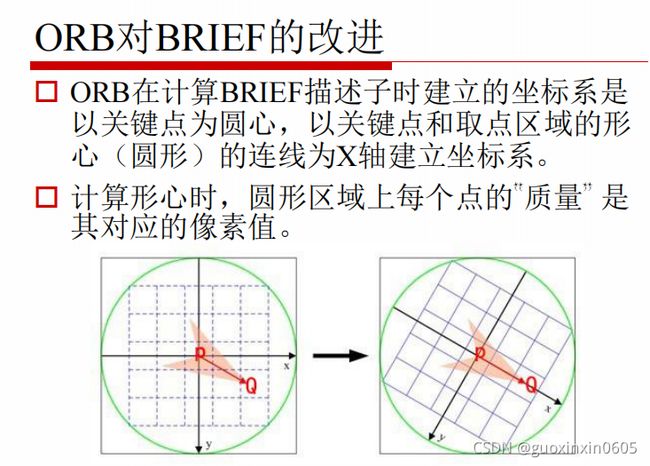
1.3.7、ORB特征
ORB特征是基于FAST角点检测的特征点检测与BRIEF特征描述技术。


LBP局部二值模式,是将每个像素点与周围点比较大小,全部量化成0或者1。

Gabor是一个三角函数与一个高斯函数叠加得到的滤波器,十分适合纹理分析。

1.3.7.1、ORB特征代码
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('box.png',0) # queryImage
img2 = cv.imread('box_in_scene.png',0) # trainImage
#ORB特征描述改进fast角点缺少的尺度不变性和BRIEF的旋转不变性进行改进,同时拥有俩者,并且,速度更快,更准。
#它运行的功能是在一副大图中找到给定的小图。
# Initiate ORB detector
orb = cv.ORB_create()
# find the keypoints and descriptors with ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# create BFMatcher object
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# Match descriptors.
matches = bf.match(des1,des2)
# Sort them in the order of their distance.
matches = sorted(matches, key = lambda x:x.distance)
# Draw first 10 matches.
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None, flags=2)
plt.imshow(img3),plt.show()

1.3.8、实现图像的拼接
import numpy as np
import cv2
class Stitcher:
#拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):
#获取输入图片
(imageB, imageA) = images
#检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.DescriptorMatcher_create("BruteForce")
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
from Stitcher import Stitcher
import cv2
# 读取拼接图片
imageA = cv2.imread("left_01.png")
imageB = cv2.imread("right_01.png")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
二、文献阅读
基于区域适应的深度学习用于对PD-L1染色组织图像的自动T肿瘤细胞(TC)评分和生存分析
2.1、摘要
文章报道了两种基于深度学习的决策系统对接受检查点抑制剂治疗的非小细胞肺癌(NSCLC)患者进行分层的能力,将其分为两个不同的生存组。
两种系统都分析了数字化组织病理学全片图像中SP263 PD-L1抗体染色的上皮区域的功能和形态学特性。第一个系统学会复制肿瘤细胞(TC)评分的病理学评估,切点为阳性的25%,用于患者分层。第二个系统不需要对TC评分进行假设,直接从总体生存时间和事件信息中学习患者分层。这两个系统都建立在一种新的非配对域自适应深度学习DASGAN解决方案之上,用于上皮区域分割。这种方法大大减少了对大像素精确手工标注数据集的需求,同时取代了通过细胞角蛋白染色获得基本真相的连续切片或重新染色的幻灯片。在703例未见病例和97例独立队列病例中,评估了首个系统复制病理医生TC评分的能力。我们的结果显示Lin对病理学家评分的一致性值分别为0.93和0.96。151个临床样本评估了第一和第二系统对抗pd - l1治疗患者的分层能力。与病理医生TC评分(HR=0.574, p=0.01)相比,两种系统的分层能力相似(第一个系统:HR= 0.539, p=0.004,第二个系统:HR=0.525, p=0.003)。
2.2、介绍
在免疫肿瘤学中引入检查点抑制剂疗法,显著提高了癌症患者的预期寿命。特别是在黑色素瘤、非小细胞肺癌(NSCLC)和膀胱癌中,针对细胞死亡蛋白(PD-1)或程序性死亡配体1 (PD-L1)的治疗带来的生存益处已经导致许多药物获得批准,改变了临床常规。人免疫球蛋白G1 kappa单克隆抗体durvalumab通过阻断肿瘤细胞上的PD-L1蛋白来靶向肿瘤的免疫逃逸,从而促进t细胞介导的肿瘤杀伤。基于这一作用机制,我们假设肿瘤组织样本中PD-L1阳性上皮细胞的百分比与对治疗的反应和总生存有关。这一假设在几项研究中得到了证实,并导致了预测性组织病理学评分系统的发展,肿瘤细胞(TC)评分,使用PDL1染色的组织切片。单细胞阳性的定义是由病理学家评估肿瘤细胞膜上PD-L1染色强度确定的。在玻片水平上,PD-L1的阴性或阳性状态是通过比较TC评分与检测的特定截止值来确定的;TC评分高于临界值表明癌症更可能对治疗有反应。TC评分通常由病理学家在显微镜下观察PD-L1染色的组织。然而,PD-L1染色组织的评分是一项具有挑战性的任务。
第一个挑战是PD-L1不能单独染色肿瘤上皮细胞的膜。免疫细胞(如巨噬细胞和淋巴细胞)、坏死区域和间质区域可能显示PD-L1阳性,但不应纳入评分。此外,显示肿瘤上皮细胞有细胞质,但没有膜染色的区域应视为阴性。
另一个与视觉评估相关的挑战是人类观察者很难估计具有空间混杂的阳性和阴性肿瘤区域[7]的细胞群的异质性分布。在某些情况下,这些挑战使TC评分受病理学家[7]的差异影响,这可能导致治疗决策过程中的主观性。
这项工作的第一个贡献是引入了基于自动图像分析(IA)的TC评分系统,该系统基于卷积神经网络(CNN),能够准确地复制病理学家评分。我们的结果显示高一致性IA算法和病理学家之间的得分对TC (i)连续得分,(ii)的二元决策PD-L1地位切割点25%,(3)识别患者群NCT01693562临床试验改善非小细胞肺癌患者的生存。我们将基于IA的TC评分任务定义为三个分类分割问题,这三个分类是:(1)TC(+): PD-L1阳性肿瘤上皮区域;(2)TC(-): PD-L1阴性肿瘤上皮区;(3)其他:未纳入TC评分的非上皮区,如免疫区、间质区、坏死区等。然后计算TC评分,作为第一个区域的像素计数(即表面积)与第一个和第二个区域并集的比值:T Cscore=|T C(+)|/|T C(+)∪T C(−)|。为了重现病理学家评分,提出的基于IA的TC评分算法建立在广泛的假设基础上,如a)应计数为阳性(或阴性)的细胞的定义,b)来自节段上皮区域的TC评分的定义,c)用于确定PD-L1状态进行患者分层的截止值。虽然这个系统可以帮助病理学家做出更有力的治疗决定,但它不能发现新的分层规则。
这让我们看到了这项工作的第二个贡献,即引入了基于cnn的生存分析系统,从PD-L1染色的组织学图像预测时间到事件的结果。根据mobaderany等人[8]最近的工作,提出的系统自动识别视觉模式以及与“处于危险”的低和高概率相关的区域。在自动分割上皮区域和基于患者的分层采样中使用硬注意(请参阅第II-B节了解硬注意的更多细节),我们能够绕过一些与之前应用于组织病理学图像[8]-[11]的弱监督学习相关的工作相关的约束。我们发现,这种修改使得基于TC评分的生存分析的复制成为可能,而不需要大的组织数据集[9]、[11],也不需要人工选择的感兴趣区域[8]或预先选择的小组织样本(如组织微阵列(TMAs)[10])进行分析。我们的方法首次实现了通过深度生存学习对小型临床试验数据集(包括穿刺活检和切除组织样本)进行回顾性分析。以上两项贡献建立在上皮区域自动分割的基础上。对于TC分数复制,分数可以从三级分割问题中得到。对于生存分析,它使注意力集中在已知信息丰富的区域。上述与PD-L1染色和TC评分相关的挑战,以及深度学习方法在数字病理学IA[9],[11] -[16]中的表现,使我们转向这一组方法,尤其是基于深度学习的语义分割网络[17],[18]。语义分割网络已经成功地应用于各种组织病理学图像分析任务,但主要是在H&E域。例如,Liu等人[19]使用Inception V3网络[20]对整张幻灯片图像进行基于patch的分类,生成course segmentation map来检测癌症转移。为了获得密集的分割结果,Scheurer等人[21]使用UNet网络[18]和高效网络B7骨干[22]进行皮肤淋巴瘤和湿疹的分类。为了将更大的组织病理学图像的背景信息整合到网络中,Graham等人使用多尺度网络进行基于实例的核分割。Rijthoven et al.[24]提出了另一种融合更多背景信息的想法,他们提出了多分辨率网络来分割和分类非小细胞肺癌和乳腺癌样本中的不同组织区域。虽然这些方法提供了准确的结果,但是这些网络的训练需要使用具有像素精确标签的大数据集。在实践中,这些数据集的生成是一个手动过程,因此会受到相关的高数据采购成本以及专业专家注释器的需求的阻碍。为了降低人工训练注释的需要,Mahmood等人[25]提出了一种方法,利用对抗式方法从分割掩模合成H&E patch,然后在其上训练网络进行核分割。Chan等人[26]提出了一种弱监督的组织亚型语义分割方法。为了降低人工标注的需求,我们建议使用上皮标记物Pan-Cytokeratin (PanCK)染色的幻灯片自动生成人工训练标注。PanCK是一种泛上皮标记物,对不同类型的上皮染色具有很好的特异性。PanCK染色的可用性使得使用基于计算机的启发式方法(颜色反卷积、Otsu阈值和形态学操作)能够简单、快速地分割上皮区域。在PanCK切片上,人的输入是最小的,它仅限于粗略去除宏观区域,显示的染色不是针对上皮区域的。对上皮区域进行像素精确标记的耗时任务完全依赖于基于计算机的启发式方法,因此可以以相对较低的工作量收集大量精确的上皮标记。因此,在本研究中使用PanCK作为辅助染色进行上皮分割是一个很自然的选择。虽然使用辅助染色产生训练标记的想法之前已经描述过,但这些方法依赖于训练队列设计,目标染色(PD-L1)和辅助染色(PanCK)在同一病例中都可用,无论是通过登记连续载片[28],还是连续染色同一载片。
2.3、方法
2.3.1、 NASGAN网络
该网络拥有两个生成器和两个判别器,生成器可以根据一个染色域的真实样本生成另一个染色域的合成样本生成器是怎么生成合成图像的:使用各自真实范围分割掩码,与原始RGB图像层通过输入图像通道轴连接。各自的连接卷经过的一系列生成器GAB和GBA转换在各自的目标染色区域A和B去生产合成图像。
在两个生成器生成合成样本的时候会产生两个对抗损失Loss(AB)和Loss(BA)。为了在两个域上平移图像,定义了周期损失Lcycle来表示将合成样本平移回原来的域的损失。
而判别器的功能是识别来自两个域的真实样本和合成样本。还扩展了第二个应用,预测像素级类概率图。怎么预测呢?肯定需要一定的信息才可以预测,就需要这里提到的类的特定信息,为了将这个信息传播到生成器中,在鉴别器中引入了分割损失Lseg。
这就导致了对所提出的DASGAN网络进行训练的损失
L(总)=L(AB)+L(BA)+λ1L(cycle)+λ2L(seg):
前两个是对抗损失,第三个是周期损失,第四个分割损失。λ1,2是参数。
本篇文章对网络部分进行的修改:
【
本篇文章中所做的修改:有助于训练稳定性
1–将输入图像和分割掩模连接起来,就是像素之间一一对应,根据真实掩模进行分割。
2–在前三个卷积层中共享源分布预测和语义分割后地图的权重,将语义分割分支扩展为三个resnet块和三个反卷积层。
】
【提出的修改后的网络,可以任意的结合两个染色域的注释,给定一个小数据可以创造出大量的数据,实现上皮区域与其他区域的二值分割。因为域A是PD-L1染色,但是域B是PanCK染色,他针对上皮染色表现很好】
现在PD-L1已将分割好了,再进行阴性和阳性区分,DASGAN引入了三级像素化掩膜调节(0类:非上皮区域(包括基质、巨噬细胞、免疫细胞簇、坏死区域等),1类:PD-L1未染色上皮区域(T C(−)),2类:PD-L1阳性上皮区域(T C(+)))
给定一个PanCK二值分割掩模,通过将标签0和1分别赋予非上皮区域和上皮区域,构建PD-L1负上皮掩模。这种条件下产生PD-L1负像。
同样,PD-L1阳性上皮掩膜由相同的PanCK掩膜生成,分别给出0和2,这个条件下,可以从相同的PanCK图像得到PD-L1正图像。
2.3.2、深度生存学习
深度生存学习是一种使用CNN直接从时间和事件生存信息中学习图像中的“危险”视觉模式的范例。
为了使神经网络能够通过反向传播进行训练并处理生存数据,Faraggi等人[36]提出了一种基于神经网络的方法,在损失函数中实现Cox模型(分析众多因素对生存期的影响)。mobaderany et al.[8]最近扩展了Faraggi et al.[36]的思想,并使用cnn直接从图像中计算Cox模型相关的负偏对数似然。COX回归模型,又称“比例风险回归模型(proportional hazards model,简称Cox模型)”,是由英国统计学家D.R.Cox(1972)年提出的一种半参数回归模型。该模型以生存结局和生存时间为因变量,可同时分析众多因素对生存期的影响,能分析带有截尾生存时间的资料,且不要求估计资料的生存分布类型。由于上述优良性质,该模型自问世以来,在医学随访研究中得到广泛的应用,是迄今生存分析中应用最多的多因素分析方法。
我们的工作建立在这项工作的基础上,我们在此回顾这项工作的完整性。一个基于patch的CNN被训练来预测来自 Cox模型的“风险”值β^T X,其中x表示不同协变量的实现值,β是线性系数的向量。
CNN通过反向传播进行训练,以最小化以下负偏对数似然
其中,U是带有事件的样本集,Ωi是总生存时间高于第i个样本的样本集。损失是根据从所有病例中采样的所有ROI【感兴趣区域】计算的,从而将时间和事件信息从患者传播到构成其ROI的每个ROI。
与其他深度学习应用程序一样,生存学习的原始形式需要大量数据集来学习有意义的“风险”模式,这些模式可以导致对高或低存活群体的稳健预测。
在数据集较小的情况下,经常会遇到模型参数与数据过拟合的问题。
此外,由于图像中的每个区域不可能编码有关患者“处于危险”的信息,将时间和事件传播到所有可能的roi中,产生低信噪比的patch(图像块)。
为了避免人工选择roi,我们采用了区域聚焦生存分析,训练roi自动从之前分割的感兴趣区域中采样。
这种将生存学习仅集中于某些预先选择的区域的过程,在本例中是上皮区域,我们称之为“硬注意”。
为了避免在训练过程中来自组织切除而不是较小的穿刺活检的不成比例的大量斑块,我们引入了一种分层采样方案,其中每幅图像采样多达10k斑块的随机子集。
训练程序在其他方面与原始生存模型相似。
输入块的分辨率标准化为10倍,即1µ/px。
2.4、结果
研究了用于训练的手工标注PD-L1图像的可用性对分割精度的影响。
在手工标注数量有限的情况下(参见图4a),所提出的DASGAN模型优于所有基线模型,即
(i)仅在真实的和手工标注的PD-L1图像上训练的语义分割模型;
(ii)仅在pd - l1翻译和自动标注的PanCK图像上训练的语义分割模型;
(iii)在真实PD-L1图像和PD-L1翻译的PanCK图像上训练的两步域自适应和语义分割模型。
DASGAN和三个基线模型将在方法(第二节)中详细介绍。
平均f1得分f1= 0.886被报告为拟议的网络。
与单独的PDL1真实图像(f1= 0.807)相比,两步模型并没有提高分割结果(f1= 0.805)。
仅对pd - l1翻译的PanCK图像进行训练不能产生准确的分割结果(f1= 0.548)。
如图5a所示,可用于训练的手工标注越多,DASGAN与三种最佳基线模型之间的差异越小。
在数据可用性最高的情况下,基线和DASGAN模型分别获得了f1= 0.894和f1= 0.916的分数。
2)三级分类
在这种三级结构中,DASGAN能够分割PD-L1阳性和PD-L1阴性的上皮区域。我们使用上述相同的测试roi,对t C(+)和t C(−)区域进行了不同的分类标签。在手工标注相对不足的情况下,DASGAN得出的分割f1得分为1= 0.850,平均高于三个兴趣类别,即(i) PD-L1阳性上皮区域(TC(+)) vs (ii) PD-L1阴性上皮区域(TC(-)) vs (iii)非上皮区域。两步和PD-L1基线法的F1评分分别为1= 0.805和F1 = 0.807。尤其(cf图4 b)。
如上所述,DASGAN在标记PD-L1训练图像的可用性方面系统地优于基线方法,达到最大值f1= 0.899(cf。图5 b)。图6提供了由DASGAN生成的上皮分割的定性示例。
2.5、总结
我们证实基于IA的PD-L1 TC评分系统与病理学家TC评分的预测能力相匹配。大量的幻灯片(表I)显示了一致性,这表明了所提出的系统的鲁棒性。我们还表明,在只关注上皮区域的条件下,直接对整体生存信息进行端到端的浅层CNN训练,也可以获得类似的预测能力。虽然后一项发现仍需在独立队列中得到证实,但目前的结果表明,所提出的硬关注方法能够对小型临床数据集进行进一步的无假设探索性分析,并有可能发现新的预测性生物标志物。
对区域聚焦生存cnn的一个自然延伸是进行研究,从其他组织区域(如肿瘤相关基质)中寻找区域聚焦的无假设生物标志物。这将使我们对不同免疫细胞群在生存中的作用有更多的了解,这将是对我们从上皮区域获得的特征的补充。该方法的适用性不限于肺癌,但可以应用于各种类型的癌症和染色,允许创建新的生物学见解和治疗靶点的建议。除了图像数据,其他临床变量,如年龄、吸烟状况和其他组学数据可以整合到CNN中。
本研究中提出的DASGAN方法存在一定的局限性,我们希望在未来能够加以解决。在目前的设置中,在开发和验证队列中,自动化TC评分的一致性仅针对一名病理学家显示。一个有趣的工作方向将是在多病理环境下比较PD-L1 TC评分的观察者间可变性多个病理学家将对相同的切片进行评分。
这将帮助我们了解在哪些样本中病理学家更可能同意/不同意TC评分。正如本工作的介绍和动机中所提到的,在空间上混杂着阳性和阴性染色的肿瘤区域的细胞群的异质性分布往往难以评分,并在评分时引起主观性。在TC评分范围的中间(25%-75%)可以看到这种观察的轻微趋势,自动评分相对于病理学评分的标准偏差最大。在PD-L1染色的肿瘤细胞的空间分布方面,这些病例更可能是不均匀的。本研究的另一个局限性是,DASGAN模型对各种上皮进行了分割,即没有区分恶性和良性上皮间室。由于这个限制,报告的TC评分可能不准确,特别是在良性上皮与恶性上皮染色不同的情况下。这种不一致更有可能发生在手术中,因为与活检中良性上皮的数量相对较少(<10%)相比,活检中有更多的机会得到良性上皮。这一限制可以通过手工划分恶性肿瘤“肿瘤核心”区域或扩展模型自动分离良性上皮和恶性上皮来解决。后者可以使用辅助染色的良性上皮与PanCK一起完成。在本研究中,DASGAN和区域聚焦生存网被开发出来,并在PD-L1 SP263实验中得到验证。我们希望该方法也能应用于其他PD-L1检测,如22C3和288 Dako PD-L1检测。目前我们没有任何数据支持这一说法。我们之所以这样认为,是因为首先,对这些克隆中PD-L1状态的估计也仅仅依赖于对肿瘤细胞上PD-L1表达的估计,其次,因为这两种检测方法与SP263检测的染色模式相对相似。然而,由于每个PD-L1克隆与不同的临床相关临界值相关联,患者状态的确定必须根据各自的指南进行调整。对于Ventana SP142克隆,方法在当前的形式不会直接适用的从我)肿瘤细胞的染色Ventana SP142试验已被证明是不整合(如污渍更少的肿瘤细胞)和ii)决定PD-L1状态不仅仅是基于TC分数的百分比也被PD-L1表达肿瘤区域肿瘤浸润免疫细胞[38]。DASGAN的适用性并不局限于PanCK辅助染色。同样的方法也可用于其他辅助染色剂CD3/CD8/CD20(用于淋巴细胞群体),CD68(用于巨噬细胞群体)。此外,DASGAN可用于不同的组织病理学成像模式(如H&E和多重免疫荧光)。使用这种系统的好处是,与可能是主观的人的评价相比,结果总是可重复的。此外,分割结果可以作为一个辅助病理医生作出更知情的诊断。随着DASGAN用于PD-L1 TC评分的进一步验证,以及考虑到TC评分中自动去除良性上皮的未来扩展,该系统可能成为一种伴随诊断(CDx),前瞻性地选择可能受益于PD-L1检查点抑制剂治疗的患者。
总结
本篇主要介绍了图像特征与描述,主要是为了将图片进行拼接,拼接的时候所用到的就是图像的各种特征。还有论文的研读,论文的主要目的是对患者分层,使用两种方法。原理是肿瘤细胞上的PD-L1蛋白被阻断后,有助于杀死肿瘤细胞,而且PD-L1蛋白的数量跟生存时间相关,数量越多活得越短。所以要使用PDL1染色的组织切片对细胞进行评分,而细胞的阴性或者阳性通过比较得到的评分与一个特定的截止值来判断的。但是,TC评分由专家观察得来。目前有两个挑战 :1-PD-L1染色组织不能单独仅仅染色肿瘤上皮细胞的膜,会导致一些坏死区域也被错误的纳入阳性范围内,导致错判。2-人自身的限制,肉眼观察难以区分空间上分布比较复杂的阳性和阴性细胞群,导致错判。TC评分的计算:T C score=|T C(+)|/|T C(+)∪T C(−)|。本篇文章介绍的这个方法–新的领域自适应深度学习方法自动化评分管道–有两个贡献:1-引入了基于自动图像分析(IA)的TC评分系统,该系统基于卷积神经网络(CNN),能够准确地复制病理学家评分。2-引入了基于cnn的生存分析系统,从PD-L1染色的组织学图像预测时间到事件的结果。但上述这种贡献是建立在上皮区域自动分割的基础上(如果图像不能自动分割,怎么评分,怎么估计呢,所以要建立在自动分割的基础上),语义分割网络已经成功地应用于各种组织病理学图像分析任务,但主要是在H&E域,虽然这个网络提供了准确的结果,但是这些网络的训练需要使用具有像素精确标签的大数据集,为了降低人工训练注释的需要,又提出一种方法,利用对抗式方法从分割掩模合成H&E patch,然后在其上训练网络进行核分割。本篇文章中使用上皮标记物Pan-Cytokeratin (PanCK)染色的幻灯片自动生成人工训练标注,可以以相对较低的工作量收集大量精确的上皮标记,简单、快速地分割上皮区域。为了绕过连续切片或后续染色的需要,利用了深层生成对抗网络(GANs),进行图像到图像的未配对转换,引入端到端可训练网络DASGAN(域自适应和分割生成对抗网络),该网络(i)联合执行未配对的图像到图像的翻译和语义分割,(ii)可以同时利用来自PanCK和PD-L1染色域的训练注释。【DASGAN是CycleGAN的扩展。CycleGAN的创新点在于能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移】。在论文的关键网络理解上还有点欠缺,下周继续努力。