python 数据整理与清洗 在水质自动监测数据分析中的应用
前言
在日常生产环境中,水质自动数据给我们带来许多帮助, 但水质自动监测数据往往因为设备故障、信息传输、数据频次不同等问题,即使经过数据库段初步删选如修约标记、上下限去除、零值、负值去除等工作,仍存在大量缺失值、异常值,需要进一步对监测数据进行整理与清洗。
数据概况及常见问题
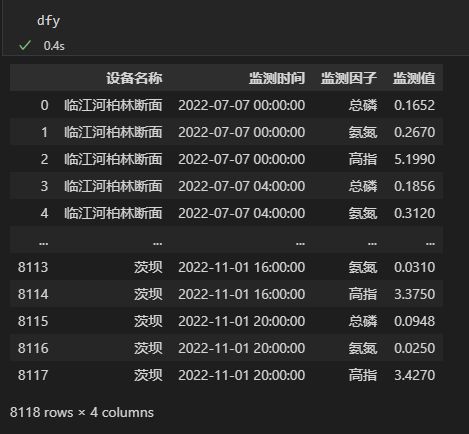
以永川区临江河干流四处重要水质监测站为例。初始数据结构为: 设备名称、监测因子、监测时间、监测值。
数据概览如下:
| index |
设备名称 |
监测时间 |
监测因子 |
监测值 |
| 0 |
临江河柏林断面 |
2022/7/7 0:00 |
总磷 |
0.1652 |
| 1 |
临江河柏林断面 |
2022/7/7 0:00 |
氨氮 |
0.267 |
| 2 |
临江河柏林断面 |
2022/7/7 0:00 |
高指 |
5.199 |
| 3 |
临江河柏林断面 |
2022/7/7 4:00 |
总磷 |
0.1856 |
| 4 |
临江河柏林断面 |
2022/7/7 4:00 |
氨氮 |
0.312 |
| ... |
... |
... |
... |
... |
| 8113 |
茨坝 |
2022/11/1 16:00 |
氨氮 |
0.031 |
| 8114 |
茨坝 |
2022/11/1 16:00 |
高指 |
3.375 |
| 8115 |
茨坝 |
2022/11/1 20:00 |
总磷 |
0.0948 |
| 8116 |
茨坝 |
2022/11/1 20:00 |
氨氮 |
0.025 |
| 8117 |
茨坝 |
2022/11/1 20:00 |
高指 |
3.427 |
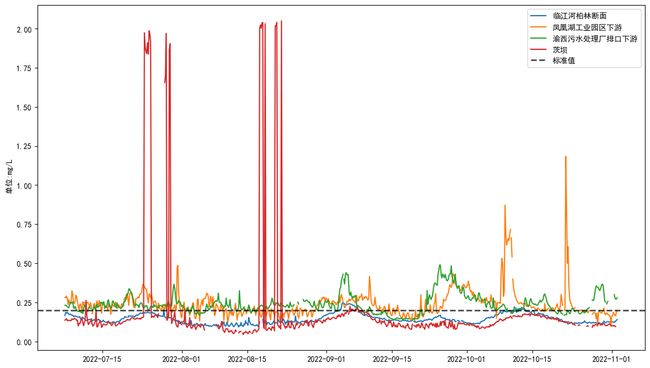
以总磷为例制图预览。
f = "总磷"
s = "茨坝"
df_tp= dfy.loc[dfy["监测因子"] == f, :]
#df.pivot(index=None, columns=None, values=None) 数据透视表
df3=df_tp.pivot(index='监测时间',columns='设备名称',values='监测值')
stations = df3.columns.to_list()
fig = plt.figure(figsize=(14,8),dpi=100)
plt.plot(df3,label=stations)
threshold = 0.2
plt.axhline(threshold, color='k', lw=2, alpha=0.7,linestyle = '--',label="标准值")
plt.legend()
plt.ylabel(" 单位:mg/L")
plt.show()根据预览折线图可以发现数据存在异常值、空值。
我们借助一些工具进一步了解数据的情况。
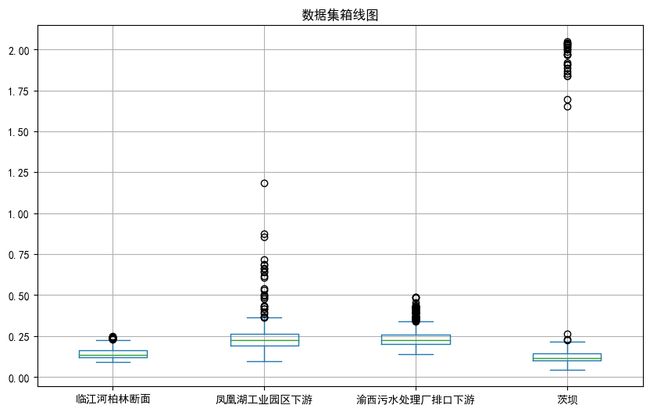
箱线图分析异常值
## 使用箱线图分析数据中是否存在异常值
df3.plot(kind = "box",figsize=(10,6))
plt.title("数据集箱线图")
plt.grid()
plt.show()明显看出茨坝存在大量异常值,根据实际情况,茨坝位于下游总磷是不会高于柏林断面的,因此可以进一步设定规则茨坝总磷大于1.5的设为异常值,设为空。当然这一步也可以在sql段处理。
df3.茨坝[df3.茨坝>1.5]=np.nan
# 或者用iloc从原始数据上去除
df.loc[(df['监测因子'] =='总磷') & (df['监测值'] > 1.5),'监测值']=np.nan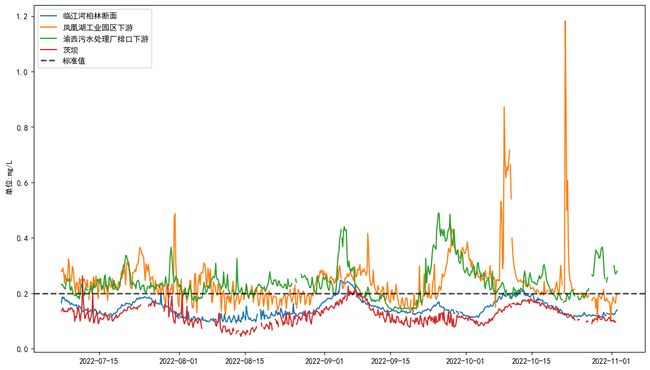
这里要注意处理异常值时,要结合业务实际情况,有些异常值缺位突发时间,若过度删选会去掉真实特征。
数据频次统一
在实际生成中,水质监测分为4小时值和1小时值,因频次不同无法分析,且存在缺失值,必须根据时间区间将4小时值,扩展index至1小时值。
思路是根据开始截止日期生产连续时间序号,然后合并数据,去掉重复值。
starttime = df3.index.to_list()[0]
endtime = df3.index.to_list()[-1]
year_month_day = pd.date_range(starttime, endtime, freq="h").strftime("%Y%m%d%h%m%s")
stations = df3.columns.to_list()
df_empty = pd.DataFrame(columns=stations,index=year_month_day)
dfln = pd.concat([df_empty, df3], axis=0, join="outer")
dfln= dfln.reset_index(drop=False)
dfln["index"] = pd.to_datetime(dfln["index"])
dfln.rename(columns = { 'index':'监测时间'},inplace=True)
dfln = dfln.sort_values(by="监测时间", ignore_index=True)
dfln =dfln.drop_duplicates(subset="监测时间", keep="last", ignore_index=True)
dfln.set_index("监测时间", inplace=True)处理后结果如下:
分析缺失值
缺失值分布
## 使用可视化方法查看缺失值在数据中的分布
import missingno as msno
msno.matrix(dfln,figsize=(14, 7),width_ratios=(13, 2),color=(0.25, 0.25, 0.5))
plt.show()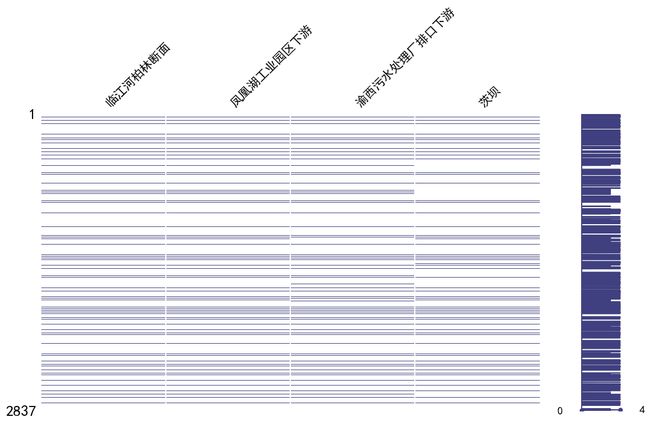
pd.isna(dfln).sum() -> 临江河柏林断面 2471 凤凰湖工业园区下游 2469 渝西污水处理厂排口下游 2474 茨坝 2487 dtype: int64
可见每个站点的空值数值并不相同,这是因为站点可能在不同时间点存在缺失。
缺失值处理
对缺失值我们可以通过缺失值删除、缺失值填充两种方法进行处理,针对水质分析通常采用补充缺失值以保证数据的连续性。因此本次不讨论缺失值删除。
缺失值补充有多种方法,可分为简单填充和复杂填充
简单填充分为前值填充、后值填充、均值填充、指定值填充、线性插值
复杂填充包括k近邻填充、多变量填充、随机森林填充
简单填充
前值填充、后值填充、线性插值、均值填充、指定值填充
指定值填充逻辑与均值一致,不赘述
## 对使用缺失值前面的值进行填充
dff = dfln.fillna(axis = 0,method = "ffill")
## 对使用缺失值后面的值进行填充
dfb = dfln.fillna(axis = 0,method = "bfill")
## 线性插值
dfxx = dfln.interpolate()
## 均值填充
dflnmean1=dfln.mean()
dfmean = dfln.fillna(value = dflnmean1)
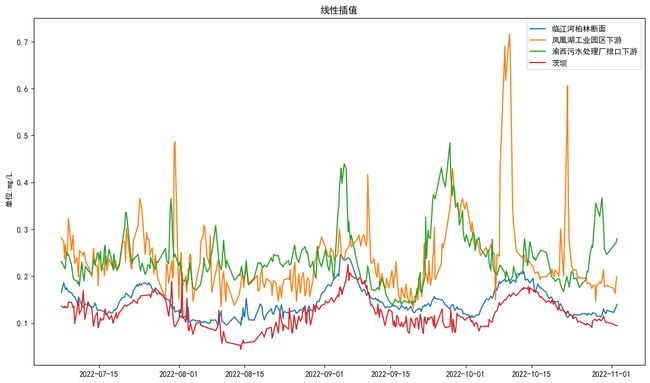

通过概览图直观展示,简单填充中线性插值更合适。
复杂填充
复杂填充包括k近邻填充、多变量填充、随机森林填充
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.impute import KNNImputer
## IterativeImputer多变量缺失值填补方法
iterimp = IterativeImputer(random_state = 123)
dfiter = iterimp.fit_transform(dfln)
## KNNImputer缺失值填补方法
knnimp = KNNImputer(n_neighbors = 5)
dfknn = knnimp.fit_transform(dfln)
## MissForest缺失值填补方法
forestimp = MissForest(n_estimators = 100,random_state = 123)
dfforest = forestimp.fit_transform(dfln)
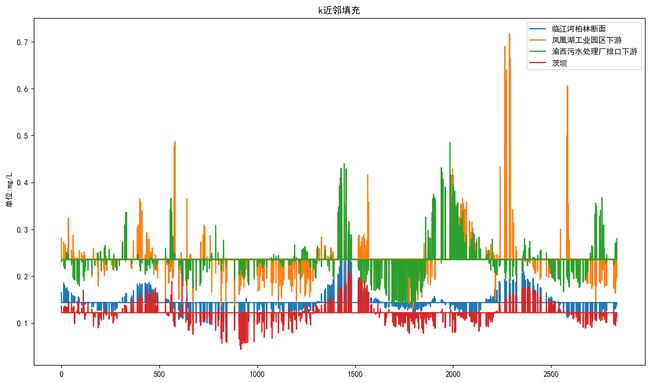

通过概览图直观展示,复杂填充中随机森更合适。
K近邻与多变量也适用于缺失值间隔较小的情况,可以通过调整顺序使用,也即在扩展数据前先填充缺失值。
综合考虑简单填充的线性插值已满足业务需求。
进一步去除异常值
在经过线性插值等操作后,数据的完整性、连续性满足要求,但局部仍存在异常值。
利用3sigma法则,超出均值3被标准差之外的数据可认为是异常值
## 发现异常值
## 根据3sigma法则,超出均值3被标准差之外的数据可认为是异常值
dfxxmean = dfxxsigma.mean()
dfxxstd = dfxxsigma.std()
## 计算对应的样本是否为异常值
outliers = abs(dfxxsigma - dfxxmean ) > 3 * dfxxstd
## 计算每个变量有多少异常值
outliers.sum()-> 临江河柏林断面 46 凤凰湖工业园区下游 75 渝西污水处理厂排口下游 63 茨坝 3 dtype: int64
得出各自的异常值数量,这个标准是通用标准,实际根据具体情况更换逻辑。
发现异常值后,去除并重新填充缺失值。
dfxxsigma[outliers]=np.nan
dfxxsigma =dfxxsigma.interpolate()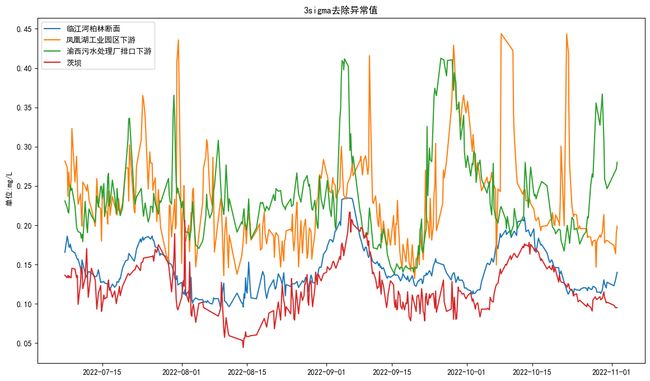
到此数据清洗工作结束。