Seq2Seq+Attention生成式文本摘要
任务描述: 自动摘要是指给出一段文本,我们从中提取出要点,然后再形成一个短的概括性的文本。自动的文本摘要是非常具有挑战性的,因为当我们作为人类总结一篇文章时,我们通常会完整地阅读它以发展我们的理解,然后写一个摘要突出其要点。由于计算机缺乏人类知识和语言能力, 它使自动文本摘要成为一项非常困难和艰巨的任务。自动摘要通常分为抽取式摘要和生成式摘要,区别在于抽取摘要选择原文中若干句子作为只要,而生成式摘要利用文本生成技术根据原文生成摘要,这个摘要会出现原文中没有出现过的句子和词。生成式方法则应用先进的自然语言处理的算法,通过转述、同义替换、句子缩写等技术,生成更凝练简洁的摘要。比起抽取式,生成式更接近人进行摘要的过程。历史上,抽取式的效果通常优于生成式。生成式文本摘要以一种更接近于人的方式生成摘要,这就要求生成式模型有更强的表征、理解、生成文本的能力。传统方法很难实现这些能力,而近几年来快速发展的深度神经网络因其强大的表征(representation)能力,提供了更多的可能性,在图像分类、机器翻译等领域不断推进机器智能的极限。借助深度神经网络,生成式自动文本摘要也有了令人瞩目的发展,不少生成式神经网络模型(neural-network-based abstractive summarization model)在DUC-2004测试集上已经超越了最好的抽取式模型。这部分文章主要介绍生成式神经网络模型的基本结构及最新成果。伴随深度神经网络的兴起和研究,基于神经网络的生成式文本摘要得到快速发展,并取得了不错的成绩。 本教程介绍一种seq2seq+attention 生成式摘要算法。 ### 数据集:使用gigaword数据集,但是由于数据集太过庞大, 只抽取了部分数据,其中训练集20000个数据,验证集1000个数据,测试集1000个数据。本文所阐述的模型主要是借鉴下边这篇机器翻译作为基础来学习生成式文本摘要,两个任务很类似。
可参考学习的论文:谷歌发表的关于机器翻译的论文
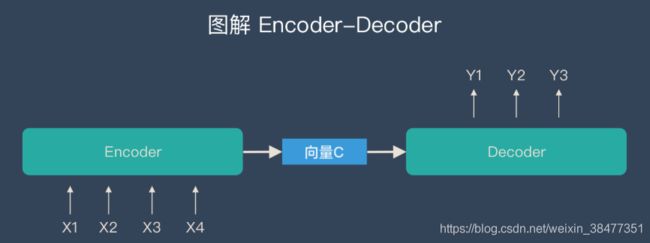
1. encoder-decoder
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。
这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
2. attention mechanism 注意力机制
为了解决上面提到的问题,一种可行的方案是引入attention mechanism。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention:
3.Seq2Seq结构 以机器翻译为例,假设我们要将 How are you 翻译为 你好吗,模型要做的事情 如下图:
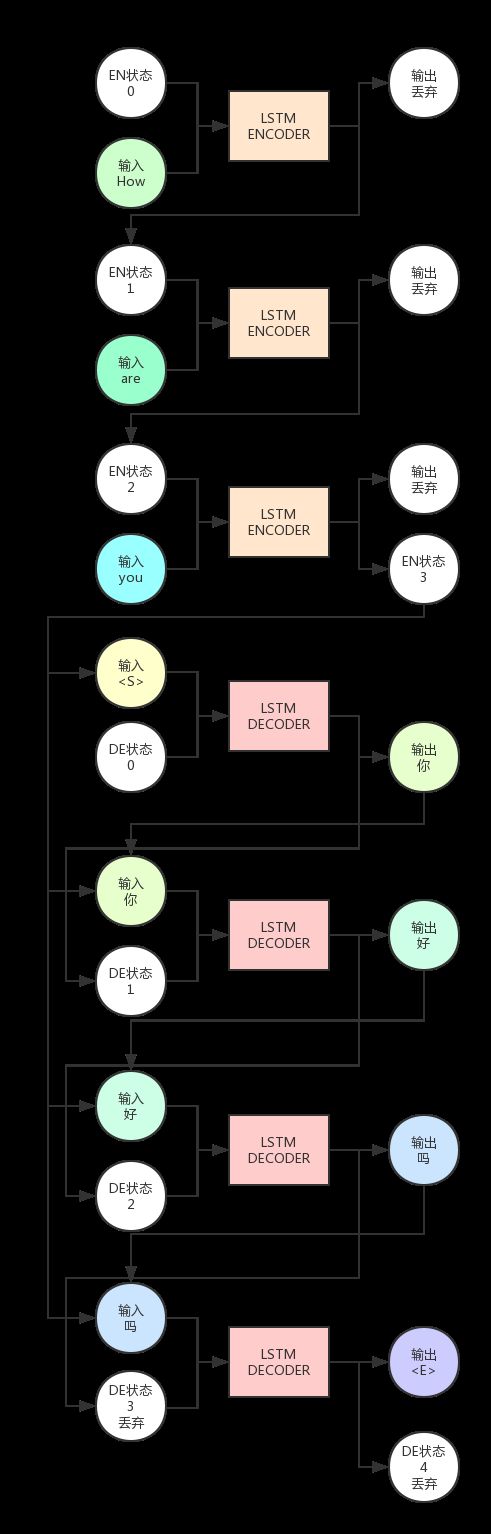
3.1图解:
(1)上图中,LSTM Encoder 是一个 LSTM 神经元,Decoder 是另一个 LSTM 神经元,Encoder 自身运行了 3 次,Decoder 运行了 4 次。
(2)可以看出,Encoder 的输出会被抛弃,我们只需要保留隐藏状态(即图中 EN 状态)作为下一次 Encoder 的状态输入。
(3)Encoder 的最后一轮输出状态会与 Decoder 的输入组合在一起,共同作为 Decoder 的输入。
(4)而 Decoder 的输出会被保留,当做下一次的输入。注意,这是说的是预测时的情况,在训练时一般会用真正正确的输出序列内容,而预测时会用上一轮 Decoder 的输出。
(5)给 Decoder 的第一个输入是 ,这是我们指定的一个特殊字符,它用来告诉 Decoder,你该开始输出信息了。
(6)而最末尾的
3.2、伪数学
从更高层的角度来看算法,整个模型也无非是一种从输入到输出的函数映射。
我们已知的输入数据是 How are you,我们希望的输出是 你好吗,模型学习了下面这些函数映射,组成了一个单射函数:
{How, are, you, } {你}
{How, are, you, , 你} {好}
{How, are, you, , 你, 好} {吗}
{How, are, you, , 你, 好, 吗} {
原文链接:https://blog.csdn.net/weixin_38477351/article/details/108814274
以上是理论部分讲解,可以根据相关的模型和动态图了解到attetnion机制是如何在Seq2Seq模型上进行计算注意力的。
4、关于文本摘要的代码,主要包括五部分,数据的准备、模型的结构以及定义、模型的训练、模型的预测、以及模型评估
##模型的说明,数据的准备以及环境的准备
### 任务描述: 自动摘要是指给出一段文本,我们从中提取出要点,然后再形成一个短的概括性的文本。自动的文本摘要是非常具有挑战性的,因为当我们作为人类总结一篇文章时,我们通常会完整地阅读它以发展我们的理解,然后写一个摘要突出其要点。由于计算机缺乏人类知识和语言能力,
它使自动文本摘要成为一项非常困难和艰巨的任务。自动摘要通常分为抽取式摘要和生成式摘要,区别在于抽取摘要选择原文中若干句子作为只要,而生成式摘要利用文本生成技术根据原文生成摘要,这个摘要会出现原文中没有出现过的句子和词。
本教程介绍一种seq2seq+attention 生成式摘要算法。
### 数据集:使用gigaword数据集,但是由于数据集太过庞大,
只抽取了部分数据,其中训练集20000个数据,验证集1000个数据,测试集1000个数据。
### 运行环境
Python==3.6
numpy==1.18.0
pandas==0.24.2
torch==1.0.0
torchtext==0.4.0
spacy==2.1.8
rouge==1.0.0
尤其要注意mask矩阵时使用的真正的长度-有相应的代码
本次运行的是短文本生成摘要
基于seq2seq+attention
模型的基本原理和机器翻译相同,是生成式的/* 模型主要结构部分 */
# 统一导入工具包
# 使用pip命令安装指定版本工具包
# !pip install numpy==1.18.0 pandas==0.24.2 torch==1.0.0 torchtext==0.4.0 spacy==2.1.8 rouge==1.0.0
"""
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator, TabularDataset, Iterator
import pandas as pd
import spacy
import numpy as np
import random
import math
import time
# 全局初始化配置参数。固定随机种子,使得每次运行的结果相同
#SEED = 22
random.seed(22)
np.random.seed(22)
torch.manual_seed(22)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(22)
torch.backends.cudnn.deterministic = True
#1.数据准备¶使用gigaword数据集本教程的实验数据,并对数据进行预处理,主要包含以下步骤:
#(1) 数据整理
#(2) 数据说明
#(3) 数据预处理:构建分词函数、构件预处理格式、载入数据、构建数据迭代器、构建词表。
#1.1数据整理
#使用gigaword数据集,但是由于数据集太过庞大,只抽取了部分数据,其中训练集20000个数据,验证集1000个数据,测试集1000个数据。其中训练集用以训练模型,
#验证集用以调整训练参数,测试集用以测试模型。
#完整的数据集详见 https://github.com/harvardnlp/sent-summary ,
#需要处理成data_train_path中相同的csv格式。
#数据处理、分词
data_train_path = 'datasets/train.csv'
data_val_path = 'datasets/val.csv'
data_test_path = 'datasets/test.csv'
#1.2数据说明
# 用pandas包读取csv格式的数据,展示数据格式,其中‘document’为原文,‘summary’为原文的摘要
data_train = pd.read_csv(data_train_path,encoding='utf-8')
print(data_train.head())
#1.3数据预处理
#为了方便模型读入数据,需要对模型进行预处理,包括:
#(1)构建分词函数
#(2)构建预处理格式
#(3)载入数据
#(4)构建数据迭代器
#(5)构建词表
#1.3.1 构建分词函数¶分词是自然语言处理的基础,需要识别文本中有哪些词组,
# 方便后续的处理。由于英文以空格的形式隔开,每个单词都是可以独立的词组,因此可以直接用空格符分词,但是为了识别文本中的所有短语词组以得到更准确的摘要结果,
# 这里使用了spacy包里的tokenizer工具对文本中的短语进行分词。
#spacy在使用前下载安装语言包,在终端命令行中输入:
#python -m spacy download en
# 载入spacy的英文处理包
# import en_core_web_md
spacy_en = spacy.load('en_core_web_md')
# 构建分词函数,返回文本里包含的所有词组的列表
def tokenize(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
#1.3.2 构建数据预处理格式
在自然语言处理的预处理中有很多优秀的工具包,可以节省开发人员的开发成本,在这里我们使用torchtext,torchtext是pytorch专门用来处理文本的工具包,使用torchtext的Field函数可以构建预处理格式,这里分别对document和summary进行预处理。Field的部分参数如下:
sequential:代表是否需要将数据序列化,大多数自然语言处理任务都是序列计算
tokenize:需要传入分词函数,传入之前定义的tokenize函数
lower:代表是否转换成小写,为了统一处理,把所有的字符转换成小写
include_lengths:代表是否返回序列的长度,在gpu计算中,通常是对矩阵的运算,因此每个batch中,矩阵的长度为该batch中所有数据里最长的长度,其他长度不够的数据通常用pad字符补齐,这就会导致矩阵中有很多pad字符。为了后续的计算中把这些pad字符规避掉,我们需要返回每个数据的真实长度,这里的长度是指分词后每个文本中词组的数量
init_token:传入起始符号,自然语言处理的任务中通常需要在文本的开头加入起始符号,作为句子的开始标记
eos_token:传入结束符号,自然语言处理的任务中通常需要在文本的加入结束符号,作为句子的结束标记
pad_token:传入pad符号,用来补全长度不够的文本,默认为
unk_token:传入unk符号,默认为。自然语言处理任务中,往往有一些词组不在我们构建的词表中,这种现场叫做00V(Out Of Vocabulary),用一个unk字符来表示这些字符。
...
还有很多默认参数,这里不再一一解释
DOCUMENT = Field(sequential=True, tokenize=tokenize, lower=True, include_lengths=True,
init_token='', eos_token='')
SUMMARY = Field(sequential=True, tokenize=tokenize, lower=True,
init_token='', eos_token='')
#1.3.3 载入数据
#torchtext 的TabularDataset支持直接从csv中载入数据,fileds为csv的每一列指定预处理方式
#这里是原文和摘要两种预处理方式。skip_header代表过滤掉csv的第一行。
fields = [("document", DOCUMENT), ("summary", SUMMARY)]
train = TabularDataset(path=data_train_path, format="csv", fields=fields, skip_header=True)
val = TabularDataset(path=data_val_path, format="csv", fields=fields, skip_header=True)
test = TabularDataset(path=data_val_path, format="csv", fields=fields, skip_header=True)
#1.3.4 构建数据迭代器¶深度学习中,训练、验证和测试通常都是批次的形式,
# 需要构建迭代器,分批次进行计算,这里可以使用torchtext中的BucketIterator或者Iterator自动构建迭代器。BucketIterator和Iterator的区别在于,
# BucketIterator会自动将长度类似的文本归在一个batch,这样可以减少补全字符pad的数量,易于计算。
#一些参数如下:
#train:传入之前用TabularDataset载入的数据
#batch_size:传入每个批次包含的数据数量
#device:代表传入数据的设备,可以选择gpu或者cpu
#sort_within_batch:代表是否对一个批次内的数据排序
#sort_key:排序方式,由于要使用到pack_padded_sequence用来规避pad符号,而pack_padded_sequence需要数据以降序的形式排列,所以这里用document的长度进行降序。
#device = torch.device('cpu')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 5
train_iter = BucketIterator(train, batch_size=BATCH_SIZE, device=device, sort_key=lambda x: len(x.document), sort_within_batch=True)
val_iter = BucketIterator(val, batch_size=BATCH_SIZE, device=device, sort_key=lambda x: len(x.document), sort_within_batch=True)
test_iter = BucketIterator(test, batch_size=BATCH_SIZE, device=device, sort_key=lambda x: len(x.document), sort_within_batch=True)
#1.3.5 构建词表¶自然语言处理任务中往往将字符转换成数字,需要构建词表,用以用数字表示每个词组,并用来训练embedding。
# 在训练集上构建词表,频次低于min_freq的词组会被过滤。构建完词表后会自动将迭代器数据中的字符转换成单词在词表中的序号。
# 在这里,我们对document和summary分别单独构建了词表,也可以只构建一个词表,使document和summary共享词表。
DOCUMENT.build_vocab(train, min_freq = 2)
SUMMARY.build_vocab(train, min_freq = 2)
print("document词表中前100个词:")
print(DOCUMENT.vocab.itos[:100])
#2.模型¶利用pytorch构建模型,并对模型进行训练,主要包括:
#(1)模型概述
#(2)模型结构定义
#(3)模型实例化
#(4)查看模型
#2.1 模型概述
2.2 模型结构定义
Encoder函数构建一个encoder,内部RNN使用了torch内置的GRU,参数为:
input_dim:输入词表的大小
emb_dim:embedding的维度
enc_hid_dim:隐藏层的大小
dropout:dropout的概率
forward参数:
doc:原文数据,是已经由词通过词表转换成序号的数据
doc_len:每个数据的真实长度,在计算RNN时,可以只计算相应长度的状态,不计算pad符号
forword输出Encoder整体的输出,以及Encoder每个状态的输出。每个状态的输出用来计算后续的attention。
值得注意的是,为了规避掉后续计算attention时受到序列中存在pad符号的影响,这里应用了nn.utils的pad_paddad_sequence方法,可以去掉doc_len以后的pad符号,这里pad_packed_sequence的输入为单词序列的embedding和序列的真实长度,这样在计算序列时,就不会计算doc_len后的pad符号了。在计算完RNN后,为了形成一个矩阵方便GPU计算,会把每个doc_len < max_len 的序列填充起来,这里使用了pad_packed_sequence方法,输入为RNN计算后的序列packed_outputs,在后续的attention计算时,会把填充的信息规避掉。
具体实现时,矩阵维度的变换比较繁琐,为了矩阵的运算经常需要增减维度或者交换维度的顺序,代码中已给出标注,建议自己调试一遍,感受维度变换过程。
# encoder的输入为原文,输出为hidden_state,size需要设置
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
# 定义embedding层,直接使用torch.nn.Embedding函数
#input_dim输入词表的大小,emb_dim embedding的维度
self.embedding = nn.Embedding(input_dim, emb_dim)
# 定义rnn层,这里使用torch.nn.GRU,enc_hid_dim:隐藏层的大小
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
# 定义一个全连接层,用来将encoder的输出转换成decoder输入的大小
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
# 定义dropout层,防止过拟合
self.dropout = nn.Dropout(dropout)
def forward(self, doc, doc_len):
# doc = [doc len, batch size]原文数据,是已经由词通过词表转换成序号的数据
# doc_len = [batch size],每个数据的真实长度,在计算RNN时,只计算真实长度,不计算pad符号
embedded = self.dropout(self.embedding(doc))
# embedded = [doc len, batch size, emb dim]
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, doc_len)
packed_outputs, hidden = self.rnn(packed_embedded)
# packed_outputs 包含了每个RNN中每个状态的输出,如图中的h1,h2,h3...hn
# hidden只有最后的输出hn
outputs, _ = nn.utils.rnn.pad_packed_sequence(packed_outputs)
# outputs已经做了填充,但是后续计算attention会规避掉填充的信息
'''n layers代表gru的层数,这里只使用的单层,因此n layer为1'''
# outputs = [doc len, batch size, hid dim * num directions]
# hidden = [n layers * num directions, batch size, hid dim]
# hidden 包含了每一层的最后一个状态的输出,是前后向交替排列的 [第一层前向RNN最后一个状态输出, 第一层后向RNN最后一个状态输出
# 第二层前向RNN最后一个状态输出, 第一层后向RNN最后一个状态输出, ...]
# outputs 仅包含了每个状态最后一层的的输出,且是前后向拼接的
# hidden [-2, :, : ] 前向RNN的最后一个状态输出
# hidden [-1, :, : ] 后向RNN的最后一个状态输出
# 用一个全连接层将encoder的输出表示转换成decoder输入的大小
# tanh为非线性激活函数
hidden = torch.tanh(self.fc(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)))
# outputs = [doc len, batch size, enc hid dim * 2]
# hidden = [batch size, dec hid dim]
return outputs, hidden
构建Attention类,参数:
Attention机制可以建立Decoder的状态和每个ENcoder状态的关系
enc_hid_dim:encoder每个位置输出的维度
dec_hid_dim:decoder每个位置输出的维度
forward的参数:
hidden:decoder里rnn前一个状态的输出
encoder_outs:encoder里rnn的输出
mask:mask矩阵,里面存储的是0-1矩阵,0代表被规避的pad符号的位置
forword的输出为attention中的每个权重,context vector的计算在下面的Decoder类中。
需要注意的是,masked_fill可以用一个值替换矩阵中相应为的值,这里的输入为mask==0和-10e,mask==0代表mask矩阵里值为0的所有位置,
即pad的位置,用-10e来替换这些位置的值,可以在计算softmax前把相应位置的值降得很低,使得softmax计算后,pad符号的相应权重变得几乎为0。
这里计算 $s_2$ 和 Encoder中每个状态的关系,需要用到 $s_1$ 的信息,先计算Decoder中 $s_{i-1}$ 和 Encodr状态 $h_{j}$ 的相似度:
$e_{ij} = a(s_{i-1}, hj)$
将 $[s_{i-1};h_{j}]$ 传入至一个全连接层计算相似度。
然后将$s_{i-1}$ 和 Encoder中每个状态的相似度做一个softmax变化,得到每个Encoder中每个状态所占的权重,作为attention:
$\alpha_{ij} = \frac{exp(e_{ij})}{\sum^{T}_{k = 1}(exp(e_{ik}))}$
attention中的每个权重会用来计算context vector,即上下文的向量:
$c_i = \sum_{k = 1}^{T} \alpha_{ij} h_j$
这个context vector会在Decoder中作为一部分输入。
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs, mask):
# hidden = [batch size, dec hid dim]//decoder里rnn前一个状态的输出
# encoder_outputs = [doc len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
doc_len = encoder_outputs.shape[0]
# 对decoder的状态重复doc_len次,用来计算和每个encoder状态的相似度
hidden = hidden.unsqueeze(1).repeat(1, doc_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# hidden = [batch size, doc len, dec hid dim]
# encoder_outputs = [batch size, doc len, enc hid dim * 2]
# 使用全连接层计算相似度
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# energy = [batch size, doc len, dec hid dim]
# 转换尺寸为[batch, doc len]的形式作为和每个encoder状态的相似度
attention = self.v(energy).squeeze(2)
# attention = [batch size, doc len]
# 规避encoder里pad符号,将这些位置的权重值降到很低
attention = attention.masked_fill(mask == 0, -1e10)
# 返回权重
return F.softmax(attention, dim=1)
Decoder接收之前的状态信息、输入的单词和context vector,预测生成摘要的单词
Decoder的RNN与Encoder中的RNN有所不同,输入为[前一步生成单词的embedding;context vector]和前一步的状态 $h_{i-1}$,目的是引入attention的信息:
$s_i = RNN([e(y_{i-1});c],s_{i-1})$
在预测生成的单词时,将context vector、 RNN的输出状态、前一步生成单词的embedding连接起来输入至全连接层预测:
$y_i = softmax(w[c;s_i;e(y_{i-1})] + b)$
构建Decoder类,参数为:
output_dim:输出的维度,为词表的长度
emb_dim:embedding的维度
enc_hid_dim:encoder每个位置输出的维度
dec_hid_dim:decoder每个位置输出的维度
dropout:dropout的概率
attention:需要传入attention类,用来计算decoder每个位置的输出和encoder每个位置的输出的关系
forword参数:
input:输入单词的序号
hidden:上一步Decoder输出的状态
encoder_outputs:Encoder每个状态的输出,用来计算attention
mask:mask矩阵,用来在计算attention时,规避pad符号的影响
forword输出为全连接层的输出、这一步Decoder的输出和attention的权重。这里输出的是预测时全连接层的输出,目的是计算后续的损失。
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs, mask):
# input = [batch size]
# hidden = [batch size, dec hid dim]
# encoder_outputs = [doc len, batch size, enc hid dim * 2]
# mask = [batch size, doc len]
input = input.unsqueeze(0)
# input = [1, batch size]
embedded = self.dropout(self.embedding(input))
# embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs, mask)
# a = [batch size, doc len]
a = a.unsqueeze(1)
# a = [batch size, 1, doc len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# encoder_outputs = [batch size, doc len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
# weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
# output = [seq len, batch size, dec hid dim * n directions]
# hidden = [n layers * n directions, batch size, dec hid dim]
# seq len, n layers and n directions 在decoder为1的情况比较多, 所以:
# output = [1, batch size, dec hid dim]
# hidden = [1, batch size, dec hid dim]
# output和hidden应该是相等的,output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden.squeeze(0), a.squeeze(1)
构建一个seq2seq类将encoder、decoder和attention整合起来,参数:
encoder:encoder类
decoder:decoder类
doc_pad_idx:原文词典中pad符号的序号
device:需要传入的设备
create_mask的参数:
doc:原文数据,create_mask会根据原文中pad符号的位置构建mask矩阵,这个mask矩阵会传入decoder,可以在计算attention时规避到pad符号的影响
forward的参数:
doc:传入的一个批次的原文数据,是已经由词转换成序号的数据
doc_len:一个批次里每个数据的长度,用来生成mask矩阵
#sum:摘要数据,同样已被转换成序号
teacher_forcing_ratio:teacher_forcing的概率,teacher_forcing是文本生成技术常用的技术,在训练时,如果一个词生成有误差,可能会影响到后面所有的词,所以以一定的概率选择生成的词还是标注的训练数据中相应位置的词,在验证测试时,不会用到teacher_forcing
forword输出生成的整体序列
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, doc_pad_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.doc_pad_idx = doc_pad_idx #原文词典中pad符号的序号
self.device = device
def create_mask(self, doc):
mask = (doc != self.doc_pad_idx).permute(1, 0)
return mask
def forward(self, doc, doc_len, sum, teacher_forcing_ratio=0.5):
# doc = [doc len, batch size]原文数据
# doc_len = [batch size]
# sum = [sum len, batch size]摘要数据
# teacher_forcing_ratio 是使用teacher forcing的概率
batch_size = doc.shape[1]
sum_len = sum.shape[0]
sum_vocab_size = self.decoder.output_dim
# 定义一个tensor来储存每一个生成的单词序号
outputs = torch.zeros(sum_len, batch_size, sum_vocab_size).to(self.device)
# encoder_outputs是encoder所有的输出状态
# hidden这是encoder整体的输出
encoder_outputs, hidden = self.encoder(doc, doc_len)
# 输入的第一个字符为
input = sum[0, :]
# 构建一个mask矩阵,包含训练数据原文中pad符号的位置
mask = self.create_mask(doc)
# mask = [batch size, doc len]
for t in range(1, sum_len):
# decoder 输入 前一步生成的单词embedding, 前一步状态hidden, encoder所有状态以及mask矩阵
# 返回预测全连接层的输出和这一步的状态
output, hidden, _ = self.decoder(input, hidden, encoder_outputs, mask)
# 把output的信息存储在之前定义的outputs里
outputs[t] = output
# 生成一个随机数,来决定是否使用teacher forcing
teacher_force = random.random() < teacher_forcing_ratio
# 获得可能性最高的单词序号作为生成的单词
top1 = output.argmax(1)
# 如果使用teacher forcing则用训练数据相应位置的单词
# 否则使用生成的单词 作为下一步的输入单词
input = sum[t] if teacher_force else top1
return outputs
INPUT_DIM = len(DOCUMENT.vocab)#输入的词表大小
OUTPUT_DIM = len(SUMMARY.vocab)#输出维度为词表的长度
ENC_EMB_DIM = 4
DEC_EMB_DIM = 4
ENC_HID_DIM = 8
DEC_HID_DIM = 8
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
DOC_PAD_IDX = DOCUMENT.vocab.stoi[DOCUMENT.pad_token]
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, DOC_PAD_IDX, device).to(device)
#查看模型
print(model)
#模型训练
使用之前处理的训练数据对模型训练,主要包括
(1)定义训练函数
(2)定义验证函数
(3)定义时间显示函数
(4)训练过程
(5)模型保存
3.1 定义训练函数¶定义训练一个epoch的函数,并返回损失,参数:
model:用以训练的模型
iteration:用以训练的数据迭代器
optimizer:训练模型使用的优化器
criterion:训练模型使用的损失函数
### clip:梯度截断的值,传入torch.nn.utils.clip_grad_norm_中,如果梯度超过这个clip,
会使用clip对梯度进行截断,可以预防训练初期的梯度爆炸现象。
def train(model, iterator, optimizer, criterion, clip):
model.train()#模型开始训练
epoch_loss = 0
for i, batch in enumerate(iterator):
doc, doc_len = batch.document
sum = batch.summary
optimizer.zero_grad()
output = model(doc, doc_len, sum)
# sum = [sum len, batch size]
# output = [sum len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
sum = sum[1:].view(-1)
# sum = [(sum len - 1) * batch size]
# output = [(sum len - 1) * batch size, output dim]
loss = criterion(output, sum)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
if i>20:break
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
### 不启用 BatchNormalization 和 Dropout,
### 评估/验证的常用做法是torch.no_grad()与配对使用model.eval()以关闭梯度计算:
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
doc, doc_len = batch.document
sum = batch.summary
output = model(doc, doc_len, sum, 0) # 验证时不使用teacher forcing
# sum = [sum len, batch size]
# output = [sum len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
sum = sum[1:].view(-1)
# sum = [(sum len - 1) * batch size]
# output = [(sum len - 1) * batch size, output dim]
loss = criterion(output, sum)
epoch_loss += loss.item()
if i>20:break
return epoch_loss / len(iterator)
### 定义时间显示函数
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 20
# N_EPOCHS = 10
CLIP = 1
lr= 0.001
weight_decay= 0.0001
SUM_PAD_IDX = SUMMARY.vocab.stoi[SUMMARY.pad_token]
# 使用ignore_index参数,使得计算损失的时候不计算pad的损失
criterion = nn.CrossEntropyLoss(ignore_index = SUM_PAD_IDX)
optimizer = optim.Adam(model.parameters(), lr=lr,weight_decay=weight_decay)
# 训练
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iter, optimizer, criterion,CLIP)
valid_loss = evaluate(model, val_iter, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch + 1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
"""
# 模型保存
torch.save(model.state_dict(), './temp/model.pt')
#模型加载
model.load_state_dict(torch.load('./temp/model.pt'))
#构建预测函数,输入生成摘要的字符串
""""
构建生成的函数,输入原文的字符串,输出生成摘要的字符串,参数为:
doc_sentence:摘要的字符串
doc_field:之前定义的针对document的预处理格式DOCUMENT
sum_field:之前定义的针对summary的预处理格式SUMMARY
model:训练的seq2seq模型
device:数据存放的设备
max_len:生成摘要的最长长度
"""
def generate_summary(doc_sentence,doc_field,sum_field,model,device,max_len=50):
# 将模型置为验证模式
model.eval()
# 对原文分词
nlp = spacy.load('en_core_web_md')
# nlp = spacy.load('en_core_web_md')
tokens = [token.text.lower() for token in nlp(doc_sentence)]
# 为原文加上起始符号和结束符号
tokens = [doc_field.init_token] + tokens + [doc_field.eos_token]
# 将字符转换成序号
doc_indexes = [doc_field.vocab.stoi[token] for token in tokens]
# 转换成可以gpu计算的tensor
doc_tensor = torch.LongTensor(doc_indexes).unsqueeze(1).to(device)
doc_len = torch.LongTensor([len(doc_indexes)]).to(device)
# 计算encoder
with torch.no_grad():
encoder_outputs, hidden = model.encoder(doc_tensor, doc_len)
mask = model.create_mask(doc_tensor)
# 生成摘要的一个单词
sum_indexes = [sum_field.vocab.stoi[sum_field.init_token]]
# 构建一个attention tensor,存储每一步的attention
attentions = torch.zeros(max_len, 1, len(doc_indexes)).to(device)
for i in range(max_len):
sum_tensor = torch.LongTensor([sum_indexes[-1]]).to(device)
# 计算每一步的decoder
with torch.no_grad():
output, hidden, attention = model.decoder(sum_tensor, hidden, encoder_outputs, mask)
attentions[i] = attention
pred_token = output.argmax(1).item()
# 如果出现了 则直接结束计算
if pred_token == sum_field.vocab.stoi[sum_field.eos_token]:
break
sum_indexes.append(pred_token)
# 把序号转换成单词
sum_tokens = [sum_field.vocab.itos[i] for i in sum_indexes]
return sum_tokens[1:], attentions[:len(sum_tokens)-1]
#读取数据
data_test = pd.read_csv("datasets/test.csv",encoding='utf-8')
data_test = data_test[:100]
doc_sentence_list = data_test['document'].tolist()
sum_sentence_list = data_test['summary'].tolist()
#开始进行预测
generated_summary = []
for doc_sentence in doc_sentence_list:
summary_words,attention = generate_summary(doc_sentence,DOCUMENT,SUMMARY,model,device,max_len = 50)
summary_sentence = (' ').join(summary_words)
generated_summary.append(summary_sentence)
# 输出一个生成的摘要
indices = random.sample(range(0, len(sum_sentence_list)), 5)
for index in indices:
print("document:")
print(doc_sentence_list[index])
print("generated summary:")
print(generated_summary[index])
print("reference summary:")
print(sum_sentence_list[index])
print("---------------")
#模型加载
model.load_state_dict(torch.load('./temp/model.pt'))
# 输出测试集损失
test_loss = evaluate(model, test_iter, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
#输出评估指标
from rouge import Rouge
rouge = Rouge()
#scores = rouge.get_scores(generated_summary, sum_sentence_list,avg=True)
scores = rouge.get_scores(generated_summary,sum_sentence_list,avg=True)
print(scores)
## 模型的预测和加载
#模型加载
model.load_state_dict(torch.load('./temp/model.pt'))
#构建预测函数,输入生成摘要的字符串
""""
构建生成的函数,输入原文的字符串,输出生成摘要的字符串,参数为:
doc_sentence:摘要的字符串
doc_field:之前定义的针对document的预处理格式DOCUMENT
sum_field:之前定义的针对summary的预处理格式SUMMARY
model:训练的seq2seq模型
device:数据存放的设备
max_len:生成摘要的最长长度
"""
def generate_summary(doc_sentence,doc_field,sum_field,model,device,max_len=50):
# 将模型置为验证模式
model.eval()
# 对原文分词
nlp = spacy.load('en_core_web_md')
# nlp = spacy.load('en_core_web_md')
tokens = [token.text.lower() for token in nlp(doc_sentence)]
# 为原文加上起始符号和结束符号
tokens = [doc_field.init_token] + tokens + [doc_field.eos_token]
# 将字符转换成序号
doc_indexes = [doc_field.vocab.stoi[token] for token in tokens]
# 转换成可以gpu计算的tensor
doc_tensor = torch.LongTensor(doc_indexes).unsqueeze(1).to(device)
doc_len = torch.LongTensor([len(doc_indexes)]).to(device)
# 计算encoder
with torch.no_grad():
encoder_outputs, hidden = model.encoder(doc_tensor, doc_len)
mask = model.create_mask(doc_tensor)
# 生成摘要的一个单词
sum_indexes = [sum_field.vocab.stoi[sum_field.init_token]]
# 构建一个attention tensor,存储每一步的attention
attentions = torch.zeros(max_len, 1, len(doc_indexes)).to(device)
for i in range(max_len):
sum_tensor = torch.LongTensor([sum_indexes[-1]]).to(device)
# 计算每一步的decoder
with torch.no_grad():
output, hidden, attention = model.decoder(sum_tensor, hidden, encoder_outputs, mask)
attentions[i] = attention
pred_token = output.argmax(1).item()
# 如果出现了 则直接结束计算
if pred_token == sum_field.vocab.stoi[sum_field.eos_token]:
break
sum_indexes.append(pred_token)
# 把序号转换成单词
sum_tokens = [sum_field.vocab.itos[i] for i in sum_indexes]
return sum_tokens[1:], attentions[:len(sum_tokens)-1]
#读取数据
data_test = pd.read_csv("datasets/test.csv",encoding='utf-8')
data_test = data_test[:100]
doc_sentence_list = data_test['document'].tolist()
sum_sentence_list = data_test['summary'].tolist()
#开始进行预测
generated_summary = []
for doc_sentence in doc_sentence_list:
summary_words,attention = generate_summary(doc_sentence,DOCUMENT,SUMMARY,model,device,max_len = 50)
summary_sentence = (' ').join(summary_words)
generated_summary.append(summary_sentence)
# 输出一个生成的摘要
indices = random.sample(range(0, len(sum_sentence_list)), 5)
for index in indices:
print("document:")
print(doc_sentence_list[index])
print("generated summary:")
print(generated_summary[index])
print("reference summary:")
print(sum_sentence_list[index])
print("---------------")
#模型加载
model.load_state_dict(torch.load('./temp/model.pt'))
# 输出测试集损失
test_loss = evaluate(model, test_iter, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
#输出评估指标
from rouge import Rouge
rouge = Rouge()
#scores = rouge.get_scores(generated_summary, sum_sentence_list,avg=True)
scores = rouge.get_scores(generated_summary,sum_sentence_list,avg=True)
print(scores)
5、文本摘要模型评估函数
人工评价方法
评估一篇摘要的好坏,最简单的方法就是邀请若干专家根据标准进行人工评定。这种方法比较接近人的阅读感受,但是耗时耗力,无法用于对大规模自动文本摘要数据的评价,和自动文本摘要的应用场景并不符合。因此,文本摘要研究团队积极地研究自动评价方法。
自动评价方法
为了更高效地评估自动文本摘要,可以选定一个或若干指标(metrics),基于这些指标比较生成的摘要和参考摘要(人工撰写,被认为是正确的摘要)进行自动评价。目前最常用、也最受到认可的指标是ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。ROUGE是Lin提出的一个指标集合,包括一些衍生的指标,最常用的有ROUGE-n,ROUGE-L,ROUGE-SU:
- ROUGE-n:该指标旨在通过比较生成的摘要和参考摘要的n-grams(连续的n个词)评价摘要的质量。常用的有ROUGE-1,ROUGE-2,ROUGE-3。
- ROUGE-L:不同于ROUGE-n,该指标基于最长公共子序列(LCS)评价摘要。如果生成的摘要和参考摘要的LCS越长,那么认为生成的摘要质量越高。该指标的不足之处在于,它要求n-grams一定是连续的。
- ROUGE-SU:该指标综合考虑uni-grams(n = 1)和bi-grams(n = 2),允许bi-grams的第一个字和第二个字之间插入其他词,因此比ROUGE-L更灵活。 作为自动评价指标,ROUGE和人工评定的相关度较高,在自动评价摘要中能给出有效的参考。但另一方面,从以上对ROUGE指标的描述可以看出,ROUGE基于字的对应而非语义的对应,生成的摘要在字词上与参考摘要越接近,那么它的ROUGE值将越高。但是,如果字词有区别,即使语义上类似,得到的ROUGE值就会变低。换句话说,如果一篇生成的摘要恰好是在参考摘要的基础上进行同义词替换,改写成字词完全不同的摘要,虽然这仍是一篇质量较高的摘要,但ROUGE值会呈现相反的结论。从这个极端但可能发生的例子可以看出,自动评价方法所需的指标仍然存在一些不足。目前,为了避免上述情况的发生,在evaluation时,通常会使用几篇摘要作为参考和基准,这有效地增加了ROUGE的可信度,也考虑到了摘要的不唯一性。对自动评价摘要方法的研究和探索也是目前自动文本摘要领域一个热门的研究方向。
参考资料
1、python自然语言处理—Seq2Seq(sequence-to-sequence)_诗雨时的博客-CSDN博客_python seq2seq
2、seq2seq和attention应用到文档自动摘要_dili8870的博客-CSDN博客
3、个人工作平台