经典CNN及PyTorch实现
经典CNN及PyTorch实现
- LeNet
-
-
- 架构图:
- 网络结构块的实现:
-
- AlexNet:
-
-
- 架构图:
- 网络架构块的实现:
-
- VGG网络:
-
-
- 架构图:
- 网络架构块的实现:
-
- NiN:
-
-
- 架构图:
- 网络架构块的实现:
-
- GoogLeNet
-
-
- 架构图:
- 网络架构块的实现:
-
- ResNet:
-
-
- 架构图:
- 网络架构块的实现:
-
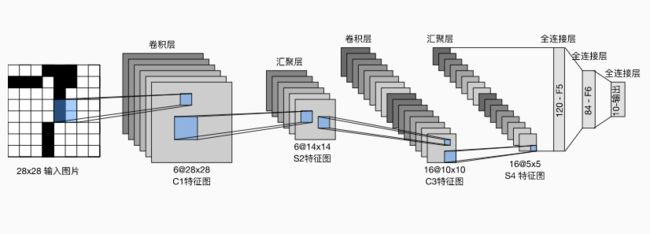
LeNet
架构图:
总的来看,LeNet由两个部分组成:
- 卷积编码器:两个卷积层;
- 全连接层密集块:三个全连接层
网络结构块的实现:
以size=(1, 1, 28, 28)的输入为例,中间变换过程中的形状如下:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 15:07
@Author : Jay Zhang
@Email : [email protected]
@File : 01_LeNet.py
"""
import torch
from torch import nn
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16*5*5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)
)
if __name__ == '__main__':
# 打印形状检查模型
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
- 卷积神经网络(CNN)是一类使用卷积层的网络。
- 在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。
- 为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。
- 在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。
- LeNet是最早发布的卷积神经网络之一。
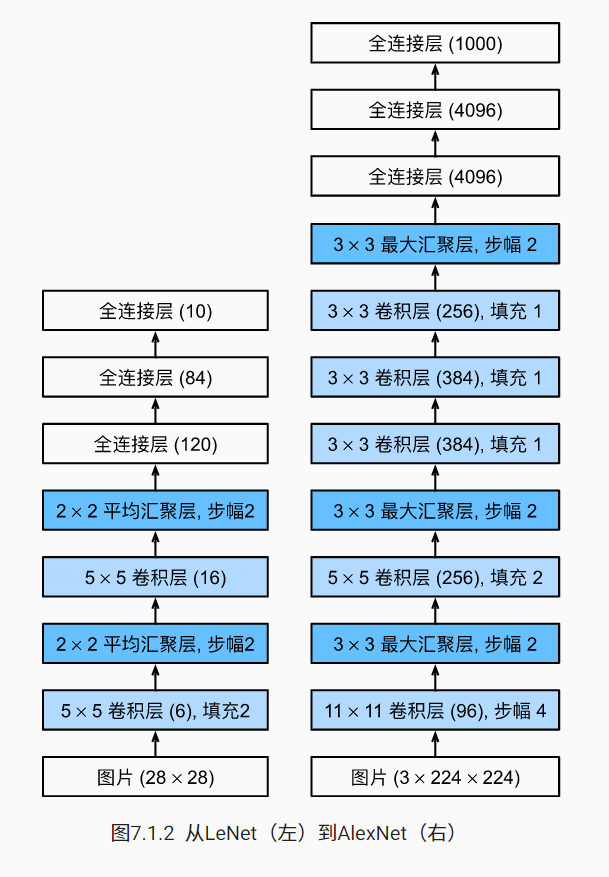
AlexNet:
架构图:
AlexNet一共由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层;其次,AlexNet使用ReLU而不是SigMoid作为其激活函数。
网络架构块的实现:
以size=(1, 1, 224, 224)的输入为例,中间变换过程中的形状如下:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 15:40
@Author : Jay Zhang
@Email : [email protected]
@File : 02_AlexNet.py
"""
import torch
from torch import nn
net = nn.Sequential(
# 输入为3*224*224 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
if __name__ == '__main__':
# 打印形状检查模型
X = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
- AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
- 今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
- 尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
- Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
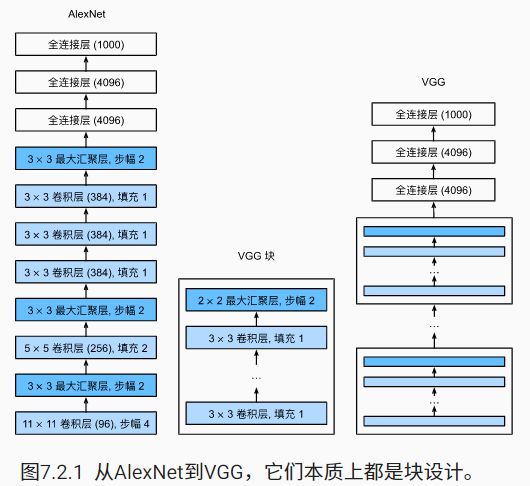
VGG网络:
VGG网络可以分为两部分:
- 第一部分由卷积层和汇聚层组成
- 第二部分由全连接层组成
架构图:
网络架构块的实现:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 16:13
@Author : Jay Zhang
@Email : [email protected]
@File : 03_VGG.py
"""
import torch
from torch import nn
# 用来实现VGG块的函数
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
# MaxPool后宽高减半
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
# VGG-11
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
if __name__ == '__main__':
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
Process finished with exit code 0
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效。
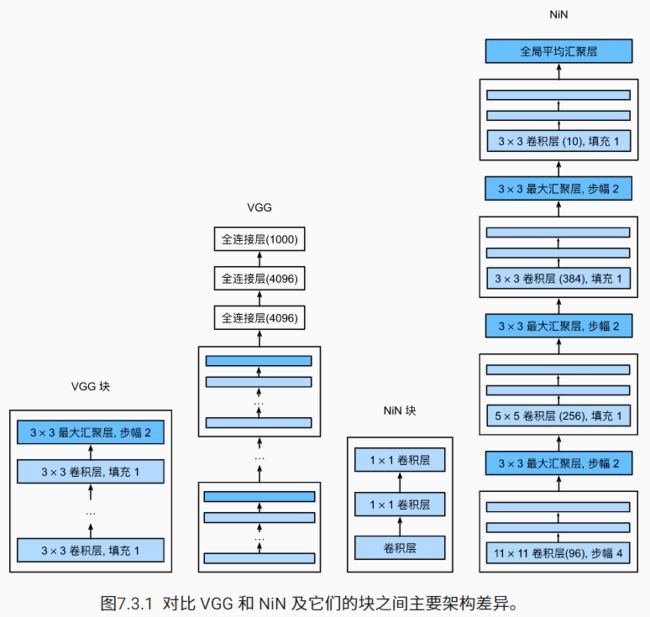
NiN:
NiN块以一个普通卷积层开始,后面是两个1×1的卷积层。这两个1×1卷积层充当带有ReLU激活函数的逐像素全连接层。
架构图:
网络架构块的实现:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 16:25
@Author : Jay Zhang
@Email : [email protected]
@File : 04_NiN.py
"""
import torch
from torch import nn
# 定义NiN块
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
# 1*1融合通道
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()
)
# NiN模型
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten()
)
if __name__ == '__main__':
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
Process finished with exit code 0
- NiN使用由一个卷积层和多个1×1卷积层组成的块。该块可以在卷积神经网络中使用,以允许更多的每像素非线性。
- NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
- 移除全连接层可减少过拟合,同时显著减少NiN的参数。
- NiN的设计影响了许多后续卷积神经网络的设计。
GoogLeNet
这里来吐槽一下GoogLeNet,放在当时这真是有钱人的游戏,而且是很玄学的。如果你没有很好的机器怎么会无聊到写这么这么复杂的网络,而且理论性也不强。害,这就是炼丹师是嘛 好像意识到了
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
架构图:

有很多滤波器的组合,不同大小的滤波器可以有效地识别不同范围的图像细节。 同时,我们可以为不同的滤波器分配不同数量的参数。
网络架构块的实现:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 16:38
@Author : Jay Zhang
@Email : [email protected]
@File : 05_GoogLeNet.py
"""
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten()
)
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
if __name__ == '__main__':
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 24, 24])
Sequential output shape: torch.Size([1, 192, 12, 12])
Sequential output shape: torch.Size([1, 480, 6, 6])
Sequential output shape: torch.Size([1, 832, 3, 3])
Sequential output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 10])
- Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1×1卷积层减少每像素级别上的通道维数从而降低模型复杂度。
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
ResNet:
加很多层就一定能像前边的模型一样提高精度吗?不一定,如其架构图:⭐为最优点的话,网络如果一直向错误方向加深,并不能达到最优点,如果你能保证复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
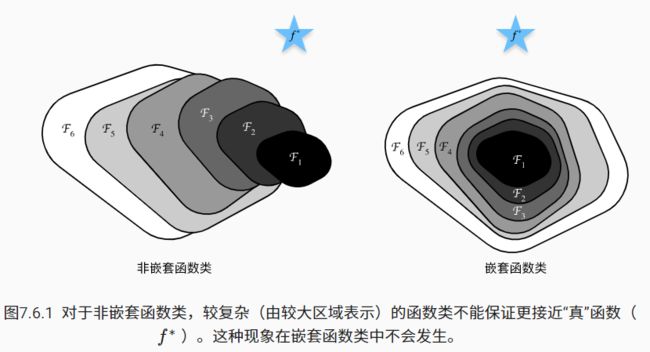
架构图:

网络架构块的实现:
# -*- coding: utf-8 -*-
"""
@Time : 2021/12/19 16:59
@Author : Jay Zhang
@Email : [email protected]
@File : 06_ResNet.py
"""
import torch
from torch import nn
from torch.nn import functional as F
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
# 使用1*1卷积会调整分辨率和通道
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 每个模块使用2个残差块
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10)
)
if __name__ == '__main__':
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
- 学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
- 利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。