transformers AutoModelForMaskedLM简单使用
参考:https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForMaskedLM
使用预测
预测mask值可以
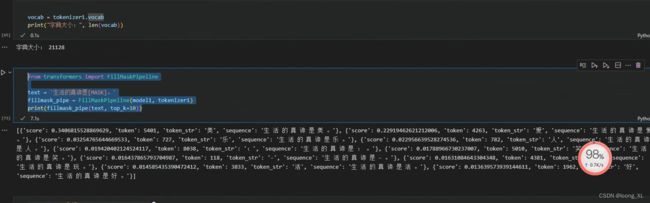
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer1 = AutoTokenizer.from_pretrained("bert-base-chinese")
model1 = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
from transformers import FillMaskPipeline
text = '生活的真谛是[MASK]。'
fillmask_pipe = FillMaskPipeline(model1, tokenizer1)
print(fillmask_pipe(text, top_k=10))
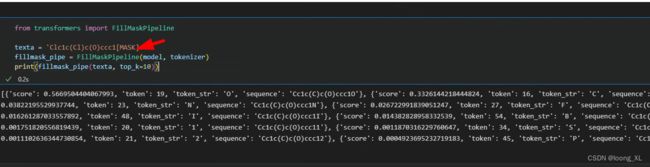
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("DeepChem/ChemBERTa-77M-MLM")
model = AutoModelForMaskedLM.from_pretrained("DeepChem/ChemBERTa-77M-MLM")
from transformers import FillMaskPipeline
texta = 'Clc1c(Cl)c(O)ccc1[MASK]。'
fillmask_pipe = FillMaskPipeline(model, tokenizer)
print(fillmask_pipe(texta, top_k=10))
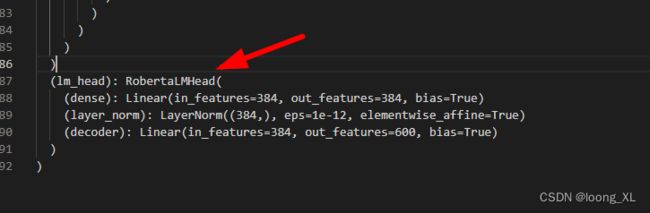
可以打印model查看模型结果;AutoModelForMaskedLM最后一层有个LMhead
print(model)
预训练,微调
参考:
https://zhuanlan.zhihu.com/p/435712578
https://cloud.tencent.com/developer/article/1854279
https://www.modb.pro/db/434589
其他预训练对应的头包含还有BertForPreTraining、BertForMaskedLM、BertForNextSentencePrediction等等
简单预训练的demo
>>> from transformers import BertTokenizer, BertForMaskedLM
>>> import torch
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> model = BertForMaskedLM.from_pretrained('bert-base-uncased')
>>> inputs = tokenizer("The capital of France is [MASK].", return_tensors="pt")
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> logits = outputs.logits
或参考官方案例:https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling
# 对模型进行MLM预训练
from transformers import AutoModelForMaskedLM,AutoTokenizer
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
from transformers import LineByLineTextDataset
import os
import math
model_dir = "../model"
model_name = "roberta-large"
train_file = "../data/wikitext-2/data.txt"
eval_file = "../data/wikitext-2/data.txt"
max_seq_length = 512
out_model_path = os.path.join(model_dir,'pretain')
train_epoches = 10
batch_size = 2
# 这里不是从零训练,而是在原有预训练的基础上增加数据进行预训练,因此不会从 config 导入模型
tokenizer = AutoTokenizer.from_pretrained(os.path.join(model_dir,model_name), use_fast=True)
model = AutoModelForMaskedLM.from_pretrained(os.path.join(model_dir,model_name))
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path=train_file,
block_size=128,
)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
eval_dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path=eval_file,
block_size=128,
)
training_args = TrainingArguments(
output_dir=out_model_path,
overwrite_output_dir=True,
num_train_epochs=train_epoches,
per_device_train_batch_size=batch_size,
save_steps=2000,
save_total_limit=2,
prediction_loss_only=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
trainer.train()
trainer.save_model(out_model_path)
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")