YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss 笔记
YOLO-Pose:使用OKS Loss增强YOLO多人姿态估计
CVPRW 2022
论文链接
代码链接
摘要: 本文引入了一种新的 heatmap-free 联合检测法:YOLO-Pose,基于YOLO目标检测框架进行2D多人姿态估计。现有的基于热图的两阶段方法是次优的,因为它们不是端到端可训练的,且训练依赖于一个surrogate L1 loss,该损失不能直接优化评估指标:对象关键点相似(OKS)。YOLO-Pose能够端到端训练,并优化OKS指标本身。模型学习在一次前向传递中联合检测多个人体边界框及其相应的2D姿态,从而实现自顶向下和自下而上的最佳方法。 本方法中每个人体边界框都有一个相关联的姿态,形成了关键点的固有分组,因此无需bottom-up法的后处理来将检测到的关键点分组到骨架中。不同于top-down方法,本方法在一次推理中定位所有人的姿态,而无需多次前向传递。YOLO-Pose在COCO val set(90.2%AP50)和test-dev set(90.3%AP50)上取得了sota,超越了现有的bottom-up法,YOLO-Pose 只需一次forward pass,无需 flip test,multi-scale testing或任何其他 test time augmentation。与使用 flip test 和 multi-scale testing来提高性能的传统方法不同,本文报告的所有实验结果都未使用任何 test time augmentation。
文章目录
- YOLO-Pose:使用OKS Loss增强YOLO多人姿态估计
- 1. Introduction
- 2. Related Work
- 3. YOLO-Pose
-
- 3.1. Overview
- 3.2. Anchor based multi-person pose formulation
- 3.3. IoU Based Bounding-box Loss Function
- 3.4. Human Pose Loss Function Formulation
- 3.5. Test Time Augmentations
- 3.6. Keypoint Outside Bounding Box
- 3.7. ONNX Export for Easy Deployability
- 4. Experiments
-
- 4.2. Results on COCO val2017
- 4.3. Ablation Study: OKS Loss vs L1 Loss.
- 4.4. Ablation Study: Across Resolution.
- 4.5. Ablation Study: Quantization
- 4.6. Results on COCO test-dev2017.
- 5. Conclusion
1. Introduction
Top-down 法的复杂性与图像中的人数成线性关系。大多数需要恒定运行时间的实时应用一般不采用复杂性高且运行时间可变的 top-down 法。相比之下,bottom-up 法具有恒定运行时间,它们依赖热图检测所有关键点,然后通过复杂的后处理将其分组为个人。bottom-up 法中的后处理可能涉及像素级NMS、线积分、细化、分组等步骤,坐标调整和细化减少了热图下采样的量化误差,而NMS用于查找热图中的局部极大值。即使经过后处理,热图也可能不够清晰,无法区分两个非常接近的同类型关节。另外,后处理步骤是不可微的,且在卷积网络之外进行,因此 bottom-up 法不能进行端到端训练。 从线性规划到各种启发式,bottom-up 法的后处理方法有很大的不同,很难使用CNN加速器加速,因此速度很慢。One-shot 法虽然避免了分组任务,但其性能不如 bottom-up 法,而且它们依赖额外的后处理来提高性能。
本工作的动机是解决无热图的姿态估计问题,并与目标检测保持一致。目标检测与姿态估计具有类似的挑战,如尺度变化、遮挡、人体的非刚性等。因此,若一个人体检测器网络能够解决这些挑战,那么它也可以很好地处理姿态估计。最新的目标检测框架试图通过多尺度预测来缓解尺度变化问题,这里,我们采用相同的策略,在每次检测的多个尺度上预测人体姿态。同样,目标检测领域的进展都可以无缝传递给姿态估计。我们提出的姿态估计技术在不额外增加计算量的情况下,可以很容易地集成到任何运行目标检测的计算机视觉系统中。
YOLO-Pose 基于YOLOv5框架,有针对性地解决无热图的2D姿态估计问题,消除目前使用的各种非标准化后处理。YOLO-Pose 使用与目标检测相同的后处理,在COCO关键点数据集上的结果表明其AP精度有竞争力,且能显著提升AP50。
在此方法中,与 ground truth box 匹配的 anchor box 或 anchor point 存储其完整的2D姿态以及bounding box位置。 来自不同人的两个相似关节在空间上可能彼此靠近,使用热图难以区分不同人的两个空间相近的相似关节,但若这两个人匹配不同的anchor,则很容易区分空间上相近且相似的关键点。 同样,与 anchor 点关联的关键点已经分组,因此无需进一步分组。如图1所示,bottom-up法中,一个人的关键点很容易被误认为是另一个人的,而此工作本质上解决了这个问题。与Top-down法不同,YOLO-Pose 的复杂性与图像中的人数无关。因此,此方法取得了top-down和bottom-up两种方法中的最佳方法:恒定运行时间和简单的后处理。
总体而言,我们做出了以下贡献:
- 我们提出根据目标检测解决多人姿态估计问题,因为两者都具有尺度变化和遮挡这样的常见挑战。因此,我们迈出了统一这两个领域的第一步。我们的方法直接得益于目标检测领域的进步。
- 我们的 heatmap-free 法使用标准的目标检测后处理,而不涉及像素级NMS、调整、细化、线积分和各种分组算法的复杂后处理。由于无需独立的后处理,端到端训练使该方法非常可靠。
- 将IoU loss 从box detection 扩展到关键点。对象关键点相似性(OKS)不仅用于评估,还用于训练。OKS loss 具有尺度不变性,本质上为不同的关键点赋予不同的权重。
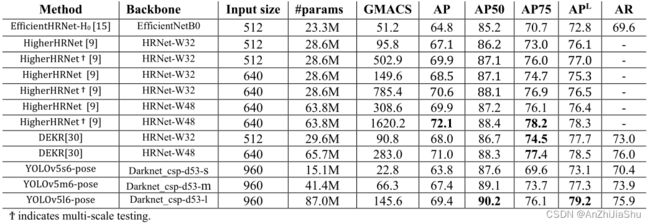
- 我们实现了SOTA AP50,且计算量减少了约4倍。在coco test-dev2017中,相较于SOTA DEKR 在283.0 GMACS上的 89.4 AP50,Yolov5m6Pose在66.3 GMACS达到89.8的AP50。(GMACS: Giga Multiply-Accumulation operations per second,每秒千兆倍累积操作数,1MAC = 2 OP,即一个MAC (乘,加,各被认为是一个operation))
- 提出了一种联合检测和姿态估计框架。目标检测网络几乎可以任意进行姿态估计。
- 我们提出了低复杂度的模型变体,大大优于EfficientHRNet 等 real-time focused models。
2. Related Work
略
3. YOLO-Pose
YOLO-Pose 和其他 bottom-up 法一样,是一种 single shot 方法,但它不使用热图而是将一个人的所有关键点与 anchor 联系起来。它基于YOLOv5目标检测框架,也可以扩展到其他框架。我们已经在YOLOX 上进行了有限程度的验证。图2展示了带有keypoint heads 用于姿态估计的整体结构。
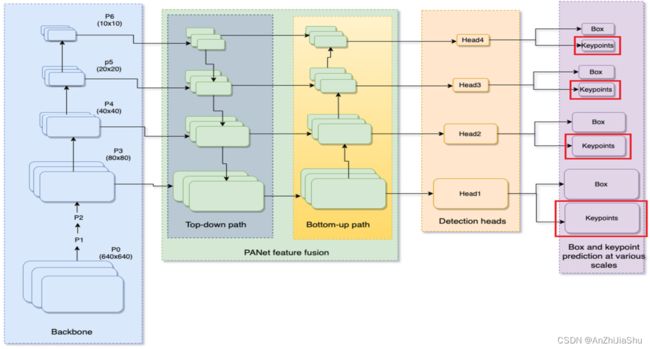
3.1. Overview
为展示我们解决方案的潜力,我们选择一个善于检测人体的架构。YOLOv5是一个准确性高且且复杂性低的检测器,因此,我们选择它作为 base 并进行重构。YOLOv5主要关注COCO目标检测的80个类,box head 为每个anchor预测 85个元素,分别对应于80个类的 bounding box,object score 和 confidence score。每个 grid 位置,有三个不同 shape 的anchor。
人体姿态估计可以归结为一个单一类人体检测问题,每个人有17个关键点,每个关键点都会再次用位置和置信度进行识别:{x, y, conf},因此,一个anchor关联17个关键点共51个元素。因此,对于每个anchor,keypoint头预测51个元素,box头预测6个元素。对于一个具有n个关键点的anchor,总体预测vector定义为:

根据关键点的可见性标志训练关键点置信度,若关键点可见或被遮挡,则gt置信度设为1,若关键点在视野之外(不在图片上),置信度设为零。推理过程中只保留置信度大于0.5的关键点,舍弃其他预测关键点。预测的关键点置信度不用于评估。网络在每次检测中都会预测所有17个关键点,所以需要过滤视野之外的关键点,否则会存在dangling 关键点,导致骨架变形。现有的基于热图的 bottom-up方法不需要这样做,因为它们不会检测到视野之外的关键点。
YOLO-Pose使用CSP-darknet53 作为 backbone,使用PANet 融合 backbone 输出的不同尺度特征,后接四个不同尺度的检测头。最后,两个解耦的头分别用于预测 box和关键点。在这项工作中,我们将复杂性限制在150个GMACS,在此范围内,我们能够取得具有竞争力的结果。随着复杂性的进一步增加,可以使用 top-down 法进一步缩小差距,但我们的重点是实时模型。
3.2. Anchor based multi-person pose formulation
对于给定的图像,与一个人匹配的 anchor 将存储其整个2D姿态和边界框。 box 坐标根据anchor的中心进行转换,box 的尺度根据 anchor 的宽高进行标准化。类似地,关键点位置也根据 anchor 中心进行转换,但关键点并不随anchor的宽高进行标准化。关键点和 box 都根据anchor中心进行预测。由于我们的 enhancement与 anchor 的宽高无关,因此易于扩展到 anchor-free 目标检测方法框架上,如YOLOX、FCOS。
3.3. IoU Based Bounding-box Loss Function
现在大多目标检测器使用 IoU loss 的变体,如GIoU、DIoU或CIoU loss,而非基于距离的损失,因为这些损失具有尺度不变性,并直接优化评估指标本身。我们使用 CIoU loss 监督bounding box。对于一个匹配处于位置 (i, j) ,尺度为 s 的 k t h k^{th} kth anchor 的 gt bounding box,loss定义为:
![]()
B o x p r e d s , i , j , k Box^{s,i,j,k}_{pred} Boxpreds,i,j,k 是位置 (i, j) ,尺度为s 的 k t h k^{th} kth anchor 的一个预测的box,每个位置有三个anchor,且在四个尺度上进行预测。
3.4. Human Pose Loss Function Formulation
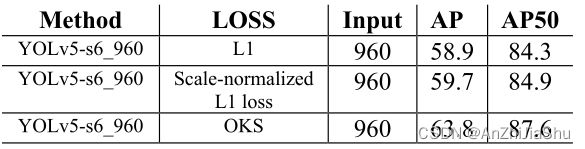
OKS是评估关键点最常用的指标。传统基于热图的 bottom-up 法使用L1损失来检测关键点,但L1损失未必适合获得最佳OKS,且 L1 loss未考虑对象的尺度或关键点的类型。由于热图是概率图,因此在纯热图方法中不可能使用OKS作为损失,只有回归关键点位置时,OKS才能用作损失函数。 Geng等人使用一个scale normalized L1 loss进行关键点回归,这是朝着OKS loss迈出的一步。
由于我们根据 anchor 中心直接回归关键点,因此我们可以优化评估指标本身,而不是使用代理损失函数。我们将 IOU loss 从 box 扩展到关键点。 对于关键点,对象关键点相似性(OKS)被视为IOU。OKS损失具有尺度不变性,且对待关键点的重要程度不同,如相比于人体关键点(肩部、膝盖、臀部等),相同 pixel-level error 的头上关键节点(眼睛、鼻子、耳朵)受到的惩罚更大。这些加权因子是COCO作者从冗余的标注的验证图像中根据经验选择的。不同于对 non-overlapping 情况出现梯度消失的原始 IoU loss,OKS损失不会停滞不前,因此 OKS 损失更类似于 dIoU loss。
每个bounding box 存储整个姿态信息。因此若一个bounding box匹配了处于位置 (i, j) ,尺度为s的一个anchor,我们预测相对于 anchor 中心的关键点。对每个关键点分别计算OKS,然后求和得出最终OKS loss 或关键点 IoU loss。

对应于每个关键点,学习一个置信度参数来显示一个人是否存在此关键点,关键点的可见性标志用作 gt。

若一个 gt box 与该 anchor 匹配,则位置 (i, j) 处的 loss 对于scale=s的 k t h k^{th} kth anchor 有效。最后,对所有 scales、anchors、locations的loss求和得到总损失:

3.5. Test Time Augmentations
所有姿态估计SOTA方法都依赖测试时间增强(Test time augmentations: TTA)来提高性能。 Flip test 和 multi-scale testing是两种常用的技术。Flip test 将复杂性增加了2倍,multi-scale testing 在三个尺度{0.5X,1X,2X}上进行推理使复杂性增加了(0.25X+1X+4X)=5.25X。随着 flip test 和 multi-scale testing的进行,复杂性增加了5.25*2x=10.5X。在我们的表中,我们相应地调整了复杂性。
除了增大计算复杂性外,准备增强数据本身代价也很高,例如,翻转测试需要翻转会增加系统延迟的图像,多尺度测试需要 resize 每个尺度。这些操作代价很高,它们不像CNN那样可以加速。融合各种前向传播的输出也需要额外的花费,对于嵌入式系统来说,在没有任何TTA的情况下获得具有竞争力的结果是非常大的改进。我们的所有结果都没有任何TTA。
3.6. Keypoint Outside Bounding Box
Top-down 法在遮挡情况下表现不佳,相比于Top-down,YOLO Pose的优点之一是:关键点不被限制在预测的 bounding box 内,因此,若关键点由于遮挡而位于边界框之外,网络仍然可以正确识别它们。但在 top-down 法中,若人体检测不正确,姿态估计也会失败。如图3所示,我们的方法在一定程度上缓解了遮挡和不正确的 box detection 的问题。

3.7. ONNX Export for Easy Deployability
Open Neural Network Exchange: ONNX(开放式神经网络交换)用于神经网络的 framework-agnostic 表示。将深度学习模型转换为ONNX能够使其高效部署于各种硬件平台上。现有 bottom-up 法中的 post-processings 没有标准化,不是标准深度学习库的一部分,例如,基于associative embedding 的bottom-up 法使用Kuhn-Munkres算法进行分组,分组是不可微的,也不是任何深度学习库的一部分。
我们模型中使用的所有操作都是标准深度学习库的一部分,并且与ONNX兼容。因此,整个模型可以导出到ONNX,从而可以轻松地跨平台部署。这个独立的ONNX模型可以使用ONNX Runtime执行,将图像作为输入,推理图像中每个人的边界框和姿态。其他 bottom-up 法没有可以端到端导出到中间ONNX表示的。
ONNX 模型分析与使用
4. Experiments
4.2. Results on COCO val2017
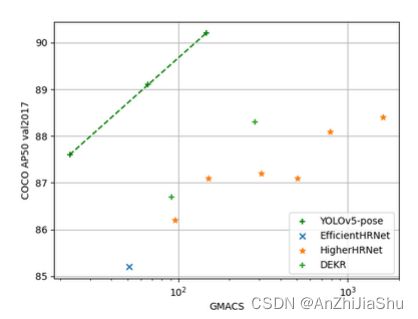
4.3. Ablation Study: OKS Loss vs L1 Loss.
4.4. Ablation Study: Across Resolution.
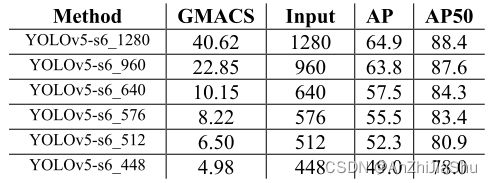

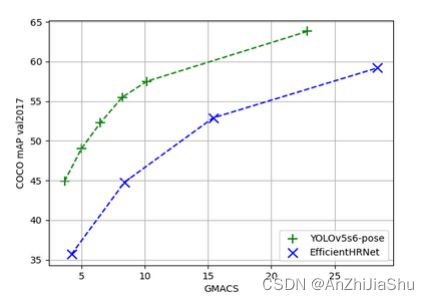
4.5. Ablation Study: Quantization

4.6. Results on COCO test-dev2017.

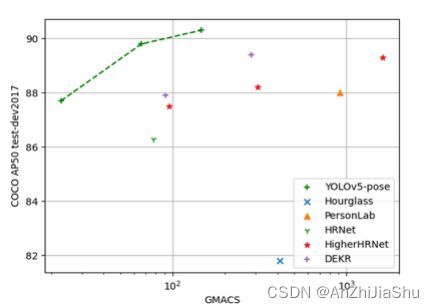
5. Conclusion
我们提出了一个基于YOLOv5的端到端联合检测和多人姿态估计框架。我们证明了我们的模型在显著降低复杂性的情况下优于现有的自底向上方法。我们的工作首次统一目标检测和人体姿态估计。到目前为止,姿态估计的大部分进展都是作为一个独立问题进行的。我们相信,我们的SOTA结果将进一步鼓励研究界探索联合解决这两项任务的潜力。我们工作的主要动机是将目标检测的所有进展传递给人体姿态估计,因为我们见证了目标检测领域的快速发展。我们在YOLOX目标检测框架上扩展了该方法并取得了不错的结果。我们将把这一想法扩展到其他目标检测框架上,进一步推动有效的人体姿态估计的极限。