TResNet学习笔记 --- TResNet: High Performance GPU-Dedicated Architecture
代码:https://github.com/mrT23/TResNet
论文:https://arxiv.org/abs/2003.13630
阿里达摩院上个月推出的推出的高性能GPU专用模型,比以前的ConvNets具有更高的准确性和效率,性能优于EfficientNet、MixNet等网络。
近年来开发的许多深度学习模型与ResNet50相比,在ImageNet上具有更高的精度,并且FLOPS数量更少或相当。尽管FLOP通常被视为网络效率的代理,但在测量实际GPU训练和推理吞吐量时,vanilla ResNet50通常比其最近的竞争对手要快得多,从而提供了更好的throughput-accuracy trade-off。在这项工作中,我们介绍了一系列体系结构修改,旨在提高神经网络的准确性,同时保留其GPU训练和推理效率。我们首先演示并讨论由FLOP优化引起的瓶颈。然后,我们提出更好地利用GPU结构和assets的替代设计。最后,我们介绍了一个称为TResNet的GPU专用模型新系列,该模型比以前的ConvNets具有更高的准确性和效率。使用TResNet模型,GPUthroughput与ResNet50相似,在ImageNet上我们达到了80.7%的top-1精度。我们的TResNet模型还可以很好地传递并在竞争性数据集上达到最先进的准确性,例如Stanford cars(96.0%),CIFAR-10(99.0%),CIFAR-100(91.5%)和Oxford-Flowers(99.1%) 。
看一下TResNet与其他modern network的对比:

可以看出,TResNet系列的TResNet-M在ImageNet的Top-1准确性上优于EfficientnetB0和Resnet50等。
本文亮点: TResNet 在 Top-1 准确度上超越了 ResNet50。
TResNet
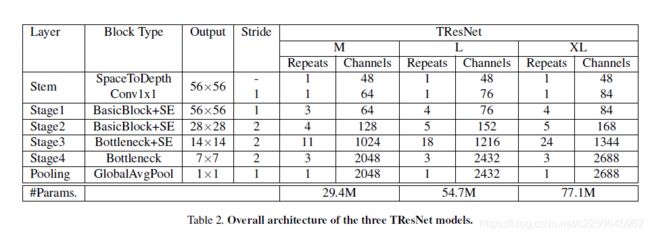
TResNet系列一共有三种型号:TResNet-M,TResNet-L和TResNet-XL,它们的区别仅在深度和通道数量不同。
与普通的ResNet50设计相比,TResNet架构包含以下改进: SpaceToDepth stem, Anti-Alias downsampling, In-Place Activated BatchNorm, Blocks selection and SE layers。
有些改进会增加模型的吞吐量,而有些则会降低模型的吞吐量。 总而言之,对于TResNet-M,我们选择了多种改进方案,它们提供了与ResNet50类似的GPU吞吐量,以公平地比较模型的准确性。
Stem Design
大多数神经网络都是从Stem单元开始的,Stem单元是其目标是快速降低输入的分辨率。
Resnet50的Stem单元是由一个步长为2的7 * 7卷积后接一个最大池化层组成,将输入的分辨率降到4倍(224 -> 56)。Resnet-D的conv7x7被三层conv3x3层所替代,该设计确实提高了准确性,但以降低训练量为代价。
TResNet的stem单元设计如下:

输入接一个SpaceToDepth转换层,该层将空间数据块重新排列为深度,后接一个简单的1x1卷积以匹配所需通道的数量。
Anti-Alias Downsampling (AA)
提出用等效的AA组件替换网络中所有下采样层,以改善深层网络的平移等距性。实现了一种类似于[14]的AA的经济变体,该变体提供了更好的速度精度折衷。所有的stride-2卷积都被stride-1卷积代替,随后是带有stride 2的3x3模糊内核滤波器,如下图所示:
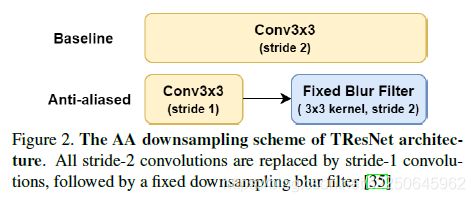
In-Place Activated BatchNorm (Inplace-ABN)
在整个架构中,作者将所有BatchNorm + ReLU层替换为Inplace-ABN 层,该层将BatchNorm和activation作为一个单独的就地操作来实现,从而大大减少了训练深度网络所需的内存,而计算量的增加可忽略不计成本。作为Inplace-ABN的激活功能,作者选择使用Leaky-ReLU而不是ResNet50的普通ReLU。 在TResNet模型中使用Inplace-ABN具有以下优点:
- BatchNorm层是GPU内存的主要消耗者。 用Inplace-ABN替换BatchNorm层实际上可使最大批处理大小增加一倍,从而提高了GPU吞吐量。
- 对于TResNet来说,Leaky-ReLU比普通的ReLU提供更好的准确率。虽然一些现代的激活函数,例如Swish和Mish,也可能与ReLU相比,它们提供了更好的精度,它们的GPU内存消耗更高,并且其计算成本更高。相反,Leaky-ReLU具有与普通ReLU完全相同的GPU内存消耗和计算成本。
Blocks Selection
Resnet34和Resnet50具有相同的架构,唯一不同的是Resnet34使用BasicBlock模块,而Resnet50使用的是Bottleneck模块。“ Bottleneck”比“ BasicBlock”具有更高的GPU使用率,但通常具有更高的准确性。
对于TResNet模型,作者发现混合使用“ BasicBlock”层和“ Bottleneck”层可提供最佳的速度准确性权衡。 由于“ BasicBlock”层具有更大的感受野,因此通常在网络开始时更为有效。
因此,作者在网络的前两个阶段放置了“ BasicBlock”层,在后两个阶段放置了“ Bottleneck”层。与ResNet50相比,作者还针对不同的TResNet模型修改了通道数和第三阶段的深度。 表2中列出了TResNet网络的完整规范,包括每阶段的宽度和块数。
SE Layers
在TResNet架构中添加了专用的SE Layer。为了减少SE块的计算成本并获得最大的速度准确性收益,仅将SE层放置在网络的前三个阶段中。与标准SE设计相比,TResNet SE的放置和超参数也得到了优化:对于Bottleneck单元,在conv3x3操作之后添加了SE模块,缩小系数为8;对于BasicBlock单元,我们在残差和之前添加了SE模块,缩减系数为4。
带有SE和Inplace-ABN的完整模块设计如图所示。

实验结果

上图展示了原始resnet50经过了五个改进的加持的效果,最终得到的TResNnet-M。
top-1准确率达到了80.7%。

上图展示了TResNet系列在不同分辨率下的top-1准确率,其中TResNet-XL大模型在448分辨率下top-1达到了84.3%

上幅图展示了TResNet与Efficientnet的训练和推断速度对比,在同等top-1准确率下,TResNet更胜一筹。
给出TResNet和Efficientnet在各个数据集下的比较结果。说明TResNet优于Efficientnet。

感想:没有非常大的创新,感觉更像是网络结构设计的一些tricks的集合,以改进网络性能。