pytorch学习笔记(二)---传统神经网络之波士顿房价预测
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、读入数据
- 二、数据预处理
-
- 1.取出标签,同时在读入的数据中删除标签
- 2.对输入数据做归一化
- 3.划分测试集和训练集
- 4.转换为tensor张量
- 三、搭建网络
- 四、训练
- 五、预测
- 总结
前言
本文承接pytorch学习笔记(一),以波士顿房价预测为例演示利用pytorch搭建一个简单的传统神经网络
一、读入数据
数据集为波士顿房价数据,预测目标为MEDV(标签),其余变量均为特征。由于是csv格式可以直接采用pandas包下的read_csv读取
feature=pd.read_csv("housing.csv")
feature
二、数据预处理
1.取出标签,同时在读入的数据中删除标签
label=feature["MEDV"]
label=np.array(label)
feature=feature.drop("MEDV",axis=1)
data=np.array(feature)
2.对输入数据做归一化
观察到在输入的数据中,有的特征普遍数值很大,神经网络会认为数值大的特征更重要,从而影响最终预测结果,因此我们需要对输入数据归一化
from sklearn import preprocessing
data=preprocessing.StandardScaler().fit_transform(data)
data
3.划分测试集和训练集
在常规任务中应当采用Dataload的方法导入并划分数据,本文为初学记录,因此采用最简单的遍历数据集划分。本案例按照3:1划分训练集和测试集。
train_data=[]
train_label=[]
test_data=[]
test_label=[]
for i in range(len(data)):
if(i%3==0):
test_data.append(data[i])
test_label.append(label[i])
else:
train_data.append(data[i])
train_label.append(label[i])
4.转换为tensor张量
torch的底层是tensor格式,其实可以就理解为 torch的模型只能识别tensor格式的数据,因为还需要对数据做一次转换
train_data=torch.tensor(train_data,dtype=float,requires_grad=True).to(torch.float32)
train_label=torch.tensor(train_label,dtype=float,requires_grad=True).to(torch.float32)
test_data=torch.tensor(test_data,dtype=float,requires_grad=True).to(torch.float32)
test_label=torch.tensor(test_label,dtype=float,requires_grad=True).to(torch.float32)
三、搭建网络
数据处理完成之后就要搭建网络结构了,传统神经网络是全连接层,因此采用torch.nn下的Linear即可,其中dropout也在nn模块下有提供
自己的网络要继承nn.Module,并在构造方法中调用父类的构造方法
在自己网络的构造方法中声明网络结构,本案例设计三个隐藏层,输入数据是13列,所以第一层隐藏层输入大小为13;本案例为回归任务,最后一层输出大小为1。
任何一个网络都需要重写forward方法,即前向传播的过程
class housing_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1=nn.Linear(13,128)
self.hidden2=nn.Linear(128,256)
self.hidden3=nn.Linear(256,256)
self.out=nn.Linear(256,1)
self.drop=nn.Dropout(0.05)
def forward(self,x):
x=F.relu(self.hidden1(x))
x=self.drop(x)
x=F.relu(self.hidden2(x))
x=self.drop(x)
x=F.relu(self.hidden3(x))
x=self.drop(x)
x=self.out(x)
x=x.squeeze(-1)
return x
测试一下,没什么问题
net=housing_NN()
net

四、训练
构造fit函数,需要注意的是,数据是分批放入模型的,即分为batch_size,此外由于torch计算梯度会累加,因此需要先将梯度清零zero_grad()
def fit(epoches,model,loss_func,opt,batch_size,data,label):
for epoch in range(epoches):
for start in range(0,len(data),batch_size):
if start+batch_size<=len(data):
end=start+batch_size
else:
end=len(data)
x=data[start:end]
y=label[start:end]
model.train()
pre=model(x)
loss=loss_func(pre,y)
opt.zero_grad()
loss.backward()
opt.step()
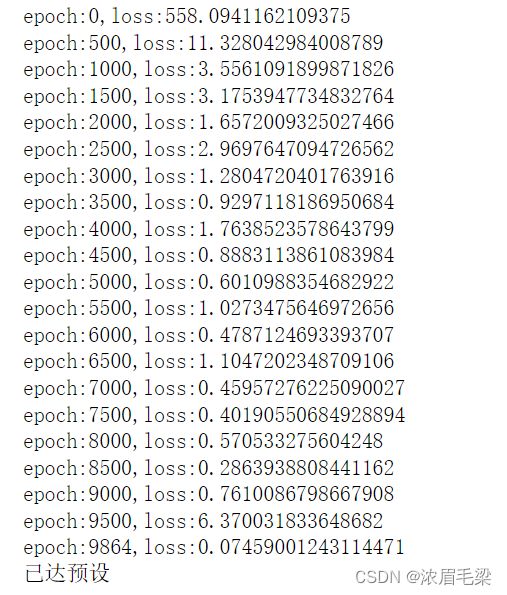
if epoch%500==0:
print(f"epoch:{epoch},loss:{loss}")
if loss<0.1:
print(f"epoch:{epoch},loss:{loss}")
print("已达预设")
break
数据和训练函数都已经就绪,下面开始传入参数训练,其中误差计算函数采用均方误差函数,优化器选择optim下的Adam优化器,更新全部参数,学习率设置为0.001,batch_size为64
from torch import optim
my_epoches=80000
my_model=housing_NN()
my_loss_func=F.mse_loss
my_opt=optim.Adam(my_model.parameters(),lr=0.001)
my_batch_size=64
fit(my_epoches,my_model,my_loss_func,my_opt,my_batch_size,train_data,train_label)
训练过程如下
五、预测
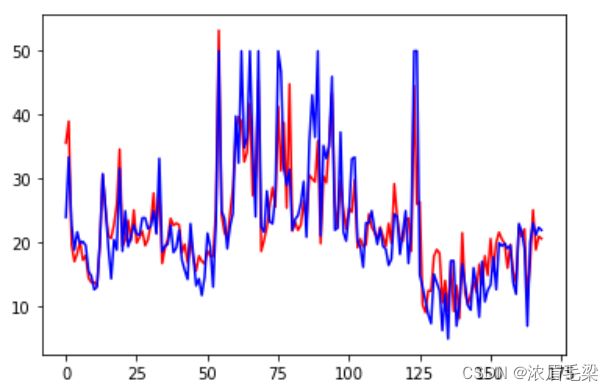
采用测试集对模型进行检验并绘图,红线为预测值,蓝线为真实值,可以看到基本是拟合的。
pre=[]
act=[]
for i in range(len(test_data)):
p=my_model(test_data[i])
pre.append(p.item())
act.append(test_label[i].item())
plt.figure(1)
plt.plot(pre,color="r")
plt.plot(act,color="b")
总结
本文仅仅用波士顿房价预测简单介绍了神经网络预测的基本过程,而torch提供了大量深度学习相关的函数和方法。后期均会使用实际案例来演示